深度学习实战项目:速算题目批改
深度学习实战项目:速算题目批改
- 前言
- 一、摘要
- 二、项目框架
- 三、项目步骤
-
- 1. 数据处理
-
- 1.1 数据收集
- 1.2 数据打标
- 1.3 数据预处理
- 2. 模型训练
-
- 2.1 目标检测
-
- 2.1.1 模型介绍
- 2.1.2 模型训练
- 2.1.3 训练结果
- 2.2 文本识别
-
- 2.2.1 模型介绍
- 2.2.2 模型训练
- 2.2.3 训练结果
- 3. 模型推理
-
- 3.1 YOLO模型接口
- 3.2 CRNN模型接口
- 4. 模型部署
-
- 4.1 上传图像
-
- 4.1.1 代码实现
- 4.1.2 页面效果
- 4.2 文本检测
-
- 4.2.1 代码实现
- 4.2.2 效果展示
- 4.3 文本识别
-
- 4.3.1 代码实现
- 4.3.2 效果展示
- 4.4 算式批改
-
- 4.4.1 代码实现
- 4.4.1 效果展示
- 4.5 结果反馈
-
- 4.5.1 推理时间
- 4.5.2 用户答题情况
- 5. 模型压缩
-
- 5.1 核心代码
- 5.2 压缩效果
- 6. 项目优化
-
- 6.1 书的部分拱起
- 6.2 模型泛化能力
- 6.3 模型压缩
- 6.4 模型推广
- 三、项目演示
- 四、项目总结
- 五、项目地址
- 六、参考资料
前言
这个项目是笔者在《深度学习实践与应用》这门课的期末大作业,可以算得上是我的深度学习启蒙项目。当时这个项目花了我很多精力去完成的,最后也取得了不错的结果,收获满满。我第一次看到这个项目时,是有点恐惧的,担心自己无法完成这个项目,但当我真正上手去做这个项目的时候,才发现它没有想象中的那么难,我只需要把项目进行拆解,分解成若干个子任务,然后各个击破就可以了。所以有时候不要畏惧挑战,干就完事了哈哈哈。而做完这个项目之后,不瞒你说贼有成就感,也因为这个项目我对人工智能应用也更加感兴趣,未来我还会继续做更多有意思的项目,敬请期待吧!废话不多说,让我们直接开始吧!
友情提示:全文篇幅有点长,建议阅读时间30分钟,可以先收藏后慢慢食用哈
一、摘要
针对AI+教育行业的应用,以小学速算作业批改为原型,我们运用了OCR(光学字符识别)中经典的目标检测搭配文本识别来实现自动批改任务。首先,我们对数据进行人工标注,分为YOLO和CRNN的标记,分别为equation和题目字符内容;然后是目标检测和文本识别两个任务,分别使用的是训练好的YOLO和CRNN模型,得到了不错的识别效果,最终使用逆波兰式对用户的答案进行批改。其中,我们还对系统进行了优化,对于数据标记,我们利用了的图像处理的方法进行自动数据标注;对于用户上传的低质量图片(模糊/倾斜/含阴影),我们同样利用了一些图像处理的方法进行修正;对于YOLO模型参数过大的,我们使用了模型剪枝方法对其进行压缩。最后,我们的展望是能将模型适用于对存在拱起区域的图片,以及将模型剪枝搭配参数量化方法进一步压缩我们的模型,进一步提升模型的推理速度。
二、项目框架

三、项目步骤
本次项目可以分为以下几步:
- 数据处理
- 模型训练
- 模型推理
- 模型部署
- 模型压缩
- 项目优化
由于本次项目是应用为主,这里我就不会过多介绍具体的算法实现,而会偏向于介绍工程上的实现,包括数据集制作、模型训练心得、模型优化等等。
1. 数据处理
数据处理又可以分为数据收集、数据打标和数据预处理。下面我就来分别介绍下。
1.1 数据收集
有多少人工就有多少智能,深度学习项目成功与否很大程度是跟数据有关,所以一开始的重中之重就是收集数据。这里我们采取分工协作的方式来创建数据集,每个小组写两大本小学速算题目并将照片拍照收集起来,(这个过程蛮有意思,如果你发现某个大学生上课在做小学计算题,请不要嘲笑他哈哈)。最后我们通力合作收集了601张照片。

1.2 数据打标
