图像分类经典网络
1. LeNet网络在眼疾分类的应用
结构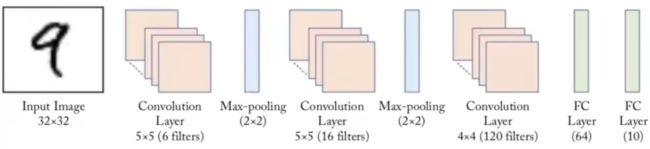
- 卷积和池化层组合使用,逐层提取图像特征,先通过卷积提取到图像特征,再通过池化降低特征对位置的敏感度,同时做降维操作。
- 激活函数都是sigmod。
- 最后一个卷积层提取完特征后通过两个全连接层输出。
- 最后一个全连接层的大小等于分类的类别数。
1.1 代码
# 定义 LeNet 网络结构
class LeNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层块,每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化
self.conv1 = Conv2D(in_channels=3, out_channels=6, kernel_size=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 创建第3个卷积层
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
# 创建全连接层,第一个全连接层的输出神经元个数为64
self.fc1 = Linear(in_features=300000, out_features=64)
# 第二个全连接层输出神经元个数为分类标签的类别数
self.fc2 = Linear(in_features=64, out_features=num_classes)
# 网络的前向计算过程
def forward(self, x, label=None):
x = self.conv1(x)
x = F.sigmoid(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.sigmoid(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.sigmoid(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.sigmoid(x)
x = self.fc2(x)
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
飞桨会根据实际图像数据的尺寸和卷积核参数自动推断中间层数据的W和H等,只需要用户表达通道数即可。
1.2 定义数据读取器
1.2.1 预处理
# 对读入的图像数据进行预处理
def transform_img(img):
# 将图片尺寸缩放道 224x224
img = cv2.resize(img, (224, 224))
# 读入的图像数据格式是[H, W, C]
# 使用转置操作将其变成[C, H, W]
img = np.transpose(img, (2,0,1))
# 图像中的像素类型改为float
img = img.astype('float32')
# 将数据范围调整到[-1.0, 1.0]之间
img = img / 255.
img = img * 2.0 - 1.0
return img
为什么归一化是放缩到[-1,1]之间,而不是[0,1]之间,上网查阅了发现大部分人观点不一。
现在的实验经验,一般归一化后的数值沿原点对称最好,即归一化到[-1,1]可以期待取得更好的效果。因此推荐在归一化时,把样本数据归一化到[-1,1],或者其他相对于原点对称的范围。
对应的,似乎使用双极性激活函数(tanh)优于单极性激活函数(sigmoid),因为tanh的激活值范围[-1,1],而sigmoid的激活值范围是[0,1]
我亲自用paddle上的项目试了一下,发现归一化到[-1, 1]和归一化到[0,1]差别并不明显。

1.2.2 训练集数据读取
# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 将datadir目录下的文件列出来,每条文件都要读入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 训练时随机打乱数据顺序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img) # 预先写好的预处理函数处理输入的图片
if name[0] == 'H' or name[0] == 'N':
# H开头的文件名表示高度近似,N开头的文件名表示正常视力
# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0
label = 0
elif name[0] == 'P':
# P开头的是病理性近视,属于正样本,标签为1
label = 1
else:
raise('Not excepted file name')
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
验证集数据读取和训练集基本一致,需要注意的点是验证集中图片的名字以及label需要从csv文件中读取。
1.3 定义训练过程
预处理工作
model.train() # 训练模式
# 定义数据读取器,训练数据读取器和验证数据读取器
train_loader = data_loader(DATADIR, batch_size=10, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE)
开始训练
for epoch in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 计算损失,均值化处理
loss = F.binary_cross_entropy_with_logits(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 20 == 0:
print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy())))
# 反向传播,更新权重,清除梯度
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
# 每训练完一个epoch,计算一次准确率
model.eval() # 切换成评估模式
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别
# 计算sigmoid后的预测概率,进行loss计算
pred = F.sigmoid(logits)
