“泰迪杯”数据分析职业技能大赛 B 题 学生校园消费行为分析
任务 1 数据导入与预处理
数据+生成数据: 提取码:zxcv
任务 1.1
将附件中的 data1.csv、data2.csv、data3.csv 三份文件加载到
分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等
方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,
X 可从 1 开始往后编号),并在报告中描述处理过程。
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月09日
import pandas as pd
df_1=pd.read_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\data1.csv',sep=',',encoding='gbk')
df_2=pd.read_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\data2.csv',sep=',',encoding='gbk')
df_3=pd.read_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\data3.csv',sep=',',encoding='gbk')
combine=[df_1,df_2,df_3]
for i in combine:
print(i.isna().any())
##只有第二个表格里面有缺失值
#查看确实情况
print(df_2.isna().sum()/df_2.shape[0]*100)
nul=[i[0] for i in df_2.isna().any().iteritems() if i[1]==True]
对应的生成结果
>>>for i in combine:
print(i.isna().any())
Index False
CardNo False
Sex False
Major False
AccessCardNo False
dtype: bool
Index False
CardNo False
PeoNo False
Date False
Money False
FundMoney False
Surplus False
CardCount False
Type False
TermNo False
TermSerNo True
conOperNo True
OperNo False
Dept False
dtype: bool
Index False
AccessCardNo False
Date False
Address False
Access False
Describe False
dtype: bool
####可以看出只有表二有缺失值
>>>print(df_2.isna().sum()/df_2.shape[0]*100)
Index 0.000000
CardNo 0.000000
PeoNo 0.000000
Date 0.000000
Money 0.000000
FundMoney 0.000000
Surplus 0.000000
CardCount 0.000000
Type 0.000000
TermNo 0.000000
TermSerNo 98.601952
conOperNo 99.951672
OperNo 0.000000
Dept 0.000000
dtype: float64
##可以看出表二中缺失值比例过大,因此暂且不做处理。
>>>nul=[i[0] for i in df_2.isna().any().iteritems() if i[1]==True]
>>>nul
['TermSerNo', 'conOperNo']
任务 1.2
将 data1.csv 中的学生个人信息与 data2.csv 中的消费记录建立
关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与
data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
将表进行关联,用到concat函数:主要是用到了外部连接。
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月09日
import pandas as pd
df_1=pd.read_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\data1.csv',sep=',',encoding='gbk')
df_2=pd.read_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\data2.csv',sep=',',encoding='gbk')
df_3=pd.read_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\data3.csv',sep=',',encoding='gbk')
df1_2_1=pd.merge(df_1, df_2,how='right',on='CardNo')
df1_2_2=pd.merge(df_1, df_3,how='right',on='AccessCardNo')
"""
pd.cmerge(objs,how,om )
常用参数说明:
how:
how{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘inner’
类似于SQL的左外,右外,外连接,内连接。
left: use only keys from left frame, similar to a SQL left outer join; preserve key order.
right: use only keys from right frame, similar to a SQL right outer join; preserve key order.
outer: use union of keys from both frames, similar to a SQL full outer join; sort keys lexicographically.
inner: use intersection of keys from both frames, similar to a SQL inner join; preserve the order of the left keys.
