rnn lstm gru
Sequence models are a special class of deep neural networks that have applications in machine translation, speech recognition, image captioning, music generation, etc. Sequence problems can be of varying types where the input X and output Y might both be sequences with either the same length or different lengths. It can also be that only one of X or Y is a sequence. These are a few examples of the applications of RNNs:
序列模型是一类特殊的深度神经网络,可用于机器翻译,语音识别,图像字幕,音乐生成等。序列问题可以是不同类型的,其中输入X和输出Y可能都是具有相同序列的序列长度或不同长度。 也可以是X或Y中只有一个是序列。 这些是RNN应用的一些示例:
单词表示 (Word Representation)
If the input is a sentence, then each word can be represented as a separate input like x(1), x(2), x(3), x(4), etc. So, how do we represent each individual word in a sentence? The first thing we need to do is come up with a dictionary containing all possible words we might have in our input sentences. The first word in the dictionary could be ‘a’, and further down we might find ‘and’ or ‘after’ and the last word could be something like ‘zebra’ or ‘zoo’. Preparing the dictionary is really in our hands because we can include as many words that we want. The length of a dictionary can vary from 10,000 to 100,000 or even more.
如果输入是一个句子,那么每个单词都可以表示为一个单独的输入,例如x(1),x(2),x(3),x(4)等。因此,我们如何表示每个单词一句话? 我们要做的第一件事是拿出一个字典,其中包含我们在输入句子中可能包含的所有可能单词。 字典中的第一个单词可能是“ a”,而在更下方的位置我们可能会找到“ and”或“ after”,最后一个单词可能是诸如“ zebra”或“ zoo”之类的东西。 实际上,准备字典是我们的事,因为我们可以包含任意数量的单词。 字典的长度可以从10,000到100,000甚至更大。
Let’s say we have a named entity recognition problem where X is an input sentence like ‘Jack and Jill went up the hill.’ and Y is an output representing whether each input word is a person’s name or not. So, essentially y(1), y(2), y(3), y(4) will be 1 if it is a persons name and 0 otherwise. And x(1), x(2), x(3), x(4) will be vectors of length 10,000 assuming our dictionary contains 10,000 words. For example, if Jack comes at the 3200th position in our dictionary, x(1) will be a vector of length 10,000 containing a 1 at the 3200th position and 0 everywhere else. There might be a case that a word in the input sequence is not present in our dictionary and for that, we can use a separate token like ‘unknown’ or something else.
假设我们有一个命名实体识别问题,其中X是一个输入语句,例如“杰克和吉尔上山了”。 Y是表示每个输入单词是否是一个人的名字的输出。 因此,如果y(1),y(2),y(3),y(4)本质上为人名,则将为1,否则为0。 假设我们的字典包含10,000个单词,则x(1),x(2),x(3),x(4)将是长度为10,000的向量。 例如,如果Jack在字典中排在第3200位,则x(1)将是一个长度为10,000的向量,其中在第3200位包含1,在其他位置为0。 在某些情况下,输入序列中的单词不会出现在字典中,为此,我们可以使用单独的标记,例如“未知”或其他。
为什么我们需要RNNS? (Why do we need RNNS?)
The next step is to build a neural network to learn the mapping from X to Y. One possibility is to use a standard neural network and has the seven words in our case as input in the form of seven one-hot vectors into a standard neural network followed by some hidden layers and a softmax layer, in the end, to predict whether each word is a person’s name or not by having 0 or 1 as an output. But this approach has two problems, one is that the input can have different lengths for different examples in which case a standard neural network will not work. Secondly, a naive architecture such as this does not share features appearing across the different position of texts. For example, if the network has learned that Jack appearing in the first position of the text is a person’s name, it should also recognise Jack as a person’s name if it appears in any position x_t.