loss = F.binary_cross_entropy_with_logits(logits, label)
# 计算预测概率小于0.5的类别
pred2 = pred * (-1.0) + 1.0
# 得到两个类别的预测概率,并沿第一个维度级联
pred = paddle.concat([pred2, pred], axis=1)
acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {:.4f}/{:.4f}".format(np.mean(accuracies), np.mean(losses)))
model.train()
模型保存
paddle.save(model.state_dict(), 'palm.pdparams')
paddle.save(optimizer.state_dict(), 'palm.pdopt')
1.4 定义评估过程
# 定义评估过程
def evaluation(model, params_file_path):
#加载模型参数
model_state_dict = paddle.load(params_file_path)
model.load_dict(model_state_dict)
# 评估模式
model.eval()
eval_loader = data_loader(DATADIR, batch_size=10, mode='eval')
acc_set = []
avg_loss_set = []
# 读测试集
for batch_id, data in enumerate(eval_loader()):
x_data, y_data = data # 读入测试集的图片和对应标签
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
y_data = y_data.astype(np.int64) # 标签转换成整型
label_64 = paddle.to_tensor(y_data)
# 计算预测和精度
prediction, acc = model(img, label_64)
# 计算损失函数值
loss = F.binary_cross_entropy_with_logits(prediction, label)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 求平均精度
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={:.4f}, acc={:.4f}'.format(avg_loss_val_mean, acc_val_mean))
2. AlexNet网络在眼疾分类的应用
只有网络的模型代码有变化,深度增加
# 定义 AlexNet 网络结构
class AlexNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(AlexNet, self).__init__()
# AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征
# 与LeNet不同的是激活函数换成了‘relu’
self.conv1 = Conv2D(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
self.conv3 = Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv4 = Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv5 = Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
self.max_pool5 = MaxPool2D(kernel_size=2, stride=2)
self.fc1 = Linear(in_features=12544, out_features=4096)
self.drop_ratio1 = 0.5
self.drop1 = Dropout(self.drop_ratio1)
self.fc2 = Linear(in_features=4096, out_features=4096)
self.drop_ratio2 = 0.5
self.drop2 = Dropout(self.drop_ratio2)
self.fc3 = Linear(in_features=4096, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.conv5(x)
x = F.relu(x)
x = self.max_pool5(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.relu(x)
# 在全连接之后使用dropout抑制过拟合
x = self.drop1(x)
x = self.fc2(x)
x = F.relu(x)
# 在全连接之后使用dropout抑制过拟合
x = self.drop2(x)
x = self.fc3(x)
return x
3. 一些问题
3.1 全连接层的作用?
- 如果是最后输出层使用全连接,一般要求输出的神经元的个数等于分类标签的类别数。
- 如果是中间的隐藏层,可以看作是将不同特征所携带的信息进行组合之后提取出欣的特征信息,size越大,网络所包含的参数越多,越能拟合复杂函数,但是也有可能造成过拟合。
3.2 关于归一化
每个卷积层后都可以加一个归一化,帮助模型更快地收敛。
3.3 sigmoid
sigmoid输出的是标签为1的概率
3.4 训练的时候loss和accuract达到阈值?
- 增加样本
- 适当增加batchnorm
- 加深或者加宽网络
3.5 归一化如何做到训练计算?
提升了数值的稳定性,使得模型训练起来收敛的很快
3.6 有多个目标预测值即y的值怎么办?
输出的预测值的形状要和标签匹配
4. VGG
通过重复使用简单的基础快来构建深度模型(当前最流行的CNN模型之一)
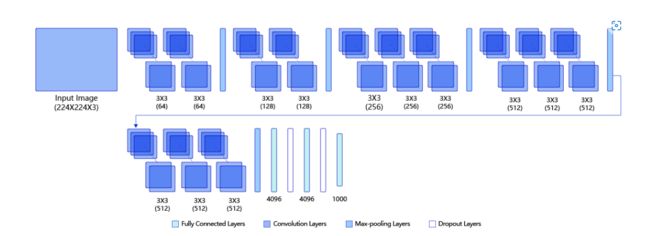
卷积层全部使用3×3的卷积核,构成了5个VGG块,再加上全连接层。
经过池化之后输出特征图会减小,进入下一层级的时候则将卷积输出通道数翻倍。
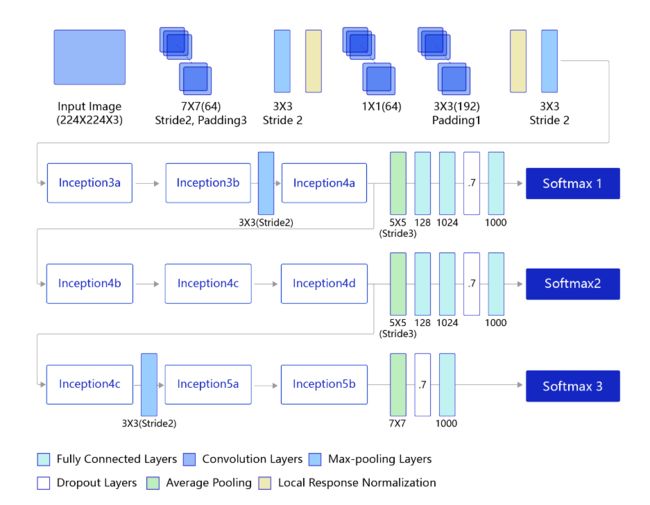
5. GoogLeNet
基础块叫做Inception块,网络不仅有深度还有宽度。

出发点:如何选取合适的卷积核大小?