on:连接时基准的参考列(也就是两张表都有的列)
"""
df1_2_1.to_csv(r'C:\Users\yunmeng\Desktop\df1_2_1.csv',index=False,encoding='utf-8')
df1_2_2.to_csv(r'C:\Users\yunmeng\Desktop\df1_2_2.csv',index=False,encoding='utf-8')
任务 2 食堂就餐行为分析
任务 2.1
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点
是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡
记录可能为一次就餐行为)
分析思路:
首先采用的数据是,data2中的数据就可以,因为我们只需要得到食堂消费的数据。
需要的处理是:对时间间隔非常接近的记录记为一次就餐行为。
那么我们设定的判断是否重复就餐的标准是:
出现在同一天,同一个人,时间间隔小于5分钟。
然后就是进行数据的处理:
整个流程如下。
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月10日
import pandas as pd
df=pd.read_csv(r"D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\data2.csv",encoding='gbk')
#将‘Date’列转化为时间对象
df['Date']=pd.to_datetime(df['Date'])
da_li=df['Date'].to_list()
#分别将每次消费的号数、小时、分钟等抽离出来。
df['day']=[i.day for i in da_li]
df['hour']=[i.hour for i in da_li]
df['minute']=[i.minute for i in da_li]
df['day']=df['day'].astype(int)
df['hour']=df['hour'].astype(int)
df['minute']=df['minute'].astype(int)
#将‘CardNo’列(卡号列)当做区分每一个学生的标准。
st_no=df['CardNo'].value_counts().index.to_list()
#用来存储需要删除的行的“Index”列的值,data2的数据中,有一列为‘Index’列,它是唯一的。
index=[]
#对每一个st_no进行遍历,相当于每次遍历取的是同一个学生的消费记录
for i in st_no:
#用学生的“CardNo'的值来拿到一个学生的所有消费记录
da=df[df['CardNo'] == i]
#获得这个学生的消费的天数的列表
day_li=da['day'].value_counts().index.to_list()
for j in day_li:
#拿到这个学生的同一天的消费记录
db=da[da['day']==j]
#对同一天的消费记录,进行遍历。每一个消费记录和他之后的消费记录进行判断。
for l in range(len(db)-1):#每一个(除了最后一个)的消费记录
for k in range(l+1,len(db)-1):#在上面的,第i个消费记录后的消费记录
#进行判断,如果小时数相等&分钟数相小于5那么就将“Index”的值记录下来,然后,判断完这个记录后就直接跳出循环,进行第二条记录的判断了。
if ((db.iloc[l:l+1,:]['hour'].to_list()[0]==db.iloc[k:k+1,:]['hour'].to_list()[0])&(abs(db.iloc[l:l+1,:]['minute'].to_list()[0]-db.iloc[k:k+1,:]['minute'].to_list()[0])<=5)):
