文本生成 | retrieval augmentation(进阶篇Atlas)
每天给你送来NLP技术干货!
来自:NLP日志
提纲
1 简介
2 模型架构
3 实验设计
3.1 损失函数
3.2 预训练任务
3.3 Efficient retriever fine-tuning
4 实验结论
5 分析
5.1 可解释性
5.2 可更新性
6 总结
参考文献
1 简介
之前写过若干篇retrieval augmentation的文章,对几种当下较为火热的retrieval augmentation的方法做了详细介绍,进而清晰地知道这种方法的价值跟优势所在。这里介绍最近看到的一篇今年八月份由Meta AI提出的retrieval augmentation的论文,Atlas,Atlas是一个经过精心设计和预训练的检索增强语言模型,可以通过少量的训练样本学习到特定任务的知识,以较少的模型参数达到媲美大规模语言模型的效果。这篇论文对于retrieval augmentation的损失函数,预训练,finetune等诸多设计细节有更加深入的研究,并验证了检索增强模型的可解释行,可更新性等诸多性能,能够帮助大家更深入的了解retrieval augmentation这种类型额度方法。
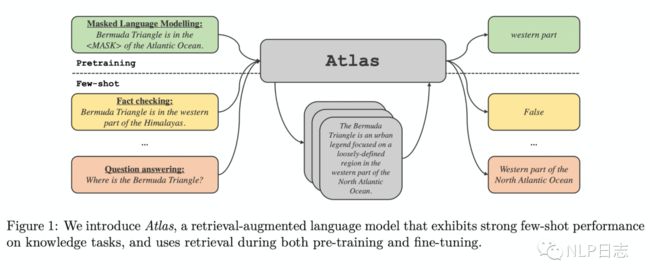
图1: Atlas框架
2 模型架构
Atlas分为检索模块跟语言模型两部分,前者用于从语料库中检索并返回跟query最接近的top-K个相关文档,为后续的语言模型显示引入知识。后者则用于将query跟检索模块返回的相关文档一同输入到语言模型中,生成最终的结果。
Atlas的检索模块是基于Contriever的,一种依赖于连续稠密向量的信息检索方法,它包括两个独立的transformer编码器,分别负责对query跟语料库中的文档进行编码,将最后一层隐状态输出通过average pooling得到相应的query或者文档的句向量,再通过句向量的点积操作来计算query跟文档之间的相似度分数。基于稠密向量检索的方式的优势在于它的编码器在没有文档标注的情况下可以进行训练。
Atlas的语言模型采用了T5的encoder-decoder模型结构,采用跟FiD同样的生成方式,利用encoder对多个query+文档的输入进行编码,利用decoder的attention模块融合多个文档的信息去生成答案。
3 实验设计
3.1 损失函数
关于训练检索模块的损失函数,损失函数应该要充分利用好语言模型的能力,如果语言模型发现一个文档对于生成结果特别有用,那么检索器的训练目标应该要鼓励检索器赋予这个文档更高的权重。这种思路可以只通过query跟最终的生成结果来训练检索模块来实现(不需要针对每个query,去标注在这个query下是否应该被召回)。基于这种想法,论文设计了以下四种不同的损失函数。
a) Attention Distillation(ADist)
这种loss是基于语言模型的注意力得分,在decoder的cross attention模块中计算的文档跟输出之间的得分可以被用来充当每个文档的重要性,对于每个文档,计算它的每个token在语言模型decoder的每层网络,每个attention的head的注意力得分的平均值作为该文档的重要性得分,进而得到多个文档的注意力得分分布pATTN,通过最小化检索器返回的得分pRETR跟语言模型的注意力得分分布pATTN,之间的KL散度来优化模型,也就是希望检索返回的得分分布pRETR尽可能的接近pATTN。
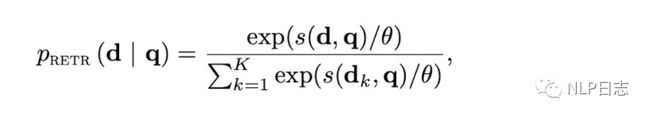
b) End-to-end training of Multi-Document Reader and Retriever(EMDR2)
这种loss的设计将检索返回的文档作为隐变量,q是给定的query,a是最终的生成结果,对应的检索器的loss由语言模型得分跟检索得分的乘积的对数组成,但是通过固定语言模型的参数实现只优化检索器的参数。之前提及的FiD,RAG等检索增强模型的联合训练使用的基本都是这种类型的损失函数。

