1运行GCN和DeepWalk
百度飞浆PGL图神经网络学习心得-1
- 目录
-
- Paddlepaddle
- PGL本地运行出现的问题
- 第一课:图学习初印象习题
-
- 1. 环境搭建
- 2. 下载PGL代码库
- 3. 运行示例
-
- 3.1 GCN
- 3.2 DeepWalk
- 4 PGL相关信息
- 5. 代码框架梳理
-
- 5.1 参数设置
- 5.2 数据预处理
- 5.3 模型构建
- 5.4 模型训练和测试
目录
这是我第一次在CSDN上发文章,之前写代码参考了无数篇CSDN上面的文章和code,也曾经想过自己写一写平常遇到的技术和代码难点,但总是因为懒所以一直搁置(咕咕咕)。有这个想法不是说想给别人有多大启发与借鉴,主要是为了记录自己的学习心得。
这次参与了百度飞浆PGL图神经网络训练营,其中一个结营作业就是写一篇结营感想,既然总要写,那不如顺便就开始在CSDN上写啦!这篇文章是图神经网络学习感想及课后作业的第一篇,以后有时间应该会继续更下去(要是有时间的话!!!)。
Paddlepaddle
深度学习的框架很多,tensorflow、pytorch等很受关注。国内的开源深度学习框架我目前在学习使用的就是百度飞浆paddlepaddle。(PS:英文不好,用飞浆的话,遇到问题可以在中文讨论区里面找答案,而且配备了非常完善的各种视频教程,对刚接触这个框架的人很友好)
安装推荐使用annaconda,可以省很多事(加一下国内的清华源)
飞桨安装文档:https://paddlepaddle.org.cn/install/quick
图片: 
提示:使用 python 进入python解释器,输入import paddle.fluid ,再输入 paddle.fluid.install_check.run_check()。
如果出现 Your Paddle Fluid is installed successfully!,说明您已成功安装。
显示如下就算成功了:

本地安装PaddlePaddle的常见错误:https://aistudio.baidu.com/aistudio/projectdetail/697227
手把手教你 win10 安装Paddlepaddle-GPU:https://aistudio.baidu.com/aistudio/projectdetail/696822
PGL本地运行出现的问题
第一天的作业还是比较简单的,运行GCN和deepwalk模型就好。
但我使用pycharm进行本地运行时,一直存在dll not load找不到指定模块的问题:
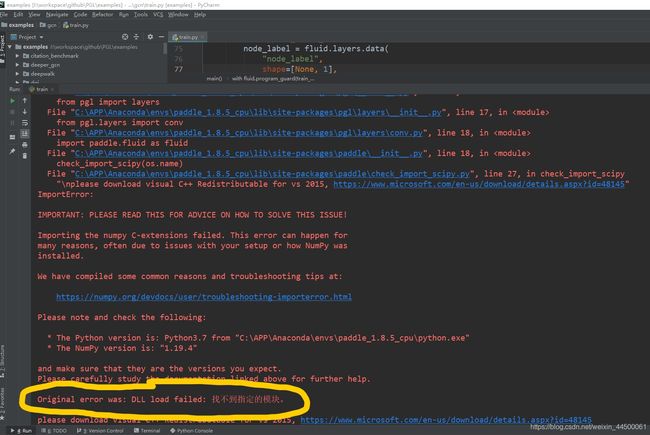
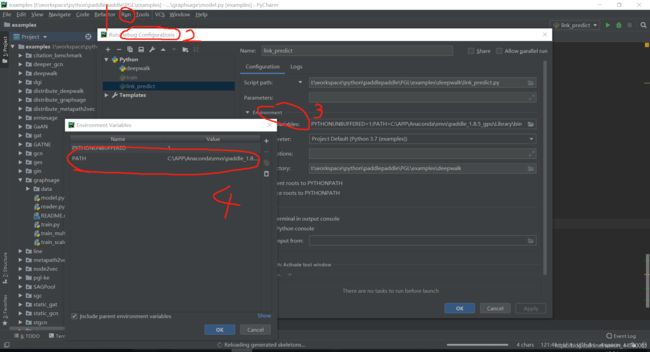
在这里非常感谢训练营里面的老师,很耐心细致的帮我解决了问题,可参考如下链接里的方法,pycharm配置一下conda 虚拟环境环境路径:
第一课:图学习初印象习题
搭建环境,运行GCN和DeepWalk。
1. 环境搭建
# !pip install paddlepaddle==1.8.5 # 安装PaddlePaddle
!pip install pgl # 安装PGL
2. 下载PGL代码库
# 由于 AIStudio 上访问 github速度比较慢,因此我们提供已经下载好了的 PGL 代码库
# !git clone --depth=1 https://github.com/PaddlePaddle/PGL
!ls PGL # 查看PGL库根目录
3. 运行示例
3.1 GCN
GCN层的具体实现见 PGL/pgl/layers/conv.py
NOTE:
- 在GCN模型中,对于图中的某个节点N,相邻节点会将学到的信息发送给它。节点N根据节点的度数给收到的信息加上权重,组合起来作为它新的表示向量。
!cd PGL/examples/gcn; python train.py --epochs 100 # 切换到gcn的目录,运行train.py在cora数据集上训练
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/externals/joblib/externals/cloudpickle/cloudpickle.py:47: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