数据收集好后,为了模型能训练准确识别算式的位置和内容,所以我们需要给图片都进行标注,这里我们用的是labelimg软件来进行数据打标,操作十分简单,只需要拖动鼠标划出矩形框,对于YOLO模型,标记统一设定为“equation”,如下图所示:
对于CRNN模型,标记设定为等式框中的字符串内容:

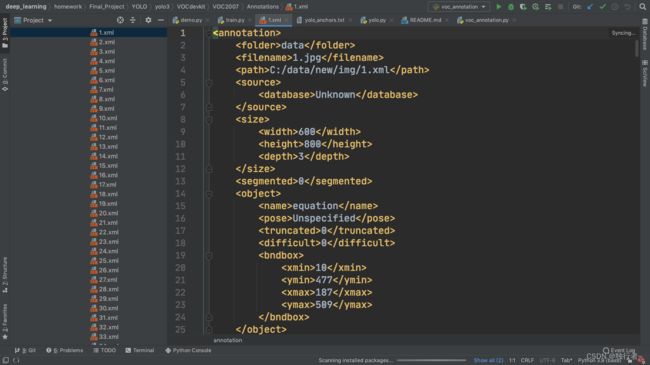
最后数据标注的结果会生成对应图片的XML文件,XML文件保存着对应图片中算式的位置坐标和标注结果信息。如下图所示:(关于XML文件的具体介绍,我后续会继续完善和补充,先占个位哈哈)
1.3 数据预处理
YOLO模型训练的数据就是整张照片,而CRNN模型训练的数据是一个个算式式子,因此我们利用脚本将YOLO模型训练数据进行处理。具体原理是根据YOLO数据打标获得的XML文件获取每张图片每个等式在图片的具体位置,然后利用CV2库将其裁剪为一个个小图片。核心代码如下:
# 裁剪,只适用标签文件为xml的情况,其他情况可相应地修改代码
for img_file in os.listdir(img_path): # 遍历图片文件夹
img_filename = os.path.join(img_path, img_file) #将 图片路径与图片名进行拼接
img_cv = cv2.imread(img_filename) #读取图片
img_name = (os.path.splitext(img_file)[0]) # 分割出图片名,如“000.png” 图片名为“000”
xml_name = xml_path + '\\' + '%s.xml'%img_name #利 用标签路径、图片名、xml后缀拼接出完整的标签路径名
root = ET.parse(xml_name).getroot() # 利用ET读取xml文件
for obj in root.iter('object'): # 遍历所有目标框
name = obj.find('name').text # 获取目标框名称,即label名
xmlbox = obj.find('bndbox') # 找到框目标
x0 = xmlbox.find('xmin').text # 将框目标的四个顶点坐标取出
y0 = xmlbox.find('ymin').text
x1 = xmlbox.find('xmax').text
y1 = xmlbox.find('ymax').text
obj_img = img_cv[int(y0):int(y1), int(x0):int(x1)] # cv2裁剪出目标框中的图片
obj_img_name = obj_img_path + '\\' + '%s_%s'%(img_name, name) + '.jpg' # 裁剪图片的名字
cv2.imencode('.jpg', obj_img)[1].tofile(obj_img_name) # 写入
print("Finished.")
最后获得CRNN训练数据长这样:

同时也生成对应的txt文件,txt文件里包含图片的名字和图片的算式内容

2. 模型训练
2.1 目标检测
我参考的代码是这个:yolo3-pytorch
(占个坑哈,后面会补上YOLO模型训练的具体过程,敬请期待)
2.1.1 模型介绍
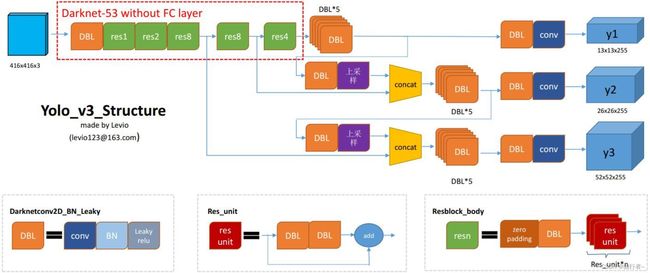
这里我采用的目标检测算法是YOLO算法 , 由于YOLO算法采用了残差网络这种跳层连接的方式,性能完全比ResNet-152和ResNet-101深层网络更好,无论是准确率还是计算效率都更佳。相比于RCNN系列的目标检测方法,YOLO的识别物体位置精准性较差,召回率低。
2.1.2 模型训练
这里我用的是
(1) 数据集
样本总量共601张,预处理前的图片平均尺寸为(1452.0, 1815.6),将样本划分为训练集:验证集:测试集=0.81:0.09:0.1
(2) 参数调整
输入图片放缩尺寸至416*416,通道数为3.
