【论文简述】P-MVSNet: Learning Patch-wise Matching Confidence Aggregationfor Multi-View Stereo(CVPR 2019)
一、论文简述
1. 第一作者:Keyang Luo
2. 发表年份:2019
3. 发表期刊:ICCV
4. 关键词:MVS、块匹配、置信度、代价聚合
5. 探索动机:参考图像的像素,各向同性和各向异性
1. A popular matching metric used in most existing methods is the variance of features between the pair of pixels, in which the contributions of all involved pixel pairs to the matching cost are treated equally. Such metric is often not conducive to the pixel-wise dense matching actually. For instance, when the features of a pixel in adjacent non-reference images are very similar but do not match the corresponding feature in the reference image, a low matching cost will be generated for this pixel, which potentially tends to give it a wrong estimation in the depth map.
2. After accumulating the matching confidences from multiple images on each of the sampled planes and storing them in a cost volume, current methods usually regularize the pixel-wise cost volume or infer the depth-map directly, which is not very robust to noisy data. Moreover, the constructed plane-sweep volume contained in the corresponding frustum is essentially anisotropic – we can infer the corresponding depth map along the depth direction of the matching cost volume, but cannot get the same information along other directions.
写太好了,不忍心翻译
6. 工作目标:在计算匹配置信度时,应强调参考图像中像素的重要性,并充分利用代价体在深度和空间方向上的各向异性。基于以上思考,是否可以提出更高效的结构?
7. 核心思想:本文提出了一种基于各向同性和各向异性三维卷积的多视点立体视觉端到端深度学习网络P-MVSNet。
- 提出了一个基于学习的图像块匹配置信度聚合模块来构建匹配代价体,通过设计特定卷积核对通道、图像块、深度信息进行聚合,该模块对于有噪声的数据具有鲁棒性和准确性;
混合3DUnet模块将置信体变成概率体,通过对普通的3DUnet的浅层卷积核做变化, - 设计了一个混合的3D U-Net,提出各向异性的1x3x3融合空间及通道信息、7x1x1扩大深度感受野,最后再在深层用各向同性3x3x3融合上下文信息,从匹配的置信体推断出潜在的概率体,并估计深度图;
- 开发了用于过滤和融合深度图的深度置信度和深度一致性标准,以提高点云重建的准确性和完整性。
8. 实验结果:在DTU和Tanks &Temple基准数据集上进行了大量的实验,结果表明,在MVS中P-MVSNet取得了最先进的性能,超过了许多现有的方法。
9.论文下载:
https://openaccess.thecvf.com/content_ICCV_2019/papers/Luo_P-MVSNet_Learning_Patch-Wise_Matching_Confidence_Aggregation_for_Multi-View_Stereo_ICCV_2019_paper.pdf
二、实现过程
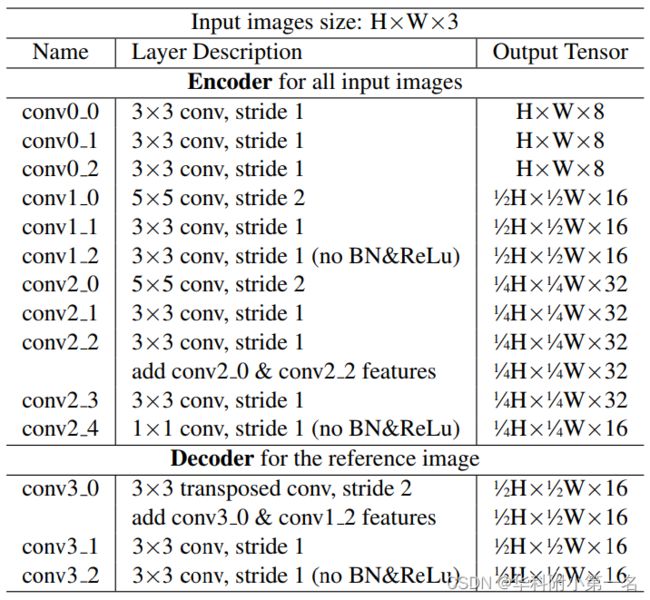
1. P-MVSNet概述
P-MVSNet是一种端到端的深度学习神经网络,包括一个权重共享图像特征提取器(蓝色),一个图像块匹配置信度聚合模块(浅蓝色),一个基于混合3D U-Net的深度图推理网络(橙色)和一个提高估计深度图空间分辨率的改进结构(绿色)。

2. 学习部分
2.1. 权重共享特征提取网络
输入一张reference image 和N-1张adjacent images,然后使用编码部分提取特征图Fi,为原图1/4分辨率的16通道的特征图,用于构建匹配置信体(MCV)。编码部分对参考图像F0进行卷积,产生为原图1/2分辨率的16通道的特征图,用于指导高分辨率深度图的估计。
2.2. 学习图像块匹配置信度
计算pixel-wise MCV
将逐像素的MCV代价体表示为M = M(d, p, c),表示第c个特征通道中F0的像素p与其相邻特征图的平面假设πd (d为πd的深度值,也就是假设的真实深度)推导出的对应像素p‘之间的的匹配置信度。因此,M是形状为[Z, H/4, W/4, C]的张量,其中Z表示采样假设平面数,C代表特征图通道数。定义为:

