Python全栈开发-数据分析-02 Pandas详解 (上)
Pandas详解 (上)
一. 安装pandas
1.按Win+R,输入CMD确定,
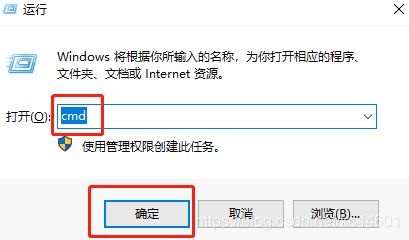
输入 pip install pandas 回车

还要安装xlrd,否则你打不开Excel文件
pip install xrld
![]()
二. 数据类型与新建文件
| 数据类型 | 说明 | 新建方法 |
|---|---|---|
| csv、tsv、txt | 用逗号分隔、tab分割的纯文本文件 | pd.to_csv |
| excel | xls或xlsx | pd.to_excel |
| mysql | 关系数据库表 | pd.to_sql |
2.1 新建空白Excel文件
示例 :
import pandas as pd
path = 'c:/pandas/新建空白文件.xlsx'
data = pd.DataFrame( )
data.to_excel(path)
print('新建空白文件.xlsx成功')
2.2 新建文件同时写入数据
案例 :
import pandas as pd
path = r'E:\Desktop\text\新建空白文件.xlsx'
data=pd.DataFrame({'id':[1,2,3],'姓名':['叶问','李小龙','落空空']})
data.to_excel(path)
print('新建空白文件.xlsx成功')
运行结果如下:
新建空白文件.xlsx成功
并在对应文件夹内成功创建excel表格,内容与其一致

2.3 将id设置为索引
案例 :
import pandas as pd
path = r'E:\Desktop\text\新建空白文件.xlsx'
data = pd.DataFrame({'id':[1,2,3],'姓名':['叶问','李小龙','落空空']}) # 写入的数据
data = data.set_index('id') # 将id设置为索引
data.to_excel(path) # 将数据写入Excel文件
print(data)
运行结果为:
姓名
id
1 叶问
2 李小龙
3 落空空
三. 读取数据
| 数据类型 | 说明 | 读取方法 |
|---|---|---|
| csv、tsv、txt | 默认逗号分隔 | pd.read_csv |
| csv、tsv、txt | 默认\t分隔 | pd.read_table |
| excel | xls或xlsx | pd.read_excel |
| mysql | 关系数据库表 | pd.read_sql |
3.1 读取CSV文件
案例:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件001-005\读取文件.csv'
data = pd.read_csv(path)
print(data)
print('==='*20)
# 二、查看前几行数据
print(data.head()) # 默认是5行,指定行数写小括号里
print('==='*20)
# 三、查看数据的形状,返回(行数、列数)
print(data.shape)
print('==='*20)
# 四、 查看列名列表
print(data.columns)
print('==='*20)
# 五、查看索引列
print(data.index)
print('==='*20)
# 六、查看每一列数据类型
print(data.dtypes)
运行结果为:
Unnamed: 0 男 杨过 19 13901234567 终南山古墓 2000/1/1
0 0 女 小龙女 25 13801111111 终南山古墓 2000/1/2
1 1 男 郭靖 40 13705555555 湖北襄阳 2020/1/1
2 2 女 黄蓉 35 13601111111 湖北襄阳 2000/1/4
3 3 男 张无忌 18 13506666666 明教 2000/1/5
4 4 女 周芷若 17 13311111111 明教 2000/1/6
5 5 女 赵敏 17 18800000000 明教 2000/1/7
============================================================
Unnamed: 0 男 杨过 19 13901234567 终南山古墓 2000/1/1
0 0 女 小龙女 25 13801111111 终南山古墓 2000/1/2
1 1 男 郭靖 40 13705555555 湖北襄阳 2020/1/1
2 2 女 黄蓉 35 13601111111 湖北襄阳 2000/1/4
3 3 男 张无忌 18 13506666666 明教 2000/1/5
4 4 女 周芷若 17 13311111111 明教 2000/1/6
============================================================
(6, 7)
============================================================
Index(['Unnamed: 0', '男', '杨过', '19', '13901234567', '终南山古墓', '2000/1/1'], dtype='object')
============================================================
RangeIndex(start=0, stop=6, step=1)
============================================================
Unnamed: 0 int64
男 object
杨过 object
19 int64
13901234567 int64
终南山古墓 object
2000/1/1 object
dtype: object
3.2 自己制定分隔符、列名
案例:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件001-005\读取文件.xlsx'
data = pd.read_excel(path, header=None, names=['序号', '姓名', '年龄', '手机', '地址', '入职日期'],index_col='序号')
print(data)
运行结果为:
姓名 年龄 手机 地址 入职日期
序号
序号 姓名 年龄 手机 地址 入职日期
序号 姓名 年龄 手机 地址 入职日期
序号 姓名 年龄 手机 地址 入职日期
1 杨过 19 13901234567 终南山古墓 2000-01-01 00:00:00
2 小龙女 25 13801111111 终南山古墓 2000-01-02 00:00:00
3 郭靖 40 13705555555 湖北襄阳 2000-01-03 00:00:00
4 黄蓉 35 13601111111 湖北襄阳 2000-01-04 00:00:00
5 张无忌 18 13506666666 明教 2000-01-05 00:00:00
6 周芷若 17 13311111111 明教 2000-01-06 00:00:00
7 赵敏 17 18800000000 明教 2000-01-07 00:00:00

