CLIP 论文学习笔记《Learning Transferable Visual Models From Natural Language Supervision》
论文标题:Learning Transferable Visual Models From Natural Language Supervision
论文地址:https://arxiv.org/abs/2103.00020
作 者:Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
Code: https://github.com/OpenAI/CLIP
时 间:2021.02.26
出 处:International Conference on Machine Learning
Zero-shot定义:学习一个新类的的视觉分类器,这个新类没有提供任何的图像数据,仅仅给出了这个类的word embedding。
Abstract:
最先进的计算机视觉系统被训练来预测一组固定的预先确定的物体类别(类别数固定,比如CIFAR10有10个类,COCO是80个类别)。这种受限的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他可视概念。(如果有新的类别需要新的数据和重新做label)。直接从原始文本中学习图像是一种很有前途的替代方法,它利用了更广泛的监督来源。从互联网上收集的4亿(图像,文本)对数据 集从头训练预测哪个标题对应哪个图像的简单预训练任务是学习SOTA图像表示(image representations)的有效和可扩展的方法。在与训练之后, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks.(自然语言引导模型去做物体的分类,分类不局限于已经学到的视觉概念,还能扩展到新的类别,从而现在学到的这个模型是能够直接在下游任务上做zero-shot的推理)。并在30多个不同的现有计算机视觉数据集上进行基准测试,研究了该方法的性能。数据集涵盖OCR、action recognition in videos, geo-localization以及许多类型的细粒度目标分类等任务。该模型可以很容易地转移到大多数任务中,能够在不需要任何数据集特定训练的情况下与完全监督的baseline相较。在ImageNet上,不需要使用128 million个训练示例中的任何一个就能匹配原始ResNet-50的精度。(迁移学习能力非常强,预训练好的模型能够在任意一个视觉分类数据集上取得好的效果)
Introduction and Motivating Work
弱监督模型与最近直接从自然语言学习图像表示的探索之间的一个关键区别是scale(数据的规模)。在本研究中,我们弥补了这一差距,并大规模地研究了经过自然语言监督训练的图像分类器的行为。借助互联网上这种形式的大量公开数据,我们创建了一个4亿对(图像、文本)的新数据集,并演示了一个简化版的从头开始训练的ConVIRT,即对比语言-图像预训练(contrast language - image pretraining,简称CLIP),是一种从自然语言监督中学习的有效方法。为了研究其可扩展性,本中共尝试了8个模型。尝试了30个数据集,都能和之前的有监督的模型效果差不多甚至更好。
Approach
我们方法的核心思想是从包含自然语言的监督中感知学习,自然语言监督的一个主要动机是这种形式的大量数据可以在互联网上公开。
工作要点1:我们构建了一个新的数据集WebImageText(WIT),包含4亿对(图像、文本)对,这些数据来自互联网上的各种公开来源。
工作要点2:选择了一个有效的预训练方式。we explored training a system to solve the potentially easier proxy task of predicting only which text as a whole is paired with which image and not the exact words of that text。(整个text和图像配对,而不是精确到text的wods)
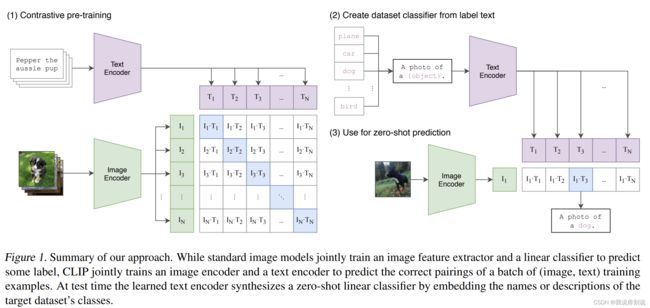
CLIP如何做预训练和zero-shot分类
给定一个有N对(图像,文本)数据,训练CLIP来预测整个N对可能发生的N × N种可能的(图像,文本)对。为了实现该操作,CLIP学习了多模态嵌入空间 通过联合训练了一个带有image encoder和text encoder去最大化N个真实数据对的正确的image和 text 对的嵌入的cosine similarity,同时最小化![]() 个不正确的数据对的image和 text 对的嵌入的cosine similarity。(总结来说使对角线的cosine similarity最大化,非对角线的cosine similarity最小化)。
个不正确的数据对的image和 text 对的嵌入的cosine similarity。(总结来说使对角线的cosine similarity最大化,非对角线的cosine similarity最小化)。
预训练后只得到了相应的文本和图像特征,没有分类头(对比学习--无监督预训练方式,需要大量训练数据);
promp template方法进行分类,以ImageNet为例,CLIP先把ImageNet中的1000个类别变化成句子,用类别代表的物体去替换句子中的{object}, 转换后的1000个句子通过预训练好的text encoder变换成1000个特征。(文中词label变换成句子的方式:prompt engineering、prompt ensemble两种方式)推理时,将图像通过image Encoder得到图像特征,把图像特征和所有1000个文本特征计算cosine similarity, 最后图像特征和文本特征那个最相似,就把特征对应的句子挑出来,从而完成分类任务。
CLIP的伪代码

基础模型:
Image Encoder:ResNet-50、ViT(微调)
Text Encoder: Transformer(微调)
最好效果模型:ViT-L/14@336px
Experiments
动机:训练一个模型,面对不同下游任务,不需要重新微调。
prompt engineering and ensembling
针对word多义性问题,本本匹配句子,作者使用prompt template "A photo of a {label}", 在句子中减少其义,并且label为名词。模板还可以补充, 比如你事先知道数据集中类别均为动物,可以更改为“A photo of a {label}, a type of pet”. 并且可以多个模板结果ensembling 效果更好,文中用了80个模板。
27个数据集的实验效果对比图

(以ResnET-50DE Linear Probe作为基线,Linear Probe是指使用与训练好的冻住的模型,只针对下游任务微调分类头。)
针对非显形物体类别(比如纹理),CLIP表现不是特别好,但是可以理解,用从未见过的数据作zero-shot有点强人所难,所以对此类数据左肋few-shot的实验。实验过程中将模型与训练好,冻住参数,训练分类头。实验结果对比如下:

这里做了20个数据集的实验,每个曲线代表20个数据集实验结果的合并,并不是一个数据集(有7个数据集的有些类样本不足16个)。
representation learning
下游任务不用zero-shot/few-shot去做实验,而是使用全部的下游数据。可以和其他预训练模型+下游任务进行公平对比。常见的两种方式:Linear Probe(冻住与训练参数,训练分类头) 和 fine tune(整个网络放开放做端到端的学习)。文中选用了Linear Probe。
参考:
https://zhuanlan.zhihu.com/p/511460120
CLIP 论文逐段精读【论文精读】_哔哩哔哩_bilibili