【算法面试题汇总】LeetBook列表的算法面试题汇总---字符串题目及答案
如果有错的还请各位大佬指出呀
有些是copy的还望不要介意
本人只做学习记录
字符串
-
-
- 验证回文串
- 分割回文串
- 单词拆分
- 单词拆分Ⅱ
- 实现Trie(前缀树)
- *单词搜索Ⅱ
- 有效的字母异位词
- 字符串中的第一个唯一的字符
- 反转字符串
-
验证回文串
题目描述:
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。
示例:
输入: s = "A man, a plan, a canal: Panama"
输出:true
解释:"amanaplanacanalpanama" 是回文串。
输入:s = " "
输出:true
解释:在移除非字母数字字符之后,s 是一个空字符串 "" 。
由于空字符串正着反着读都一样,所以是回文串。
直接在原字符串中动手
- 代码实现
class Solution {
public boolean isPalindrome(String s) {
int n = s.length();
int left = 0, right = n - 1;
while (left < right) {
//isLetterOrDigit判断是否是字母或数字
while (left < right && !Character.isLetterOrDigit(s.charAt(left))) {
++left;
}
while (left < right && !Character.isLetterOrDigit(s.charAt(right))) {
--right;
}
if (left < right) {
//toLowerCase转换为小写
if (Character.toLowerCase(s.charAt(left)) != Character.toLowerCase(s.charAt(right))) {
return false;
}
++left;
--right;
}
}
return true;
}
}
- 不用isLetterOrDigit
class Solution {
public boolean isPalindrome(String s) {
char[] c = s.toLowerCase().toCharArray();
int i=0, j=c.length-1;
while(i<j){
while(!isValid(c[i]) && i<j){
++i;
}
while(!isValid(c[j]) && i<j){
--j;
}
if(c[i] != c[j]){
return false;
}
++i;
--j;
}
return true;
}
private boolean isValid(char c){
return (c >= 'a' && c <= 'z') || (c >= '0' && c <= '9');
}
}
分割回文串
题目描述:
给你一个字符串 `s`,请你将 `s` 分割成一些子串,使每个子串都是 **回文串** 。返回 `s` 所有可能的分割方案。
**回文串** 是正着读和反着读都一样的字符串。
示例:
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
此处用到回溯
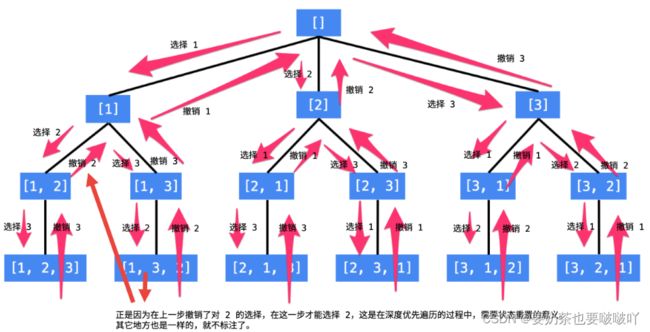
回溯需要注意的操作:
1.深度遍历时,保存所需变量,往深处走则在path尾部添加,往回走则删除尾部的
2.若此时的变量满足条件,则需要添加到结果集,注意添加时要new,在java中参数传递是值传递,对象类型变量在传参的过程中,复制的是变量的地址。所以path所指向的列表只有一份,如果不new回到根节点便会成为空列表
- 代码实现
class Solution {
List<List<String>> ans = new ArrayList<>();
public List<List<String>> partition(String s) {
dfs(s.toCharArray(),0,new ArrayList());
return ans;
}
//回溯方法
void dfs(char[]s,int startIndex,List<String> path){
if(startIndex == s.length){
ans.add(new ArrayList(path));
return;
}
for(int i=startIndex;i<s.length;i++){
if(check(s,startIndex,i)){
//此处一定要new,在java中参数传递是值传递,对象类型变量在传参的过程中,复制的是变量的地址。所以path所指向的列表只有一份,如果不new回到根节点便会成为空列表
path.add(new String(s,startIndex,i-startIndex+1));
dfs(s,i+1,path);
//删除上一步才是回溯操作,往深处走便在尾部添加,返回则删除尾部的
path.remove(path.size()-1);
}
}
}
boolean check(char[]s ,int start,int end){
while(start<=end){
if(s[start++] != s[end--]){
return false;
}
}
return true;
}
}
单词拆分
题目描述:
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。
用到动态规划
- 代码实现
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
//法一
