nvcc编译器之设备和主机独立编译(chapter 6)
目录
6. CUDA中的独立编译
6.1 单独编译时的代码改动
6.2 nvcc独立编译选项
6.3 库
6.4 示例
6.5 分布编译优化
6.6 独立编译的潜在问题
6. CUDA中的独立编译
在5.0版本之前,CUDA不支持分开编译,因此CUDA代码不能访问跨文件(编译单元)的设备函数或变量, 这种编译称为全程序编译。cuda一直都支持单独编译主机侧代码,实际上,只有设备端CUDA代码在单文件中需要支持。从CUDA 5.0开始,支持了单独编译设备端代码,但旧的全程序编译模式仍然是默认的方式,所以有新的选项来触发单独编译 。
6.1 单独编译时的代码改动
单独编译设备端(GPU)代码所需对主机端代码的更改,与单主机端(CPU)代码分文件编译相同,即使用extern和static来控制符号的可见性。注意,之前(cuda 5.0前面)的extern,在CUDA代码中被忽略了,5.0之后则不会。通过使用static,可以在不同的文件中,使用多个具有相同名称的设备符号。由于这个原因,通过字符串名称引用符号的CUDA API调用被弃用了,取而代之,应该由使用API的地址。
6.2 nvcc独立编译选项
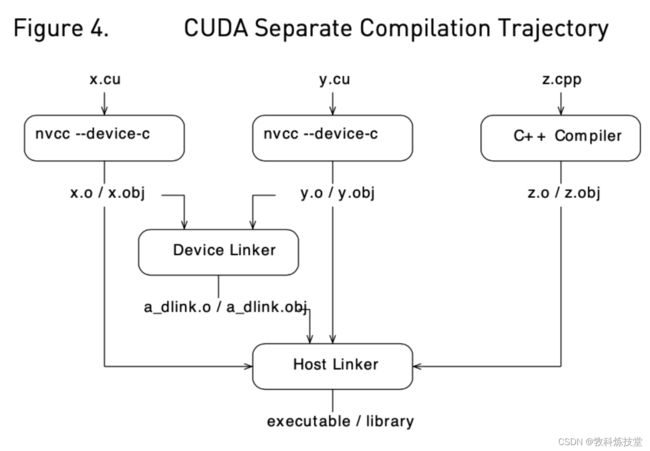
CUDA的工作原理是将设备端代码嵌入到主机目标对象中。 在全程序编译模式中,CUDA将可执行的设备代码嵌入到主机对象(object)。
在独立(分开)的编译中,则将可重定位设备代码嵌入到主机对象中,并通过运行nvlink(设备链接器),将所有设备代码链接到一起。 然后,nvlink的输出,再通过主机链接器与所有主机侧目标对象链接在一起,形成最终的可执行文件。
可重定位与可执行设备代码的生成是由--relocatable-device-code选项控制的.
--compile选项已经被用于控制主机端编译器对对象的编译,所以添加了一个新选项--device-c,等同于--relocable-device-code=true --compile。
需要只调用设备端链接器时,可以使用--device-link选项,它给出一个包含嵌入式可执行设备代码的主机侧目标对象。然后,它的输出必须传递给主机链接器。
或者,使用nvcc
图4显示了流程(nvcc --device-c具有与#unique_50/unique_50_connect_42_cuda-compiler-from-cu-to-o相同的流程)
6.3 库
设备链接器具有读取主机侧静态库的能力(Linux和Mac OS X上的.a,Windows上.lib),但它忽略任何动态(.so或.dll)库。可以使用--library和--library-path选项将库传递给设备端和主机端链接器。当使用--library选项时,指定的库名没有库文件扩展名:
nvcc --gpu-architecture=sm_50 a.o b.o --library-path= --library=foo 或者,在windows上,不使用--library选项时可以使用带后缀名的库名。
nvcc --gpu-architecture=sm_50 a.obj b.obj foo.lib --library-path= 注意,设备链接器忽略任何没有可重定位设备代码的主机目标对象。
6.4 示例
//---------- b.h ----------
#define N 8
extern __device__ int g[N];
extern __device__ void bar(void); //---------- b.cu ----------
#include "b.h"
__device__ int g[N];
__device__ void bar (void)
{
g[threadIdx.x]++;
} //---------- a.cu ----------
#include
#include "b.h"
__global__ void foo (void) {
__shared__ int a[N];
a[threadIdx.x] = threadIdx.x;
__syncthreads();
g[threadIdx.x] = a[blockDim.x - threadIdx.x - 1];
bar();
}
int main (void) {
unsigned int i;
int *dg, hg[N];
int sum = 0;
foo<<<1, N>>>();
if(cudaGetSymbolAddress((void**)&dg, g)){