注意:你的txt文档必需另存为utf-8编码,如果是ASCII报错
| 参数 | 描述 |
|---|---|
| sep | 分隔符或正则表达式 sep=’\s+’ |
| header | 列名的行号,默认0(第一行),如果没有列名应该为None |
| names | 列名,与header=None一起使用 |
| index_col | 索引的列号或列名,可以是一个单一的名称或数字,也可以是一个分层索引 |
| skiprows | 从文件开始处,需要跳过的行数或行号列表 |
| encoding | 文本编码,例如utf-8 |
| nrows | 从文件开头处读入的行数 nrows=3 |
3.3 txt文件转csv文件
案例 :
import pandas as pd
data = pd.read_csv(r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件001-005\读取文件.txt')
data.to_csv(r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件001-005\读取文件.csv')
print(data)
运行结果为:
男 杨过 19 13901234567 终南山古墓 2000/1/1
0 女 小龙女 25 13801111111 终南山古墓 2000/1/2
1 男 郭靖 40 13705555555 湖北襄阳 2020/1/1
2 女 黄蓉 35 13601111111 湖北襄阳 2000/1/4
3 男 张无忌 18 13506666666 明教 2000/1/5
4 女 周芷若 17 13311111111 明教 2000/1/6
5 女 赵敏 17 18800000000 明教 2000/1/7
3.4 读取MySQL数据库
案例 :
import pandas as pd
import pymysql
pd_sql = pymysql.connect(host='localhost', user='这里填用户', password='这里填密码', database='这里填数据库名', charset='utf8')
data = pd.read_sql('select * from class1', con=这里填连接对象)
print(data)
3.5 读取Excel文件
案例:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件001-005\读取文件.xlsx'
data = pd.read_excel(path, header=None, names=['序号', '姓名', '年龄', '手机', '地址', '入职日期'],index_col='序号')
print(data)
data.to_excel(path) # 写入到Excel文件
运行结果为:
注意 : 在这里刚开始不能正常保存excel文件
后来安装了pyexcel-xls才能正常保存
pip install pyexcel-xls
姓名 年龄 手机 地址 入职日期
序号
1 杨过 19 13901234567 终南山古墓 2000-01-01
2 小龙女 25 13801111111 终南山古墓 2000-01-02
3 郭靖 40 13705555555 湖北襄阳 2000-01-03
4 黄蓉 35 13601111111 湖北襄阳 2000-01-04
5 张无忌 18 13506666666 明教 2000-01-05
6 周芷若 17 13311111111 明教 2000-01-06
7 赵敏 17 18800000000 明教 2000-01-07
案例 :
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件001-005\读取文件.xlsx'
data = pd.read_excel(path)
# 二、查看前几行数据
print(data.head()) # 默认是5行,指定行数写小括号里
print('==='*20)
# 三、查看数据的形状,返回(行数、列数)
print(data.shape)
print('==='*20)
# 四、 查看列名列表
print(data.columns)
print('==='*20)
# 五、查看索引列
print(data.index)
print('==='*20)
# 六、查看每一列数据类型
print(data.dtypes)
运行结果为:
序号 姓名 年龄 手机 地址 入职日期
0 1 杨过 19 13901234567 终南山古墓 2000-01-01
1 2 小龙女 25 13801111111 终南山古墓 2000-01-02
2 3 郭靖 40 13705555555 湖北襄阳 2000-01-03
3 4 黄蓉 35 13601111111 湖北襄阳 2000-01-04
4 5 张无忌 18 13506666666 明教 2000-01-05
============================================================
(7, 6)
============================================================
Index(['序号', '姓名', '年龄', '手机', '地址', '入职日期'], dtype='object')
============================================================
RangeIndex(start=0, stop=7, step=1)
============================================================
序号 int64
姓名 object
年龄 int64
手机 int64
地址 object
入职日期 datetime64[ns]
dtype: object
自己设置并写入表头的两种方法:
第一种:
import pandas as pd
path= 'c:/pandas/读取文件.xlsx'
data = pd.read_excel(path,header=None)
data.columns=['序号','姓名','年龄','地址','电话','入职日期'] # 给每个列重复设置表头
data=data.set_index('序号') # 重新指定索引列
print(data.columns) # 查看列名列表
data.to_excel(path) # 写入到Excel文件
第二种:
import pandas as pd
path= 'c:/pandas/读取文件.xlsx'
data = pd.read_excel(path,header=None,index_col='序号')
data.columns=['序号','姓名','年龄','地址','电话','入职日期'] # 给每个列重复设置表头
data=data.set_index('序号',inplace=True) # 只在index上面改,不要生成新的
