残差网络性能机制 ResNet、DenseNet及网络结构应用
深度学习在过去的神经网络学习中,理论上层数越高的网络准确率越高,层数越高的网络其实在当时并没有提升准确率,单纯的堆层并不能提升网络的表现,有时甚至网络的层数越多,准确率越低,而深度残差网络机制ResNet可以解决这个问题。
残差网络ResNst
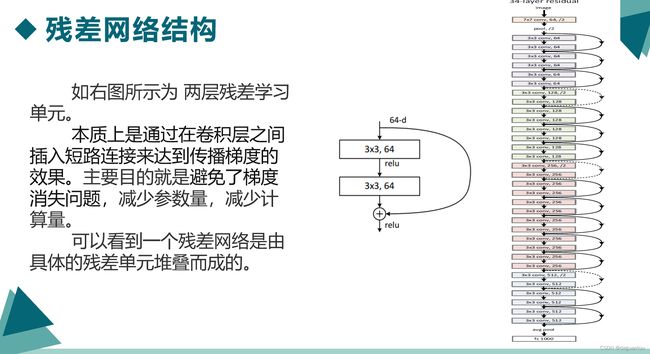
如图是ResNet的核心结构,残差网络以块(block)为单位,每个block由一系列的层和一个短路链接,短路链接将模块的输入和输出连接在一起,然后在元素层面上进行加(add),相当于跨过中间层,这样做不会产生额外的参数,不会增加计算的复杂度,而且保证加深后网络的性能不会比加深前差。
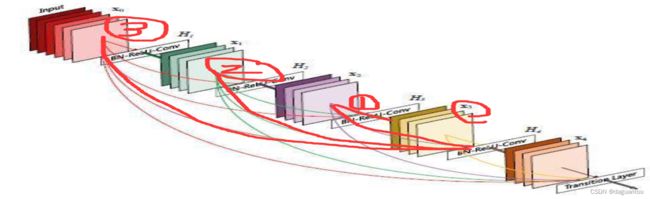
在DenseNet中,一个层会和其余所有层相连。这也是它被称为“稠密连接”的原因。这样的话DenseNet的计算量会增加,运行速度也会变慢。DenseNet的主要构建模块是稠密块(dense block)和过渡层〈transition layer)。前者定义了输入和输出是如何连结的,后者则用来控制通道数,使之不过大。
残差稠密网络DenseNet
在DenseNet中,将每一层与其余层密集连接,一个层会和其余所有层相连。这样做的目的是可以确保各层之间的信息流动达到最大。
程序网络结构





用到函数的解释
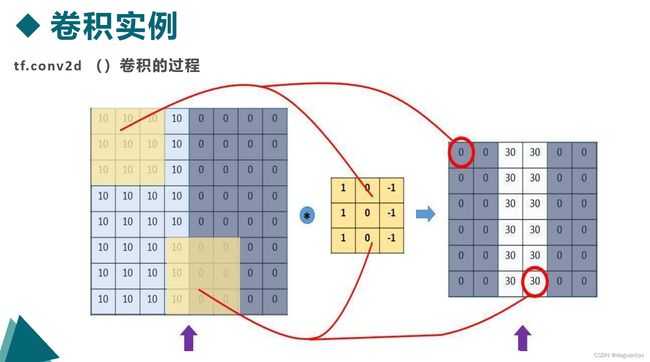
tf.layers.conv2d()
input:指需要做卷积的输入图像,要求是一个Tensor,具有[batch,in_height,in_width,in_channels]这样的图像,具体含义是“训练时一个batch的图片数量,图片的高度,图片的宽度,图像通道数”,注意:这是一个四维的Tensor,要求类型为float32和float64之一。
卷积核的个数决定了输出的特征图的个数,也就是特征图的通道数,或者说是卷积后的输出的通道数。一般来说要设成True。但是当卷积层后根由BatchNorm或者InstanceNorm层时,最好设为False,因为归一化层会归一化卷积层输出并且加上自己的bias,卷积层的(如果有)bias就是多余的了。
(2) filters: 整数,输出空间的维数(即卷积中的滤波器数).是个数字。
(3) kernel_size:滤波器的大小,如果是一个整数,则宽高相等。是个数字。
(4)strides:一个整数,或者包含了两个整数的元组/队列,表示卷积的纵向和横向的步长。如果是一个整数,则横纵步长相等。另外, strides 不等于1 和 dilation_rate 不等于1 这两种情况不能同时存在。
(5)padding:定义元素边框与元素内容之间的空间,“valid” 或者 “same”(不区分大小写)。“valid” 表示边缘不填充,"same"表示填充到过滤器可以达到图像边缘,注:在same情况下,只有在步长为1时生成的feature map才会和输入值相等。Padding:在原始照片周围打0的圈数padding规则介绍:valid情况:输出的宽高,same情况:输出的宽高和卷积核没有关系。
(6)data_format:一个字符串,可以是channels_last(默认)或channels_first,表示输入维度的顺序。channels_last对应于具有形状(batch, height, width, channels)的输入,而channels_first对应于具有形状(batch, channels, height, width)的输入.
