第一次跑yolov5-pytorch,第一次利用github深度学习库
(注意:全文只针对所找到的这个深度学习库)
目录
1.首先找到github开源库
2.配置环境
3.过程中——
4.后期工作:
4.1 train.py——
1.首先找到github开源库
2.配置环境
使用anaconda创建了一个虚拟环境,利用指令安装该库需要的环境(最后面是requirements.txt文件所在位置,里面包含该环境需要的模块)
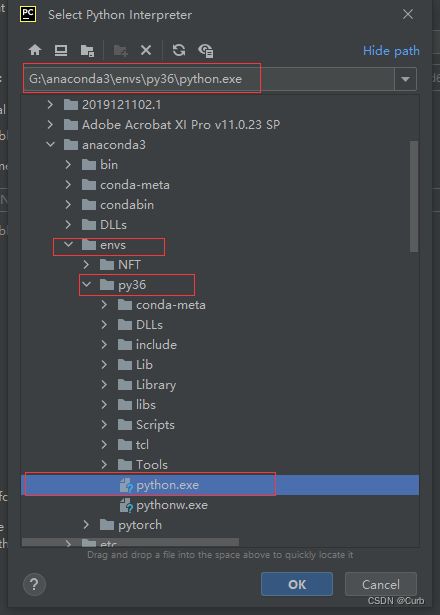
pip install -r G:\yk\yolov5-pytorch-main\requirements.txt这里使用的是pycharm,所以还需要在pycharm中使用该环境。如下,找到创建的虚拟环境py36,在env文件下,选中python.exe,最后点击ok即可
遇到的问题
安装torch.1.20失败了,解决办法,参考链接:安装 pytorch---1.2.0【各种版本pytorch安装 合集 采用了以下语句
conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch
关于下载速度慢的问题,可以使用镜像源进行下载。
#下载pytorch
python3 -m pip install --upgrade torch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple
# 下载TensorFlow
# 1.CPU版本
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow
# 2.GPU版本
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow-gpu
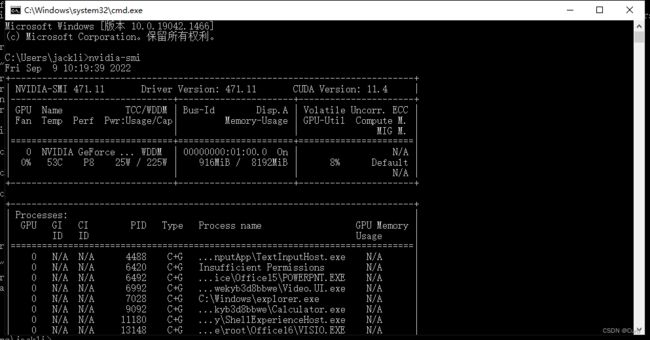
穿插一个:如何查看CUDA的版本,在window终端中输入nvidia-smi。(高版本的pytorch一般能兼容低版本cuda)
可以参考
PyTorch 最新安装教程(2021-07-27)
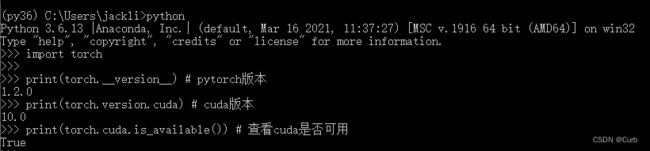
安装环境完成后,可进行检查,是否成功。“True”即成功了
import torch
print(torch.__version__) # pytorch版本
print(torch.version.cuda) # cuda版本
print(torch.cuda.is_available()) # 查看cuda是否可用
4.后期工作,运行代码,训练->预测->评估
主要步骤:首先训练数据集==》然后预测(使用自己训练的权重)==》最后评估自己的数据集
过程中肯定需要看代码,看懂代码
根据自己想要实现的功能,构造数据集格式,
制作好数据集,完成数据集的处理,自己可以建立一个cls_classes.txt,里面写自己所需要区分的类别。并注意需要修改对应的路径。
具体可参照找到的深度学习库里面的实现步骤。
运行过程中,出现了一些报错
4.1 准备数据集(VOC)
1)批量裁剪,得到想要的大小的数据集
这里进行了批量裁剪与批量重命名——
批量裁剪函数:
import cv2
import os
def update(input_img_path, output_img_path):
image = cv2.imread(input_img_path)
print(image.shape)
cropped = image[0:640, 0:640] # 裁剪坐标为[y0:y1, x0:x1],获得640*640的图片
cv2.imwrite(output_img_path, cropped)