print(data.columns) # 查看列名列表,index和columns是分开的
data.to_excel(path) # 写入到Excel文件
推荐方法:
import pandas as pd
path= 'c:/pandas/读取文件.xlsx'
data = pd.read_excel(path,header=None,names=['序号','姓名','年龄','手机','地址','入职日期'],index_col='序号')
print(data)
data.to_excel(path)
四. pandas数据结构
DataFrame:二维数据,整个表格,多行多列 【简称df】
df.index:索引列
df.columns:列名
Series:一维数据,一行或一列
4.1 Series 一维数据,一行或一列
Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引)组成。
4.1.1 仅有数据列表即可产生最简单的Series
案例 :
import pandas as pd
data= pd.Series([520,'落空空',1314,'2021-07-30']) # 左侧是索引,右侧是数据
print(data)
print('==='*20)
print(data.index) # 获取索引,返回索引的(起始值,结束值,步长)
print('==='*20)
print(data.values) # 获取数据,返回值序列,打印元素值的列表
运行结果为:
0 520
1 落空空
2 1314
3 2021-07-30
dtype: object
============================================================
RangeIndex(start=0, stop=4, step=1)
============================================================
[520 '落空空' 1314 '2021-07-30']
4.1.2 我们指定Series的索引
案例:
import pandas as pd
data= pd.Series([520,'落空空',1314,'2021-07-30'],index=['a','b','c','d']) # 指定索引
print(data)
print('==='*20)
print(data.index) # 返回指定的索引
运行结果为:
a 520
b 落空空
c 1314
d 2021-07-30
dtype: object
============================================================
Index(['a', 'b', 'c', 'd'], dtype='object')
4.1.3 使用Python字典创建Series
案例:
import pandas as pd
dict1={'姓名':'落空空','性别':'男','年龄':'20','地址':'花果山水帘洞'}
data=pd.Series(dict1)
print(data)
print('==='*20)
print(data.index) # 返回key
运行结果为:
姓名 落空空
性别 男
年龄 20
地址 花果山水帘洞
dtype: object
============================================================
Index(['姓名', '性别', '年龄', '地址'], dtype='object')
4.1.4 根据标签索引查询数据
案例:
print(data) # 查询整个字典
print(data['姓名']) # 通过key可以查对应的值
print(type(data['年龄'])) # 通过key可以查对应值的类型
print('==='*20)
print(data[['姓名','年龄']]) # 通过多个key查对应的值
print(type(data[['姓名','年龄']])) # 注意:他不返回值的类型,而返回Series
运行结果为:
姓名 落空空
性别 男
年龄 20
地址 花果山水帘洞
dtype: object
落空空
<class 'str'>
============================================================
姓名 落空空
年龄 20
dtype: object
<class 'pandas.core.series.Series'>
4.1.5 键和值存在两个列表中,创建Series
案例:
import pandas as pd
list1 = ['姓名','性别','年龄']
list2 = ['落空空','男',20]
data = pd.Series(list2,index=list1) # 指定谁是索引
print(data)
运行结果为:
姓名 落空空
性别 男
年龄 20
dtype: object
4.1.6 Series常用方法
#常用方法
数据.index #查看索引
数据.values #查看数值
数据.isnull() #查看为空的,返回布尔型
数据.notnull()
数据.sort_index() #按索引排序
数据.sort_values() #按数值排序
4.2 认识DataFrame
每列可以是不同的值类型(数值、字符串、布尔值等)
• 既有行索引index,也有列索引columns
• 可以被看做由Series组成的字典
• DataFrame是一个表格型的数据结构
创建DataFrame最常用的方法,参考读取CSV、TXT、Excel、MySQL等
案例 :
import pandas as pd
data=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=['a','b','c'])
print(data)
print('==='*20)
print(data['a'][0] )
print('==='*20)
print(data.loc[0]['a'] )
print('==='*20)
print(data.iloc[0][0] )
print('==='*20)
print(data[['a','b']])
运行结果为:
a b c
0 1 2 3
1 4 5 6
2 7 8 9
============================================================
1
============================================================
1
============================================================
1
============================================================
a b
0 1 2
1 4 5
2 7 8