[INFO] 2020-11-24 14:35:23,012 [ train.py: 153]: Namespace(dataset='cora', epochs=100, use_cuda=False)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/core/fromnumeric.py:3118: RuntimeWarning: Mean of empty slice.
out=out, **kwargs)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/core/_methods.py:85: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
[INFO] 2020-11-24 14:35:24,072 [ train.py: 135]: Epoch 0 (nan sec) Train Loss: 1.946185 Train Acc: 0.142857 Val Loss: 1.937398 Val Acc: 0.350000
[INFO] 2020-11-24 14:35:24,115 [ train.py: 135]: Epoch 1 (nan sec) Train Loss: 1.935671 Train Acc: 0.342857 Val Loss: 1.927820 Val Acc: 0.523333
[INFO] .......此处太多,故省略
[INFO] 2020-11-24 14:35:28,392 [ train.py: 135]: Epoch 99 (0.02773 sec) Train Loss: 0.696660 Train Acc: 0.864286 Val Loss: 0.935254 Val Acc: 0.793333
[INFO] 2020-11-24 14:35:28,408 [ train.py: 143]: Accuracy: 0.759000
3.2 DeepWalk
模型代码详见 PGL/examples/deepwalk/deepwalk.py
NOTE:
-
DeepWalk的主要原理是通过随机游走生成节点路径,然后将其作为词向量模型SkipGram的输入来学习节点表示。
-
DeepWalk 模型会在第二节课详细介绍。
Step1 学习节点表示
查看deepwalk.py中的parser(239行起),修改不同参数的值,观察其对训练结果的影响,比如游走路径长度walk_len,SkipGram窗口大小win_size等
Tips
- 如果出现内存不足的问题,可以调小batch_size参数
- 以下设置的参数为了让同学们可以快速跑出结果,设置的 epoch、walk_len、hidden_size 均比较小,可以自行尝试调大这些值。
!cd PGL/examples/deepwalk/; python deepwalk.py --dataset ArXiv --save_path ./tmp/deepwalk_ArXiv --offline_learning --epoch 2 --batch_size 256 --processes 1 --walk_len 10 --hidden_size 10
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/externals/joblib/externals/cloudpickle/cloudpickle.py:47: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
[INFO] 2020-11-24 14:36:01,632 [ deepwalk.py: 258]: Namespace(batch_size=256, dataset='ArXiv', epoch=2, hidden_size=10, neg_num=20, offline_learning=True, processes=1, save_path='./tmp/deepwalk_ArXiv', use_cuda=False, walk_len=10, win_size=10)
[INFO] 2020-11-24 14:36:02,430 [ deepwalk.py: 172]: Start random walk on disk...
[INFO] 2020-11-24 14:36:03,184 [ deepwalk.py: 182]: Random walk on disk Done.
[INFO] .......此处太多,故省略
[INFO] 2020-11-24 14:36:03,601 [ deepwalk.py: 228]: Step 0 Deepwalk Loss: 0.724576 0.372420 s/step.
