[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期待与您前行,加油。
这是向量表征系列文章,从Word2vec和Doc2vec到Deepwalk和Graph2vec,再到Asm2vec和Log2vec。前文介绍了谷歌的Word2vec和Doc2vec,它们开启了NLP的飞跃发展。这篇文章将详细讲解DeepWalk,通过随机游走的方式对网络化数据做一个表示学习,它是图神经网络的开山之作,借鉴了Word2vec的思想,值得大家学习。同时,本文参考了B站同济大学子豪老师的视频,强烈推荐大家去学习DeepWalk原文和子豪老师的视频。下一篇文章逐渐进入安全领域,介绍两个安全领域二进制和日志的向量表征。通过类似的梳理,让读者看看这些大佬是如何创新及应用到新领域的,希望能帮助到大家。这六篇都是非常经典的论文,希望您喜欢。一方面自己英文太差,只能通过最土的办法慢慢提升,另一方面是自己的个人学习笔记,并分享出来希望大家批评和指正。希望这篇文章对您有所帮助,这些大佬是真的值得我们去学习,献上小弟的膝盖~fighting!
文章目录
- 一.图神经网络发展历程
- 二.Word2vec:NLP经典工作(谷歌)
- 三.Doc2vec
- 四.DeepWalk:网络化数据经典工作(KDD2014)
-
- (一).论文阅读
-
- 1.摘要
- 2.引言和贡献
- 3.问题定义
- 4.网络连接的特征表示
- 5.本文方法
- 6.对比实验
- 7.个人感受
- (二). 原文PPT分享
-
- 1.Introduction:Graphs as Features
- 2.Language Modeling
- 3.DeepWalk
- 4.Evaluation:Network Classification
- 5.Conclusion & Future Work
- (三).代码实战:学习同济子豪兄视频
- 五.Asm2vec:安全领域经典工作(S&P2019)
- 六.Log2vec:安全领域经典工作(CCS2019)
- 七.总结
前文赏析:
- [论文阅读] (01) 拿什么来拯救我的拖延症?初学者如何提升编程兴趣及LATEX入门详解
- [论文阅读] (02) SP2019-Neural Cleanse: Identifying and Mitigating Backdoor Attacks in DNN
- [论文阅读] (03) 清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [论文阅读] (04) 人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [论文阅读] (05) NLP知识总结及NLP论文撰写之道——Pvop老师
- [论文阅读] (06) 万字详解什么是生成对抗网络GAN?经典论文及案例普及
- [论文阅读] (07) RAID2020 Cyber Threat Intelligence Modeling Based on Heterogeneous GCN
- [论文阅读] (08) NDSS2020 UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats
- [论文阅读] (09)S&P2019 HOLMES Real-time APT Detection through Correlation of Suspicious Information Flow
- [论文阅读] (10)基于溯源图的APT攻击检测安全顶会总结
- [论文阅读] (11)ACE算法和暗通道先验图像去雾算法(Rizzi | 何恺明老师)
- [论文阅读] (12)英文论文引言introduction如何撰写及精句摘抄——以入侵检测系统(IDS)为例
- [论文阅读] (13)英文论文模型设计(Model Design)如何撰写及精句摘抄——以入侵检测系统(IDS)为例
- [论文阅读] (14)英文论文实验评估(Evaluation)如何撰写及精句摘抄(上)——以入侵检测系统(IDS)为例
- [论文阅读] (15)英文SCI论文审稿意见及应对策略学习笔记总结
- [论文阅读] (16)Powershell恶意代码检测论文总结及抽象语法树(AST)提取
- [论文阅读] (17)CCS2019 针对PowerShell脚本的轻量级去混淆和语义感知攻击检测
- [论文阅读] (18)英文论文Model Design和Overview如何撰写及精句摘抄——以系统AI安全顶会为例
- [论文阅读] (19)英文论文Evaluation(实验数据集、指标和环境)如何描述及精句摘抄——以系统AI安全顶会为例
- [论文阅读] (20)USENIXSec21 DeepReflect:通过二进制重构发现恶意功能(恶意代码ROI分析经典)
- [论文阅读] (21)S&P21 Survivalism: Systematic Analysis of Windows Malware Living-Off-The-Land (经典离地攻击)
- [论文阅读] (22)图神经网络及认知推理总结和普及-清华唐杰老师
- [论文阅读] (23)恶意代码作者溯源(去匿名化)经典论文阅读:二进制和源代码对比
- [论文阅读] (24)向量表征:从Word2vec和Doc2vec到Deepwalk和Graph2vec,再到Asm2vec和Log2vec(一)
- [论文阅读] (25)向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)
一.图神经网络发展历程
在介绍向量表征之前,作者先结合清华大学唐杰老师的分享,带大家看看图神经网络的发展历程,这其中也见证了向量表征的发展历程,包括从Word2vec到Deepwalk发展的缘由。
图神经网络的发展历程如下图所示:
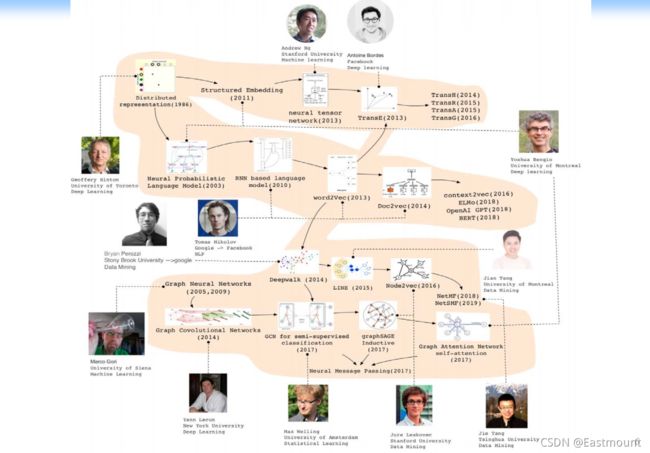
(1) Hinton早期(1986年)
图神经网络最早也不是这样的,从最早期 Hinton 做了相关的思路,并给出了很多的ideas,他说“一个样本可以分类成不同的representation,换句话,一个样本我们不应该去关注它的分类结果是什么,而更应该关注它的representation,并且它有很多不同的representation,每个表达的意思可能不同” ,distributed representation 后接着产生了很多相关的研究。
(2) 扩展(Bengio到Word2Vec)
Andrew Ng 将它扩展到网络结构上(结构化数据),另一个图灵奖获得者Yoshua Bengio将它拓展到了自然语言处理上,即NLP领域如何做distributed representation,起初你可能是对一个样本representation,但对自然语言处理来讲,它是sequence,需要表示sequence,并且单词之间的依赖关系如何表示,因此2003年Bengio提出了 Nerual Probabilistic Language Model,这也是他获得图灵奖的一个重要工作。其思路是:每个单词都有一个或多个表示,我就把sequence两个单词之间的关联关系也考虑进去。
- Yoshua Bengio, Rejean Ducharme, Pascal Vincent, and Christian Jauvin. A neural probabilistic language model. Journal of Machine Learning Research (JMLR), 3:1137–1155, 2003.