c) Perplexity Distillation(PDist)
上述a)的改进版,将a中的目标分布由pATTN改成语言模型的得分经过softmax操作后的概率分布,然后训练目标是最小化pATTN跟改进版的概率分布,进而去优化检索器的参数。

d) Leave-one-out Perplexity Distillation(LOOP)
上述c)的改进版,将对应的语言模型的概率得分改成移除了特定文档后的语言模型得分的负数,训练目标同样是最小化pATTN跟新版语言模型概率分布的KL散度。这种损失函数的计算成本明显高于前面几种。

3.2 预训练任务
关于预训练的任务涉及,论文也尝试了一下几种不同的方式。
a) Prefix language modeling
以N个字符为单位将文本分块,将每个块的文本切分为长度为N/2的两段子序列,用第一段子序列作为query,通过检索模块召回相关的文档,然后去生成结果,生成的目标是对应的第二段子序列。
b) Masked language modeling
以N个字符为单位将文本分块,对于每一个分块,随机抽样若干个平均长度为3的子片段进行mask,直到被mask的长度占文本总长度15%,将被mask后的每个分块作为query输入,通过检索模块去召回相关文档,然后利用语言模型去生成被mask掉的片段。
c) Title to section generation
利用Wikipeida的文章信息,将文章的标题跟章节的标题作为query输入,通过检索模块去召回相关文档,然后利用语言模型去生成对应章节的详细内容。
3.3 Efficient retriever fine-tuning
Retriever中的语料通过文档编码器被编码成向量被存储到索引中,在联合训练retriever跟语言模型时,retriever的文档编码器更新后,相应的索引就需要被更新,全量更新索引会耗费非常多的计算资源跟时间。尤其是在finetune阶段,训练样本的数量会远小于文档的索引数,更新索引的时间会增加整体的训练时间。
a) Full index update
训练每经过一定步数后更新全部索引,这种方式的好处在于全量更新索引能保证retriever中的文档编码器跟索引之间的相关性,同时可以根据实际需要来设置更新的频率。在论文中索引总数是3700万,训练batch size是64,每次召回20个文档,每经过1000步后更新全部索引,更新索引的计算量占模型训练的30%左右。
b) Re-ranking
在训练的每一步,检索模块会召回top-L个文档,返回其中top-K个文档给语言模型,并且更新这个L个文档的索引,L会大于K,也就是每次更新的索引数量会大于语言模型用到的文档数量。在论文中,每次更新的索引数量是语言模型接受文档数量的10倍,更新索引的计算量占模型训练的10%。
c) Query-side fine-tuning
训练过程retriever模块只更新query编码器,不更新文档编码器,那样就不需要更新索引了,所以更新索引的计算量占模型训练0%。固定文档编码器的影响在不同任务下不尽相同,在大多数few shot场景下,这种方式不会带来较大的性能影响,有时甚至能提高模型表现。
4 实验结论
a) 联合预训练的效果显著
从实验结果上可以看出,在few-shot场景下,所有包含联合预训练的方法效果都领先没有预训练的方法,其次,可以看到联合训练retriever的方法优于固定retriever,这个差距在64-shot场景可以明显见到,但在128-shot场景几乎见不到,这也说明了联合预训练的最大作用是对于语言模型的预训练,让其学会如何利用和融合检索得到的文档的信息。另外可以看到几种不同的retriever损失函数最终训练得到模型性能没有明显差距。最后可以看到选择MLM作为预训练任务的效果最佳。