[INFO] 2020-11-24 14:39:34,124 [ deepwalk.py: 228]: Step 1450 Deepwalk Loss: 0.538972 0.078368 s/step.
Step2 链接预测任务上的测试
这里选用的数据集是ArXiv,它包含了天体物理学类的论文作者间的合作关系图,得到的节点表示存储在 ./tmp/deepwalk_Arxiv
!cd ./PGL/examples/deepwalk/; python link_predict.py --ckpt_path ./tmp/deepwalk_Arxiv/paddle_model --epoch 50
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/externals/joblib/externals/cloudpickle/cloudpickle.py:47: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
[INFO] 2020-11-24 14:40:44,192 [link_predict.py: 233]: Namespace(batch_size=None, ckpt_path='./tmp/deepwalk_Arxiv/paddle_model', dataset='ArXiv', epoch=50, hidden_size=128, use_cuda=False)
2020-11-24 14:40:44,980-WARNING: paddle.fluid.layers.py_reader() may be deprecated in the near future. Please use paddle.fluid.io.DataLoader.from_generator() instead.
2020-11-24 14:40:44,999-WARNING: paddle.fluid.layers.py_reader() may be deprecated in the near future. Please use paddle.fluid.io.DataLoader.from_generator() instead.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py:1093: UserWarning: There are no operators in the program to be executed. If you pass Program manually, please use fluid.program_guard to ensure the current Program is being used.
warnings.warn(error_info)
[INFO] 2020-11-24 14:40:45,836 [link_predict.py: 215]: Step 1 Test Loss: 0.693220 Test AUC: 0.503291
[INFO] 2020-11-24 14:40:46,125 [link_predict.py: 215]: Step 2 Test Loss: 0.693154 Test AUC: 0.504987
[INFO] .......此处太多,故省略
[INFO] 2020-11-24 14:40:59,882 [link_predict.py: 192]: Step 50 Train Loss: 0.693121 Train AUC: 0.528213
[INFO] 2020-11-24 14:41:00,010 [link_predict.py: 215]: Step 50 Test Loss: 0.693128 Test AUC: 0.520660
4 PGL相关信息
pip install pgl # 安装PGL
git clone --depth=1 https://github.com/PaddlePaddle/PGL #下载PGL代码库(或者直接把左边文件中的下载到本地)
# 运行示例-GCN
cd PGL/examples/gcn; python train.py --epochs 100 # 切换到gcn的目录,运行train.py在cora数据集上训练
5. 代码框架梳理
本小节以GCN的 PGL/examples/gcn/train.py 为例,简单介绍一下图模型的训练框架。
5.1 参数设置
可修改parser的参数来使用不同的数据集进行训练
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='GCN')
# 设置数据集,默认选择cora数据集
parser.add_argument(
"--dataset", type=str, default="cora", help="dataset (cora, pubmed)")
# 设置是否使用GPU
parser.add_argument("--use_cuda", action='store_true', help="use_cuda")
args = parser.parse_args()
log.info(args)
main(args)
5.2 数据预处理
读取数据后,需要进行一些预处理,例如GCN中对图中节点度数进行了标准化
dataset = load(args.dataset)
indegree = dataset.graph.indegree()
norm = np.zeros_like(indegree, dtype="float32")
norm[indegree > 0] = np.power(indegree[indegree > 0], -0.5)
dataset.graph.node_feat["norm"] = np.expand_dims(norm, -1)
5.3 模型构建
Step1 实例化GraphWrapper和Program
- 定义train_program、startup_program和test_program等程序
place = fluid.CUDAPlace(0) if args.use_cuda else fluid.CPUPlace()
train_program = fluid.Program()
startup_program = fluid.Program()
test_program = fluid.Program()
- 实例化GraphWrapper,它提供了图的基本信息,以及GNN算法message passing机制中的send和receive两个接口。
with fluid.program_guard(train_program, startup_program):
gw = pgl.graph_wrapper.GraphWrapper(
name="graph",
place=place,
node_feat=dataset.graph.node_feat_info())
Step2 模型定义
在train_program中定义要使用的模型结构,这里是双层的GCN模型
output = pgl.layers.gcn(gw,