- 原文地址:https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf

但是,当时做出来后由于其计算复杂度比较高,很多人无法fellow。直到谷歌2013年提出 Word2Vec,基本上做出来一个场景化算法,之后就爆发了,包括将其扩展到paragraph、文档(Doc2Vec)。补充一句,Word2Vec是非常经典的工作或应用,包括我们安全领域也有相关扩展,比如二进制、审计日志、恶意代码分析的Asm2Vec、Log2Vec、Token2Vec等等。
- Efficient Estimation of Word Representations in Vector Space
- 原文地址:https://arxiv.org/abs/1301.3781v3
(3) 网络化数据时期(Deepwalk)
此后,有人将其扩展到网络化的数据上,2014年Bryan做了 Deepwalk 工作。其原理非常建立,即:原来大家都在自然语言处理或抽象的机器学习样本空间上做,那能不能针对网络化的数据,将网络化数据转换成一个类似于自然语言处理的sequence,因为网络非常复杂,网络也能表示成一个邻接矩阵,但严格意义上没有上下左右概念,只有我们俩的距离是多少,而且周围的点可多可少。如果这时候在网络上直接做很难,那怎么办呢?
通过 随机游走 从一个节点随机到另一个节点,此时就变成了一个序列Sequence,并且和NLP问题很像,接下来就能处理了。
- 原文地址:https://dl.acm.org/doi/10.1145/2623330.2623732
随后又有了LINE(2015)、Node2Vec(2016)、NetMF(2018)、NetSMF(2019)等工作,它们扩展到社交网络领域。唐老师们的工作也给了证明,这些网络本质上是一个Model。
(4) 图卷积神经网络(GCN)时期
2005年,Marco Gori 实现了 Graph Neural Networks。2014年,Yann Lecun 提出了图卷积神经网络 Graph Convolutional Networks。2017年,Max Welling将图卷积神经网络和图数据结合在一起,完成了 GCN for semi-supervised classification,这篇文章引起了很大关注。还有很多不做卷积工作,因此有很多Graph Neural Networks和Neural Message Passing(一个节点的分布传播过去)的工作。Jure针对节点和Transductive Learning又完成了 Node2vec 和 grahpSAGE 两个经典工作。唐老师他们最近也做了一些工作,包括 Graph Attention Network。
GraphSAGE 是 2017 年提出的一种图神经网络算法,解决了 GCN 网络的局限性: GCN 训练时需要用到整个图的邻接矩阵,依赖于具体的图结构,一般只能用在直推式学习 Transductive Learning。GraphSAGE 使用多层聚合函数,每一层聚合函数会将节点及其邻居的信息聚合在一起得到下一层的特征向量,GraphSAGE 采用了节点的邻域信息,不依赖于全局的图结构。
- Hamilton, Will, Zhitao Ying, and Jure Leskovec. “Inductive representation learning on large graphs.” Advances in neural information processing systems. 2017.
- 原文地址:https://proceedings.neurips.cc/paper/2017/file/5dd9db5e033da9c6fb5ba83c7a7ebea9-Paper.pdf

Data Mining over Networks
- DM tasks in networks:
– Modeling individual behavior
– Modeling group behavioral patterns
– Reveal anomaly patterns
– Deal with big scale
第一部分花费大量时间介绍了研究背景,接下来我们正式介绍这六个工作。
二.Word2vec:NLP经典工作(谷歌)
(详见前文)
Word2vec是一个用于生成词向量(word vectors)并预测相似词汇的高效预测框架,Word2vec是Google公司在2013年开发。
- Tomás Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. ICLR, 2013.
三.Doc2vec
(详见前文)
在Word2Vec方法的基础上,谷歌两位大佬Quoc Le和Tomas Mikolov又给出了Doc2Vec的训练方法,也被称为Paragraph Vector,其目标是将文档向量化。
- Quoc V. Le, Tomás Mikolov. Distributed Representations of Sentences and Documents. ICML, 2014: 1188-1196.