index.append(db.iloc[l:l+1,:]['Index'].to_list()[0])
continue
#得到原来数据的复制本进行操作,不改变源数据。
de=df.copy()
#将“Index”列设置为索引列。
de=de.set_index('Index')
#去除重复了的“Index”的值
result=de.drop(index,axis=0)
#将结果保存到本地。
result.to_csv(r'C:\Users\yunmeng\Desktop\df2_1.csv',encoding='utf-8')
>>>result.shape#处理后行数
(388592, 16)
>>>df.shape#处理前行数
(519367, 17)
对上述数据用tableau进行可视化分析如图所示。

对统计的3餐的消费数据可以得出如下结论:
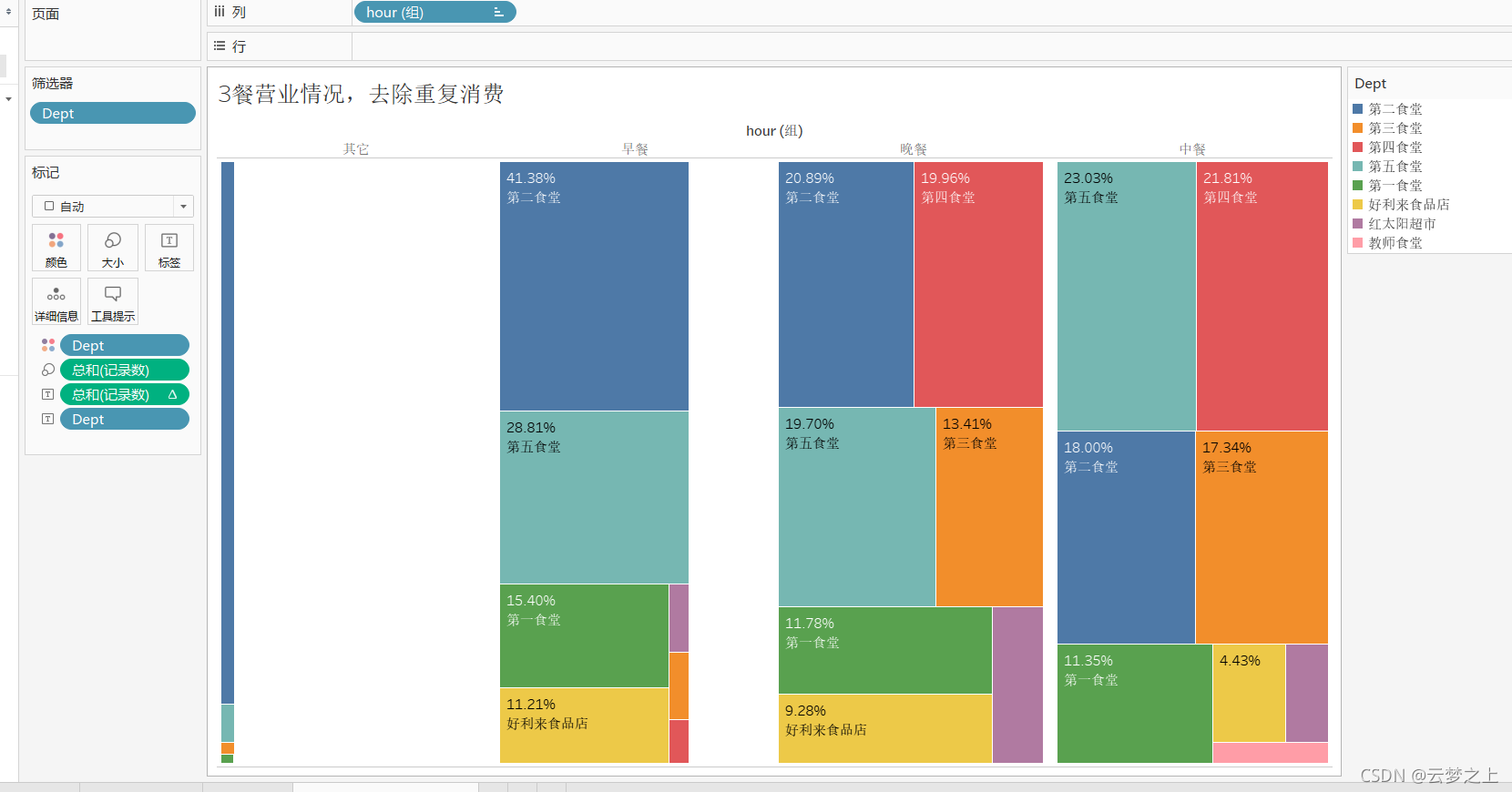
可以看到,学生在早中晚餐的就餐地点是有差别的。
早餐时间:大部分同学的选择依次是:第二食堂、第五食堂、第一食堂、好利来食品店。
中餐时间:大部分同学的选择依次是:第二食堂、第五食堂、第四食堂、第三食堂、第一食堂、好利来食品店。
晚餐时间:大部分同学的选择依次是:第二食堂、第五食堂、第四食堂、第三食堂、第一食堂、好利来食品店。
可见:第二、五食堂的早餐更受欢迎
中餐各食堂消费整体平均。
二五食堂营业领先。
同时,在0-6点期间,大部分统计去的是二食堂,说明二食堂营业时间最长,大晚上也有买吃的。
总体来讲,
3,4食堂:都是在中餐和晚餐时间为主营时间段
1,5食堂:3餐都为主要营业时间段
2食堂:3餐都为主要营业时间段,但在早餐时间业务最为繁忙,需要增加人员
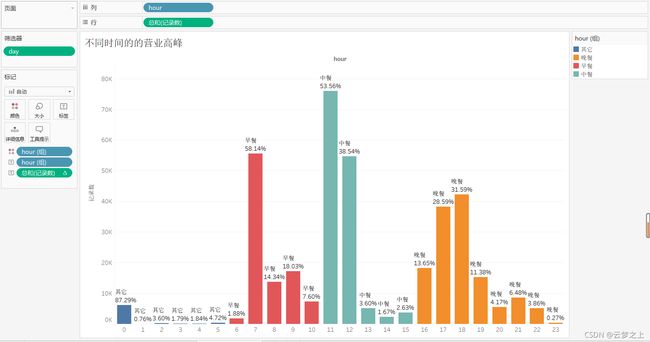
不同时间的的营业高峰,可以看出:
高分期分别为:
早餐:7.00-8.00
中餐:11:00-13.00
晚餐:17:00-19:00
所以食堂要在这几个点增加人员的部署。
任务 2.2
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲
线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。
由于作图的需要,需要区分工作日与节假日,所以得加一列数据作为是否为假期。
参考方法:python pandas 怎么判断一天是否为工作日+计算距离特定时间之间的天数
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月10日
import pandas as pd
from chinese_calendar import is_workday
df=pd.read_csv(r'C:\Users\yunmeng\Desktop\泰迪标准代码文件\学生消费\df2_1.csv',encoding='utf-8')
df['Date']=pd.to_datetime(df['Date'])
df['Date'].map(lambda x:is_workday(x))
df['is_workday']=df['Date'].map(lambda x:is_workday(x))
df.to_csv(r'C:\Users\yunmeng\Desktop\df2_2.csv',encoding='utf-8')
工作日与非工作日一天24小时的消费记录图
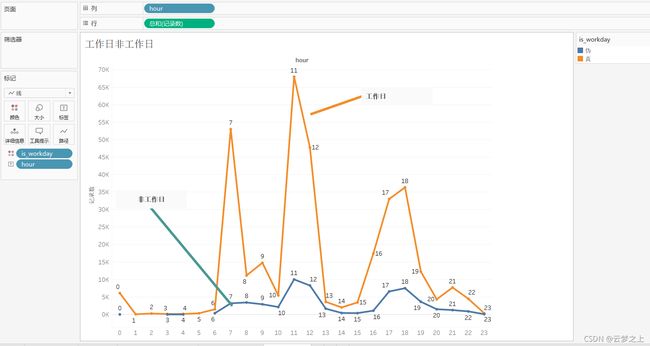
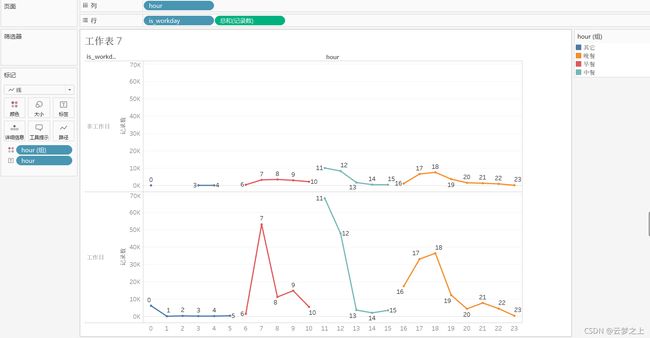

不同时间的的营业高峰,可以看出:
工作日:高分期分别为:
早餐:6.00-8.00
中餐:10:00-12.00
晚餐:17:00-19:00
非工作日:高分期分别为:
早餐:7.00-10.00
中餐:10:00-12.00
晚餐:17:00-19:00
所以食堂要在这几个点增加人员的部署。
任务 2.3