冻结阶段:epochs为20、batch_size为8、lr为1e-3。
解冻阶段:epochs为50,batch_size为4、lr为1e-4。
预测概率阈值为0.5(只有预测概率大于0.5的预测框才会保留)
2.1.3 训练结果
2.2 文本识别
我参考的代码是这个:使用pytorch训练自己的文字识别模型
关于文本识别的训练过程蛮有意思的可以分享下哈哈:当时我在使用大佬模型训练过程中一直出现问题,所以我通过B站蹲点联系上了大佬并加上了大佬的微信,大佬也很热情地帮我解决了问题。这告诉我们:办法总是比困难多的(B站真的是个学习的地方 )
(再占个坑哈,到时候会补上CRNN模型训练的具体过程,敬请期待)
2.2.1 模型介绍
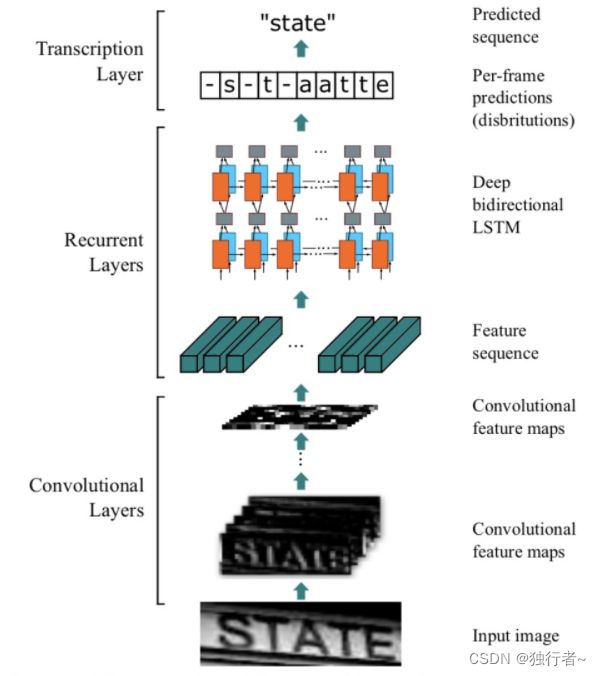
文本识别我采用的是CRNN模型 ,文字识别可以认为是对序列的预测方法,所以采用了对序列预测的RNN网络。通过CNN将图片的特征提取出来后采用RNN对序列进行预测,最后通过一个CTC的翻译层得到最终结果。简单来说就是CNN+RNN+CTC的结构。CRNN可以直接从序列标签(例如单词)学习,不需要详细的标注,虽然其对较大形变的手写字体的的识别准确率欠佳,但在速算识别的应用场景下的识别率较为稳定。
2.2.2 模型训练
(1) 数据集
样本总量共3284张,预处理前的图片平均尺寸为(266,65),将样本划分为训练集:验证集:测试集=0.75:0.2:0.05
(2) 参数调整
输入图片放缩尺寸至262*32,通道数为3.
训练轮数epochs为30、batch_size为256、lr为1e-3。
Val_epoch为1,即每轮都验证一次。
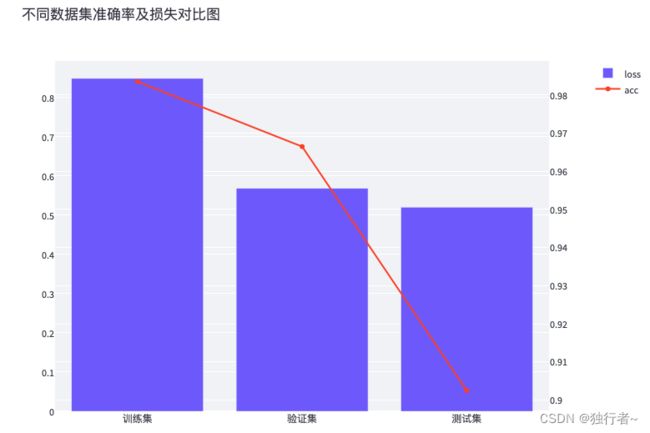
2.2.3 训练结果
3. 模型推理
3.1 YOLO模型接口
我们根据以下两个YOLO接口,将YOLO模型嵌入我们的系统中。
- yolo.detect_image(image)
- GetBoxedPic(img, boxes)
接口1:yolo.detect_image(image)
目的:该接口用于调用YOLO3模型对图片进行预测并返回相应的预测结果信息。
输入:原图image(PIL的image对象)。
输出:等式检测图、所有等式框的坐标信息和对应的置信度。
其中,等式检测图是在输入的原图上进行了等式框的绘制;等式框的坐标信息将作为后面CRNN文本识别的输入;等式框的置信度将在模型性能分析报告中体现。
如下图所示,该Detecting函数用于实现将等式检测的部分展现至web上,首先,根据st.subheader函数显示副标题(Detected Image),根据st.write函数提示用户等待信息。然后创建一个yolo对象,并输入用户上传的图像,调用接1(yolo.detect_image)进行等式检测并返回结果信息,与此同时,st.progress函数将会显示识别的进度条,防止用户错认为网站卡顿。
# 进行yolo检测,呈现在web页面上
def Detecting(image):
st.subheader("Detected Image")
st.write("Just a second ...")
