个人yolov学习笔记与总结
yolov3学习,根据大佬CSDN博主「Bubbliiiing」的原创文章Pytorch 搭建自己的YOLO3目标检测平台学习的笔记,下方是原文链接
Pytorch 搭建自己的YOLO3目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
(8条消息) 一层层堆叠的意思是什么_卷积神经网络多层网络中每一层的意义是什么?_weixin_39573535的博客-CSDN博客
上方是整体卷积神经网络大致思路参考
yolov3的特点,使用Darknet-53作为主干特征提取网络,使用特征金字塔结构提取更有效的提取特征



初入深度学习1——如何下载与打开一个Github深度学习库
下载git,找到源码网址,点击绿色的code,复制里面的路径,通过git的 git clone +地址下载好源文件文件夹,一般下载c盘用户文件夹里面,移到对应文件夹后通过pycharm打开,然后下载权重,训练集
初入深度学习2——如何使用一个深度学习库
一,环境配置:1.仓库包含requirements.txt(直接下载),2.仓库不包含requirements.txt (所谓麻烦)
二,训练,1.训练通用数据集 2.训练自己的数据集
训练步骤如下

yolov3的整体结构
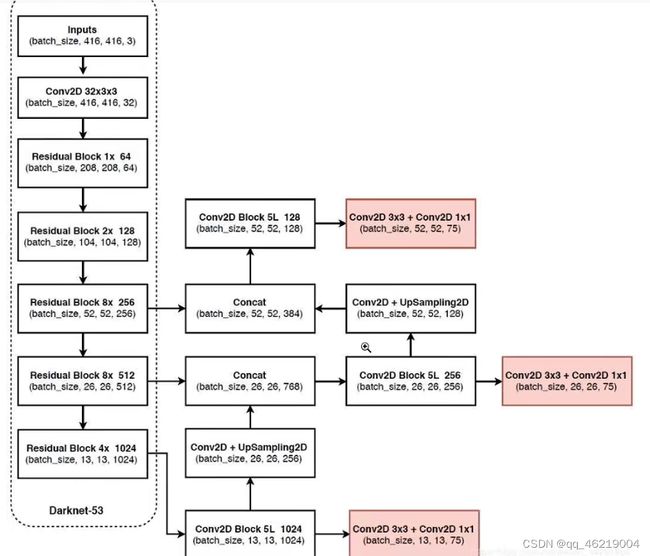
左边虚线部分是yolov主干特征提取网络Darknet-53,residual block意思是残差块,conv意思是卷积
BATCH_SIZE:即一次训练所抓取的数据样本数量;
BATCH_SIZE的大小影响训练速度和模型优化。同时按照以上代码可知,其大小同样影响每一epoch训练模型次数。

13 13 3的意思是有三个13 13 的大小的特征层,用来标记一定的区域,20是因为此次分类一共有20种,4的调整参数是调整先验框的大小的参数,即把先验框变成预测框
13 13 13 1024 5次卷积后向上即是构建特征金字塔的过程,卷积加上采样
什么是残差网络
残差网络和普通卷积最大的区别是它使用了残差边,残差网络由一个一个块组成,每一个块有输入和输出,结构如下
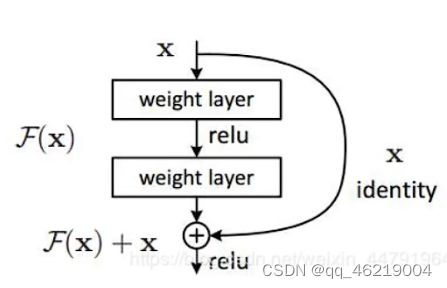
部分数据结果卷积等处理,部分不经过处理直接和尾部相连,中间是主干提取网络,x即残差边(基本上不处理),也就是说残差网络有一个残差边绕过来
因为有残差边所以更容易优化和训练,Darknrt53除了刚开始的卷积,其他都使用了残差块
ResNet50网络介绍
a、什么是残差网络
Residual net(残差网络):
将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
其结构如下:
深度残差网络的设计是为了克服由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。
b、什么是ResNet50模型
ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
Conv Block的结构如下,由图可以看出,Conv Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,存在一次卷积、标准化,由于残差边部分存在卷积,所以我们可以利用Conv Block改变输出特征层的宽高和通道数:
卷积