图2: 检索器消融实验结果

图3: 预训练任务选择
b) Retriever Finetune
首先明显可以看到在finetune阶段固定检索模块(包括文档编码器跟query编码器)的方法有明显的性能下降,只更新部分索引的re-ranking方式性能接近更新全部索引的标准策略,由于引入了更少的计算量所以re-ranking看起来是更加高效的策略。最后,固定文档编码器的query-side策略也能取得不错效果,在64-shot场景下甚至取得超过更新全部索引的方式,这有可能是因为它更不容易过拟合。总之,如果训练样本较少,推荐query-side fine-tuning,反之,则根据预算跟成本选择另外两种策略其中之一。
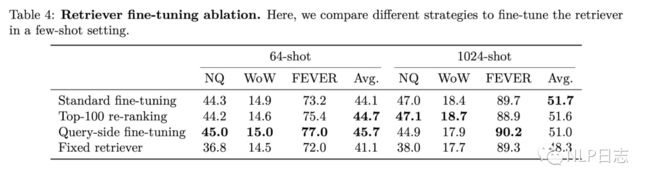
图4: 多种finetune时索引更新策略对比
5 分析
5.1 可解释性
基于检索增强的方法的一个优势在于可以通过检视检索得到的文档来增强可解释性。为了更好的理解检索模块召回的文档质量,论文针对MMLU任务做了更细致的研究。从左图可以看到,虽然索引中Wikipedia占比只有10%,但是在召回的文档里Wikipedia平均占比接近15%,不同领域下它的占比不尽相同。在中间的图可以看出,当找检索返回超过25个文档时,就有30%的概率返回提及正确答案的文档。从右图可以看出,随着返回提及正确答案的文档数量的增多,模型效果也在逐步提升。通过人为分析50个模型正确回复的case,可以发现检索返回的结果可以有多种方式去帮助模型正确生成结果。44%的case返回的文档包含部分有用的背景信息,可以提高回复的正确性或者缩小答案的范围,26%是返回的文档包括直接包含正确回复的重要信息,28%返回的文档没有提及任何明显游泳信息,2%的case文档里同时包含了问题跟答案。

图5: 可解释性分析
5.2 可更新性
检索增强模型的另一个优势在于可以通过更新或者切换索引来实现实时更新,而不需要重新训练。为了验证Atlas的可更新性,论文在一个答案随时间变化的数据集上进行实验(同样一个问题,在2017年跟2020会有不同的答案),其中closed-book采用的是T5,通过实验可以发现Atlas不仅在一般情形下效果上远超T5,还具有良好的可更新性,例如用2017年的answers训练得到的Atlas,只要将索引切换成2020的answers数据,也能很好的回复出2020年对应的正确答案,而传统的生成模型则会遭遇明显的性能下降。

图6: 可更新性对比
6 总结
Atlas这篇论文,在模型架构上跟之前介绍的其他retriever aumengtation的方式如出一辙,但是对于具体的实现,包括损失函数的选择,预训练任务的选择,索引更新方式的选择等内容有了更细致的研究,还对retriever aumengtation的可解释性跟可更新性做了详细分析。
参考文献
1.(2022,) Few-shot Learning with Retrieval Augmented Language Models
https://arxiv.org/pdf/2208.03299.pdf
2.(2022,) Unsupervised dense information retrieval with contrastive learning
https://arxiv.org/abs/2112.09118v4
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
为什么回归问题不能用Dropout?
Bert/Transformer 被忽视的细节
中文小样本NER模型方法总结和实战
一文详解Transformers的性能优化的8种方法
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
苏州大学NLP团队文本生成&预训练方向招收研究生/博士生(含直博生)
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~