yolo = YOLO()
my_bar = st.progress(0)
img = image.copy()
start1 = time.time()
r_image, boxes, top_conf = yolo.detect_image(image)
end1 = time.time()
# print(boxes)
for percent_complete in range(100):
my_bar.progress(percent_complete + 1)
st.image(r_image, use_column_width=True) # 展现检测结果
# st.download_button(label="Download image", data=r_image, file_name='large_df.jpg', mime="image/jpg")
st.subheader("Detection outcome Analysis")
plt.scatter(np.arange(len(top_conf)), top_conf)
plt.xlabel('detected rectangle')
plt.ylabel('score')
st.pyplot()
# st.balloons()
pics = GetBoxesPic(img, boxes)
return boxes, start1, end1
# st.image(pic, use_column_width=True)
接口2:GetBoxedPic(img, boxes)
目的:该接口用于存储检测出的所有等式图像,作为CRNN文本识别的输入图像。输入:原图img(PIL的image对象)、等式框坐标信息boxes。
输出:将所有截取的等式框图像保存。
其中,等式框的坐标信息需要转为整型,分别为top, left, bottom, right四个整型,代表等式框的上(y),左(x),下(y),右(x)坐标。在等式检测完毕后,返回(输出)了等式检测图像r_image、等式框坐标信息boxes、等式框检测置信度top_conf。我们使用st.image在web上显示出等式检测图像,并将等式框识别置信度以散点图的形式绘制在web上。除此之外,调用接口2用于存储boxes的信息,代码如下:
def get4pos(box, image):
top, left, bottom, right = box
top = max(0, np.floor(top).astype('int32'))
left = max(0, np.floor(left).astype('int32'))
bottom = min(image.size[1], np.floor(bottom).astype('int32'))
right = min(image.size[0], np.floor(right).astype('int32'))
return top, left, bottom, right
# 返回yolo框出的区域,并将其等式图片存入对应文件夹中
def GetBoxesPic(image, boxes):
pics = []
shutil.rmtree('./yolo3/tmp_img') # 清空操作
os.mkdir('./yolo3/tmp_img')
for i in range(len(boxes)):
top, left, bottom, right = get4pos(boxes[i], image)
pic = image.crop((left - 15, top, right + 40, bottom))
pic.save('./yolo3/tmp_img/pic' + str(i).rjust(3, '0') + '.jpg')
pics.append(pic)
return pics
3.2 CRNN模型接口
- 接口1:parse_opt配置函数
- 接口2:main函数
接口1:parse_opt配置函数
目的:对CRNN模型提供参数以及路径,包括模型权重、预测图片路径、批量大小、结果存放路径等。
输出:返回模型的配置内容的对象。代码如下图所示:
def parse_opt():
parser = argparse.ArgumentParser(description='detect')
parser.add_argument('--weights', type=str, default='../crnn_master/weights/CPU.pt', help='权重的路径')
parser.add_argument('--source', type=str, default='../YOLO/yolo3/tmp_img/', help='要用来推理图片的路径,可以是一张图片,也可以是一个目录')
parser.add_argument('--batch_size', type=int, default=32, help='批次大小')
parser.add_argument('--chinese', type=str, default='../crnn_master/data/formula.txt', help='字符集保存路径')
parser.add_argument('--imgH', type=int, default=32)
parser.add_argument('--nc', type=int, default=1)
parser.add_argument('--nh', type=int, default=256)
opt = parser.parse_args()
return opt
接口2:main函数
目的:使用CRNN模型对输入的一系列等式图像进行识别。
输入:接口1返回的配置对象。
输出:CRNN的识别结果,即所有等式图像对应的等式字符串。
def main(opt):
chinese = get_chinese(opt.chinese)
converter = StrLabelConverter(chinese)
nclass = len(chinese) + 1
crnn = CRNN(opt.imgH, opt.nc, nclass, opt.nh)
crnn.load_state_dict(torch.load(opt.weights))
log_load_model(opt.weights)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#device = torch.device('cpu')
log_device(device)
crnn = crnn.to(device)
equations = detect_(crnn, opt.source, device, converter)
return equations
4. 模型部署
本次项目对训练好的YOLO3目标识别模型和CRNN文本检测模型,使用Streamlit轻量级机器学习部署工具呈现至web端,提供给用户良好的速算批改体验。这里简单介绍下Streamlit:它是第一个专门针对机器学习和数据科学团队的应用开发框架,它是开发自定义机器学习工具的最快的方法,它的目标是取代Flask在机器学习项目中的地位,可以帮助机器学习工程师快速开发用户交互工具。(下面是官网首页的介绍)
“Streamlit turns data scripts into shareable web apps in minutes.All in pure Python. No front‑end experience required.”