四.DeepWalk:网络化数据经典工作(KDD2014)
(一).论文阅读
原文标题:Deepwalk: Online learning of social representations
原文作者:Perozzi B, Al-Rfou R, Skiena S
原文链接:https://dl.acm.org/doi/abs/10.1145/2623330.2623732
发表会议:2014 KDD,Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining
参考资料:强推B站同济子豪兄 - https://www.bilibili.com/video/BV1o94y197vf
DeepWalk是图嵌入(Graph Embedding)的开山之作,于2014年被Bryan Perozzi等提出,旨在将图中的每一个节点编码为一个D维向量,为后续节点分类等下游任务提供支撑。DeepWalk通过随机游走算法从一个节点随机到另一个节点,从而将网络化数据转换成一个序列(Sequence),再利用类似于NLP的方法处理。DeepWalk将图当作语言,节点当作单词来生成Embedding。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第1张图片](http://img.e-com-net.com/image/info8/93b6ac38a60c43c8a75fea9be9b34e21.jpg)

1.摘要
本文提出了DeepWalk,一种新颖的(novel)用于学习网络节点的隐式表征(latent representations)的方法。这些隐式表征能够把节点在图中的连接关系进行编码,编码为一个稠密低维连续的向量空间(vector space),再通过该向量很容易地完成后续的统计机器学习分类。DeepWalk对现有的语言模型和无监督特征学习(或深度学习)的最新进展进行了概括,将原本用于NLP领域对文本或单词序列进行建模的方法(如Word2Vec)用至图中,对节点进行嵌入。
DeepWalk使用有截断的 随机游走(random walks) 序列去学习局部信息的隐层表示,并将随机游走序列当作是句子。我们演示了DeepWalk在社交网络的一些多类别网络分类任务上的隐式表示,比如BlogCatalog(博客)、Flickr(图片)和YouTube(视频)。实验结果表明DeepWalk的表现优于现有的同类(基线)算法,后者拥有一个网络的全局视图,特别是在信息缺失(标注稀疏)的场景下。当标记数据稀疏(sparse)时,DeepWalk的表示可以提供比竞争方法高出10%的F1值。在一些实验中,DeepWalk的表示优于所有基线方法,并且少使用60%的训练数据。
DeepWalk也是可扩展的(scalable)。它是一个在线学习算法,可以迭代有用的增量学习结果,并且是并行的。这些特性使得它可以适用于广泛的现实世界的应用中,如网络分类(network classification)和异常检测(anomaly detection)。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第2张图片](http://img.e-com-net.com/image/info8/121ea3ac63224ec4822e930561ea9ccc.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第3张图片](http://img.e-com-net.com/image/info8/1dd7cd29704e451d8ba7fb518a5aef74.jpg)
2.引言和贡献
由于引言至关重要,因此该部分会全文介绍,学习这些经典文章如何介绍背景、引出问题及本文的贡献及动机。
网络表示的稀疏性(sparsity)既是优点也是缺点。稀疏性使得设计有效的离散算法成为可能,但如果使用统计机器学习模型去分类或回归就会很困难。网络中的机器学习应用(如网络分类、内容推荐、异常检测和缺失链路预测)必须能够处理这种稀疏性,才能生存下来(或工作)。
在本文中,我们介绍了深度学习(无监督特征学习)技术 [3],即Word2Vec,该技术在自然语言处理中已被证明是成功的,并首次将其引入到网络分析中。
- [3] Y. Bengio, A. Courville, and P. Vincent. Representation learning: A review and new perspectives. 2013.
我们提出了DeepWalk算法,通过建模一连串的随机游走序列来学习一个图的顶点的网络连接表示(social representations,即连接结构信息)。连接结构信息是捕获邻域相似性和社群成员信息的顶点的隐式特征。这些隐式表示编码连接关系成一个连续低维稠密的向量空间。DeepWalk是神经语言模型的推广,通过随机游走序列去类比一个个句子。神经语言模型(Word2Vec)已被证明在捕获人类语言的语义和句法结构上非常成功,甚至是逻辑类比问题中。
DeepWalk将一个图作为输入,并产生一个隐式表示(向量)作为输出。本文方法应用于经典的空手道网络数据集的结果如图1所示。图1(a)是由人工排版的,图1(b)显示了我们方法所生成的2维向量(输出)。除了原图中的节点都惊人的相似外,我们注意到在图1(b)中出现了线性可分的边界,图1(b)的聚类结果对应于输入图1(a)中模块最大化的集群(用顶点颜色显示)。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第4张图片](http://img.e-com-net.com/image/info8/854db166b35b434991d06e0ecee18d41.jpg)
图1的补充内容:
(1) 图1(a)表示34个人组建的空手道俱乐部的无向图,连接表示两个人相互认识,后续分成了不同颜色的派系;图1(b)是经过DeepWalk编码后的D维向量(二维),它会将graph的每一个节点编码为一个D维向量(二维节点),绘制直角坐标系中会发现,原图中相近的节点嵌入后依然相近。该结果说明DeepWalk生成的Embedding隐式包含了graph中的社群、连接、结构信息。
(2) DeepWalk会将复杂的图转换成一个Embedding向量,然后下游任务再对该向量进行分类或聚类。此外,DeepWalk编码和嵌入属于无监督过程,没有用到任何的标记信息,只用到了网络的连接、结构、社群属性的信息,因为随机游走不会考虑节点的特征和类别信息,它只会采样图节点之间的顺序、结构信息。
(3) Karate Graph(空手道图)是经典的数据集,类似于机器学习中的鸢尾花数据集。
为了验证(demonstrate)DeepWalk在真实场景中的潜力,我们评估了它在大型异质图(heterogeneous graphs)中具有挑战性的多标签网络分类问题上的性能。在关系分类问题中,特征向量之间的链接违反了传统的独立同分布假设(i.i.d.)。解决这个问题的技术通常使用近似推理(approximate inference)技术来利用依赖信息以改进分类结果。我们跳出这些传统的方法(we distance ourselves),通过学习图的标签无关的表示来将每个节点表示为一个向量。我们的表示质量不受标记顶点选择的影响(无监督学习),因此它们可以在任务之间共享。
- 关系分类问题(relational classification):在图中标注一些节点,用已有节点去预测未标注节点的类别,如攻击者识别。
- 独立同分布假设:在鸢尾花或MNIST图谱数据集中,每个样本(花)之间或数字之间是无关的,彼此互不影响,但它们都是鸢尾花或手写数字图像,因此叫独立同分布,适用于传统的机器学习。然而,在图中,比如标注已有的攻击者去预测未知的攻击者,图之间是存在联系的,因此既不独立也不一定满足同分布,没法直接用传统的LR、SVM、DT算法解决。
