常用的损失函数合集
目录
一、什么是损失函数?
二、为什么需要损失函数?
三、损失函数通常使用的位置
四、损失函数的分类
五、常用的损失函数
1、回归损失(针对连续型变量)
1.L1 Loss也称为Mean Absolute Error,即平均绝对误差(MAE)
2.L2 Loss 也称为Mean Squred Error,即均方差(MSE)
3. Smooth L1 Loss 即平滑的L1损失(SLL)
锚框损失(参考讲解会更详细)
4.IoU Loss 即交并比损失
5.GIoU Loss 即泛化的IoU损失(考虑重叠面积)
6.DIoU Loss 即距离IoU损失(考虑重叠面积,中心点距离)
7.CIoU Loss 即完整IoU损失(考虑重叠面积,中心点距离,宽高比)
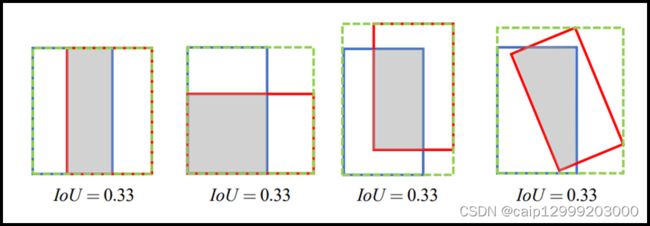
8.F-EIoU Loss
9.CDIoU Loss
2、分类损失(针对离散型变量)
1.1 Entropy即“熵”
1.2 Cross Entropy 交叉熵
2.K-L Divergence 即KL散度(相对熵)
3. Hinge 损失函数(SVM)
4.Dice Loss 即骰子损失
5.Focal Loss即 焦点损失
6.Tversky loss
六、如何选择损失函数
七、总结
八、参考链接
一、什么是损失函数?
| 简单的理解就是每一个样本经过模型后会得到一个预测值,然后得到的预测值和真实值的差值就成为损失(当然损失值越小证明模型越是成功),我们知道有许多不同种类的损失函数,这些函数本质上就是计算预测值和真实值的差距的一类型函数,然后经过库(如pytorch,tensorflow等)的封装形成了有具体名字的函数。 机器学习中,损失函数是代价函数的一部分,而代价函数则是目标函数的一种类型。 损失函数(Loss Function): 用于定义单个训练样本与真实值之间的误差; 代价函数(Cost Function): 用于定义单个批次/整个训练集样本与真实值之间的误差; 目标函数(Objective Function): 泛指任意可以被优化的函数。 损失函数用来评估模型预测值与真实值的偏离程度。通常情况下,损失函数选取的越好,模型的性能越好。不同模型间采用的损失函数一般也不一样。最常用的最小化损失函数的算法便是“梯度下降”(Gradient Descent)。 |
二、为什么需要损失函数?