卷积想象成一种混合信息的手段。想象一下装满信息的两个桶,我们把它们倒入一个桶中并且通过某种规则搅拌搅拌。也就是说卷积是一种混合两种信息的流程
关于卷积概念的深入理解:什么是深度学习中的卷积? - 知乎 (zhihu.com)
卷积神经网络(CNN)概念解释 - 腾讯云开发者社区-腾讯云 (tencent.com)
从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变_哔哩哔哩_bilibili
卷积需要进行的是矩阵操作,此处补充一下,矩阵的知识点,矩阵的本质就是线性方程式,两者是一一对应关系,矩阵的最初目的,只是为线性方程组提供一个简写形式。
网络实操的代码实现过程
1.根据网络,首先构建主干提取网络提取特征,后利用提取到的特征构建特征金字塔,进行分类预测和回归预测,详情在代码nets/Darknet.py里有做标注,提取网络如下
通过Darknet 53获取特征,之后通过获取的特征构建的特征金字塔,进行分类预测和回归预测
通过Darknet 53获取特征部分:
1.为整个Drknet 53网络传入一个列表,如(1,2,8,8,4),对应残差块使用的次数
2.Darknet先进行初始化,即.Darknet上方的卷积和添加残差块make layer,卷积后进行标准化和激活函数,此时还未进行网络传播
3.开始进入网络堆叠,(1,2,8,8,4),make layer先通过卷积核为3*3,步长为2的卷积对输入进来的特征层进行下采样,这个下采样时输入进来的特征层长宽进行压缩,通道数扩张,卷积后进行标准化和激活函数
之后进行bsaic block通过堆叠,(注意上述图)bsaic block在初始化时定义了两组初始化加激活函数,在forwoard里面分为两个部分一个是主干边,另一个是残差边x;主干边对输入进来的特征进行两组卷积标准化加激活函数的操作,然后把得到结果与残差边进行相加,以上构建好了残差网路,注意,在残差网络构建的结构里面,首先会利用1*1的卷积下降通道数(32通道),相当于全连接,再利用3*3的卷积扩张通道数(64通道数),这样的结构可以减少参数量,减少参数是因为1*1的卷积压缩了通道数,下次3*3的卷积用的参数3*3*channels中channels就少了,卷积核的通道数和上一级的特征图是一致的
block参数规定了残差块循环堆叠的次数
forwoard意思是前向传播,相当与通过该函数构建整体网络线,将各个部分按步骤连接起来
前面的特征层不需要输出,将最后三个特征层处理后的结构输出
通过获取的特征构建的特征金字塔,进行分类预测和回归预测部分:(注意上方结构图)
1. 在yolobody函数中,通过darknet 53获取最后三层的特征层,首先获取参数final_out_filter0,这个参数关乎最终输出结果,此结构都是75,#75的由来,3*25(5+numclass即20),3表示3个先验框,5表示为1+4,1表示为是否存在物体,4表示检测框的调整参数,20表示种类为20
2.然后从下到上,进行卷积,最后的7(5+2),前面的的五次利用的是之前先1后3的卷积提取,原因一样,获取特征的同时减少参数量,后面的两次卷积是用来进行线性预测和回归预测的
3.卷积加上采样部分,上采样可以扩张通道数,因此扩张之后可以堆叠系统的通道数
整体按网络进行
最后输出三个线性预测和回归预测的结果,之后利用结果解码先验框和进行预测