我们的模型部署主要分为以下五个方面:
- 上传图像
- 文本检测
- 文本识别
- 算式批改
- 结果反馈
4.1 上传图像
在使用streamlit工具进行部署的过程中,我们无需像部署Flask应用程序,编写html、css和js代码,只需要调用若干个streamlit库的API就可以实现不错的页面交互效果。
4.1.1 代码实现
首先,我们通过streamlit的set_option函数设置配置项的值,然后通过st.title在web端显示标题,并通过st.file_uploader进行文件的读取,返回至file_up变量,然后使用PIL库中的Image.open函数读取file_up中的图像数据。最后通过st.subheader显示副标题,以及将读取的图片展示在web端。
st.set_option('deprecation.showPyplotGlobalUse', False)
st.title("Handwriting Recognition")
st.write("")
file_up = st.file_uploader("Upload an image", type="jpg")
if file_up is not None:
image = Image.open(file_up)
st.subheader("Uploaded Image")
st.image(image, use_column_width=True)
4.1.2 页面效果
以上传图像为例,我们实现了如下web交互页面,通过点击“Browse files”就可以上传一个本地文件,以供后续使用。在本项目中,根据用户需求上传的文件是图片文件,文件名以.jpg等后缀结尾。
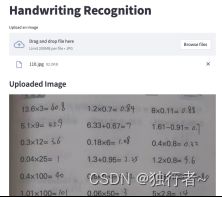
4.2 文本检测
对于文本位置检测,我使用的是训练好的YOLO3模型。我将上传的图片进行等式位置检测后返回含有标记框的图片。首先,设置一个按钮(Detect),点击该选项后将依次进行等式检测和文本识别,等式检测的过程在Detecting函数中进行了实现。
4.2.1 代码实现
首先通过st.subheader设置好标题后,便调用Detecting( )函数来实现文本位置的检测,相关代码如下:
if st.button('Detecting'):
st.subheader("Recognition")
# 等式检测
boxes, start1, end1 = Detecting(image)
接着利用yolo.detect_image(image)函数对图片进行预测并返回相应的预测结果信息,预测结果包括等式检测图、所有等式框的坐标信息以及对应的置信度。其中,等式检测图是在输入的原图上进行了等式框的绘制;等式框的坐标信息将作为后续的CRNN文本识别的输入;等式框的置信度将在模型性能分析报告中体现。相关代码如下:
def Detecting(image):
st.subheader("Detected Image")
st.write("Just a second ...")
yolo = YOLO()
my_bar = st.progress(0)
img = image.copy()
start1 = time.time()
r_image, boxes, top_conf = yolo.detect_image(image)
end1 = time.time()
# print(boxes)
for percent_complete in range(100):
my_bar.progress(percent_complete + 1)
st.image(r_image, use_column_width=True) # 展现检测结果
最后利用GetBoxedPic(img, boxes)函数来存储检测出的所有等式图像,作为CRNN文本识别的输入图像。其中,等式框的坐标信息需要转为整型,分别为top, left, bottom, right四个整型,代表等式框的上(y),左(x),下(y),右(x)坐标。相关代码如下:
# 返回yolo框出的区域,并将其等式图片存入对应文件夹中
def GetBoxesPic(image, boxes):
pics = []
shutil.rmtree('./yolo3/tmp_img') # 清空操作
os.mkdir('./yolo3/tmp_img')
for i in range(len(boxes)):
top, left, bottom, right = get4pos(boxes[i], image)
pic = image.crop((left - 15, top, right + 40, bottom))
pic.save('./yolo3/tmp_img/pic' + str(i).rjust(3, '0') + '.jpg')
pics.append(pic)
return pics
4.2.2 效果展示

4.3 文本识别
对于文本识别,我只需要需要调用CRNN的接口对之前文本检测后存储起来的图像进行预测,得到等式的文本信息。
4.3.1 代码实现
调用pasrse_oppt函数、main函数,分别是用于CRNN的模型配置、运行CRNN。
if st.button('Detecting'):
st.subheader("Recognition")
# 等式检测
boxes, start1, end1 = Detecting(image)
# 文本识别
start2 = time.time()
opt = parse_opt()
equations = main(opt)
end2 = time.time()
painting(equations, img, boxes)
首先是CRNN的模型配置,我是调用pasrse_oppt函数来进行模型的初始化配置,它将会对CRNN的模型权重、预测图片路径、批量大小、结果存放路径等参数进行配置,最后会返回模型的配置内容的对象。
def parse_opt():
parser = argparse.ArgumentParser(description='detect')
parser.add_argument('--weights', type=str, default='../crnn_master/weights/CPU.pt', help='权重的路径')
parser.add_argument('--source', type=str, default='../YOLO/yolo3/tmp_img/', help='要用来推理图片的路径,可以是一张图片,也可以是一个目录')
parser.add_argument('--batch_size', type=int, default=32, help='批次大小')
parser.add_argument('--chinese', type=str, default='../crnn_master/data/formula.txt', help='字符集保存路径')
parser.add_argument('--imgH', type=int, default=32)
parser.add_argument('--nc', type=int, default=1)
parser.add_argument('--nh', type=int, default=256)
opt = parser.parse_args()
return opt
接着使用使用CRNN模型的main()函数对输入的一系列等式图像进行识别。
它将会返回所有等式图像对应的等式字符串。
def main(opt):
chinese = get_chinese(opt.chinese)
converter = StrLabelConverter(chinese)
nclass = len(chinese) + 1
crnn = CRNN(opt.imgH, opt.nc, nclass, opt.nh)
crnn.load_state_dict(torch.load(opt.weights))
log_load_model(opt.weights)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#device = torch.device('cpu')
log_device(device)
crnn = crnn.to(device)
equations = detect_(crnn, opt.source, device, converter)
return equations
4.3.2 效果展示
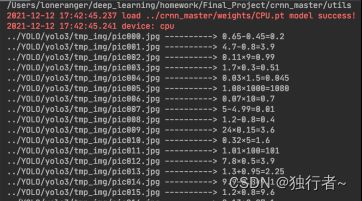
4.4 算式批改
对于速算批改,我只需将文本识别得到的等式文本信息作为输入,通过逆波兰式计算出等式的正确答案,判断是否相等即可。
4.4.1 代码实现
这里我调用outcome函数和painting函数,分别是来判断文本识别返回的结果是否正确,以及在网页上上绘制文本识别的结果。
首先是outcome函数,它将传入的式子以等号做切分,将等式左边的表达式利用逆波兰式计算出表达式的正确答案,再将其与等式右边的值进行比较,如果相等则返回1,如果不相等则返回0.