int n = s.length();
//存储0-i的子串能否匹配,长度包括 0 ,因此状态数组的长度为 n + 1
boolean[] dp = new boolean[n+1];
//空字符串也能匹配
dp[0] = true;
for(int i=1;i<=n;i++){
for(String word : wordDict){
int len = word.length();
if(len <= i && word.equals(s.substring(i-len,i))){
dp[i] = dp[i] || dp[i-len];
}
}
}
return dp[n];
//法二
Set<String> set = new HashSet<>(wordDict);
int n = s.length();
//f[i]表示以i结尾的0~i的字符串能否在wordDict匹配
boolean f[] = new boolean[n + 1];
//空串可以匹配
f[0] = true;
for (int i = 1; i <= n; i ++ ) {
for (int j = 0; j < i; j ++ ) {
//如果j可以匹配,并且子串[j, i]存在的话,在字符串下标要减一
if (f[j] && set.contains(s.substring(j, i))) {
f[i] = true;
break;
}
}
}
return f[n];
}
}
单词拆分Ⅱ
题目描述:
给定一个字符串 s 和一个字符串字典 wordDict ,在字符串 s 中增加空格来构建一个句子,使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。
注意:词典中的同一个单词可能在分段中被重复使用多次。
示例:
输入:s = "pineapplepenapple", wordDict = ["apple","pen","applepen","pine","pineapple"]
输出:["pine apple pen apple","pineapple pen apple","pine applepen apple"]
解释: 注意你可以重复使用字典中的单词。
- 代码实现
class Solution {
//存储结果集
List<String> res = new ArrayList<>();
//存储路径
LinkedList<String> track = new LinkedList<>();
public List<String> wordBreak(String s, List<String> wordDict) {
backtrack(s,0,wordDict);
return res;
}
/**
* 回溯
* i:起始位置
*/
void backtrack(String s,int i,List<String>wordDict){
//已经拼出整个s
if(i == s.length()){
//用指定分隔符分割字符串
res.add(String.join(" ",track));
return;
}
if(i>s.length()){
return;
}
for(String word:wordDict){
int len = word.length();
if(i+len > s.length()) continue;//单词太长跳过
String subStr = s.substring(i,i+len);
if(!subStr.equals(word)) continue;//无法匹配跳过
track.addLast(word);
backtrack(s,i+len,wordDict);
track.removeLast();//回溯
}
}
}
实现Trie(前缀树)
题目描述:
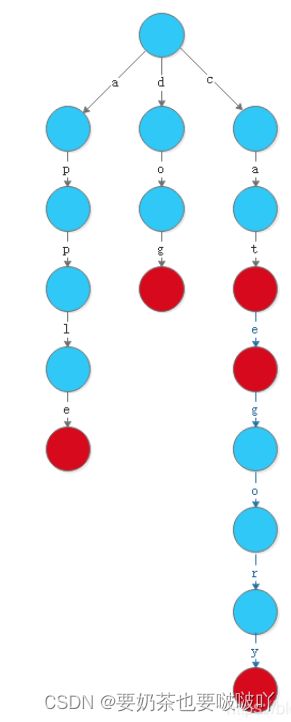
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie() 初始化前缀树对象。
void insert(String word) 向前缀树中插入字符串 word 。
boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
示例:
输入
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
- 代码实现
class Trie {
private Trie[] children;
private boolean isEnd; //设置该字母的后置位是否为单词的结尾
public Trie() {
//26个英文字母
children = new Trie[26];
//区分这个字母是否是单词的结尾
isEnd = false;
}
public void insert(String word) {
Trie node = this;
for(int i=0;i<word.length();i++){
char w = word.charAt(i);
int index = w - 'a';
//如果还没有以这个字母开头的一个分支则创建
if(node.children[index] == null){
node.children[index] = new Trie();
}
node = node.children[index];
}
//遍历到这个单词的最后一个字母要将后置位设置为true表示是一个完整的单词
node.isEnd = true;
}
public boolean search(String word) {
Trie trie = searchPrefix(word);
return trie!=null && trie.isEnd;