dataset_dir = 'E:/data/maofa/select'
output_dir = ['E:/data/maofa/out_1', 'E:/data/maofa/out_2', 'E:/data/maofa/out_3', 'E:/data/maofa/out_4', 'E:/data/maofa/out_5', 'E:/data/maofa/out_6']
# 获得需要转化的图片路径并生成目标路径
image_filenames = [(os.path.join(dataset_dir, x), os.path.join(output_dir[3], x))
for x in os.listdir(dataset_dir)]
# 转化所有图片
for path in image_filenames:
update(path[0], path[1])批量重命名:
import os
class BatchRename():
def __init__(self):
self.path = 'E:/data/maofa/data_use' # 表示需要命名处理的文件夹目录,复制地址后注意反斜杠
def rename(self):
filelist = os.listdir(self.path) # 获取文件路径
total_num = len(filelist) # 获取文件长度(文件夹下图片个数)
i = 1 # 表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg') or item.endswith('.PNG') or item.endswith('.bmp'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可,我习惯转成.jpg)
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), format(str(i), '0>3s') + '.jpg') # 处理后的格式也为jpg格式的,当然这里可以改成png格式
# 这种情况下的命名格式为000xxxx.jpg形式,可以自主定义想要的格式
try:
os.rename(src, dst)
print('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
2)打标签(这个过程很痛苦)——labelimg
具体实现参见:4 教你如何制作自己的yolo数据集_哔哩哔哩_bilibili
4.2 voc_annotation;train.py——
voc_annotation.py——主要进行对数据集的处理,获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
train.py——训练数据集
遇到的问题
no module named ‘tensorboard’ 解决:pip install tensorboard
ModuleNotFoundError: No module named 'past' 解决:pip install future
下面这个错误折腾了好久——
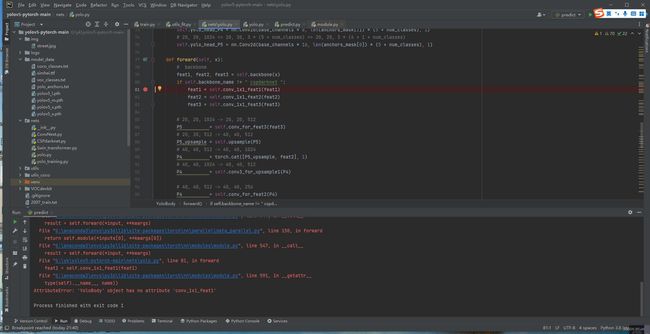
最后发现,“cspdarknet”多了两个空格 ,引起的报错
训练成功
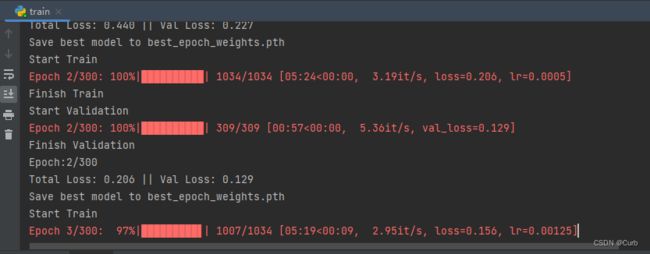
(跑了一晚上都没跑出来)
4.3 yolo.py;predict.py
这两个是训练结果预测需要运行的文件,记得修改相关参数。(特别是训练自己的数据集的时候)
另外还可以评估数据集,具体参见深度学习库里面的readme.md文件。