变分推断(variational inference)
变分推断
- 总体解释
-
- ELOB 证据下界
- 平均场推断
- ------------------------------------------------------------------------------
- 对观测值的边缘分布进行分解
-
- 分解概率分布(平均场理论)
- Mean field 下的最优closed solution:
总体解释
把所有潜在变量和参数组成的集合记作 Z = { Z 1 , Z 2 , . . . , Z N } \mathbf Z=\{\mathbf Z_1,\mathbf Z_2,...,\mathbf Z_N\} Z={Z1,Z2,...,ZN}.观测变量的集合记作 X \mathbf X X.
一般来说条件分布(后验分布) p ( Z ∣ X ) = p ( Z , X ) / P ( X ) p(\mathbf Z|\mathbf X)=p(\mathbf Z, \mathbf X)/P( \mathbf X) p(Z∣X)=p(Z,X)/P(X)比较难求,因为边缘分布 P ( X ) P( \mathbf X) P(X)需要从联合分布 p ( Z , X ) p(\mathbf Z, \mathbf X) p(Z,X)进行积分,所以变分推断就是使用一个分布 q ( Z ) q(\mathbf Z) q(Z)来直接逼近这个条件分布,逼近的度量采用KL 散度, 即目标就是优化函数 q ( Z ) q(\mathbf Z) q(Z), 使得 K L ( q ( Z ) ∣ ∣ p ( Z ∣ X ) ) KL(q(\mathbf Z)||p(\mathbf Z|\mathbf X)) KL(q(Z)∣∣p(Z∣X))最小。一般正常情况下,优化变量是一个向量时,只要使用梯度(微分)为0,或者使用KTT等优化方法就可以得到最优或者是次优解。 当这里,因为优化的是一个函数,所以需要求所谓的变分,而不是微分。 进一步,为了求解空间小一些,使用平均场理论,假设联合分布 q ( Z ) q(\mathbf Z) q(Z)是通过每个独立分量的分布联合的,也就化成了连乘。(https://zhuanlan.zhihu.com/p/91640654)
ELOB 证据下界
想要使用变分推断,必须要得到ELOB的表达式,
有两种方法可以推出ELOB(https://xyang35.github.io/2017/04/14/variational-lower-bound/),
- 可以直接通过对KL散度的变形得到,这里要使用 q ( Z ) q(Z) q(Z)作为积分,因为proposed 的分布 q ( Z ) q(Z) q(Z)一般会简单,比如采用高斯或者伯努利,所以用 q ( Z ) q(Z) q(Z)来算期望会更容易。

由于 K L ≥ 0 KL\ge 0 KL≥0, 所以 L L L 就是 l o g p ( X ) logp(X) logp(X)的下界,也就是lower bound 的来源了。
- 可以使用Jensen’s inequality 进行推导
从观测变量X的边缘分布出发,进行配凑
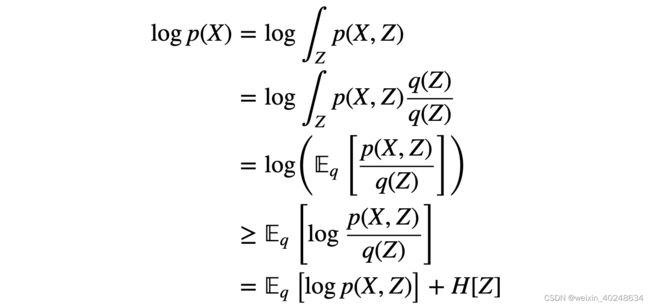
也可以得到ELOB energy functional L = E q [ log p ( X , Z ) q ( Z ) ] L=E_q[\log\frac{p(X,Z)}{q(Z)}] L=Eq[logq(Z)p(X,Z)]
平均场推断
得到ELOB 的表达式L之后,后面就变成了变分优化问题,即 找个函数 q ( Z ) q(Z) q(Z), 使得L最大
m a x q L = m a x q E q [ log p ( X , Z ) q ( Z ) ] max_q L=max_q E_q[\log\frac{p(X,Z)}{q(Z)}] maxqL=maxqEq[logq(Z)p(X,Z)]
如果不指定 q ( Z ) q(Z) q(Z)所在的分布家族(e.g.高斯分布), 直接搜索 q q q是很困难的,所以如果使用最简单的概率图模型,即没有边的概率图,in other word, Z = ( z 1 , . . . , z n ) Z=(z_1,...,z_n) Z=(z1,...,zn)都相互独立,但不要求同分布。
这就有了很多VAE 中的公式,上来就是
q ( Z ) = Π i q i ( z i ) q(Z)=\Pi_i q_i(z_i) q(Z)=Πiqi(zi)
将其代入到L中, 令 p ~ ( x ) = p ( X , Z ) \tilde p(x)=p(X,Z) p~(x)=p(X,Z)。