4.2.1 DataFrame 整个表格
案例:
import pandas as pd
dict1 = {
'姓名':['落空空','李小龙','叶问'],
'年龄':[20,80,127],
'功夫':['撸铁','截拳道','咏春']
}
data = pd.DataFrame(dict1)
print(data)
print('==='*20)
print(data.dtypes) # 返回每一列的类型
print('==='*20)
print(data.columns) # 返回列索引,以列表形式返回:[列名1,列名2,…]
print('==='*20)
print(data.index) # 返回行索引,(起始,结束,步长)
运行结果为:
姓名 年龄 功夫
0 落空空 20 撸铁
1 李小龙 80 截拳道
2 叶问 127 咏春
============================================================
姓名 object
年龄 int64
功夫 object
dtype: object
============================================================
Index(['姓名', '年龄', '功夫'], dtype='object')
============================================================
RangeIndex(start=0, stop=3, step=1)
4.2.2 从DataFrame中查询出Series
案例:
# 如果只查询一列,返回的是pd.Series
print(data['姓名']) # 返回索引和这一列数据
print('==='*20)
# 如果只查询一行,返回的是pd.Series
print(data.loc[1]) # 这时,它的索引是列名
print('==='*20)
# 如果查询多列,返回的是pd.DataFrame
print(data[['姓名','年龄']]) # 返回索引和这两列数据
print('==='*20)
# 如果查询多行,返回的是pd.DataFrame
print(data.loc[1:3]) # 返回前3行,包括结束值
运行结果为:
0 落空空
1 李小龙
2 叶问
Name: 姓名, dtype: object
============================================================
姓名 李小龙
年龄 80
功夫 截拳道
Name: 1, dtype: object
============================================================
姓名 年龄
0 落空空 20
1 李小龙 80
2 叶问 127
============================================================
姓名 年龄 功夫
1 李小龙 80 截拳道
2 叶问 127 咏春
4.2.3 将多个Series加入DataFrame
案例:
import pandas as pd
data1 = pd.Series(['叶问','李小龙','落空空'],index=[1,2,3],name='姓名')
data2 = pd.Series(['男','男','男'],index=[1,2,3],name='性别')
data3 = pd.Series([127,80,20],index=[1,2,3],name='年龄')
table1 = pd.DataFrame({data1.name:data1,data2.name:data2,data3.name:data3})
print(table1)
运行结果为:
姓名 性别 年龄
1 叶问 男 127
2 李小龙 男 80
3 落空空 男 20
4.2.4 DataFrame常用方法
# 常用方法
数据.head( 5 ) #查看前5行
数据.tail( 3 ) #查看后3行
数据.values #查看数值
数据shape #查看行数、列数
数据.fillna(0) #将空值填充0
数据.replace( 1, -1) #将1替换成-1
数据.isnull() #查找数据中出现的空值
数据.notnull() #非空值
数据.dropna() #删除空值
数据.unique() #查看唯一值
数据.reset_index() #修改、删除,原有索引,详见例1
数据.columns #查看数据的列名
数据.index #查看索引
数据.sort_index() #索引排序
数据.sort_values() #值排序
pd.merge(数据1,数据1) #合并
pd.concat([数据1,数据2]) #合并,与merge的区别,自查
pd.pivot_table( 数据 ) #用df做数据透视表(类似于Excel的数透)
五. 连接查询
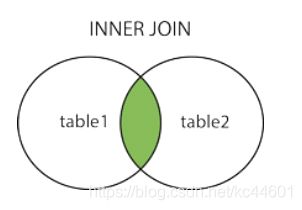