设计思想:多通路设计形式,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化操作,将这四个输出层沿着通道这一维度进行拼接。最终输出特征图将包含不同大小的卷积核提取到的特征,从而达到捕捉不同尺度信息的效果。(类似电路中的并联)每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常大。为了减小参数量,Inception模块在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。
6. ResNet
在ResNet提出之前,人们发现当模型层数提升到一定程度后,再增加层数就不再能提升模型效果了——这就导致深度学习网络看似出现了瓶颈,通过增加层数来提升效果的方式似乎已经到头了。ResNet解决了这一问题。

输入特征矩阵以两个分支进入残差块,直线分支经过多个卷积层产生输出特征矩阵,**注意:**在直线残差块中,经过最后一个卷积层之后并不是立刻通过激活函数ReLU激活(残差块中除去最后一个卷积层,其他的卷积层都是产生输出特征矩阵之后立刻进行激活),而是要和shortcut分支传过来的特征矩阵相加之后再进行激活。在这里涉及到了矩阵的相加,那么就要求直线分支(主分支)和shortcut分支(旁分支)的输出特征矩阵的shape(高、宽、channel)必须相同。
- 所以残差网络到底有啥用?
可以这样理解:假如新加的这些层的学习效果非常差,那我们就可以通过一条残差边将这一部分直接“跳过”。实现这一目的很简单,将这些层的权重参数设置为0就行了。这样一来,不管网络中有多少层,效果好的层我们保留,效果不好的我们可以跳过。总之,添加的新网络层至少不会使效果比原来差,就可以较为稳定地通过加深层数来提高模型的效果了。
此外,使用残差边的另一个好处在于可以避免梯度消失的问题。因为它的这个特点,它可以训练几百甚至上千层的网络。
- 残差网络为什么可以避免梯度消失?
在没有残差边的时候,假如网络层数很深的话,要想更新底层的(靠近输入数据部分)的网络权重,首先对其求梯度,根据链式法则需要一直向前累乘,只要其中的任何一个因数过小就会导致求出来的梯度很小很小,这个小梯度就算乘以再大的学习率也是无济于事。
而当我们有了残差边时,求梯度可以直接经过“高速公路”直达我们想要求梯度的对象,此时不管通过链式法则走正常路线得到的梯度多么小,两条路线相加的结果都不会小,就可以很有效地进行梯度更新了。
- ResNet一些具体要点
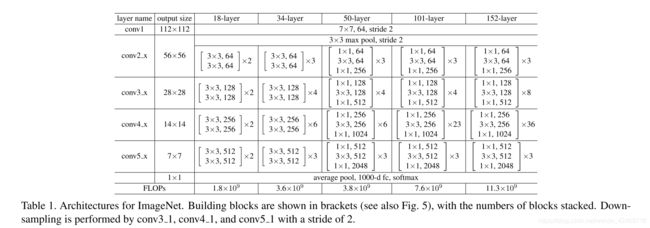
ResNet根据层数的不同分为很多种,比如上图中的每一列,也就分别对应着ResNet18,ResNet34,ResNet50等网络结构。其中ResNet152层数最多,也被普遍认为是效果最不错的(代价也是需要更多的计算量)。一般来说ResNet可以作为首选的网络去做分类任务,如果追求最高的精度就用ResNet152。
7. 一些问题
7.1 通道数的变化是如何影响图像信息的?
通道数增加,相当于图像像素点变多。如何调节输出通道数量,更多依靠经验。
7.2 为什么要分成一个一个的BLOCK?
每个block块内部的图像大小都基本是一致的,块与块之间内部有比较大的变化。
7.3 卷积核的大小和感受野的大小由关联么?
有关联,但是并不是完全取决与卷积核大小,如果卷积核很小,但是网络深度很大,感受野也可以很大。
7.4 编码器和解码器是什么?
- 编码器:输入的语音或图像,将原始的信号转换成更加抽象的信号,即将图像输入网络,经过一系列卷积和池化操作转换成特征向量,这就是编码的过程。
- 解码器:将特征图通过网络还原成一张二维图像。
7.5 遇到问题的时候是否要自己设计网络?
非常有难度,在遇到问题的时候,最简单有效的办法还是直接用别人的模型,并在这个模型上做一些微调。需要作的就是造样本,处理数据,优化模型。
7.6 参数需要修改么?
需要。比如ResNet50有很多个版本,一般会挑一个版本使用,其中的参数也会根据实际的业务进行调整。
8. 总结
- LeNet,卷积神经网络首次应用在图像识别数据集上
- AlexNet, 首个成功应用在ImageNet数据集上的深度学习模型
- VGG,通过重复使用简单的基础块来构建深度模型
- GoogLeNet,多通路设计的Inception块增加了网络宽度
- ResNet,残差块的设计方案使得网络可以设计得很深
是编码的过程。
- 解码器:将特征图通过网络还原成一张二维图像。
7.5 遇到问题的时候是否要自己设计网络?
非常有难度,在遇到问题的时候,最简单有效的办法还是直接用别人的模型,并在这个模型上做一些微调。需要作的就是造样本,处理数据,优化模型。
7.6 参数需要修改么?
需要。比如ResNet50有很多个版本,一般会挑一个版本使用,其中的参数也会根据实际的业务进行调整。
8. 总结
- LeNet,卷积神经网络首次应用在图像识别数据集上
- AlexNet, 首个成功应用在ImageNet数据集上的深度学习模型
- VGG,通过重复使用简单的基础块来构建深度模型
- GoogLeNet,多通路设计的Inception块增加了网络宽度
- ResNet,残差块的设计方案使得网络可以设计得很深