def outcome(exp): # 传入表达式,返回判断结果
input = exp.split('=')[0]
output1 = float(exp.split('=')[1])
output = cal(input)
if (abs(output - output1) < 0.001): # 计算正确
return 1
else:
return 0
接着我利用利用painting函数对CRNN得到的等式字符串结果进行批改,并将结果呈现在web页面上。painting函数输入的是等式字符串equations,原始图像image,等式框坐标信息boxes。它将创建一个PIL的绘图对象,并设置字体类型和大小,接着遍历每一个等式字符串,调用outcome函数判定结果是否正确,然后利用对应的等式框坐标信息显示在原始图片上,然后将最终的图片呈现在网页上。
def painting(equations, image, boxes):
st.subheader("Identification outcome")
imgdraw = ImageDraw.ImageDraw(image) # 创建一个绘图对象,传入img表示对img进行绘图操作
font = ImageFont.truetype('Microsoft Sans Serif.ttf', image.size[1] // 50, encoding="utf-8")
for i in range(len(boxes)):
top, left, bottom, right = get4pos(boxes[i], image)
if outcome(equations[i]):
imgdraw.text(xy=(left, bottom + 3), text=equations[i] + '√', fill=(255, 0, 0), font=font)
else:
imgdraw.text(xy=(left, bottom + 3), text=equations[i] + '×', fill=(255, 0, 0),
font=font) # 调用绘图对象中的text方法表示写入文字
st.image(image, use_column_width=True)
4.4.1 效果展示
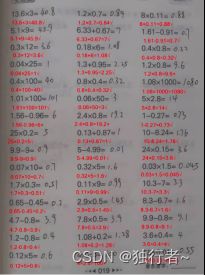
4.5 结果反馈
4.5.1 推理时间
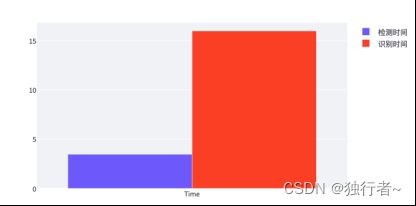
可以看到时间上,文本识别时间比文本检测的时间要长一些,文本识别所花时间是15秒,说明我的CRNN模型推理速度优化上还存在提升空间,使得模型能更快地完成推理工作,这样才能给用户带来更好的使用体验。
4.5.2 用户答题情况
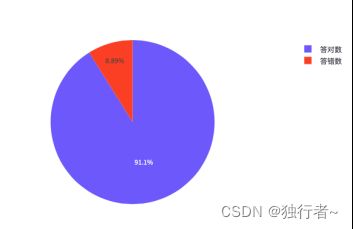
利用饼图将用户的答题情况进行可视化,这样就可以清晰地看到用户的答题情况,接下来可以继续优化,比如记录用户是哪一道题打错,并将其记录下来,用于后面的统计分析得到哪道题错误率最高,可以帮助老师更好辅导学生。
5. 模型压缩
随着现在模型越来越复杂,模型压缩也越来越受到重视,因为当模型的准确度达到一定程度后,如何用更少的硬件成本去做模型服务变得有意义。而常用的模型压缩方法有模型设计,知识蒸馏,网络剪枝,参数量化。在本次实验中我主要尝试的模型压缩方法是模型剪枝。
速算批改中的YOLO算法模型参数有240多MB,所以我采用NNI工具包中的模型剪枝的方法来对其进行压缩。NNI (Neural Network Intelligence) 是一个轻量但强大的工具包,帮助用户自动的进行 特征工程,神经网络架构搜索,超参调优以及模型压缩。NNI 管理自动机器学习 (AutoML) 的 Experiment, 调度运行由调优算法生成的 Trial 任务来找到最好的神经网络架构和/或超参,支持各种训练环境。
NNI 提供了一些支持细粒度权重剪枝和结构化的滤波器剪枝算法。细粒度剪枝通常会生成非结构化模型,这需要专门的硬件或软件来加速稀疏网络。滤波器剪枝一些剪枝算法使用 One-Shot 的方法,即根据重要性指标一次性剪枝权重(有必要对模型进行微调以补偿精度的损失)
而我采用的是L1Filter Pruner,这是一个 One-Shot Pruner,它修剪卷积层中的滤波器。除此之外,它还提供了依赖感知模式。
5.1 核心代码
这里对用cfg_list对剪枝模型进行配置,稀疏度设为0.6,即将会剪除 60%,同时设置剪枝类型为“conv2d”,即卷积层。除此之外,这里还加了个函数isinstance()来对模型是否能剪进行了判断
#模型压缩
print(model)
model.eval()
dummy_input = torch.rand(8, 3, 320, 320)
model(dummy_input)