}
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
private Trie searchPrefix(String word){
Trie trie = this;
for(int i = 0;i<word.length();i++){
char w = word.charAt(i);
int index = w - 'a';
if(trie.children[index] == null){
return null;
}
trie = trie.children[index];
}
return trie;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
*单词搜索Ⅱ
题目描述:
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
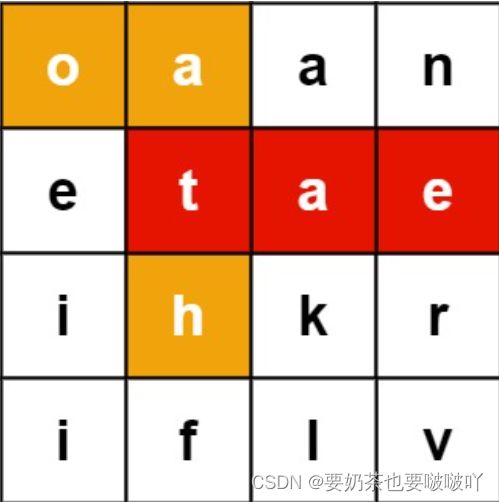
输入:board = [["o","a","a","n"],
["e","t","a","e"],
["i","h","k","r"],
["i","f","l","v"]],
words = ["oath","pea","eat","rain"]
输出:["eat","oath"]
前缀树+DFS+回溯+剪枝
- 代码实现
class Solution {
//上下左右移动方向
int[][] dirs = new int[][]{{-1,0},{1,0},{0,-1},{0,1}};
public List<String> findWords(char[][] board, String[] words) {
//结果集
List<String> res = new ArrayList<>();
//构造前缀树
TrieNode trie = buildTrie(words);
int m = board.length;
int n = board[0].length;
//记录沿途遍历到的元素
StringBuilder s = new StringBuilder();
for(int i = 0;i<board.length;i++){
for(int j=0;j<board[i].length;j++){
//从每个元素开始遍历
dfs(res,s,board,i,j,trie,trie);
}
}
return res;
}
private void dfs(List<String> res,StringBuilder s,char[][] board,int i,int j,TrieNode root,TrieNode node){
//判断越界,或者访问过,或者不在字典树,直接返回
if(i<0 || j<0 || i>=board.length || j>=board[0].length
|| board[i][j] == '#'
|| node == null || node.children[board[i][j] - 'a'] == null){
return;
}
//记录当前字符
char curr = board[i][j];
s.append(curr);
//如果有结束字符则加入结果集
if(node.children[board[i][j] - 'a'].isEnd){
String word = s.toString();
res.add(word);
deleteWordFromTrie(root,word);
}
//记录当前元素被访问过
board[i][j] = '#';
//按四个方向遍历
for(int[] dir:dirs){
dfs(res,s,board,i+dir[0],j+dir[1],root,node.children[curr - 'a']);
}
//还原状态
board[i][j] = curr;
s.deleteCharAt(s.length()-1);
}
private void deleteWordFromTrie(TrieNode root,String word){
//已经找过的从前缀树中删除,相当于剪枝优化
//先找到最后一个字符,从后往前删
delete(root,word,0);
}
//返回true表示可以将沿途节点删除
private boolean delete(TrieNode root,String word,int i){
if(i == word.length()-1){
//如果后面还有单词则不能直接删除,比如dog和dogs在同一个分支上
TrieNode curr = root.children[word.charAt(i) - 'a'];
if(hasChildren(curr)){
curr.isEnd = false;
return false;
}else{
root.children[word.charAt(i) - 'a'] = null;
return true;
}
}else{
//有dog和dig两个单词时,删除dog返回到d时d是不能删除的,也就是没有其他子节点
//后面没有节点了,也就是不能删除dogs中的dog
if(delete(root.children[word.charAt(i) - 'a'],word,i+1)
&& !root.children[word.charAt(i) - 'a'].isEnd
&& !hasChildren(root.children[word.charAt(i) - 'a'])){
root.children[word.charAt(i) - 'a'] = null;
return true;
}
return false;
}
}