DeepWalk在创建连接维度方面优于其它的隐式表示方法,特别是在标记节点稀疏的情况下。我们的表示具有很强的性能,能够使用非常简单的线性分类器(如逻辑回归)完成相关实验。此外,我们的表示方法是通用的,并且可以与任何分类方法(包括传统的迭代推理方法)相结合。DeepWalk同时也是一个在线学习算法,并且能并行加速。
本文的贡献如下:
- 我们引入深度学习作为图嵌入的工具,以建立适用于统计机器学习建模且鲁棒的向量表示。DeepWalk能够通过随机游走序列学习图的结构规律。
- 我们在多个社交网络的多标签分类任务上评估了本文的表示方法。特别在标注稀疏的场景下,DeepWalk显著提高了分类的性能,Micro F1值提高了5%到10%。在某些情况下,即使减少了60%的训练数据,DeepWalk的表现也可以超过竞争算法。
- 我们通过并行加速将DeepWalk扩展到互联网级别的图(如YouTube)上来证明我们算法的可扩展性。此外,我们还进行了一些变种改进,通过构建streaming version所需的最小变化来生成图嵌入。
3.问题定义
首先需要解决节点分类问题。我们考虑将一个社交网络的成员划分为一个或多个类别的问题。
- G = (V,E):V表示网络的节点,E表示连接关系。
- E ⊆ (V×V):E可以表示成一个V行V列的邻接矩阵,表明第i个节点和第j个节点存在联系。
- G_L = (V,E,X,Y):X表示特征(每个节点有S维特征),Y表示类别,|V|表示节点个数,|y|表示类别个数,G_L为被标注的社交网络。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第5张图片](http://img.e-com-net.com/image/info8/92d3e6b134c74fbfa6ab59c9d2d979a2.jpg)
在传统机器学习算法中,通常需要拟合一个映射H,它将X的元素映射到标签集y中。在本文的示例中,由于是图数据,因此需要利用图G结构中的依赖重要信息来获得优越的性能。在本文中,这种称为关系分类(relational classification)或集体分类(collective classification)问题。
-
传统关系分类解决方法:无向马尔科夫网络推理,通过迭代近似推理算法(如迭代分类算法、Gibbs采样、Label relaxation)计算标签给定网络结构的后验概率分布。
-
本文关系分类解决方法:提出一种新颖的方法来捕获网络拓扑信息。该方法不将标签和连接特征混合,而是通过随机游走序列来采样连接信息,即仅在Embedding中通过随机游走来编码连接信息,这是一种无监督的学习方法。
该方法的好处是将网络的连接结构信息(结构表征)和标签信息分开,从而避免误差累积(cascading errors)。此外,相同的表示方法(即图嵌入)可以用于各种网络相关的多分类问题。
本文的目标是学习到一个X_E矩阵,如下所示:比如将10个节点(|V|),每个节点压缩成128维度(d)的向量。其中,d可以是一个低维分布的向量,通过该低维连续稠密的向量(每个元素不为0)的每个元素来表达整个网络。
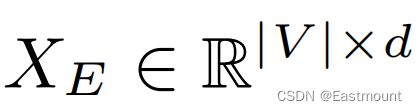
利用这些结构特征,我们将反映连接信息的Embedding和反映节点本身的特征连接,用来帮助分类决策。这些特征是通用的,可以用于任何分类算法(包括迭代方法)。然而,我们认为这些特性的最大优势是它们很容易与简单的机器学习算法集成。它们在现实世界的网络中能够被有效地扩展,我们将在第6节中展示。
4.网络连接的特征表示
该部分主要是描述Embedding。我们希望DeepWalk学到的Embedding(特征表示)具有下列特性:
- 适应性(Adaptabilty):真实网络在持续地演化,新的节点和关系出现时不需要再重新训练整个网络,而是能够增量或在线训练。换句话说,网络的拓扑结构随着网络新的节点和连接动态变化。
- 社区意识(Community aware):应该反映社群的聚类信息,如图1所示,属于同一个社区的节点有着相似的表示,网络中会出现一些特征相似的点构成的团状结构,这些节点表示成向量后也必须相似。这允许在具有同质性的网络中进行泛化。
- 低维(Low dimensional):当标记数据稀缺时,低维模型可以更好地扩展并加速收敛和推理(防止过拟合)。即每个顶点的向量维度不能过高。
- 连续(Continuous):低维向量应该是连续的,每个元素的细微变化都会对结果有影响,并且能拟合平滑的决策边界,从而实现鲁棒性更强的分类任务。
DeepWalk是通过一连串随机游走序列来对节点进行嵌入(或表示)的,并是有最初的语义模型(Word2Vec)进行优化。接下来,我们将简单回顾随机游走和语言模型的知识。
(1) Random Walks
假设将一个起始点v(i)的随机游走表示为W(vi),对应的随机过程(stochastic process)定义为:
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第6张图片](http://img.e-com-net.com/image/info8/7f334775b1be44a6bef4b5e896c614da.jpg)
其中,k表示随机游走的第k步,v(i)表示起始点,之后的第k+1节点是从第k个节点的邻居节点中随机选择一个,属于均匀的随机游走。
随机游走已被应用于内容推荐和社区检测领域中的各种相似性度量问题。通过该方法将离得近且容易走动(或连通)的节点聚集。随机游走也是输出敏感类算法的基础,这些算法利用随机游走来计算与输入图大小相关的局部社区结构信息。
- Random Walk:假设相邻节点具有相似性
- Word2Vec:假设相邻单词具有相似性
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第7张图片](http://img.e-com-net.com/image/info8/aaff545bf33246b3bb6cc9ee7d0d9387.jpg)
这种局部结构信息可以促使我们利用一连串的随机游走来提取网络的信息。除了捕获社群信息外,随机游走还有其它两个比较好的优点。
- 并行采样
- 在线增量学习(迭代学习不需要全局重新计算)
(2) Connection: Power laws(幂律分布)
选择在线随机游走算法作为捕获图结构的雏形后,我们现在需要一种合适的方法来捕获这些信息。如果连通图的度(degree)分布遵循幂律分布(即无标度图,重要节点),我们观察到顶点在随机游走中出现的频率也将遵循幂律分布。
- 随机网络:节点的度服从正态分布
- 真实世界网络:属于无标度网络,比如社交网络存在大V、银行客户存在富翁等,存在大型中枢节点,此时服从幂律分布(长尾分布或二八分布)
图2中展示了幂律分布现象,图2(a)是一个无标度图一系列随机游走的分布图,图2(b)是英文维基百科上的10万篇文章的单词幂律分布图。
- 图2(a)的横轴表示被媒体提及次数,纵轴表示节点个数(UP主数量)
- 图2(b)的横轴表示某个单词被采样到的次数,纵轴表示单词数,比如the\an\we出现较多
幂律分布参考我的前文:
- [python数据分析] 简述幂率定律及绘制Power-law函数 - Eastmount
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第8张图片](http://img.e-com-net.com/image/info8/8bde5eef8e904082a2d70c0ce4c6fca8.jpg)
为什么介绍这部分内容呢?