# Generate the config list for pruner
# Filter the layers that may not be able to prune
not_safe = not_safe_to_prune(model, dummy_input)
cfg_list = []
for name, module in model.named_modules():
if name in not_safe:
continue
if isinstance(module, torch.nn.Conv2d):
cfg_list.append({'op_types': ['Conv2d'], 'sparsity': 0.6, 'op_names': [name]})
# Prune the model
pruner = L1FilterPruner(model, cfg_list)
pruner.compress()
pruner.export_model('./compression/model.pth', './compression/mask.pth')
pruner._unwrap_model()
# Speedup the model
ms = ModelSpeedup(model, dummy_input, './compression/mask.pth')
ms.speedup_model()
model(dummy_input)
print(model)
torch.save(model, './compression/YOLO.pth')
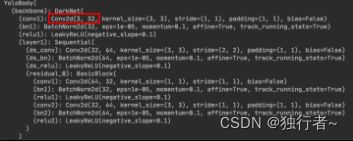
5.2 压缩效果
模型压缩前:
模型压缩后:
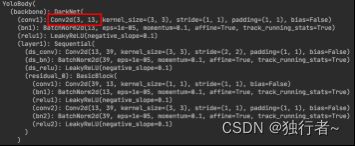
可以看到里面卷积层的参数已经被剪掉
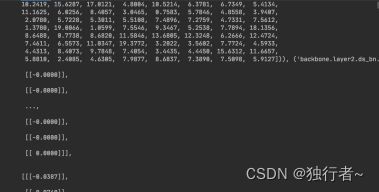
最后我们再来看下模型最终压缩后的大小,为91.2MB,压缩了63%,效果还是不错的。

不过目前模型压缩还存在一些问题,压缩完后的模型还无法进行正常地推理,目前正在解决中,后面解决完后再完善哈。
6. 项目优化
目前项目已完成了预期的基本要求,但项目还有许多方面可以进行优化,下面就提一些可以优化的方向以供大家参考,有补充的也可以在评论区留言:
6.1 书的部分拱起
一般而言,新书在翻折的时候都会出现一定的拱起,这样会造成图片的局部扭曲。可以发现,由于用户在写速算题答案时,位置可能会存在不小的差异,导致如果存在局部扭曲的话,识别一整个题目+答案将会比较困难。对于这种情况,可以考虑将题目和答案由等号分隔开,建立在自动标记的基础之上,可以先对其自动打标,然后放大标记框,确保整个等式完全包含在框中,再通过像素分布找出等号的位置,从而将题目与答案分隔开来了。
当两者分隔开来以后,只需使用一个较为简单的模型就能轻松识别题目了,这是由于题目属于印刷体,就算存在一定的扭曲,也能达到较高的准确率;对于答案而言,由于答案占的区域较小,几乎不存在较大的倾斜,因此在CRNN下也依旧能得到很高的准确率。由此,便化解了书部分拱起带来的一系列困扰

6.2 模型泛化能力
当我们使用不清晰的图片时,可以看到推理的结果不是很理想,主要体现在等式右边的数字推理效果,等式左侧的推理效果是相当不错。不过这也是可以理解的,因为当时进行模型训练时,训练样本中是印刷体的数字和字符占大多数,其中印刷体数字样本是手写体数字样本的两倍,这才导致模型推理中手写体数字推理效果不佳。针对这个问题,如果想要在不额外增加数据集下,提升模型的性能,那么接下来的改进方向有:
(1) 采用图像增广方法,在不额外增加其他数据集下增加数据样本。可以尝试采用裁剪,翻转、颜色变化、灰度图等方法扩充数据样本。
(2) 单独把手写的那部分裁剪出来,当成训练集一起训练。具体做法:把手写的数字,裁剪下来,复制两份,最后3份拼接再一起,例如:裁剪出来123,最后拼接后是123123123。这样就可以保持和原图一样的长度,保证模型训练的效果达到最佳。

6.3 模型压缩
模型压缩这里我们只采用了模型剪枝的方法来对YOLO进行剪枝,还没对CRNN进行裁剪。除此之外,YOLO模型的压缩也还有进一步压缩的空间。一般来说,模型剪枝方法会与其他模型压缩方法进行搭配使用,所以接下来我们将首先尝试模型量化的方式,并将其与模型剪枝搭配使用来看看模型最终的压缩效果。同时我们还会尝试知识蒸馏以及模型设计等常用的模型方法来横向对比不同方法的压缩效果。待到对模型压缩足够了解后,我们会尝试设计自己模型压缩算法来针对性地对我们自己的模型进行压缩。
6.4 模型推广
- 手写体
本次实验中计算式子都是打印体,比较规整,识别效果也相当不错。但如果都用手写体的话,效果会不是很理想,所以接下来我们会收集大量的手写体数据来对我们的模型进行训练,使得它在识别手写体数字以及公式时也能得到不错的结果。 - 多张图片
当前进行速算批改时每次只能上传一张图片,但真实应用场景用户不可能一张一张照片的上传,而是多张照片,甚至是直接上传整个文档。所以接下来我们会继续完善我们的项目使得它能满足用户同时上传多张照片或者一个文档的需求,快速相应并对结果进行反馈。 - 高级运算