private boolean hasChildren(TrieNode curr){
for(TrieNode child:curr.children){
if(child != null){
return true;
}
}
return false;
}
private TrieNode buildTrie(String[] words){
TrieNode root = new TrieNode();
for(String word: words){
char[] arr = word.toCharArray();
TrieNode curr = root;
for(char c:arr){
if(curr.children[c - 'a'] == null){
curr.children[c - 'a'] = new TrieNode();
}
curr = curr.children[c - 'a'];
}
curr.isEnd = true;
}
return root;
}
class TrieNode{
TrieNode[] children = new TrieNode[26];
boolean isEnd = false;
}
}
有效的字母异位词
题目描述:
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
提示:
1 <= s.length, t.length <= 5 * 104
s 和 t 仅包含小写字母
进阶: 如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
输入: s = "anagram", t = "nagaram"
输出: true
- 代码实现
class Solution {
public boolean isAnagram(String s, String t) {
if(s.length() != t.length()){
return false;
}
//对于进阶问题,Unicode 中可能存在一个字符对应多个字节(字符是离散未知的),
//所以用hash表维护对应字符的频次便可
Map<Character,Integer> map = new HashMap<>();
for(int i=0;i<s.length();i++){
char ch = s.charAt(i);
//getOrDefault(Object key, V defaultValue),如果有这个key则用对应的值,如果没有则用defaultValue
map.put(ch,map.getOrDefault(ch,0) + 1);
}
for(int j=0;j<t.length();j++){
char ch = t.charAt(j);
map.put(ch,map.getOrDefault(ch,0) - 1);
if(map.get(ch)<0){
return false;
}
}
return true;
}
}
字符串中的第一个唯一的字符
题目描述:
给定一个字符串 `s` ,找到 *它的第一个不重复的字符,并返回它的索引* 。如果不存在,则返回 `-1`
输入: s = "leetcode"
输出: 0
- hashmap代码实现
class Solution {
public int firstUniqChar(String s) {
Map<Character,Integer> map = new HashMap<>();
for(int i=0;i<s.length();i++){
char ch = s.charAt(i);
map.put(ch,map.getOrDefault(ch,0)+1);
}
for(int j = 0;j<s.length();j++){
if(map.get(s.charAt(j)) == 1){
return j;
}
}
return -1;
}
}
-
字符串的api
当它的某个字符的第一次出现的位置和最后一次出现的位置下标相同则表示该字符只出现了一次
class Solution {
public int firstUniqChar(String s) {
for(int i=0;i<s.length();i++){
if(s.indexOf(s.charAt(i))==s.lastIndexOf(s.charAt(i))){
return i;
}
}
return -1;
}
}
- int数组(最优)
class Solution {
public int firstUniqChar(String s) {
//每个字母出现的次数
int[] count = new int[26];
//char数组比字符串遍历更快
char[] charArr = s.toCharArray();
for(char c:charArr){
count[c - 'a']++;
}
for(char c:charArr){
if(count[c-'a'] == 1){
return s.indexOf(c);
}
}
return -1;
}
}
反转字符串
题目描述:
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
输入:s = ["h","e","l","l","o"]
输出:["o","l","l","e","h"]
- 代码实现
class Solution {
public void reverseString(char[] s) {
int n = s.length;
int left = 0,right = n-1;
while(left<right){
char temp = s[right];
s[right] = s[left];
s[left] = temp;
left++;
right--;
}
}
}