| 我们上文说到损失函数是计算预测值和真实值的一类函数,而在机器学习中,我们想让预测值无限接近于真实值,所以需要将差值降到最低(在这个过程中就需要引入损失函数)。而在此过程中损失函数的选择是十分关键的,在具体的项目中,有些损失函数计算的差值梯度下降的快,而有些下降的慢,所以选择合适的损失函数也是十分关键的。 |
三、损失函数通常使用的位置
| 在机器学习中,我们知道输入的feature(或称为x)需要通过模型(model)预测出y,此过程称为向前传播(forward pass),而要将预测与真实值的差值减小需要更新模型中的参数,这个过程称为向后传播(backward pass),其中我们损失函数(lossfunction)就基于这两种传播之间,起到一种有点像承上启下的作用,承上指:接収模型的预测值,启下指:计算预测值和真实值的差值,为下面反向传播提供输入数据。 |
四、损失函数的分类
| 损失函数的分类方式有多种,按照是否添加正则项可分为经验风险损失函数和结构风险损失函数。按照任务类型分类,可分为两种:回归损失(针对连续型变量)和分类损失(针对离散型变量)。 |
五、常用的损失函数
1、回归损失(针对连续型变量)
1.L1 Loss也称为Mean Absolute Error,即平均绝对误差(MAE) |
||||||||
|
平均绝对误差(MAE)是另一种常用的回归损失函数,它是目标值与预测值之差绝对值和的均值,表示了预测值的平均误差幅度,而不需要考虑误差的方向(注:平均偏差误差MBE则是考虑的方向的误差,是残差的和),范围是0到∞。 (1)图像:
(2)性能:
(3)代码实现
|


2.L2 Loss 也称为Mean Squred Error,即均方差(MSE) |
||||||||
|
即平滑的L1损失(SLL),出自Fast RCNN 。SLL通过综合L1和L2损失的优点,在0点处附近采用了L2损失中的平方函数,解决了L1损失在0点处梯度不可导的问题,使其更加平滑易于收敛。此外,在|x|>1的区间上,它又采用了L1损失中的线性函数,使得梯度能够快速下降。 (1)图像:
(2)性能:
(3)代码实现
|


3. Smooth L1 Loss 即平滑的L1损失(SLL) |
||||||||||
|
均方误差(Mean Square Error,MSE)是回归损失函数中最常用的误差,它是预测值f(x)与目标值y之间差值平方和的均值。出自Fast RCNN 。 (1)图像:
(2)性能:
(3)应用的案例: Faster RCNN目标检测。 (4)代码实现
|


锚框损失(参考讲解会更详细) |
|||||||||||||||||||
| 理论参考: 【YOLO v4 相关理论】Bounding Box regression loss: IoU Loss、GIoU Loss、DIoU Loss、CIoU Loss_满船清梦压星河HK的博客-CSDN博客 极市开发者平台-计算机视觉算法开发落地平台 代码参考: 【深度学习】锚框损失 IoU Loss、GIoU Loss、 DIoU Loss 、CIoU Loss、 CDIoU Loss、 F-EIoU Loss_XD742971636的博客-CSDN博客_ciou loss论文 IoU、GIoU、DIoU、CIoU损失函数的那点事儿 - 知乎 深度学习笔记(十三):IOU、GIOU、DIOU、CIOU、EIOU、Focal EIOU、alpha IOU损失函数分析及Pytorch实现_ZZY_dl的博客-CSDN博客_eiou |
|||||||||||||||||||
|
|||||||||||||||||||
4.IoU Loss 即交并比损失论文:https://arxiv.org/pdf/1608.01471.pdf 即交并比损失,出自UnitBox,由旷视科技于ACM2016首次提出。常规的Lx损失中,都是基于目标边界中的4个坐标点信息之间分别进行回归损失计算的。因此,这些边框信息之间是相互独立的。然而,直观上来看,这些边框信息之间必然是存在某种相关性的。如下图(a)-(b)分别所示,绿色框代表Ground Truth,黑色框代表Prediction,可以看出,同一个Lx分数,预测框与真实框之间的拟合/重叠程度并不相同,显然重叠度越高的预测框是越合理的。IoU损失将候选框的四个边界信息作为一个整体进行回归,从而实现准确、高效的定位,具有很好的尺度不变性。为了解决IoU度量不可导的现象,引入了负Ln范数来间接计算IoU损失。