即计算参考特征图F0上的点p与所有相邻特征图Fj上的对应点p’,计算两者差值的平方,求和后取平均值作为e的负指数。该方法与MVSNet的取方差法区别在于,方差法中各视图下的对应特征点起到了均等的作用,而该方法是让各源图像对应点与参考图特征点求差值,因此强调了参考图上特征的作用。
聚合patch-wise MCV
接下来,学习基于πd上像素p周围的一个图像块聚合上文的M,获得patch-wise MCV,M*(d, p, c)定义为:

Ω1是指在假设平面πd上以p为中心的3x3的图像块;ρ2是使用1x3x3为卷积核的3D卷积块,后接BN和ReLU,该部分作用是聚合每个图像块内的匹配信息;ρ1是使用1x1x1为卷积核的3D卷积块(后接BN和ReLU),作用是聚合各点在不同通道的匹配置信度。
Ω2是沿深度方向上相邻3个patch块的集合,ρ3是使用3x3x3为卷积核的3D卷积块,后接BN,作用是在深度方向上聚合多个图像块的置信度,最终使用tanh函数激活来正则化置信度。
2.3. 深度图推断
该过程中的数字2和1分别代表尺度大小,l2是指[H/4, W/4]的正常尺度,l1是指[H/2, W/2]尺度。
2.3.1. Hybrid 3D Unet
首先将聚合得到的M*输入混合3D UNet得到隐式概率体(Latent Probability Volume,LPV),V2 = V2(d, p),表示F0的每个像素沿深度方向的潜在概率分布,其大小为Z × H/4 × W/4。与普通的3D Unet相比,混合3D U-Net由多个各向异性和各向同性的三维卷积块和一个深层聚集层组成,简单理解就是3x3x3这种各个方向尺度都相同的卷积核具有各向同性,而1x3x3这种就是各向异性。
在较浅层,分别使用两种各向异性的卷积核1x3x3和7x1x1进行卷积:
- 1x3x3主要是在同一个采样深度平面上融合信息
- 7x1x1可以在深度方向上扩大感受野,以较低的计算成本利用全局信息
在较深层和输出层使用各向同性(正常的)3x3x3卷积核来融合更多上下文信息。
Hybrid 3D Unet网络结构图如下所示:

2.3.2. 计算深度图
对上一步输出的隐式概率体,沿深度使用softmax,得到各点沿深度方向概率和为1的概率体P2,在加权求和回归得到深度图:

2.3.3 计算更高分辨率深度图
事实上,深度图Dl2往往分辨率较低,因此我们使用l1特征图F0 '通过改进结构指导分辨率较高的深度图Dℓ1的估计。
(1)利用特征提取步骤中解码获得的特征图F‘0[H/2, W/2, C],与论文中3.1得到的隐式概率体V2上采样后的隐式概率体V2’[H/2, W/2, Z]沿通道方向连接得到一个尺寸为[H/2,W/2, C+Z]的输入;
(2)输入通过一个包含三个2D卷积层的网络,分别输出通道数为C+Z、Z、Z,其中前两层附加了BN和ReLU操作,最后输出隐式概率体V1;
(3)对隐式概率体V1重复论文中3.2和3.3的操作得到具有更高分辨率的深度图Dl1。
2.4. Loss
对于深度回归,计算真实深度图和预测深度图(L1和L2分辨率)的差值,即

其中Φ2和Φ1是带标签的像素集,D⋆ℓ1和D⋆ℓ2是相应的真值深度图。超参数α控制了这两项的相对重要性,在实验中将其设置为0.5。
3. 非学习部分
3.1. 点云重建
P-MVSNet推导出N个参考图像的原始深度图,由于估计深度的误差,它们可能在公共区域上不太一致。为此论文引入两个滤波准则,来去除错误预测的深度值。其实就是MVSNet中的两种后处理准则稍加变化和应用,然后对不同深度图进行融合并重建点云。
- 深度置信度准则(depth-confidence criterion) : 去除明显不可信的预测
- 深度一致性准则(depth-consistency criterion): 舍弃相邻图像间不一致的深度值
深度置信度准则。很明显,当像素p沿深度方向的概率分布有一个单峰时,估计的深度具有很大的置信度。我们首先定义粗分辨率层深度图Dl2对应的置信图C2为:
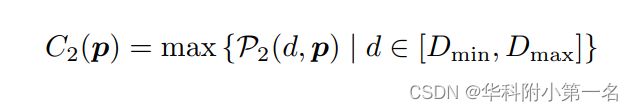
更精细层Dl1对应的置信度图C1计算如下:我们先将C2上采样至与Dl1相同的大小,记为U1,然后计算Dl1在p处的置信度为