我们工作的一个核心贡献是将用于自然语言模型(幂律分布或Zipf定律)的技术可以用在图结构中建模(图数据挖掘)。换句话说,真实世界中,只有极少部分的单词被经常使用,或极少部分的节点被经常使用。
(3) Language Modeling
语言模型的目标是估计一个特定的单词序列出现在一个语料中的似然概率(likelihood)。换句话说,给定一系列单词W,通过上文的前n-1个词来预测第n个词。最近的表示学习研究就聚焦于利用神经网络语言模型来实现词的表示。
- 语言模型能反映一句话是否自然、高频或真实存在。

在本文中,我们提出了一种语言模型的推广,通过一系列的随机游走路径来进行建模。 随机游走可以被看作是一种特殊语言的短句或短语,节点类比成单词,通过前i-1个节点来预测第i个节点(预测访问顶点vi的可能性)。公式如下如下:

然而,本文希望利用的是节点的Embedding,而不是节点本身,如何解决呢?
我们的目标是学习一个隐式表示,因此引入一个映射函数Φ,即取出对应节点的Embedding。
![]()
接着我们就可以用公式(2)完成计算,通过前i-1个节点的Embedding来预测第i个节点。该问题是要估计它的似然概率 。

然而,随着随机游走长度的增加,计算这个条件概率就变得不可行了(n个概率连续相乘结果太小)。
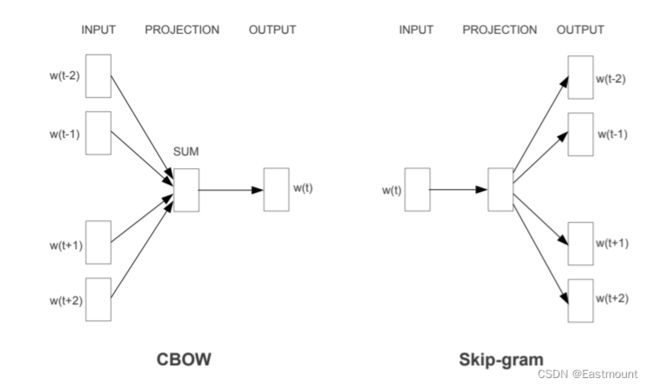
最近语言模型[27,28](Word2Vec)很好地解决了这个问题。它可以利用周围上下文来预测中间缺失的单词(CBOW),也可以利用中心词去预测上下文单词(Skip-gram),从而构建自监督场景。
- [27] T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781, 2013.
Word2Vec将单词编码成向量如下图所示:
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第9张图片](http://img.e-com-net.com/image/info8/f4f4b58300f845a69d5e5ba286de3035.jpg)
其次,上下文是由同时出现在给定单词的左右两侧的单词组成的。最后,它消除了问题的顺序约束,而是要求模型在不知道单词与给定单词之间的情况下,最大化上下文中任何单词出现的偏移的概率。
DeepWalk(Skip-gram)的损失函数定义如下(优化问题),最大化似然概率:
- 我们期待通过大量的随机游走序列训练,迭代地去优化Φ中的每一个元素,直到这个函数收敛或损失函数最小化,此时的Φ就是每个节点的Embedding。

该方法对于图嵌入(表示学习)非常适用。
- 随机游走生成的顺序没有意义,符合当前场景,能很好地捕获邻近信息。
- 模型较小能加快训练时间。
方程3的优化问题:
- 具有相同邻居节点将获得相似的表示(编码共引相似)
总而言之,本文提出一种图嵌入的表示方法,通过结合随机游走和语言模型,能将图的每个节点编码为一个连续、稠密、低维的向量(Embedding),其包含了社群的语义特征,适用于各种变化的网络拓扑结构。==
5.本文方法
该部分将详细介绍该算法的主要组件及变体。同各种语言模型算法一样,需要构建语料库和词汇表。在DeepWalk中,语料库就是一系列的随机游走序列,词汇表就是节点集合本身(V)。
(1) Algorithm: DeepWalk
该算法的详细描述如下图所示:
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第10张图片](http://img.e-com-net.com/image/info8/2b0283f912854f4397b9abd590c919e6.jpg)
a) SkipGram
SkipGram是一种语言模型,旨在利用中心词去预测上下文单词,它能反映词和词的共现关系,即使句子中出现在窗口w中的单词共现概率最大化。它使用一个独立假设来近似方程3中的条件概率,SkipGram计算Pr的算法如下:
- 通过中心节点的Embedding和上下文的某个节点的Embedding做向量的数量积。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第11张图片](http://img.e-com-net.com/image/info8/2ffccdf8585546c0bb3308e36e13ccdd.jpg)
算法2是SkipGram的具体流程。给定vj表示,我们希望在随机游走中最大化它邻居的概率(算法第3行)。此外,它也会遇到和Word2Vec相同的问题。当节点较多时,会有数以万亿的分类预测,其分母会很大。因此,为加快训练时间,我们使用分层Softmax来近似概率分布。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第12张图片](http://img.e-com-net.com/image/info8/ea2db110499f4f7aa9ae88650305398b.jpg)
b) Hierarchical Softmax
分层Softmax计算如下,它会将顶点分配给二叉树的叶子节点,将预测问题转化为层次结构中特定路径的概率最大化。
- 时间复杂度从O(n)降至O(log(n))
前一篇Word2Vec论文中已详细介绍:
- Hierarchical Softmax:Huffman树将较短的二进制代码分配给频繁出现的单词,减少需要评估的输出单元的数量。
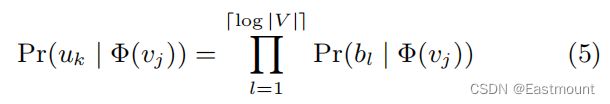
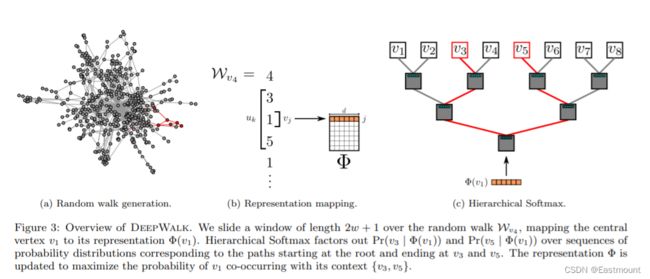
如图3c所示,原来的八分类问题转换成了3个二分类(log2(8)=3)。图中,最上层为叶子节点(8个),第二层和第三次的灰色方块为非叶子节点,即逻辑回归二分类器(7个),其参数量和Embedding维度一致。V3和V5是标签,两条红色先为对应的路径,会按照公式计算对应的损失函数并更新Embedding。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第13张图片](http://img.e-com-net.com/image/info8/e208349d328a443e88fbe3b596cac276.jpg)
接着详细分析图3。
- 首先,图3(a)表示从图中随机游走采样出一个节点序列(红色标注);
- 然后生成图3(b)所示的映射关系,v4表示4号节点,输入中心节点(v1)来预测上文和下文的节点,每侧窗口宽度w=1,通过查表得到中心节点v1映射对应的表示Φ(v1);
- 最后,将该中心词的向量输入到分层Softmax中(图3c),由于v3和v5都是标签,两条路径回各自计算损失函数,再各自优化更新,这里存在两套权重,分别是:N个节点的D维向量,N-1个逻辑回归(每个有D个权重),这两套权重会被同时优化。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第14张图片](http://img.e-com-net.com/image/info8/799624ae9762465eb0ca14812590a706.jpg)
Pr(bl | Φ(vj)) 可以通过一个二分类器来建模,该分类器被分配给节点bl的父节点,如式6所示:
- 公式的指数表示词的Embedding和逻辑回归的权重的乘积,再通过Sigmod函数输出一个后验概率。

总之,我们通过在随机游走中分配更短的路径来加快训练过程(Hierarchical Softmax),霍夫曼编码可以减少树中频繁元素的访问时间。
c) Optimization(优化)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第15张图片](http://img.e-com-net.com/image/info8/682af070e3a345b0b518be1f5524c5df.jpg)
(2) Parallelizability
可以通过多线程异步并行(集群)来实现DeepWalk,ASGD梯度通过MapReduce实现。实验结果如图4所示,证明了加速的有效性(性能不变&加速)。
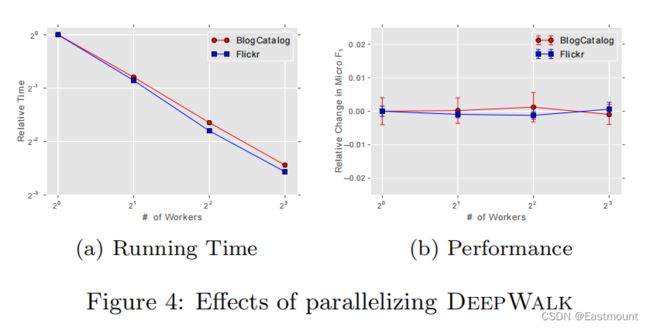
(3) Algorithm Variants
变种算法主要包括:
- Streaming
在未知全图时,直接通过采样出的随机游走训练Embedding,新的节点会增量对应的Embedding - Non-random walks
不随机的自然游走
6.对比实验
(1) 数据集和Baseline方法