(1) 性能
(2)应用场景:
(3)代码实现: |
|||||||||||||||||||
5.GIoU Loss 即泛化的IoU损失(考虑重叠面积)论文:https://arxiv.org/pdf/1902.09630.pdf
即泛化的IoU损失,全称为Generalized Intersection over Union,由斯坦福学者于CVPR2019年发表的这篇论文 中首次提出。上面我们提到了IoU损失可以解决边界框坐标之间相互独立的问题,考虑这样一种情况,当预测框与真实框之间没有任何重叠时,两个边框的交集(分子)为0,此时IoU损失为0,因此IoU无法算出两者之间的距离(重叠度)。另一方面,由于IoU损失为零,意味着梯度无法有效地反向传播和更新,即出现梯度消失的现象,致使网络无法给出一个优化的方向。此外,如下图所示,IoU对不同方向的边框对齐也是一脸懵逼的,所计算出来的值都一样。
为了解决以上的问题,如下图公式所示,GIoU通过计算任意两个形状(这里以矩形框为例)A和B的一个最小闭合凸面C,然后再计算C中排除掉A和B后的面积占C原始面积的比值,最后再用原始的IoU减去这个比值得到泛化后的IoU值。
GIoU具有IoU所拥有的一切特性,如对称性,三角不等式等。GIoU ≤ IoU,特别地,0 ≤ IoU(A, B) ≤ -1, 而0 ≤ GIoU(A, B) ≤ -1;当两个边框的完全重叠时,此时GIoU = IoU = 1. 而当 |AUB| 与 最小闭合凸面C 的比值趋近为0时,即两个边框不相交的情况下,此时GIoU将渐渐收敛至 -1. 同样地,我们也可以通过一定的方式去计算出两个矩形框之间的GIoU损失,具体计算步骤也非常简单,详情参考原 (1)性能
(2)代码实现: |
|||||||||||||||||||
6.DIoU Loss 即距离IoU损失(考虑重叠面积,中心点距离)论文:https://arxiv.org/pdf/1911.08287.pdf 即距离IoU损失,全称为Distance-IoU loss,由天津大学数学学院研究人员于AAAI2020所发表的这篇论文中首次提出。上面我们谈到GIoU通过引入最小闭合凸面来解决IoU无法对不重叠边框的优化问题。但是,其仍然存在两大局限性:边框回归还不够精确 & 收敛速度缓慢 。考虑下图这种情况,当目标框完全包含预测框时,此时GIoU退化为IoU。显然,我们希望的预测是最右边这种情况。因此,作者通过计算两个边框之间的中心点归一化距离,从而更好的优化这种情况。
下图表示的是GIoU损失(第一行)和DIoU损失(第二行)的一个训练过程收敛情况。其中绿色框为目标边框,黑色框为锚框,蓝色框和红色框则分别表示使用GIoU损失和DIoU损失所得到的预测框。可以发现,GIoU损失一般会增加预测框的大小使其能和目标框重叠,而DIoU损失则直接使目标框和预测框之间的中心点归一化距离最小,即让预测框的中心快速的向目标中心收敛。
左图给出这三个IoU损失所对应的计算公式。对于DIoU来说,如图右所示,其惩罚项由两部分构成:分子为目标框和预测框中心点之间的欧式距离;分母为两个框最小外接矩形框的两个对角线距离。因此, 直接优化两个点之间的距离会使得模型收敛得更快,同时又能够在两个边框不重叠的情况下给出一个优化的方向。
(1)性能
(2)代码实现: |
|||||||||||||||||||
7.CIoU Loss 即完整IoU损失(考虑重叠面积,中心点距离,宽高比)被与DIoU同一篇的论文提出:https://arxiv.org/pdf/1911.08287.pdf 即完整IoU损失,全称为Complete IoU loss,与DIoU出自同一篇论文。上面我们提到GIoU存在两个缺陷,DIoU的提出解决了其实一个缺陷,即收敛速度的问题。而一个好的边框回归损失应该同时考虑三个重要的几何因素,即重叠面积(Overlap area)、中心点距离(Central point distance)和高宽比(Aspect ratio)。GIoU考虑到了重叠面积的问题,DIoU考虑到了重叠面积和中心点距离的问题,CIoU则在此基础上进一步的考虑到了高宽比的问题。