深度置信度准则的目的是过滤出置信度较低的预测深度:对于深度图中的每个像素,如果其置信度低于ξ值(实验中设置ξ = 0.5),则认为该像素为不可靠深度,并将其丢弃。
深度一致性准则。用于加强多个相邻深度图之间预测深度的一致性。为了实现这一目标,我们首先将参考像素p通过其估计深度d(p)(根据需要可以是dl1或dl2深度图)投影到另一个深度图上,并通过以下方法确定其对应的像素q:
如果真实相机参数可用,则采用标准的双线性深度方案,否则采用“深度一致性优先”策略,如图所示。然后通过深度估计d(q)将q重新投影回参考深度图。如果重投影点q'及其深度d(q')满足 |q'−p|< E和 d(q')−d(p)|/d(p) < η (E = 0.9,η = 0.01),则认为这两个深度图在p处的预测深度d(p)是一致的。如果预测深度d至少能在μ(实验设定μ = 2)个相邻深度图保持一致,则认为是可靠的预测。该策略可以提高融合点云的完整性。
- 最近邻深度:选择离真实对应点p’距离最近的点a
- 标准双线性深度:使用双线性插值获取并使用点p’
- 深度一致优先深度:使用与点p对应3D点P真实深度最接近的点q

4. 实验
4.1. 数据
DTU Dataset:the mean errors of the reconstruction accuracy and completeness, and the overall errors which is the average of the former two. The accuracy is measured as the distance from the reconstructed point cloud to the ground truth, while the completeness is defined as the distance from the ground truth to the reconstructed point cloud. Therefore, the lower the values of the three metrics, the better the reconstruction quality.
数据集介绍:The DTU robot image dataset is a large scale multi-view stereo benchmark. It composes of 124 different scenes and each scene captures 49 or 64 images of resolution 1600 × 1200 pixels under seven different lighting conditions. The difference of material, texture and geometric property of captured scenes varies greatly and the provided ground-truth point clouds are acquired by a structured light scanner.There are a total of 27,097 images used for training of P-MVSNet. Notice that ground-truth models are not always complete and may contain holes in some areas.
Tanks and Temples Benchmark:The F-score is used as the evaluation metric, which can measure the accuracy and completeness of the reconstructed models simultaneously.
数据集介绍:Unlike the DTU dataset acquired under well-controlled laboratory environment, the Tanks & Temples dataset benchmark sequences were acquired under realistic conditions. Its intermediate set consists of eight scenes: Family, Francis, Horse, Lighthouse, M60, Panther, Playground, and Train. These captured scenes have varying scales, surface reflection and exposure conditions, moreover, no camera parameter information is provided for them. We will use this dataset to validate the generalization ability of the tested methods.
目前看到的最详细的数据集介绍了。
4.2. 模型设定
通过TensorFlow实现,在一张Nvidia Titan RTX GPU显卡上,使用DTU数据集训练,训练图像大小设置为W × H = 640 × 512,输入视图数N = 3,深度假设的采样范围为425mm至905mm,间隔为2mm,D = 256。为了提高训练网络的泛化性能,将P-MVSNet的训练过程分为两个阶段,先用Adam作为优化器(收敛快速),再用SGD。
4.3. Ablation Studies
评价预测深度图的质量,根据平均绝对深度误差以及预测精度:

其中,R表示评估的像素集,d和d*分别为预测深度和真实深度,τ为距离阈值,[·]为艾弗森括号。这里设置τ分别为σ和3σ,其中σ是两个相邻假设平面之间的距离。

P-MVSNet的不同模型变体与MVSNet生成的深度图的在DTU数据集上的比较。
4.4. 与现有方法的比较
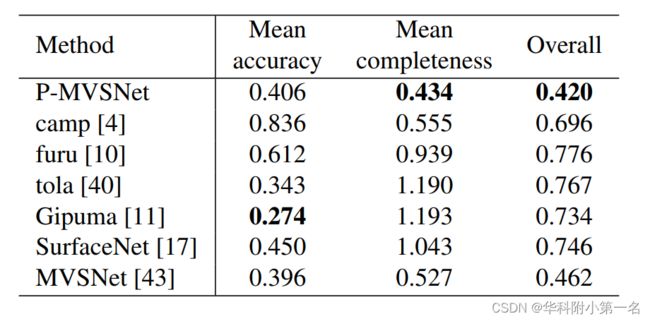 DTU的融合3D点云的性能结果。
DTU的融合3D点云的性能结果。
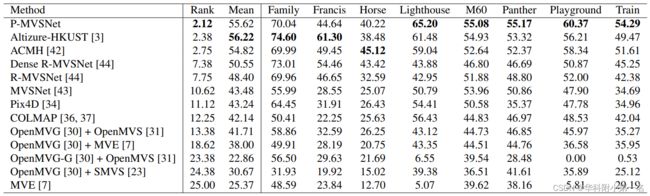
在Tanks and Temples数据集上不同方法的性能结果,最优算法与一些经典的传统算法的比较。