(7)dilation_rate:2个整数的整数或元组/列表,指定用于扩张卷积的扩张率.可以是单个整数,以指定所有空间维度的相同值.目前,指定任何dilation_rate值!= 1与指定任何步幅值!= 1都不相容.
(8)activation:激活功能,将其设置为“None”以保持线性激活.
(9)use_bias:Boolean,该层是否使用偏差. 如果 use_bias 是 True(且提供了bias_initializer),则一个偏差向量会被加到输出中。
(10)kernel_initializer:卷积内核的初始化程序.
(11)bias_initializer:偏置向量的初始化器,如果为None,将使用默认初始值设定项.
(12)kernel_regularizer:卷积内核的可选正则化器.
(13)bias_regularizer:偏置矢量的可选正则化器.
(14)activity_regularizer:输出的可选正则化函数.
(15)kernel_constraint:由Optimizer更新后应用于内核的可选投影函数(例如,用于实现层权重的范数约束或值约束).该函数必须将未投影的变量作为输入,并且必须返回投影变量(必须具有相同的形状).在进行异步分布式培训时,使用约束是不安全的.
(16)trainable:Boolean,如果为True,还将变量添加到图集合GraphKeys.TRAINABLE_VARIABLES中(请参阅参考资料tf.Variable).
(17)name:字符串,图层的名称.
tf.layers.batch_normalization()
BN操作就是批标准化,标准化使数据都服从正态分布,加快模型的训练速度,平稳收敛,缓解DNN训练中的梯度消失问题。
关于trainable=False:如果设置trainable=False,那么这一层的BatchNormalization层就会被冻结(freeze),它的trainable weights(可训练参数)(就是gamma和beta)就不会被更新。
Lrelu:激活函数一般情况下,卷积之后都要加一个激活函数的,目的是增强模型的泛化能力和表达能力。
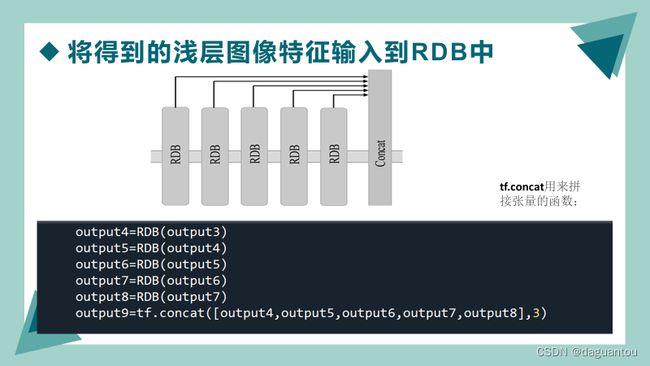
tf.concat
用来拼接张量的函数;功能是将输入参数中的tensor1, tensor2, tensor3,...进行拼接。
tf.concat连接多个通道作为下一个网络层的输入。
tf.nn.relu()用法总结
ReLU函数是常用的神经网络激活函数之一。relu称为线性整流函数(修正线性单元),用于将输入小于0的值增幅为0,输入大于0的值不变。减少神经网络的一层层计算!
tf.nn.relu(features, name=None)
tf.nn.tanh()用法总结
双曲正切函数(也称为tanh)也是常用的神经网络激活函数之一,把值压缩到 -1~1 之间。![]() 。
。
tf.nn.tanh()[别名tf.tanh]为Tensorflow中的双曲正切函数提供支持。
用法:tf.nn.tanh(x, name=None) or tf.tanh(x, name=None)
x:以下任何类型的张量:float16,float32,double,complex64或complex128。
name(可选):操作的名称。
tf.sigmoid()用法总结
应用sigmoid函数可以将输出压缩至0~1的范围。计算公式为f ( x ) = 1/ 1+ e^-x
tf.sigmoid(x,name=None)参数说明:
x :类型为float16, float32, float64, complex64, or complex128的tensor
name: 操作的名称(可选)