CIoU的计算公式如下所示,可以看出,其在DIoU的基础上加多了一个惩罚项αv。其中α为权重为正数的重叠面积平衡因子,在回归中被赋与更高的优先级,特别是在两个边框不重叠的情况下;而v则用于测量宽高比的一致性。
(1)性能
(2)代码实现: |
|||||||||||||||||||
8.F-EIoU Loss论文:https://yfzhang114.github.io/files/cvpr_final.pdf Focal and Efficient IoU Loss是由华南理工大学学者最近提出的一篇关于目标检测损失函数的论文,文章主要的贡献是提升网络收敛速度和目标定位精度。目前检测任务的损失函数主要有两个缺点:(1)无法有效地描述边界框回归的目标,导致收敛速度慢以及回归结果不准确(2)忽略了边界框回归中不平衡的问题。 F-EIou loss首先提出了一种有效的交并集(IOU)损失,它可以准确地测量边界框回归中的重叠面积、中心点和边长三个几何因素的差异:
其次,基于对有效样本挖掘问题(EEM)的探讨,提出了Focal loss的回归版本,以使回归过程中专注于高质量的锚框:
最后,将以上两个部分结合起来得到Focal-EIou Loss:
其中,通过加入每个batch的权重和来避免网络在早期训练阶段收敛慢的问题。 (1)代码实现: |
|||||||||||||||||||
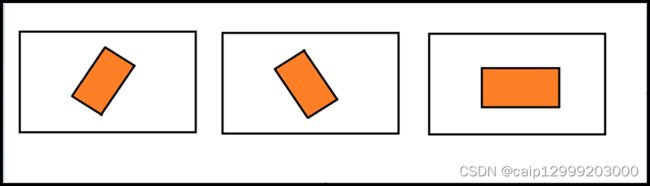
9.CDIoU Loss论文:https://arxiv.org/pdf/2103.11696.pdf Control Distance IoU Loss是由同济大学学者提出的,文章的主要贡献是在几乎不增强计算量的前提下有效提升了边界框回归的精准度。目前检测领域主要两大问题:(1)SOTA算法虽然有效但计算成本高(2)边界框回归损失函数设计不够合理。
文章首先提出了一种对于Region Propasl(RP)和Ground Truth(GT)之间的新评估方式,即CDIoU。可以发现,它虽然没有直接中心点距离和长宽比,但最终的计算结果是有反应出RP和GT的差异。计算公式如下:
对比以往直接计算中心点距离或是形状相似性的损失函数,CDIoU能更合理地评估RP和GT的差异并且有效地降低计算成本。然后,根据上述的公式,CDIoU Loss可以定义为:
通过观察这个公式,可以直观地感受到,在权重迭代过程中,模型不断地将RP的四个顶点拉向GT的四个顶点,直到它们重叠为止,如下图所示:
|







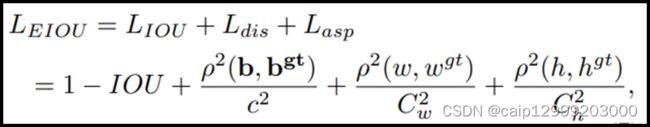







2、分类损失(针对离散型变量)
1.1 Entropy即“熵”更详细的了解: (1)视频:“交叉熵”如何做损失函数?打包理解“信息量”、“比特”、“熵”、“KL散度”、“交叉熵”_哔哩哔哩_bilibili (2)博客: 交叉熵损失函数原理详解_Cigar丶的博客-CSDN博客_交叉熵损失函数交叉熵损失函数原理详解_Cigar丶的博客-CSDN博客_交叉熵损失函数交叉熵损失函数原理详解_Cigar丶的博客-CSDN博客_交叉熵损失函数 【深度学习】损失函数详解_LogosTR_的博客-CSDN博客_损失函数 1.2 Cross Entropy 交叉熵交叉熵损失函数的标准形式如上:(公式中x表示样本,y表示实际的标签,a表示预测的输出, n表示样本总数量。
交叉熵(cross-entropy)刻画了两个概率分布之间的距离,更适合用在分类问题上,因为交叉熵表达预测输入样本属于某一类的概率。 1、二分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):
2、多分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):
(1)性能:
(2)代码实现
别名: 网址:【常见的损失函数总结】_菜菜雪丫头的博客-CSDN博客_常见损失函数
|




2.K-L Divergence 即KL散度(相对熵) |