实验包括三个数据集。
- BlogCatalog:博客作者提供的社会关系网络,标签代表作者提供的主题类别。
- Flickr:照片分享网站,作者之间的联系网络,标签代表用户的兴趣组。
- YouTube:视频分享网站,用户之间的社交网络,标签代表喜欢视频类型(如动漫和摔跤)的观众群体。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第16张图片](http://img.e-com-net.com/image/info8/9515b7009d3f43a0bc3bef4acf87b14e.jpg)
对比方法如下:
- SpectralClustering(谱聚类)
- Modularity(模块化)
- EdgeCluster
- wvRN
- Majority
(2) 实验结果
评估指标包括:
- T_R:标注的节点比例
- Macro-F1
- Micro-F1
实验参数:
- γ =80:每个节点被采样的次数
- w = 10:滑动窗口
- d = 128:向量的维度
- t = 40:游走的节点长度
通过one-vs-rest逻辑回归分类器解决多分类问题(构建多个二分类实现多分类预测)。整个实验结果如下所示:
- DeepWalk预测效果优于其它算法
- 当标注节点比例越小,DeepWalk效果表现越好,甚至只用20%的数据比其他算法用90%的数据更强
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第17张图片](http://img.e-com-net.com/image/info8/deebbdee1cc246a6b88a2b674454dd4b.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第18张图片](http://img.e-com-net.com/image/info8/dfc50cef7f794469bb30c3fd753d43be.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第19张图片](http://img.e-com-net.com/image/info8/200a52d3559d4c2bbebad5048b6c34cf.jpg)
参数敏感性对比实验如下图所示:
- TR会影响最优d,TR越大效果越好
- γ越大,效果越好,但边际效果逐渐降低
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第20张图片](http://img.e-com-net.com/image/info8/1046850266e0445bbe56539f770ced67.jpg)
7.个人感受
首先,本文在相关工作中进一步突出DeepWalk的优势,具体如下:
- DeepWalk是通过机器学习得到的隐式表示(Embedding),而非人工统计构造。
- DeepWalk不考虑节点的标注和特征信息,只考虑Graph的连接信息,属于无监督学习。后续可以利用无监督的Embedding和标注信息训练有监督的分类模型。
- DeepWalk是一种只使用Graph的局部信息且可扩展的在线学习方法,先前的方法都需要全局信息且是离线的。
- 本文将无监督表示学习思路应用于图中。
综上所述,本文提出了DeepWalk,一种用来学习隐式网络表征的新颖方法。通过随机游走序列捕捉网络的局部信息,再将每个节点编码成向量Embedding,能有效表征原图的结构规律。通过实验证明了DeepWalk多分类的有效性。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第21张图片](http://img.e-com-net.com/image/info8/77edce11f836409788fa89d7319be016.jpg)
下图是子豪老师的总结:
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第22张图片](http://img.e-com-net.com/image/info8/ac0846cb8c4e468b8fe27442b1924652.jpg)
个人感受:
DeepWalk是图嵌入(Graph Embedding)的开山之作,图神经网络领域非常重要的一篇论文。其核心思想是将Word2vec应用在图中,语言模型和图网络的转换非常精妙,DeepWalk将图当作语言,节点当作单词来生成Embedding。在DeepWalk中,它通过随机游走算法从一个节点随机到另一个节点,从而将网络化数据转换成一个序列(Sequence),再无监督地生成对应的Embedding,其扩展性、性能和并行性都表现良好,且支持在线学习。此外,上一篇文章我们介绍了Word2Vec,推荐大家结合阅读。
最后,好文章就是好文章,真心值得我们学习。同时,本文除了作者阅读原文外,也学习了B站同济子豪老师的视频,强烈推荐大家去学习和关注。在此表示感谢,他也说到,本文可能存在一些语法错误,但最重要的是Idea,大家写论文也优先把握好的Idea和贡献,花更多精力在那方面。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第23张图片](http://img.e-com-net.com/image/info8/fb98d116e93d4b9e8ac556d2f53fef96.jpg)
(二). 原文PPT分享
接着我们给出原作者的PPT,非常不错的内容,真心值得我们学习。因为前面已经介绍了论文,这里不再叙述,仅给出图片。
- https://docs.google.com/presentation/d/1TKRfbtZg_EJFnnzFsnYOsUiyFS0SbNi0X3Qg9OtfDSo/edit
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第24张图片](http://img.e-com-net.com/image/info8/fe7515a60f5346e68f26a441950800cc.jpg)
1.Introduction:Graphs as Features
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第25张图片](http://img.e-com-net.com/image/info8/265dc39cc50a4b52a90e8b284eea336a.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第26张图片](http://img.e-com-net.com/image/info8/43c6140225b74956847ddc0ba1266c23.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第27张图片](http://img.e-com-net.com/image/info8/74472560db5e4c6c92cde62c3538cafb.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第28张图片](http://img.e-com-net.com/image/info8/92171563fdd440a3942843d61ca98b1f.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第29张图片](http://img.e-com-net.com/image/info8/140ba406befc4df2ad873289dcf32780.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第30张图片](http://img.e-com-net.com/image/info8/068ccc42547b4c1dbfe07dcf9f7dbf12.jpg)
2.Language Modeling