根据上述分析的结果,为食堂的运营提供建议。
任务 3 学生消费行为分析
任务 3.1
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消
费额,并选择 3 个专业,分析不同专业间不同性别学生群体的消费特点。
得出的本月人均刷卡频次和人均消费额
>>>money_average
245.81
>>>fre_average
60.14
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月11日
import pandas as pd
df=pd.read_csv(r'C:\Users\yunmeng\Desktop\泰迪标准代码文件\学生消费\df1_2_1.csv',encoding='utf-8')
#读取学生的数据表
df2=pd.read_csv(r'C:\Users\yunmeng\Desktop\泰迪标准代码文件\学生消费\data1.csv',encoding='gbk')
#计算所有的学生数
stu_num=df['CardNo'].value_counts().count()
#计算消费的总金额
consum_total=df['Money'].sum()
#得出对于所有人的:月平均消费频率,月平均消费金额
money_average=round(consum_total/stu_num,2)
fre_average=round(df['CardNo'].count()/stu_num,2)
#获得每个学生的月消费频率
count=df['CardNo'].value_counts().to_list()
CardNo=df['CardNo'].value_counts().index.to_list()
df_count=pd.DataFrame({"count":count,'CardNo':CardNo})
#获得每个学生的消费均值
Mean=df.groupby('CardNo').mean()['Money'].to_list()
cardno=df.groupby('CardNo').mean()['Money'].index.to_list()
df_mean=pd.DataFrame({'mean':Mean,'CardNo':cardno})
#得到每个学生消费均值,消费频率与学生信息的合并表格
data1=pd.merge(df_mean,df_count,how='outer',on='CardNo')
data2=pd.merge(df2,data1,how='right',on='CardNo')
data2.to_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\df3_1.csv',index=False,encoding='gbk')
选取:18电子商务、18工程造价、18工商企管3个专业进行可视化分析
从专业上看:18电子商务、18工程造价、18工商企管。
18电子商务和18工商企管专业的学生的,学生消费均值,消费频率均比18工程造价专业的更高

从专业和性别上看
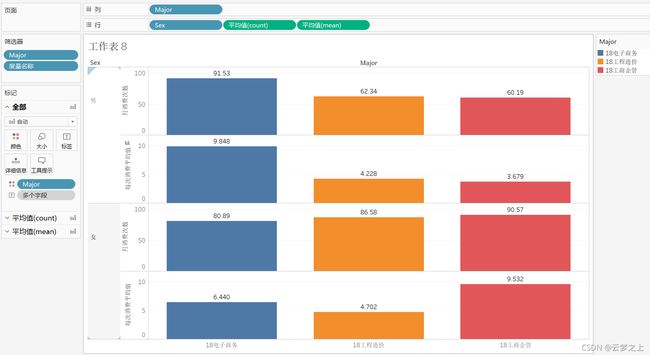
任务 3.2
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,
分析每一类学生群体的消费特点。
思路:
用到的数据要全面,因此对提供的数据进行feature的提取。(加上3.1中提取的2个数据,总共提取了5个数据)
所以,需要用到,任务3.1的人均刷卡频次和人均消费额的数据:df3_1
data3中门禁的信息数据:得到一个feature:每个人最常去的地点(address_most)
data2中的消费数据:得到2个feature:总消费次数(CardCount)、消费最常去的地点(consum_most_add)
最终得到的feature:
| feature | meaning |
|---|---|