printf("couldn't get the symbol addr\n");
return 1;
}
if(cudaMemcpy(hg, dg, N * sizeof(int), cudaMemcpyDeviceToHost)){
printf("couldn't memcpy\n");
return 1;
}
for (i = 0; i < N; i++) {
sum += hg[i];
}
if (sum == 36) {
printf("PASSED\n");
} else {
printf("FAILED (%d)\n", sum);
}
return 0;
} Linux 环境的编译命令如下:
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 a.o b.o如果想分步触发设备和主机侧的链接器,则如下操作:
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file device_link.o
g++ a.o b.o device_link.o --library-path= --library=cudart 需要注意,所有运行的目标架构都必须传递给设备链接器(因此使用了sm_50,忽略--gpu-code使得其默认值也是cm_50),因为它指定了最终可执行文件中的生成内容(一些objects对象或库可能包含多个目标架构的设备代码,链接步骤因而会选择将哪些代码编译放入最终可执行文件中)。
如果想使用driver API来加载一个已经链接过的cubin二进制,可以直接使用--cubin生成设备端二进制代码(.cubin格式):
nvcc --gpu-architecture=sm_50 --device-link a.o b.o \
--cubin --output-file link.cubin使用--lib将上述目标生成库(设备链接器只支持静态库) :
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --lib a.o b.o --output-file test.a
nvcc --gpu-architecture=sm_50 test.aptx码文件可以被编译到主机目标文件,并被链接使用:
nvcc --gpu-architecture=sm_50 --device.c a.ptx使用库、主机链接器、动态机制,示例:
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file link.o
nvcc --lib --output-file libgpu.a a.o b.o link.o
g++ host.o --library=gpu --library-path= \
--library=cudadevrt --library cudart 可以在一个主机端的可执行文件中链接多个设备端目标,只要每个设备链接是相互独立的。这种独立性要求,不能在跨设备可执行文件间共享代码,也不能共享地址(例如,可以从主机侧传递一个主机侧的函数地址给设备,以便设备侧进行回调,但这只有在设备链接时可以同时看到caller和潜在的回调callee(调用者)时才行得通。无法将一个设备可执行文件中的地址传递到另一个设备可执行文件中,因为它们是独立的地址空间)。
6.5 分布编译优化
单独编译的代码可能没有全程序代码编译那么高的性能,因为不能跨文件内联代码(inline)。
获得最佳性能的一个方法是使用链接时优化(link-time optimization),它存储中间代码,然后将中间代码链接在一起以执行高级别的优化。这可以通过--dlink-time-opt或-dlto选项支持,此选项必须在编译和链接同时指定。如果只是部分文件使用-dlto编译,则这些文件将被链接和优化在一起,其余的使用普通的单独编译。副作用是,这会将一些编译时间转移到链接阶段,并且对于真正的大型代码可能存在一些可扩展性问题。如果你想使用-gencode编译到多个目标架构(arch),使用-dc -gencode arch=compute_NN,code=lto_NN来指定要存储的中间IR(其中NN是SM架构版本)。然后使用-dlto选项链接特定的架构。对于LTO代码没有运行时JIT支持,因此需要静态链接到最终的sm_NN架构。作为一个review功能,CUDA 11.4的驱动程序API支持LTO下的JIT,请参阅CUDA驱动程序API文档获取更多信息。
6.6 独立编译的潜在问题
6.6.1 目标文件的兼容性