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第31张图片](http://img.e-com-net.com/image/info8/8013ba6982e14bfabb7f3ecbb98f9ecd.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第32张图片](http://img.e-com-net.com/image/info8/66cd90a0b2c049fcbf40def363977d11.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第33张图片](http://img.e-com-net.com/image/info8/0988fbcd09ac4821a7d9737d857617d6.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第34张图片](http://img.e-com-net.com/image/info8/22004b3fb112409e8b07042d818c9ec7.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第35张图片](http://img.e-com-net.com/image/info8/4a60b2293cd14dd1b8c3023f962b2d05.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第36张图片](http://img.e-com-net.com/image/info8/fd01bcf81cfb4c57880d9e51ba0c9262.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第37张图片](http://img.e-com-net.com/image/info8/b84a5fdb145444228fa8a6c533ab7e69.jpg)
3.DeepWalk
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第38张图片](http://img.e-com-net.com/image/info8/d63397a696714af38ffc86b2cc9b96b6.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第39张图片](http://img.e-com-net.com/image/info8/34c2fbf2ca91485ab439acd33b1f4adb.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第40张图片](http://img.e-com-net.com/image/info8/43ccb4275f2744b7b8bfd1b827200288.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第41张图片](http://img.e-com-net.com/image/info8/f87ff3a62919410e87cba2285c80efbd.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第42张图片](http://img.e-com-net.com/image/info8/3130e76f1c8349aba9f98bef3739e6a3.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第43张图片](http://img.e-com-net.com/image/info8/9e9ac8201ccc4aa58ff7430cc3c4c143.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第44张图片](http://img.e-com-net.com/image/info8/1be7668a5ff340639c3c20c403b4d0ed.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第45张图片](http://img.e-com-net.com/image/info8/a76f9946543a40c8983fcf861deebabe.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第46张图片](http://img.e-com-net.com/image/info8/fb2c3d1d631f4c48a3fc4ac5a17827e5.jpg)
4.Evaluation:Network Classification
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第47张图片](http://img.e-com-net.com/image/info8/5290e0f3459246908351e8f049054305.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第48张图片](http://img.e-com-net.com/image/info8/a8c2470a64c94e7fbd05d0973af71d36.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第49张图片](http://img.e-com-net.com/image/info8/634e28704db14b0d87db6a8edcf7fa34.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第50张图片](http://img.e-com-net.com/image/info8/f513d0617770420c91e238190dd9c284.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第51张图片](http://img.e-com-net.com/image/info8/8d7fa1ad02a241d8988b11f18deb1622.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第52张图片](http://img.e-com-net.com/image/info8/47a2f4fd47f14a28986673a76cc58a91.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第53张图片](http://img.e-com-net.com/image/info8/03da09e5468248169ec2542a61c00d67.jpg)
5.Conclusion & Future Work
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第54张图片](http://img.e-com-net.com/image/info8/875e00a20154496da255d4e8d4e9acf7.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第55张图片](http://img.e-com-net.com/image/info8/38be4a324bf44cefb2e6f57f03fb78b5.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第56张图片](http://img.e-com-net.com/image/info8/43e95335d56d41e28752245f72d573a9.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第57张图片](http://img.e-com-net.com/image/info8/980ea5341d074610827c983319c8a075.jpg)
(三).代码实战:学习同济子豪兄视频
这是同济子豪老师分享的DeepWalk代码实战内容,我简单复现下,仅当学习笔记。后续的Python人工智能系列,会撰写代码实现DeepWalk并应用于我们的真实案例中。
- 参考资料:强推B站同济子豪兄 - https://www.bilibili.com/video/BV1o94y197vf
- B站子豪老师的地址:https://space.bilibili.com/1900783
首先分享两章图神经网络的技术路线图。
- 图神经网络或许是最容易发顶会论文的领域之一。
- 推荐:斯坦福CS224W公开课
- Neo4j能非常方便地构建图数据库和知识图谱
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第58张图片](http://img.e-com-net.com/image/info8/19d66c730c464f7385ba5cf465b3ef70.jpg)