| ‘Sex’ | 性别 |
| ’Major‘ | 专业 |
| ‘mean’ | 单次消费平均额 |
| ‘count’ | 一个月的消费数 |
| ‘address_most’ | 门禁表格中统计的最常去的地方 |
| ‘CardCount’ | 卡的总共消费次数 |
| ‘consum_most_add’ | 消费最长去的地方 |
将此7个特征作为分类标准进行分类,分为5类
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月12日
import copy
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
#每个学生的消费频率和平均消费情况
#作为核心的表格,在此基础上进行数据的添加
df=pd.read_csv(r"C:\Users\yunmeng\Desktop\泰迪标准代码文件\学生消费\df3_1.csv",sep=",",encoding="gbk")
#student info
data1=pd.read_csv(r"C:\Users\yunmeng\Desktop\泰迪标准代码文件\学生消费\data1.csv",sep=",",encoding="gbk")
#消费信息的表格
data2=pd.read_csv(r"C:\Users\yunmeng\Desktop\泰迪标准代码文件\学生消费\data2.csv",sep=",",encoding="gbk")
#门禁信息的表格
data3=pd.read_csv(r"C:\Users\yunmeng\Desktop\泰迪标准代码文件\学生消费\data3.csv",sep=",",encoding="gbk")
df3=data3.copy()
df3['Address']=df3['Address'].str.extract('(.*?)\[')
add_nama=df3.Address.value_counts().index.to_list()
data3_stu=df3['AccessCardNo'].value_counts().index.to_list()
result=[]
for i in data3_stu:
tem_da=df3[df3['AccessCardNo']==i]
#tem_da['Address'].value_counts().index.to_list()[0]
tem_dic=tem_da['Address'].value_counts().to_dict()
result.append(max(tem_dic,key=tem_dic.get))
###feature
address_most=pd.DataFrame({'AccessCardNo':data3_stu,'address_most':result})
########################################################
#对表二操作
df2=data2.copy()
####feature
card_count_gross=pd.DataFrame(df2.groupby('CardNo')['CardCount'].max().reset_index())
data2_stu=df2['CardNo'].value_counts().index.to_list()
result_2=[]
for i in data2_stu:
tem_da = df2[df2['CardNo'] == i]
# tem_da['Address'].value_counts().index.to_list()[0]
tem_dic = tem_da['Dept'].value_counts().to_dict()
result_2.append(max(tem_dic, key=tem_dic.get))
#####feature