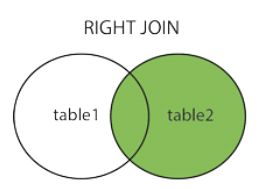
5.1 Merge
首先merge的操作非常类似sql里面的join,实现将两个Dataframe根据一些共有的列连接起来,当然,在实际场景中,这些共有列一般是Id,
连接方式也丰富多样,可以选择inner(默认),left,right,outer 这几种模式,分别对应的是内连接,左连接,右连接,全外连接

5.1.1 InnerMerge (内连接)
内连接的参数on和how可以省略
数据3 = pd.merge(数据1,数据2,on='姓名',how='inner')
连接后,显示两个表内的公有数据(交集)
案例 :
import numpy as np
import pandas as pd
data1= pd.DataFrame({'姓名':['叶问','李小龙','落空空','李小龙','叶问','叶问'],'出手次数1':np.arange(6)})
data2 = pd.DataFrame({'姓名':['黄飞鸿','落空空','李小龙'],'出手次数2':[1,2,3]})
data3 = pd.merge(data1,data2)
print(data1)
print('==='*20)
print(data2)
print('==='*20)
print(data3)
运行结果为:
李小龙和落空空在data1和data2中都存在,所以都存入data3
姓名 出手次数1
0 叶问 0
1 李小龙 1
2 落空空 2
3 李小龙 3
4 叶问 4
5 叶问 5
============================================================
姓名 出手次数2
0 黄飞鸿 1
1 落空空 2
2 李小龙 3
============================================================
姓名 出手次数1 出手次数2
0 李小龙 1 3
1 李小龙 3 3
2 落空空 2 2
5.1.2 LeftMerge (左连接)
以左边参数的表为标准,右边的表链接进去
案例 :
import numpy as np
import pandas as pd
data1= pd.DataFrame({'姓名':['叶问','李小龙','落空空','李小龙','叶问','叶问'],'出手次数1':np.arange(6)})
data2 = pd.DataFrame({'姓名':['黄飞鸿','落空空','李小龙'],'出手次数2':[1,2,3]})
data3 = pd.merge(data1,data2,on='姓名',how='left')
print(data1)
print('==='*20)
print(data2)
print('==='*20)
print(data3)
运行结果为:
姓名 出手次数1
0 叶问 0
1 李小龙 1
2 落空空 2
3 李小龙 3
4 叶问 4
5 叶问 5
============================================================
姓名 出手次数2
0 黄飞鸿 1
1 落空空 2
2 李小龙 3
============================================================
姓名 出手次数1 出手次数2
0 叶问 0 NaN
1 李小龙 1 3.0
2 落空空 2 2.0
3 李小龙 3 3.0
4 叶问 4 NaN
5 叶问 5 NaN
5.1.3 RightMerge (右连接)
以右边参数的表为标准,左边的表链接进去
案例:
import numpy as np
import pandas as pd
data1= pd.DataFrame({'姓名':['叶问','李小龙','落空空','李小龙','叶问','叶问'],'出手次数1':np.arange(6)})
data2 = pd.DataFrame({'姓名':['黄飞鸿','落空空','李小龙'],'出手次数2':[1,2,3]})
data3 = pd.merge(data1,data2,on='姓名',how='right')
print(data1)
print('==='*20)
print(data2)
print('==='*20)
print(data3)
运行结果为:
姓名 出手次数1
0 叶问 0
1 李小龙 1
2 落空空 2
3 李小龙 3
4 叶问 4
5 叶问 5
============================================================
姓名 出手次数2
0 黄飞鸿 1
1 落空空 2
2 李小龙 3
============================================================
姓名 出手次数1 出手次数2
0 黄飞鸿 NaN 1
1 落空空 2.0 2
2 李小龙 1.0 3
3 李小龙 3.0 3
5.1.4 OuterMerge (全连接)
两张表的联合(并集)
案例:
import numpy as np
import pandas as pd
data1= pd.DataFrame({'姓名':['叶问','李小龙','落空空','李小龙','叶问','叶问'],'出手次数1':np.arange(6)})
data2 = pd.DataFrame({'姓名':['黄飞鸿','落空空','李小龙'],'出手次数2':[1,2,3]})
data3 = pd.merge(data1,data2,on='姓名',how='outer')
print(data1)
print('==='*20)
print(data2)
print('==='*20)
print(data3)
运行结果为:
姓名 出手次数1
0 叶问 0
1 李小龙 1
2 落空空 2
3 李小龙 3
4 叶问 4
5 叶问 5
============================================================
姓名 出手次数2
0 黄飞鸿 1
1 落空空 2
2 李小龙 3
============================================================
姓名 出手次数1 出手次数2
0 叶问 0.0 NaN
1 叶问 4.0 NaN
2 叶问 5.0 NaN
3 李小龙 1.0 3.0
4 李小龙 3.0 3.0
5 落空空 2.0 2.0
6 黄飞鸿 NaN 1.0
5.1.5 MultipleKey Merge (基于多个key上的merge)
刚才我们都是仅仅实现的在一个key上的merge,当然我们也可以实现基于多个keys的merge
案例:
import pandas as pd
data1 = pd.DataFrame({'姓名': ['张三', '张三', '王五'],'班级': ['1班', '2班', '1班'],'分数': [10,20,30]})
print(data1)
print('==='*20)
data2 = pd.DataFrame({'姓名': ['张三', '张三', '王五','王五'],'班级': ['1班', '1班', '1班','2班'],'分数': [40,50,60,70]})
print(data2)
print('==='*20)
data3= pd.merge(data1,data2,on=['姓名','班级']) # 内连接(交集)的结果
print(data3)
print('==='*20)
data4= pd.merge(data1,data2,on=['姓名','班级'],how='outer') # 外连接(并集)的结果
print(data4)
运行结果为:
姓名 班级 分数
0 张三 1班 10
1 张三 2班 20
2 王五 1班 30
============================================================
姓名 班级 分数
0 张三 1班 40
1 张三 1班 50
2 王五 1班 60
3 王五 2班 70
============================================================
姓名 班级 分数_x 分数_y
0 张三 1班 10 40
1 张三 1班 10 50
2 王五 1班 30 60
============================================================
姓名 班级 分数_x 分数_y
0 张三 1班 10.0 40.0
1 张三 1班 10.0 50.0
2 张三 2班 20.0 NaN
3 王五 1班 30.0 60.0
4 王五 2班 NaN 70.0
5.1.6 Merge on Index (基于index上的merge)
我们还可以实现几个Dataframe基于Index的merge,还是老样子,先让我们创建两个Dataframe
import pandas as pd
data1 = pd.DataFrame({'姓名': ['张三','李四','王五','张三','李四'],'次数':range(5)})
data2 = pd.DataFrame({'数据': [10, 20]}, index=['张三','李四'])
data3=pd.merge(data1,data2,left_on='姓名',right_index=True)
print(data3)
print('==='*20)
data4=pd.merge(data1,data2,left_on='姓名',right_index=True,how='outer')
print(data4)
运行结果为:
姓名 次数 数据
0 张三 0 10
3 张三 3 10
1 李四 1 20
4 李四 4 20
============================================================
姓名 次数 数据
0 张三 0 10.0
3 张三 3 10.0
1 李四 1 20.0
4 李四 4 20.0
2 王五 2 NaN
5.1.7 总结
(1)通过on指定数据合并对齐的列
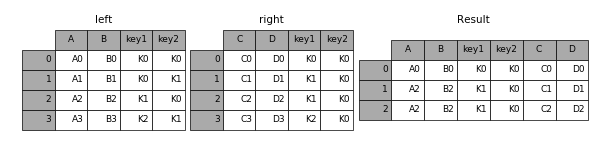
result = pd.merge(left, right, on=[‘key1’, ‘key2’])
(2)没有指定how的话默认使用inner方法,除了内连接,还包括左连接、右连接、全外连接
左连接:
result = pd.merge(left, right, how=‘left’, on=[‘key1’, ‘key2’])
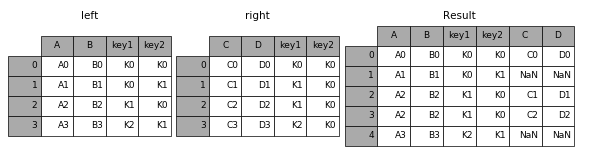
右连接:
result = pd.merge(left, right, how=‘right’, on=[‘key1’, ‘key2’])