只有具有相同ABI版本、链接兼容的SM目标架构以及相同指针大小(32或64)的可重定位设备代码才能链接在一起。 不兼容的对象将产生链接错误。链接兼容的SM目标架构,具有兼容的SASS二进制文件,这些二进制文件无需转换就可以组合,例如:sm_52和sm_50。
一个对象可能已经被编译为支持不同的架构,但同时也包含PTX码。在这种情况下,设备连接器将把PTX 码即时编译(JIT)到所需目标架构的cubin二进制,然后进行链接。可重定位设备代码,需要CUDA 5.0或更高版本的Toolkit。
如果使用launch_bounds属性或--maxrregcount选项,将内核函数使用的寄存器限制在一定数量,那么内核调用的所有函数,都不能使用超过这个数量的寄存器;如果它们超过了限制,那么将给出一个链接错误。
6.6.2 JIT链接支持
CUDA 5.0不支持JIT(即时)链接,而CUDA 5.5支持。这意味着要使用JIT链接,必须使用CUDA 5.5或更高版本重新编译代码。
JIT链接意味着在启动时对代码进行重新链接。 设备链接器(nvlink)在cubin层进行链接。如果cubin在加载时与目标架构不匹配,驱动程序将重新调用设备链接器来,为目标架构生成cubin。方法是:首先将每个对象的PTX码即时编译(JIT)到适当的cubin,然后将新的cubin链接在一起。
6.6.3 隐式CUDA主机代码
像上面的b.cu这样的文件只包含CUDA设备代码,所以可能会认为b.o对象不需要传递给主机链接器。但实际上,只要设备符号可以从主机端访问,就会生成隐式的主机代码,无论是通过launch还是像cudaGetSymbolAddress()这样的API调用。
这个隐式的主机代码放在b.o中,需要传递给主机链接器。另外,为了支持即时编译(JIT)的链接,所有设备代码都必须传递给主机链接器,否则主机可执行文件将不包含即时编译(jit)链接所需的设备代码。
所以,一般的规则是设备链接器和主机链接器必须看到相同的主机目标文件(如果该主机目标文件中有任何设备端的引用;如果一个目标文件是纯主机文件,那么设备链接器就不需要看到它)。如果一个包含设备代码的目标文件没有传递给主机链接器,那么你将看到一个关于函数__cudaRegisterLinkedBinary_name调用一个未定义或未解析的符号__fatbinwrap_name的错误消息。
6.6.4 使用__CUDA_ARCH__宏
在单独的编译中,不能在头文件中使用__CUDA_ARCH__宏,这样不同的目标对象可能包含不同的行为。或者,必须保证所有对象都为同一个compute_arch编译。如果在头文件中定义了一个弱函数或模板函数,并且它的行为依赖于__CUDA_ARCH__,那么如果目标对象为不同的compute arch编译,该函数在对象中的实例可能会发生冲突。例如,a.h包含:
template
__device__ T* getptr(void)
{
#if __CUDA_ARCH__ == 500
return NULL; /* no address */
#else
__shared__ T arr[256];
return arr;
#endif
} 如果a.cu和b.cu都include了a.h,并且实例化了相同类型的getptr,而b.cu需要一个非null地址,编译时使用:
nvcc --gpu-architecture=compute_50 --device-c a.cu
nvcc --gpu-architecture=compute_52 --device-c b.cu
nvcc --gpu-architecture=sm_52 a.o b.o在链接时,只使用getptr的一个版本,因此行为将取决于选择的版本(为不同架构编译的不同版本)。为了避免这种情况,a.cu和b.cu必须编译为同一个计算架构,否则在共享头函数中不应该使用__CUDA_ARCH__。
6.6.5 库中的设备代码
如果一个使用非weak(弱符号)的外部链接设备函数,该函数符号同时定义在一个库和非库对象(或另一个库)中,设备链接器将产生多个定义(这有别于传统主机连接器,可以忽略库中的函数对象定义,如果它已经在前面的目标对象中找到该函数符号)的链接错误。
关于作者:
犇叔,浙江大学计算机科学与技术专业,研究生毕业,而立有余。先后在华为、阿里巴巴和字节跳动,从事技术研发工作,资深研发专家。主要研究领域包括虚拟化、分布式技术和存储系统(包括CPU与计算、GPU异构计算、分布式块存储、分布式数据库等领域)、高性能RDMA网络协议和数据中心应用、Linux内核等方向。
专业方向爱好:数学、科学技术应用
关注犇叔,期望为您带来更多科研领域的知识和产业应用。
内容坚持原创,坚持干货有料。坚持长期创作,关注犇叔不迷路