consum_most_add=pd.DataFrame({'CardNo':data2_stu,'consum_most_add':result_2})
###合并所有的feature
#feature: address_most
#feature: card_count_gross
#feature: consum_most_add
df_1=pd.merge(df,address_most,on='AccessCardNo',how='left')
df_2=pd.merge(df_1,card_count_gross,on='CardNo',how='left')
df_3=pd.merge(df_2,consum_most_add,on='CardNo',how='left')
######################################
#对合并后的数据进行标注话处理,转化为数值型数据
deal=copy.deepcopy(df_3)
#删除没有用的列
deal.drop('Index',axis=1,inplace=True)
deal.drop('AccessCardNo',axis=1,inplace=True)
#查看一下每一列数的数据的类型情况
for col in deal.columns:
print(f"{col}: \n{deal[col].unique()}\n")
#得到非数据类型(对象类型)的数据的列名。
obj=[i for i in deal.columns if deal[i].dtype=='O']
#定义函数:对其中的不同类型的值转化为对应的数字。
def rep(repname):
major = deal[repname].unique().tolist()
major_dic = dict(zip(major, np.arange(len(major))))
deal[repname] = deal[repname].map(major_dic)
print(major_dic)
for i in obj:
rep(i)
#定义函数:查看每列数据间的方差,并把方差大于5的列名输出,同时排除CardNo列(为学号,后期分类不考虑)。
adj_name=[i for i in deal.columns if (deal[i].var()>5)&(i!='CardNo')]
#定义函数:对每一列的数进行取log(x+1),标准化
def adj(adjname):
deal[adjname]=np.log(deal[adjname]+1)
for i in adj_name:
adj(i)
#######################
#进行分类模型的搭建
model=KMeans(n_clusters=5, random_state=0).fit(deal)
deal['type']=model.labels_
pd.DataFrame(model.labels_).value_counts()
#聚类的中心
model.cluster_centers_
#得出分类的结果后,添加进原数据列,进行数据的保存导出为df3_2
final_result=pd.merge(df_3,deal[['CardNo','type']],how='left',on='CardNo')
final_result.to_csv(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\df3_2.csv',index=False,encoding='gbk')
用tableau进行可视化分析:

从图中看,这5类消费人群的特征
分为5类:
高:1 消费次数少,单价高,总消费次数少、高
中上:0 消费次数高,消费单价高,总次数中
中:1 消费次数多,消费单价低,总次数少
较低:3 消费次数低,消费单价低,总次数较低
低:4 消费次数少,消费单价低,总次数多


任务 3.3(还未做)
通过对低消费学生群体的行为进行分析,探讨是否存在某些特征,
能为学校助学金评定提供参考。