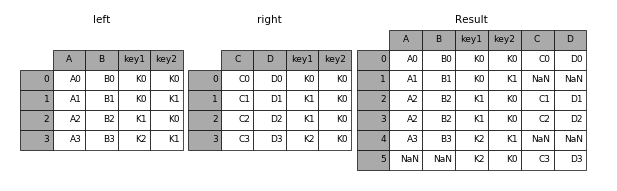
全外连接:
result = pd.merge(left, right, how=‘outer’, on=[‘key1’, ‘key2’])
5.2 Join
案例:
import pandas as pd
left_dict={'姓名1':['叶问','李小龙','落空空'],'年龄1':[127,80,20]}
right_dict={'姓名2':['大刀王五','霍元甲','陈真'],'年龄2':[176,152,128]}
left = pd.DataFrame(left_dict)
right = pd.DataFrame(right_dict)
print(left.join(right))
运行结果为:
姓名1 年龄1 姓名2 年龄2
0 叶问 127 大刀王五 176
1 李小龙 80 霍元甲 152
2 落空空 20 陈真 128
其实通过这一个小例子大家也就明白了,join无非就是合并,默认是横向,还有一个点需要注意的是,我们其实可以通过join实现和merge一样的效果,但是为了
避免混淆,我不会多举其他的例子了,因为我个人认为一般情况下还是用merge函数好一些
join方法将两个DataFrame中不同的列索引合并成为一个DataFrame参数的意义与merge基本相同,只是join方法默认左外连接how=left
def join(self, other, on=None, how='left', lsuffix='', rsuffix='',sort=False):
(1)on参数
result = left.join(right, on=‘key’)
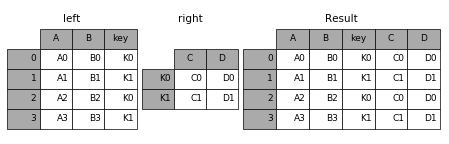
(3)组合多个dataframe
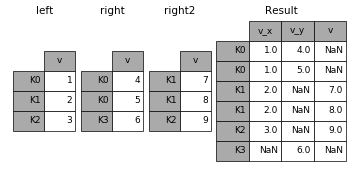
一次组合多个dataframe的时候可以传入元素为dataframe的列表或者tuple。一次join多个,一次解决多次烦恼~
right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2'])
result = left.join([right, right2])
5.3 Concat

import numpy as np
arr = np.arange(9).reshape((3,3))
print(arr)
arr1 = np.concatenate([arr,arr],axis=1)
print(arr1)
arr2 = np.concatenate([arr,arr],axis=0)
print(arr2)
运行结果为:
[[0 1 2]
[3 4 5]
[6 7 8]]
[[0 1 2 0 1 2]
[3 4 5 3 4 5]
[6 7 8 6 7 8]]
[[0 1 2]
[3 4 5]
[6 7 8]
[0 1 2]
[3 4 5]
[6 7 8]]
concat语法
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False,
sort=None, copy=True)