|||||||||||||
|
机器学习中,往往存在两种分布,一个是数据样本的真实分布,分布由原始数据决定;另一个是模型预测的分布,KL散度来衡量以上两个分布的差异程度。其中P数据样本概率分布, Q为模型预测的概率分布。当P和Q的分布越接近, DKL的值越小,表明模型对原始数据分布特点预测的越准。 (1)性能:
(2)代码实现:
|

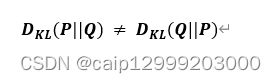
3. Hinge 损失函数(SVM) |
| 在机器学习中,hinge loss是一种损失函数,它通常用于"maximum-margin"的分类任务中,如支持向量机(SVM)。数学表达式为:
|
4.Dice Loss 即骰子损失即骰子损失,出自V-Net,是一种用于评估两个样本之间相似性度量的函数,取值范围为0~1,值越大表示两个值的相似度越高。 |
5.Focal Loss即 焦点损失焦点损失,出自何凯明的《Focal Loss for Dense Object Detection》,出发点是解决目标检测领域中one-stage算法如YOLO系列算法准确率不高的问题。作者认为样本的类别不均衡(比如前景和背景)是导致这个问题的主要原因。比如在很多输入图片中,我们利用网格去划分小窗口,大多数的窗口是不包含目标的。如此一来,如果我们直接运用原始的交叉熵损失,那么负样本所占比例会非常大,主导梯度的优化方向,即网络会偏向于将前景预测为背景。即使我们可以使用OHEM(在线困难样本挖掘)算法来处理不均衡的问题,虽然其增加了误分类样本的权重,但也容易忽略掉易分类样本。而Focal loss则是聚焦于训练一个困难样本的稀疏集,通过直接在标准的交叉熵损失基础上做改进,引进了两个惩罚因子,来减少易分类样本的权重,使得模型在训练过程中更专注于困难样本。 |
6.Tversky lossTversky loss,发表于CVPR 2018上的一篇《Tversky loss function for image segmentation using 3D fully convolutional deep networks》文章,是根据Tversky 等人于1997年发表的《Features of Similarity》文章所提出的Tversky指数所改造的。Tversky系数主要用于描述两个特征(集合)之间的相似度。 |

六、如何选择损失函数
Pytorch-工业应用中如何选取合适的损失函数(MAE、MSE、Huber)_tt姐whaosoft的博客-CSDN博客_mse pytorch
七、总结
本文章从整理了计算机视觉常用的损失函数,分别从出处、原理、优缺点和代码实现几个方面进行编写;由于损失函数变种太多,所以这里只提供了一部分,当然弄懂了这一部分,对于另外的大部分的理解也就差不多了。后续,我会总结自己在项目中见到或用过的损失,把他们归类展示,并且尝试分析一下什么场景应选择哪些损失函数训练。如果你觉得有用的话,请点个,谢谢。
八、参考链接
1、文章主要参考的链接有:
CNN损失函数学习(最全)_张小波的博客-CSDN博客_cnn的损失函数(这里的L1和L2优缺点评价弄反了)
【深度学习】损失函数详解_LogosTR_的博客-CSDN博客_损失函数
损失函数loss大总结_watersink的博客-CSDN博客_loss损失函数
【常见的损失函数总结】_菜菜雪丫头的博客-CSDN博客_常见损失函数
TensorFlow2损失函数大全_bigcindy的博客-CSDN博客_tensorflow二分类损失函数
2、个别损失的参考链接
2.1 MAE损失参考链接:
深度学习_损失函数(MSE、MAE、SmoothL1_loss...)_ClFH的博客-CSDN博客_mse损失函数
tensorflow中的loss函数总结_fkyyly的博客-CSDN博客_tensorflow的loss
2.2 K-L Divergence 即KL散度(相对熵)参考链接:
通俗理解交叉熵和KL散度(包括标签平滑的pytorch实现)_栋次大次的博客-CSDN博客_kl loss pytorch
使用tensorflow2.x解决离散分布之间的KL散度_InceptionZ的博客-CSDN博客_kl tensorflow