2.通过utils_bbox.py的DecodeBox进行解码,特征层解码过程通过Decode box实现,Decode box每次只能对一个特征层进行解码操作,解码过程主要用到3*(1+4+20)里面4的内容,4包含先验框的变换参数,代码很详细,因此不写步骤
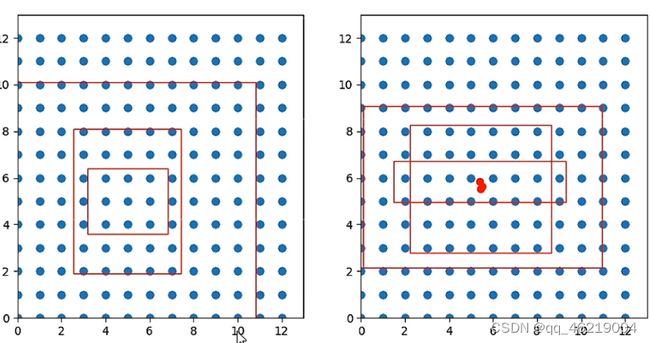
生成的原始三个先验框大小的不一样的,如图所示
调整前后 ,在13 13的特征层中
3.Predict -预测过程详解
包括前处理和后处理的过程(如何使用预测,点击运行predict.py文件,输入图片文件地址)
利用yolo文件中detect_image的方法,进行图片的检测
在yolov.py 的detect_image开始,包括在utils_bbox.py中的non_max_suppression函数,该函数将预测框进行堆叠,然后进行非极大抑制,非极大抑制的功能是筛选一定区域内,属于同一种类得分最大的框框
预测过程包括:
1.将图像转换成RGB图像,防止灰度图在预测时报错。改成rgb格式的原因 1.对rgb有权重配置 2.rgb更容易绘图
2.给图像增加灰条,实现不失真的resize,因为预测的图片标准格式一般是方图
3.图片添加上batch_size维度,才能添加到网络中进行预测
4.图片归一化与转置到第一维度,将数据从numpy的形式转换为torch形式,接下来进行预测部分
5.判断是否需要使用GPU,将图像输入网络当中进行预测,decode_box把结果进行解码,与先验框的解码类似
6.将预测框进行堆叠,然后进行非极大抑制,非极大抑制的功能是筛选一定区域内,属于同一种类得分最大的框框,得出结果
7.判断是否检测到物体与输出参数包括,物体的种类,检测框的置信度和坐标
8.图像绘制,将为了不失真,给图像增加灰条的图片改成原始大小格式
训练集部分
4.Dateset-数据集格式详解
我们使用的是voc格式,在VOCdevkit 文件夹中,JPEGimages里是图片文件,Annotations存放的是标签文件,一一对应前面的图片文件,也就是对应图片的标签,标签文件主要关注的是
ImageSet文件里面包括 test 文件 train文件 trainval文件 val文件
train文件里面存放的是训练图片文件,val文件存放的是拿来验证的文件名,test是用map来进行计算的,做测试集
Dateset2-数据集的制作,labelimg的使用,安装后cmd激活环境,输入labelimg运行制作
训练参数解析
train.py文件,model_data文件夹里面,classes存放的是标签名,注意train.py中classes_path里的路径
yolo_anchors.txt,里存放的是对应特征层先验框的大小,三个一组,可在此修改,一般不修改model_path对应的是预训练权重
input_shape是输入图片的大小,可修改,但是一定要是32的倍数
训练数据集
voc_annotation.py里面有详细内容,运行train.py开始训练
利用训练好的模型进行预测
修改yolo.py里的路径,非极大抑制等参数后运行predication.py进行预测
Eval 评价指标map的计算
get_map.py
修改好classes_path的路径,后运行该文件,
5.训练过程解析-损失函数计算
计算过程在utils_fit.py中的fit_one_epoch函数中,yololoss函数在yolo_train.py中,
过程:获得网络应该有的预测结果,之后进行某些特征点的忽略,忽略完成之后计算损失,计算损失时会使小样本的权重大一些,大样本权重小一些