其次是维基百科的实战案例。
- 网址:https://densitydesign.github.io/strumentalia-seealsology/
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第59张图片](http://img.e-com-net.com/image/info8/5df3fdf46da742e9833a73029585bd50.jpg)
输入下列内容点击开始捕获即可。
https://en.wikipedia.org/wiki/Computer_vision
https://en.wikipedia.org/wiki/Deep_learning
https://en.wikipedia.org/wiki/Convolutional_neural_network
https://en.wikipedia.org/wiki/Decision_tree
https://en.wikipedia.org/wiki/Support-vector_machine
生成的维基百科关联词条的DeepWalk词嵌入如下图所示,词条作为节点,词条之间的相互关联或引用关系作为图的边。然后,在该图上实现DeepWalk算法,将每个词条编码转换为D维向量。
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第60张图片](http://img.e-com-net.com/image/info8/02806f887a594675a5aabca4d6ab7511.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第61张图片](http://img.e-com-net.com/image/info8/9c6733baf39c4a11b33b345f8f8cd8bc.jpg)
此外,向量之间的关系和原始图中词条的关系是一致的,原图中相关联或相似的词条,降维可视化的相似词条聚集在一起。
- https://github.com/prateekjoshi565/DeepWalk
- https://www.analyticsvidhya.com/blog/2019/11/graph-feature-extraction-deepwalk
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第62张图片](http://img.e-com-net.com/image/info8/b64115bac1574eb8932b2634c33fe8c2.jpg)
![[论文阅读] (25) 向量表征经典之DeepWalk:从Word2vec到DeepWalk,再到Asm2vec和Log2vec(二)_第63张图片](http://img.e-com-net.com/image/info8/db01fb30075f4642b83531cc3ff39b39.jpg)
该示例的关键代码:
# function to generate random walk sequences of nodes
def get_randomwalk(node, path_length):
random_walk = [node]
for i in range(path_length-1):
temp = list(G.neighbors(node))
temp = list(set(temp) - set(random_walk))
if len(temp) == 0:
break
random_node = random.choice(temp)
random_walk.append(random_node)
node = random_node
return random_walk
get_randomwalk('space exploration', 10)
from gensim.models import Word2Vec
# train word2vec model
model = Word2Vec(window = 4, sg = 1, hs = 0,
negative = 10, # for negative sampling
alpha=0.03, min_alpha=0.0007,
seed = 14)
model.build_vocab(random_walks, progress_per=2)
model.train(random_walks, total_examples = model.corpus_count, epochs=20, report_delay=1)
# find top n similar nodes
model.similar_by_word('astronaut training')
五.Asm2vec:安全领域经典工作(S&P2019)
(待续见后)
六.Log2vec:安全领域经典工作(CCS2019)
(待续见后)
七.总结
写到这里,这篇文章就分享结束了,再次感谢论文作者及引文的老师们。由于是在线论文读书笔记,仅代表个人观点,写得不好的地方,还请各位老师和博友批评指正。下面简单总结下:
这篇文章我从向量表征角度介绍了6个经典的工作,前文介绍了谷歌的Word2vec和Doc2vec,它们开启了NLP的飞跃发展;这篇文章将介绍DeepWalk,通过随机游走的方式对网络化数据做一个表示学习,它是图神经网络的开山之作,借鉴了Word2vec的思想(Graph2vec推荐大家阅读)。接下来,我们将介绍Asm2vec和Log2vec,它们是安全领域二进制和日志向量表征的两个经典工作,借鉴了前面论文的思想,并优化且取得了较好的效果,分别发表在S&P19和CCS19。挺有趣的六个工作,希望您喜欢。其实啊,写博客其实可以从很多个视角写,科研也是,人生更是。
最后祝大家在读博和科研的路上不断前行。项目学习再忙,也要花点时间读论文和思考,这些大佬真心值得我们学习,加油!这篇文章就写到这里,希望对您有所帮助。由于作者英语实在太差,论文的水平也很低,写得不好的地方还请海涵和批评。同时,也欢迎大家讨论,继续努力!感恩遇见,且看且珍惜。

(By:Eastmount 2022-11-30 周一夜于武汉 http://blog.csdn.net/eastmount/ )
参考文献如下,感谢这些大佬!也推荐大家阅读原文。
- [1] 唐杰老师网站:http://keg.cs.tsinghua.edu.cn/jietang
- [2] Perozzi B, Al-Rfou R, Skiena S. Deepwalk: Online learning of social representations. KDD, 2014.
- [3] Narayanan A, Chandramohan M, Venkatesan R, et al. graph2vec: Learning distributed representations of graphs[J]. arXiv preprint arXiv:1707.05005, 2017.
- [4] 强推B站同济子豪兄 - https://www.bilibili.com/video/BV1o94y197vf
- [5] https://densitydesign.github.io/strumentalia-seealsology/
- [6] Tomás Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. ICLR, 2013.
- [7] Quoc V. Le, Tomás Mikolov. Distributed Representations of Sentences and Documents. ICML, 2014: 1188-1196.
- [8] Eastmount. word2vec词向量训练及中文文本相似度计算. https://blog.csdn.net/Eastmount/article/details/50637476
- [9] https://github.com/prateekjoshi565/DeepWalk
- [10] 斯坦福CS224W公开课
- [11] B站子豪老师的地址:https://space.bilibili.com/1900783
- [12] https://docs.google.com/presentation/d/1TKRfbtZg_EJFnnzFsnYOsUiyFS0SbNi0X3Qg9OtfDSo/edit