下一步是建立一个神经网络,以学习从X到Y的映射。一种可能性是使用标准神经网络,在我们的案例中,将七个单词作为七个单热向量的形式输入到标准神经网络中。网络最后是一些隐藏层和一个softmax层,最后通过将0或1作为输出来预测每个单词是否是一个人的名字。 但是这种方法有两个问题,一个是对于不同的示例,输入的长度可能不同,在这种情况下,标准的神经网络将无法工作。 其次,像这样的幼稚架构不会共享出现在文本不同位置的功能。 例如,如果网络得知出现在文本第一个位置的杰克是一个人的名字,那么如果它出现在x_t的任何位置,它也应该将杰克识别为一个人的名字。

For these reasons, we need a recurrent neural network where the input to the first layer is the word vector x(1) and an activation function a_0 which can be initiated in several different ways. The output of the first layer will be y(1) indicating whether x(1) is a person’s name or not. The second layer will have input a(1) from the first layer and the second word vector x(2) giving an output y(2) and so on till the last layer or last time step will have an input a(t-1) and x(t) giving an output y(t).
由于这些原因,我们需要一个递归神经网络,其中第一层的输入是单词向量x(1)和激活函数a_0,该函数可以通过几种不同的方式启动。 第一层的输出将是y(1),指示x(1)是否是一个人的名字。 第二层将具有来自第一层的输入a(1)和第二个单词向量x(2)给出输出y(2),依此类推,直到最后一层或最后一个时间步将具有输入a(t-1) )和x(t)给出输出y(t)。
So in a Recurrent Neural Network information flows from left to right and while making a prediction for y(3), information from x(1) and x(2) is also used along with x(3). But one drawback of this type of RNN is that it only considers the words appearing before the word we are trying to make a prediction on and not the words following it. For example, in predicting y_3, we are using x(1), x(2) and x(3) but not x(4), x(5), x(6), x(7) and so on. For example, take a sentence ‘He took Rose to a nice restaurant for dinner’. Here if you try to predict whether Rose is a person’s name using just the fire two words ‘He’ and ‘took’ you will not get good results because the sentence could possibly be ‘He took Rose petals out of the bouquet and spread it on the bed’. So it would be nice to consider the words followed by x(3) such as x(4), x(5), x(6), x(7), etc while predicting y(3). This problem can be solved by using bidirectional RNNs or BRNNs which we will not discuss in this article.
因此,在递归神经网络中,信息从左到右流动,并且在对y(3)进行预测时,还将x(1)和x(2)的信息与x(3)一起使用。 但是这种RNN的一个缺点是,它仅考虑出现在我们要对其进行预测的单词之前的单词,而不考虑其后的单词。 例如,在预测y_3时,我们使用x(1),x(2)和x(3),但不使用x(4),x(5),x(6),x(7)等。 例如,说一句“他把罗斯带到一家不错的饭店吃晚饭”。 在这里,如果您仅用火两个词“ He”和“ take”来预测罗斯是否是一个人的名字,您将不会得到很好的结果,因为这句话可能是“他从花束中拿出玫瑰花瓣并将其摊开”床”。 因此,在预测y(3)时考虑x(3)后跟的单词(如x(4),x(5),x(6),x(7)等)会很好。 此问题可以通过使用双向RNN或BRNN来解决,我们将不在本文中讨论。
基本的RNN架构 (Basic RNN architecture)
Let’s talk about the parameters of our network. In the first layer, we have a(0) coming as input from the left along with x(1) coming from the bottom. To compute a(1), we multiply a(0) by a set of parameters Waa and multiply x(1) with a set parameters Wax and add the two together along with a bias b_a. Next, to compute y^(1), we multiply a(1) by a set of parameters Wya along with a bias b_y. Now, the beauty of RNNs is in the fact that we use the same parameters Wax, Waa, Wya for all time steps. The equations to compute a(t) and y^(t) will be as follows:
让我们谈谈我们网络的参数。 在第一层中,我们有一个(0)从左边开始输入,而x(1)从底部开始输入。 为了计算a(1),我们将a(0)乘以一组参数Waa,然后将x(1)与一组参数Wax相乘,然后将两者与偏差b_a相加。 接下来,为了计算y ^(1),我们将a(1)与一组参数Wya以及偏差b_y相乘。 现在,RNN的优点在于,我们在所有时间步长上都使用相同的参数Wax,Waa和Wya。 计算a(t)和y ^(t)的公式如下:
a(t)=g(W_aa*a(t-1)+W_ax*x(t)+b_a)
a(t)= g(W_aa * a(t-1)+ W_ax * x(t)+ b_a)
y ^(t)=g(W_ya*a(t)+b_y)
y ^(t)= g(W_ya * a(t)+ b_y)
We calculate y^(1), y^(2), y^(3), y^(4) and so on till y^(t) using the above equations. Then, we compare all the y^(t) to the ground truth y(t) to compute the loss which we can backpropagate through our network. Then we add up the losses at each time step which is why we call it backpropagation through time. The loss function is similar to the one used in logistic regression known as the cross entropy loss function. The loss function will be as follows:
我们使用上述公式计算y ^(1),y ^(2),y ^(3),y ^(4)等等,直到y ^(t)。 然后,我们将所有y ^(t)与基本事实y(t)进行比较,以计算可通过网络反向传播的损耗。 然后,我们将每个时间步的损耗加起来,这就是为什么我们称其为时间反向传播。 损失函数类似于逻辑回归中使用的一种,称为交叉熵损失函数。 损失函数如下:
L(t)(y^(t), y(t)) = -y^(t)log y^(t) -(1- y^(t))log(1- y^(t))
L(t)(y ^(t),y(t))= -y ^(t)log y ^(t)-(1- y ^(t))log(1- y ^(t))
Total Loss = ∑ L(t)(y^(t), y(t) )
总损耗= ∑ L(t)(y ^(t),y(t))
Until now we have been dealing with the case where the input length X is equal to the output length Y. But, this might not always be the case. For example, in sentiment classification, we have an input sequence X but Y can be an integer between 1 to 10. For example, say you have a text ‘The movie had a weak plot and the acting was mediocre’ and you wan to give it a rating between 1–5 stars. In this case, we will input one word in each time step without having the output y^(t) and output a single y^ at the last time step or the last word. This is called a many to one architecture. There can also be the case of one to many architectures, for example, music generation where we have only one input a(0) that could be an integer representing the genre of the music or the starting note of the music we want to generate. Then we get the output y^(1) from a(0) which is fed into the next time step along with a(1) to get y^(2) which is again fed in the next time step along with a(2) to generate y^(3) and then y^(4) and so on till the last piece of music y^(t) is generated.
到目前为止,我们一直在处理输入长度X等于输出长度Y的情况。但是,情况并非总是如此。 例如,在情感分类中,我们有一个输入序列X,但Y可以是1到10之间的整数。例如,假设您有一个文字“电影情节薄弱,演技平庸”,而您想给出它的评级介于1到5星之间。 在这种情况下,我们将在每个时间步中输入一个单词,而没有输出y ^(t),并在最后一个时间步或最后一个单词中输出单个y ^。 这称为多对一体系结构。 也可能存在一对多架构的情况,例如音乐生成,其中我们只有一个输入a(0),它可以是代表音乐类型或我们要生成的音乐起始音符的整数。 然后,我们从a(0)获得输出y ^(1),并将其与a(1)一起馈入下一个步骤,以获得y ^(2),再将其与a(2)一起馈入下一个步骤)生成y ^(3),然后生成y ^(4),依此类推,直到生成最后一首音乐y ^(t)。
And there can also be the case of a many to many architectures where the input length X is not equal to the output length Y like in machine translation where we try to translate a french sentence into English using an RNN, the length of the french sentence might be different from the translated English sentence. Here is an overview of the different types of RNN architectures:
甚至在许多体系结构中,输入长度X不等于输出长度Y就像机器翻译中那样,我们尝试使用RNN将法语句子翻译成英语,即法语句子的长度可能与翻译后的英语句子有所不同。 这是不同类型的RNN架构的概述:

消失的梯度问题 (The vanishing gradient problem)
So far what we have discussed can be called as basic RNN algorithms and one of the problems with a basic RNN is that it may run into vanishing gradient problems. For example, let’s say we have a sentence ‘The kid ran for hours in the playground and was exhausted on reaching home’. And then consider the sentence ‘The kids ran for hours in the playground and were exhausted on reaching home’. So to be consistent, it should be ‘kid was’ and ‘kids were’ which shows us that sentences can have long term dependencies which basic RNNs are not able to capture. It means that when we have very deep RNNs with several time steps, it is difficult for the errors associated with the later time steps to affect the computations of the earlier time steps. In this case, the RNN has to remember that ‘kid’ is singular and so later it should use ‘was’ and for ‘kids’ it should use ‘were’. And in English, we see that words can have very long term dependencies which basic RNNs are not able to tackle. Here, the output y^(5) is influenced only by values close to y^(5) which makes it difficult for an output to be strongly influenced by an input which came much earlier in the sequence.