5.3.1 在Pandas中使用Concat
案例:
import pandas as pd
data1 = pd.Series([0,1,2],index=['A','B','C'])
data2 = pd.Series([3,4],index=['D','E'])
data3 = pd.concat([data1,data2])
print(data3)
运行结果为:
A 0
B 1
C 2
D 3
E 4
dtype: int64
在上面的例子中,我们分别创建了两个没有重复Index的Series,然后用concat默认的把它们合并在一起,这时生成的依然是Series类型,如果我们把axis换成1,那生成
的就是Dataframe,像下面一样
data4 = pd.concat([data1,data2],axis=1,sort =True) # sort=Ture是默认的,pandas总是默认index排序,默认axis=0
print(data4)
运行结果为:
0 1
A 0.0 NaN
B 1.0 NaN
C 2.0 NaN
D NaN 3.0
E NaN 4.0
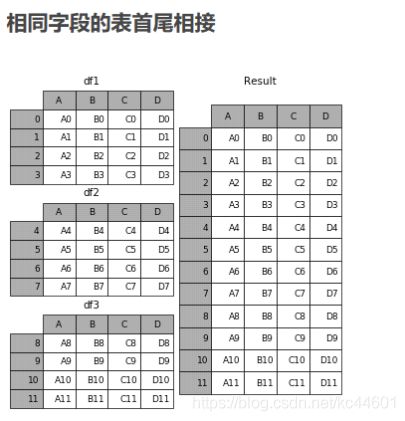
5.3.2 首尾相接
frames = [df1, df2, df3]
result = pd.concat(frames)
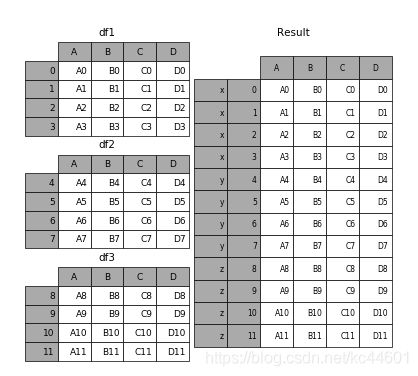
要在相接的时候在加上一个层次的key来识别数据源自于哪张表,可以增加key参数
result = pd.concat(frames, keys=['x', 'y', 'z'])
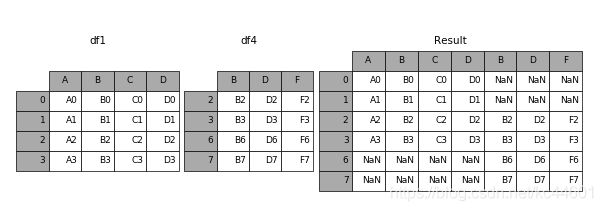
5.3.3 横向表拼接(行对齐)
(1)axis
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
result = pd.concat([df1, df4], axis=1)
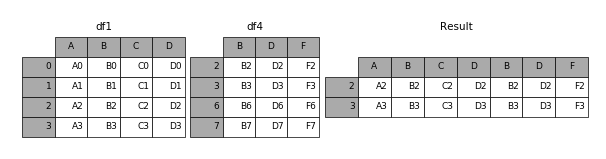
(2)join
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是
outer,得到的是两表的并集。
result = pd.concat([df1, df4], axis=1, join='inner')
(3)join_axes
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之
拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
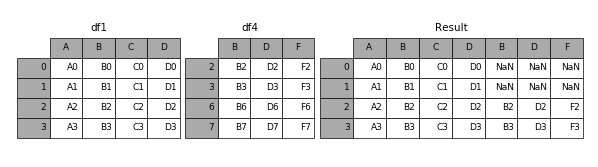
5.3.4 append
append是series和dataframe的方法,使用它就是默认沿着列进行凭借(axis = 0,列对齐)
result = df1.append(df2)

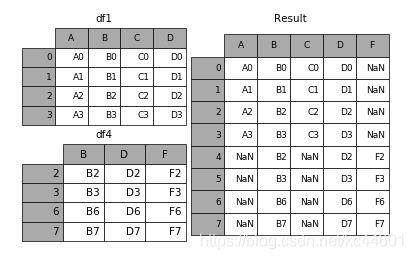
5.3.5 无视index的concat
如果两个表的index都没有实际含义,使用ignore_index参数,置true,合并的两个表就是根据列字段对齐,然后合并。最后再重新整理一个新的index。
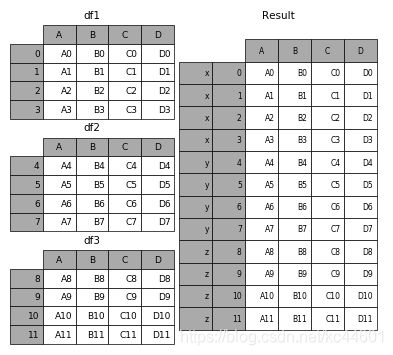
5.3.6 合并的同时增加区分数据组的键
前面提到的keys参数可以用来给合并后的表增加key来区分不同的表数据来源
(1)可以直接用key参数实现
result = pd.concat(frames, keys=['x', 'y', 'z'])

(2)传入字典来增加分组键
pieces = {'x': df1, 'y': df2, 'z': df3}
result = pd.concat(pieces)
5.3.7 在dataframe中加入新的行
append方法可以将 series 和 字典就够的数据作为dataframe的新一行插入。
s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
result = df1.append(s2, ignore_index=True)

5.3.8 表格列字段不同的表合并
如果遇到两张表的列字段本来就不一样,但又想将两个表合并,其中无效的值用nan来表示。那么可以使用ignore_index来实现。
dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4}, {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
result = df1.append(dicts, ignore_index=True)

六. 填充常用类型数据
pd.read_excel参数:
skiprows=行数 #跳过几行
usecols="区域" # 和Excel中一样,就是一个列的区域
index_col="字段名" # 将谁设置为索引
dtype={'序号':str,'性别':str,'日期':str} # 防止出错,把类型全指定为字符型
数据.at的用法
作用:获取某个位置的值,例如,获取第0行,第a列的值,即:index=0,columns=‘a’
变量名 = 数据.at[0, 'a']
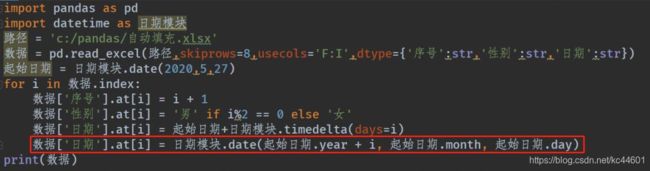
日期模块 datetime
import pandas as pd
import datetime as dt
def add_month(date, month):
year = month // 12
mon = date.month + month % 12
if mon != 12:
year = year + mon // 12
mon = mon % 12
return dt.date(date.year + year, mon, date.day)
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件010\自动填充.xlsx'
data = pd.read_excel(path, skiprows=8, usecols='F:I', dtype={'序号': str, '性别': str, '日期': str})
start_date = dt.date(2021, 7, 27)
for i in data.index:
data['序号'].at[i] = i + 1
data['性别'].at[i] = '男' if i % 2 == 0 else '女'
# data['日期'].at[i] = start_date + dt.timedelta(days=i)
data['日期'].at[i] = dt.date(start_date.year + i, start_date.month, start_date.day)
data['日期'].at[i] = add_month(start_date, i)
data.set_index('序号',inplace=True)
# data.to_excel(path)
print(data)
运行结果为:
姓名 性别 日期
序号
1 张三 男 2021-07-27
2 李四 女 2021-08-27
3 王五 男 2021-09-27
6.1 填充数字
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件010\自动填充.xlsx'
data = pd.read_excel(path)
print(data)
这样做不行,因为所有的空行和空列会被显示为Nan
skiprows 从文件开始处,需要跳过的行数或行号列表
如下图,跳过前8行