gw.node_feat["words"],
hidden_size,
activation="relu",
norm=gw.node_feat['norm'],
name="gcn_layer_1")
output = fluid.layers.dropout(
output, 0.5, dropout_implementation='upscale_in_train')
output = pgl.layers.gcn(gw,
output,
dataset.num_classes,
activation=None,
norm=gw.node_feat['norm'],
name="gcn_layer_2")
Step3 损失函数计算
- node_index和node_label定义了有标签样本的数据下标和标签数据
node_index = fluid.layers.data(
"node_index",
shape=[None, 1],
dtype="int64",
append_batch_size=False)
node_label = fluid.layers.data(
"node_label",
shape=[None, 1],
dtype="int64",
append_batch_size=False)
- 使用gather函数找出output中有标签样本的预测结果后,计算得到交叉熵损失函数值以及准确度
pred = fluid.layers.gather(output, node_index)
loss, pred = fluid.layers.softmax_with_cross_entropy(
logits=pred, label=node_label, return_softmax=True)
acc = fluid.layers.accuracy(input=pred, label=node_label, k=1)
loss = fluid.layers.mean(loss)
Step4 构造测试程序
复制构造test_program的静态图。到此为止,train_program和test_program的静态图结构完全相同,区别在于test_program不需要梯度计算和反向传播过程。
test_program = train_program.clone(for_test=True)
Step5 定义优化器
为了实现train_program上的参数更新,需要定义优化器和优化目标,这里是用Adam最小化loss
with fluid.program_guard(train_program, startup_program):
adam = fluid.optimizer.Adam(
learning_rate=1e-2,
regularization=fluid.regularizer.L2DecayRegularizer(
regularization_coeff=0.0005))
adam.minimize(loss)
5.4 模型训练和测试
模型构建完成后,就可以定义一个Executor来执行program了
exe = fluid.Executor(place)
Step1 初始化
执行startup_program进行初始化
exe.run(startup_program)
Step2 数据准备
将预处理阶段读取到的数据集填充到GraphWrapper中,同时准备好训练、验证和测试阶段用到的样本下标和标签数据
feed_dict = gw.to_feed(dataset.graph)
train_index = dataset.train_index
train_label = np.expand_dims(dataset.y[train_index], -1)
train_index = np.expand_dims(train_index, -1)
val_index = dataset.val_index
val_label = np.expand_dims(dataset.y[val_index], -1)
val_index = np.expand_dims(val_index, -1)
test_index = dataset.test_index
test_label = np.expand_dims(dataset.y[test_index], -1)
test_index = np.expand_dims(test_index, -1)
Step3 训练和测试
给Executor分别传入不同的program来执行训练和测试过程
- feed以字典形式给定了输入数据 {变量名:numpy数据}
- fetch_list给定了模型中需要取出结果的变量名,可以根据需要自行修改
dur = []
for epoch in range(200):
if epoch >= 3:
t0 = time.time()
feed_dict["node_index"] = np.array(train_index, dtype="int64")
feed_dict["node_label"] = np.array(train_label, dtype="int64")
train_loss, train_acc = exe.run(train_program,
feed=feed_dict,
fetch_list=[loss, acc],
return_numpy=True)
# 3个epoch后,统计每轮训练执行的时间然后求均值。
if epoch >= 3:
time_per_epoch = 1.0 * (time.time() - t0)
dur.append(time_per_epoch)
feed_dict["node_index"] = np.array(val_index, dtype="int64")
feed_dict["node_label"] = np.array(val_label, dtype="int64")
val_loss, val_acc = exe.run(test_program,
feed=feed_dict,
fetch_list=[loss, acc],
return_numpy=True)
log.info("Epoch %d " % epoch + "(%.5lf sec) " % np.mean(dur) +
"Train Loss: %f " % train_loss + "Train Acc: %f " % train_acc
+ "Val Loss: %f " % val_loss + "Val Acc: %f " % val_acc)
feed_dict["node_index"] = np.array(test_index, dtype="int64")
feed_dict["node_label"] = np.array(test_label, dtype="int64")
test_loss, test_acc = exe.run(test_program,
feed=feed_dict,
fetch_list=[loss, acc],
return_numpy=True)
log.info("Accuracy: %f" % test_acc)
图模型训练的基本框架大概就是这样啦,下次再见咯~