到目前为止,我们所讨论的可以称为基本RNN算法,而基本RNN的问题之一就是它可能会遇到消失的梯度问题。 例如,假设我们有一句话“孩子在操场上跑了几个小时,回家后精疲力竭”。 然后考虑句子“孩子们在操场上跑了几个小时,回家后精疲力竭”。 因此,为了保持一致,应该是“孩子是”和“孩子是”,这向我们表明句子可以具有基本RNN无法捕获的长期依赖性。 这意味着当我们具有多个时间步长的非常深的RNN时,与后续时间步长相关的错误很难影响早期时间步长的计算。 在这种情况下,RNN必须记住“孩子”是单数,因此以后应使用“ was”,对于“孩子”应使用“ were”。 而用英语,我们看到单词可能具有非常长期的依赖性,而基本的RNN无法解决这些依赖性。 此处,输出y ^(5)仅受接近y ^(5)的值影响,这使得输出很难受到序列中更早出现的输入的强烈影响。
On the other hand, we can also run into an exploding gradient problem where our parameters become very large and don’t converge. The exploding gradient problem can be solved by gradient clipping. But generally, vanishing gradients is a more common and much harder problem to solve compared to exploding gradients. Now, let’s talk about GRUs and LSTM that are used to tackle the vanishing gradient problem.
另一方面,我们也可能遇到一个爆炸梯度问题,其中我们的参数变得非常大并且不收敛。 爆炸梯度问题可以通过梯度裁剪解决。 但是通常,消失梯度是比爆炸梯度更普遍且更难解决的问题。 现在,让我们谈谈用于解决消失的梯度问题的GRU和LSTM。
门控循环单元 (Gated Recurrent Units)
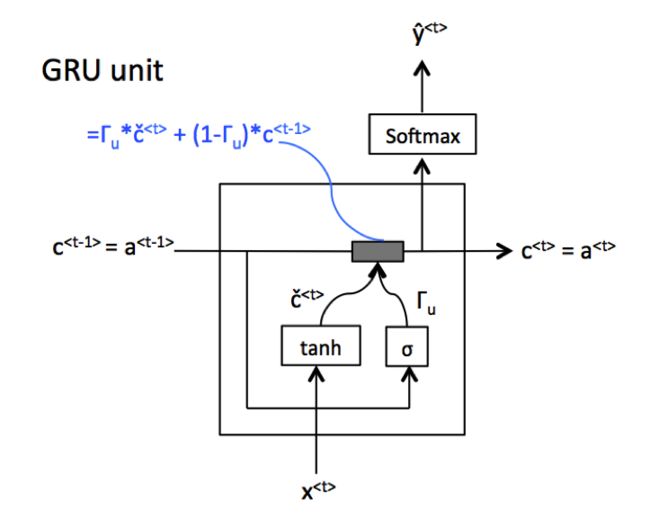
Gated Recurrent Units have a new variable called memory cell or ‘c’ which provides the required memory to RNNs. So in the case of our previous example, the memory cell helps the RNN to remember whether the subject of our sentence which is kid or kids is singular or plural, so that later on in the sentence it can work under the consideration whether the subject is singular or plural. At every time step, we will consider overwriting c(t) with a new variable c ̃(t). And we will compute c ̃(t) using the activation function tanh of the parameter Wc matrix multiplied by the previous memory cell c(t-1) and the current input x(t) plus a bias term b. Now, a very important element of a GRU is the gate Γ_u also known as the update gate which has a value between 0 and 1 because it is calculated using the sigmoid function. But for all practical purposes, Γ_u can be assumed to be either 0 or 1 because the sigmoid function is very close to either 0 or 1 for most range of values.