当前我们的模型只能识别简单的加减乘除四则运算,但这只能满足小学生批改作业的需求,无法满足中学生甚至大学生们的需求,所以接下来我们会对项目进行完善使得它可以处理线性代数的矩阵运算和积分运算以及微分运算。
三、项目演示
四、项目总结
本次项目收获颇多,要用一个词语来形容的话就是惊喜。首先是Streamlit,一开始我还在担心模型训练出来后如何将结果展示出来,毕竟要做一个网页来对模型进行展示需要花费相当多的时间,而Streamlit的到来可谓解决了我这个后顾之忧,它是第一个专门针对机器学习和数据科学团队的应用开发框架,它是开发自定义机器学习工具的最快的方法,可以帮助机器学习工程师快速开发用户交互工具。有了Streamlit我才能在本次项目中能将模型结果呈现给用户看。
其次我惊喜的是我居然完成了这个当初看上去很有挑战性的任务,从模型的训练、模型部署、模型压缩这整个流程我完整体验了一遍,也初步掌握了产品开发的整个流程。这在项目开始之前是不敢相信,但在我不断地努力中一点点地攻克完成,最终得到现在不错的结果,所以还是蛮有成就感的。在这次项目中,我从一个萌新小白逐渐初窥深度学习的门道,在一点点完成项目过程中去快速学习深度学习相关的知识:如何调参数使得训练效果更理想,如何让模型的推理速度加快等等。直到现在我还记得当时我在计软楼同时开几台电脑,用控制变量法来进行调参只为找到最佳的训练参数的场景。
这时我才真正体会到学习新知识的最好方法不是单纯的授课方式,而是像这样项目导向型的方式,尤其是深度学习这需要大量实践领域。当然这也有一定的弊端,就是在完成项目的过程中我可能不太关注技术的细节,而是专注于实现最后的功能。但是现在的我在完成项目过程中对其有了更浓厚的兴趣,所以本学期结束后我会继续专注研究其背后技术细节,提升自己对深度学习的理解。
最后说下这个项目,虽然现在已经完成了我初步设想的基本功能,但还是有许多地方可以改进优化,首先是模型的推理速度可以提升下,毕竟这个项目是面向用户的,结果反馈所花的时间太久会影响用户的体验,所以模型的相应速度必须提升。在本次项目中虽然我尝试了模型剪枝的方法来对模型进行压缩,模型是压缩成功了,但我对压缩过后的模型进行调用时仍会出现一些问题,现在还没有解决,所以项目中就没有展现最终压缩后模型的推理速度。但是在研究模型压缩过程中我也发现了些问题:首先是模型剪枝本身是没有剪层的,它只是修剪参数,所以当网络比较深的时候,他的压缩效果可能不会很好,但我似乎也没有看到很多从模型深度来进行压缩的方法。还有就是这里一般来说模型剪枝和模型量化来搭配使用会比较好,所以接下来我会进一步研究模型压缩这方面的内容,将模型进一步压缩。其次是模型的精度还需要提升,毕竟他的在推理模糊或者有阴影的图片时效果还是不理想,除此之外,我之后还打算对项目进行优化,比如:每次用户提交一些照片时,我就重新对模型进行训练,使得模型能在与用户进行交互时不断更新迭代使得模型性能进一步提升。
五、项目地址
如果觉得不错的话,就给我的项目star一下吧!!!
【Github】Quick-Calculation-Correction
【百度网盘】Quick-Calculation-Correction 密码: 37o4
六、参考资料
[1] https://zhuanlan.zhihu.com/p/137086882
[2] https://blog.csdn.net/leviopku/article/details/82660381
[3] https://github.com/zhijiezhong/crnn/tree/master
[4] https://github.com/bubbliiiing/yolo3-pytorch
[5] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[6] Otsu, N. A threshold selection method from gray-level histogram[J]. IEEE Transactions on Systems, Man and Cybernetics, 1979 (9): 62-66.
[7] Canny J. A computational approach to edge detection[J]. IEEE Transactions on pattern analysis and machine intelligence, 1986 (6): 679-698.
[8] Sobel I. History and definition of the sobel operator[J]. Retrieved from the World Wide Web, 2014, 1505.
[9] Shi B, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 39(11): 2298-2304.
[10] 视频转GIF工具