最后得到每个分量解析表达式,j=1,2,…m=n
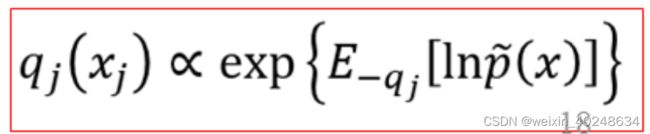
得到最后的分布
q ( Z ) = Π i q i ( z i ) q(Z)=\Pi_i q_i(z_i) q(Z)=Πiqi(zi)
前面的最大化问题会有最优解是由凸性保证。
最后推断的时候就用 q ( Z ) q(Z) q(Z) 来替代 p ( Z ∣ X ) p(Z|X) p(Z∣X)了
------------------------------------------------------------------------------
对观测值的边缘分布进行分解
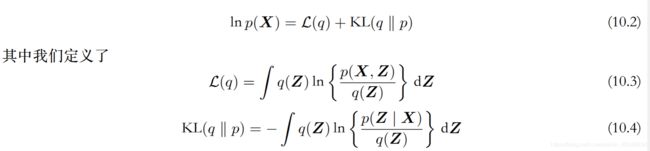 这里前一项 L ( q ) \mathcal L(q) L(q)为Evidence lower Bound(ELOB)。 第二项为KL散度。
这里前一项 L ( q ) \mathcal L(q) L(q)为Evidence lower Bound(ELOB)。 第二项为KL散度。
下面的核心是对ELOB objective function 求上界。 当其越大,KL散度越小,代表拟合的越好,当KL=0 时,表示两个分布完全相等。
这与我们关于EM的讨论的唯一的区别是参数向量不再出现,因为参数现在是随机变量,被整合到了 Z \mathbf Z Z中.
分解概率分布(平均场理论)
为了容易得到迭代表达式,这里假设 联合分布可以分解为以下:
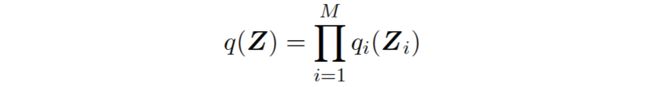 其中 q i ( Z i ) q_i(\mathbf Z_i) qi(Zi)不要求相同分布, i = 1 , 2 , . . . , N i=1,2,..., N i=1,2,...,N. 变分推断的这个分解的形式对应于物理学中的一个近似框架,叫做平均场理论(mean field theory). 将上式代入到(10.3), q j ( Z j ) q_j(\mathbf Z_j) qj(Zj)记作 q j q_j qj.
其中 q i ( Z i ) q_i(\mathbf Z_i) qi(Zi)不要求相同分布, i = 1 , 2 , . . . , N i=1,2,..., N i=1,2,...,N. 变分推断的这个分解的形式对应于物理学中的一个近似框架,叫做平均场理论(mean field theory). 将上式代入到(10.3), q j ( Z j ) q_j(\mathbf Z_j) qj(Zj)记作 q j q_j qj.
 第二个等式,只考虑第 j j j个分量的显式形式, 第一部分 是将多重积分的 q j q_j qj提了出来,第二部分是将除了 j j j以外的元素都放在const 。
第二个等式,只考虑第 j j j个分量的显式形式, 第一部分 是将多重积分的 q j q_j qj提了出来,第二部分是将除了 j j j以外的元素都放在const 。
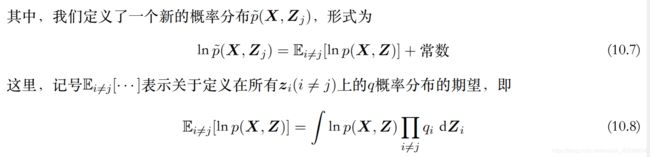

Mean field 下的最优closed solution:
通过Evidence lower Bound(ELOB) 目标函数的最小化 来间接获得最优解的表达式 (https://xyang35.github.io/2017/04/14/variational-lower-bound/)
ln q j ∗ ( Z j ) = E q 1 ( Z 1 ) , q 2 ( Z 2 ) , ⋯ , q N ( Z N ) / q j ( Z j ) [ ln p ( X , Z ) ] + c o n s t , = ∫ Z 1 , Z 2 , . . . , Z N / Z j ln p ( X , Z ) ∏ i ≠ j ( q i ( Z i ) d Z i ) , j = 1 , 2 , 3 , . . . , N \operatorname{ln}q^*_j(\mathbf Z_j)=\mathbb E_{q_1(\mathbf Z_1),q_2(\mathbf Z_2),\cdots,q_N(\mathbf Z_N)/q_j(\mathbf Z_j)}[\text{ln}p(\mathbf X, \mathbf Z)]+const,\\ =\int_{Z_1,Z_2,...,Z_N/Z_j}\text{ln}p(\mathbf {X,Z})\prod_{i\neq j}(q_i(\mathbf Z_i)d\mathbf Z_i), \quad j=1,2,3,... ,N lnqj∗(Zj)=Eq1(Z1),q2(Z2),⋯,qN(ZN)/qj(Zj)[lnp(X,Z)]+const,=∫Z1,Z2,...,ZN/Zjlnp(X,Z)i=j∏(qi(Zi)dZi),j=1,2,3,...,N
迭代更新 q j ∗ ( Z j ) q^*_j(\mathbf Z_j) qj∗(Zj),从 j = 1 j=1 j=1 开始,得到 q 1 ∗ ( Z 1 ) q^*_1(\mathbf Z_1) q1∗(Z1) 代入到式子中用于更新 q 2 ∗ ( Z 2 ) q^*_2(\mathbf Z_2) q2∗(Z2) ,直到收敛(算法保证收敛,因为 − ln q j ∗ ( Z j ) -\operatorname{ln}q^*_j(\mathbf Z_j) −lnqj∗(Zj)关于每个因子 q i ( Z i ) q_i(\mathbf Z_i) qi(Zi)是一个凸函数, 最大化上凸(凹)即最下化下凸(凸))。
迭代完成后,通过下式即可以得到逼近的分布表达式。
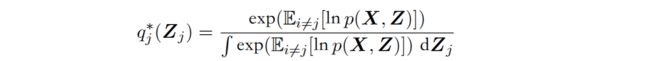
PRML
bilibili教程