门控循环单元具有一个称为存储单元或“ c”的新变量,该变量可为RNN提供所需的存储空间。 因此,在我们前面的示例中,存储单元帮助RNN记住我们的句子中主语是kid还是kids的主语是单数还是复数,因此在句子的后面,它可以在考虑主语是单数或复数。 在每个时间步长,我们都将考虑用新变量c ̃(t)覆盖c(t)。 然后,我们将使用参数Wc矩阵的激活函数tanh乘以先前的存储单元c(t-1)和当前输入x(t)加上偏置项b来计算c ̃(t)。 现在,GRU的一个非常重要的元素是门Γ_u,也称为更新门,其值在0到1之间,因为它是使用S型函数计算的。 但是出于所有实际目的,可以将Γ_u假定为0或1,因为对于大多数值范围,S型函数都非常接近0或1。
Then we try to update the value of c(t) using c ̃(t) and the gate Γ_u decides whether we update it or not. So basically, if Γ_u is equal to 1, it means updating the cell memory c(t) with c ̃(t) which in our example could be used to remember that the subject of our sentence is singular that is ‘kid’. Now, for the next few time steps, let’s assume that Γ_u is equal to 0, which means that we are telling the RNN to not update the value of the memory cell and keep setting c(t) = c(t-1) in order to remember that the subject is singular. And when it reaches a point where we need to decide whether the subject is singular or plural, the cell memory will tell us that the subject is singular and we should use ‘was’ instead of ‘were’. If we don’t need to remember whether the subject is singular or plural any further in the sentence, Γ_u can be set to 1 which means that now we can forget the old value and update the memory cell with the new value c ̃(t). The following equation will give a better picture of how GRUs work:
然后,我们尝试使用c ̃(t)更新c(t)的值,然后门Γ_u决定是否更新它。 因此,基本上来说,如果Γ_u等于1,则意味着用c ̃(t)更新单元格内存c(t),在我们的示例中,该内存可以用来记住我们句子的主旨是“孩子”。 现在,在接下来的几个时间步中,假设Γ_u等于0,这意味着我们要告诉RNN不要更新存储单元的值,并继续在其中设置c(t)= c(t-1)。为了记住这个主题是单数的。 当到达需要确定主题是单数还是复数的点时,单元格内存将告诉我们主题是单数,我们应该使用“ was”而不是“ were”。 如果我们不需要记住句子中的主题是单数还是复数,则可以将Γ_u设置为1,这意味着现在我们可以忘记旧值,并用新值c ̃(t )。 以下等式将更好地说明GRU的工作原理:
1. c ̃(t) = tanh(W_c [c(t-1), x(t)] + b_c)
1. c ̃(t)=tanh(W_c [c(t-1),x(t)] + b_c)
2. Γ_u = σ(W_u [ c(t-1), x(t) ] + b_u)
2.Γ_u=σ(W_u [c(t-1),x(t)] + b_u)
3. c(t) = Γ_u*c ̃(t) + (1-Γ_u )*c(t-1)
3. c(t)=Γ_u* c ̃(t)+(1-Γ_u)* c(t-1)
In the case of GRUs, c(t) is the activation value for the next time step a(t), and c(t) can also be passed through a function like softmax to get an output y(t) for the current time step. This is all that we need to know about GRUs, the following diagram will give a better idea of how GRUs work:
对于GRU,c(t)是下一个时间步a(t)的激活值,并且c(t)也可以通过softmax之类的函数传递,以获取当前时间的输出y(t)。步。 这就是我们需要了解的有关GRU的全部信息,下图将更好地了解GRU的工作原理:
长期记忆 (Long Short Term Memory)
LSTM which is short for Long Short Term Memory is another algorithm that can tackle the vanishing gradient problem and help remember long term dependencies in sequences. LSTM can be thought to be a more powerful and general version of GRUs. One major difference is that in LSTMs, a(t) is not equal to c(t). The following equations govern the working of LSTM which we will discuss in details:
LSTM是Long Short Term Memory的缩写,是另一种算法,可以解决梯度消失的问题并帮助记住序列中的长期依赖性。 可以认为LSTM是GRU的更强大和更通用的版本。 一个主要区别是在LSTM中,a(t)不等于c(t)。 下列方程式控制LSTM的工作,我们将详细讨论:
1) c ̃(t) = tanh(W_c [a(t-1), x(t)]+b_c)
1)c ̃(t)=tanh(W_c [a(t-1),x(t)] + b_c)
2) Γ_u = σ(W_u [a(t-1), x(t)]+b_u)
2)Γ_u=σ(W_u [a(t-1),x(t)] + b_u)
3) Γ_f = σ(W_f [a(t-1), x(t)]+b_f)
3)Γ_f=σ(W_f [a(t-1),x(t)] + b_f)
4) Γ_o = σ(W_o [a(t-1), x(t)]+b_o)
4)Γ_o=σ(W_o [a(t-1),x(t)] + b_o)
5) c(t) = Γ_u∗c ̃(t) + Γ_f∗c(t-1)
5)c(t)=Γ_u∗ c ̃(t)+Γ_f∗ c(t-1)
6) a^(t) = Γ_o∗c(t)
6)a ^(t)=Γ_o∗ c(t)
Here you can see that we are using a(t-1) instead of c(t-1). Another difference that we can see is that, we are using Γ_u and Γ_f to calculate c(t) instead of Γ_u and (1-Γ_u). And Γ_f is calculated as the sigmoid of W_f matrix multiplied by [a(t-1), x(t)] plus b_f. So, new value of the memory cell c(t) is update gate, Γ_u element-wise multiplied with c ̃(t) plus forget gate, Γ_f element-wise multiplied by previous value of the memory cell c(t-1). We also have an output gate, Γ_o which is calculated as the sigmoid of W_o matrix multiplied by [a(t-1), x(t)] plus b_o. Also, as mentioned before a(t) is not equal to c(t) rather it is equal to the output gate, Γ_o element-wise multiplied by c(t). So, basically in LSTM, we have three gates: update gate, forget gate and output gate whereas GRUs just have one update gate. The following diagram will give us a better picture of how LSTM works:
在这里您可以看到我们使用的是a(t-1)而不是c(t-1)。 我们可以看到的另一个区别是,我们使用Γ_u和Γ_f而不是Γ_u和(1-Γ_u)来计算c(t)。 然后将Γ_f计算为W_f矩阵的S形乘以[a(t-1),x(t)]加b_f。 因此,存储单元c(t)的新值是更新门,Γ_u元素方式乘以c ̃(t)加上忘记门,Γ_f元素方式乘以存储单元c(t-1)的先前值。 我们还有一个输出门Γ_o,它的计算公式为W_o矩阵的S形乘以[a(t-1),x(t)]加b_o。 同样,如前所述,a(t)不等于c(t)而是等于输出门,Γ_o逐元素乘以c(t)。 因此,基本上在LSTM中,我们有三个门:更新门,忘记门和输出门,而GRU仅具有一个更新门。 下图将使我们更好地了解LSTM的工作方式:

Now, imagine having a bunch of these LSTM units connected in parallel. Each unit will have an input x(t) like x(1), x(2), x(3), x(4) and so on and the output a(t) of a cell will be the input c(t+1) of the next adjacent cell. And if we set the forget and the update gate properly, we can have a certain value c(1) pass all the way till c(6) without being altered so that c(1) = c(6). And in our previous example sentence, ‘The kids ran for hours in the playground and were exhausted on reaching home’ the information that the subject is plural can be stored in the memory cell c(2) of the unit taking ‘kids’ as input just after the unit that takes ‘The’ as input. Then it can be transferred all the way till the memory cell c(10) of the unit taking ‘and’ as input such that c(10) = c(3) so that we get the desired output for y(10) that should be ‘were’. This is why LSTM and GRUs are very good at remembering long term dependencies. The following diagram shows how LSTM units are connected to each other:
现在,假设将这些LSTM单元束并联连接。 每个单位都有一个输入x(t),例如x(1),x(2),x(3),x(4)等,一个像元的输出a(t)将是输入c(t +1)。 而且,如果我们正确设置了“忘记”和“更新”门,则可以使某个值c(1)一直传递到c(6),而无需更改,这样c(1)= c(6)。 在我们之前的例句中,“孩子们在操场上跑了几个小时,精疲力尽,回家了”,可以将多个对象存储在单元的存储单元c(2)中,以“孩子”作为输入。在以“ The”作为输入单位的后面。 然后可以一直传输到单元的存储单元c(10)以“和”作为输入,这样c(10)= c(3),这样我们就可以得到y(10)的期望输出是“被”。 这就是LSTM和GRU非常擅长记住长期依赖关系的原因。 下图显示了LSTM单元如何相互连接:

LSTM与GRU (LSTM vs GRUs)
When should we use a GRU and when should we use an LSTM? There is no definite answer to this and even though we discussed GRUs first, LSTM came much earlier in practise. And then GRUs were invented as a simpler version of the more complicated LSTM model. GRUs are simpler models and computationally less intensive compared to LSTM. So, we can build much larger networks with GRUs although LSTM is more powerful and a lot more effective. Bur more importantly, neither of the two is a universally superior algorithm and it really depends on the data we are working with and the problem we are trying to solve.
什么时候应该使用GRU,什么时候应该使用LSTM? 对此没有明确的答案,即使我们首先讨论了GRU,LSTM在实践中也要早得多。 然后,GRU被发明为更复杂的LSTM模型的简化版本。 与LSTM相比,GRU是更简单的模型,并且计算强度较低。 因此,尽管LSTM功能更强大且效率更高,但我们可以使用GRU构建更大的网络。 更重要的是,这两者都不是通用的高级算法,它实际上取决于我们正在使用的数据以及我们要解决的问题。
This is everything that I wanted to or could cover in this article. Hope you were able to get a good idea about how sequence models work and its applications in the real world. I would like to thank Dr. Andrew Ng for his course on deep learning specialisation without which I wouldn’t be able to write this article. I am working on an article where I will demonstrate how we can implement some of these algorithms in python and create some useful applications. I am also working on some articles on the beam search algorithm that can be used to improve machine translation and image captioning and bleu score that is used to check the performance of machine translation and image captioning. So, stay tuned!
这就是我想要或可能在本文中介绍的所有内容。 希望您能够对序列模型如何工作及其在现实世界中的应用有一个很好的了解。 我要感谢吴安德(Andrew Ng)博士提供的深度学习专业课程,否则我将无法写这篇文章。 我正在写一篇文章,我将演示如何在python中实现其中的某些算法并创建一些有用的应用程序。 我还在研究有关波束搜索算法的一些文章,这些文章可用于改善机器翻译和图像字幕以及用于检查机器翻译和图像字幕性能的bleu分数。 所以,请继续关注!
翻译自: https://towardsdatascience.com/simplifying-grus-lstm-and-rnns-in-general-8f0715c20228
rnn lstm gru