下图为选择列

6.2 填充字符
遇到填充时,这里都指定为str类型,因为他不支持int等类型

6.3 填充日期

如果只想累加年份,用Date
timedelta只能加天,小时,秒,毫秒
但是月的累计很麻烦,因为累加到12月就要进1位到年份上

这个时候,设置索引不能在read_excel中完成,因为我们在填充时用到他的自动索引,需要用另一个方法设置索引
数据.set_index(‘序号’,inplace=True) # 只在index上面改,不要生成新的
数据.to_excel(路径) # 写入Excel文件
6.4 在CSV中完成自动填充

七. 计算列
案例 :
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件011\计算列.xlsx'
data = pd.read_excel(path,index_col='序号')
data['销售金额']=data['单价']*data['销售数量']
print(data)
运行结果为:
商品名称 单价 销售数量 销售金额
序号
1 香蕉 5 20 100
2 苹果 6 15 90
3 梨 3 18 54
当你不想全部都计算,只想计算一部分行的时候,需要使用For循环
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件011\计算列.csv'
data = pd.read_csv(path,index_col='序号')
for i in range(1,3):
data['销售金额'].at[i] = data['单价'].at[i] * data['销售数量'].at[i]
print(data)
运行结果为:
商品名称 单价 销售数量 销售金额
序号
1 香蕉 5 20 100.0
2 苹果 6 15 90.0
3 梨 3 18 NaN
7.1 pandas apply() 函数
理解 pandas 的函数,要对函数式编程有一定的概念和理解。函数式编程,包括函数式编程思维,当然是一个很复杂的话题,但对今天介绍的 apply() 函数,只需要理解:函数作为一个对象,能作为参数传递给其它参数,并且能作为函数的返回值。
pandas 的 apply()函数可以作用于 Series 或者整个 DataFrame,功能也是自动遍历整个 Series 或者 DataFrame, 对每一个元素运行指定的函数
Series.apply():民族为少数民族的加5分
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件011\apply函数.xlsx'
data = pd.read_excel(path,index_col='序号')
data['加分']=data['民族'].apply(lambda x:5 if x != '汉' else 0)
data['最终分数'] = data['总分']+data['加分']
print(data)
运行结果为:
姓名 民族 总分 加分 最终分数
序号
1 张三 汉 591 0 591
2 李四 满 589 5 594
3 王五 回 587 5 592
apply() 函数当然也可执行 python 内置的函数,比如我们想得到 Name 这一列字符的个数,如果用 apply() 的话:
data['姓名字符个数']=data['姓名'].apply(len)
print(data)
运行结果为:
姓名 民族 总分 加分 最终分数 姓名字符个数
序号
1 张三 汉 591 0 591 2
2 李四 满 589 5 594 2
3 王五 回 587 5 592 2
DataFrame.apply() 函数则会遍历每一个元素,对元素运行指定的 function。比如下面的示例:计算数组的平方根
import pandas as pd
import numpy as np
arr = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
data = pd.DataFrame(arr, columns=['x', 'y', 'z'], index=['a', 'b', 'c'])
print(data.apply(np.square))
运行结果为:
x y z
a 1 4 9
b 16 25 36
c 49 64 81
如果只想 apply() 作用于指定的行和列,可以用行或者列的 name 属性进行限定。比如下面的示例将 x 列进行平方运算:
data2 = data.apply(lambda a : np.square(a) if a.name=='x' else a)
print(data2)
运行结果为:
x y z
a 1 2 3
b 16 5 6
c 49 8 9
对 x 和 y 列进行平方运算:
data3 = data.apply(lambda a : np.square(a) if a.name in ['x','y'] else a)
print(data3)
运行结果为:
x y z
a 1 4 3
b 16 25 6
c 49 64 9
第一行 (a 标签所在行)进行平方运算:
data4 = data.apply(lambda m : np.square(m) if m.name == 'a' else m, axis=1)
print(data4)
运行结果为:
x y z
a 1 4 9
b 4 5 6
c 7 8 9
第一行和第三行(a标签和c标签所在行)进行平方运算
data5 = data.apply(lambda m : np.square(m) if m.name in ['a','c'] else m, axis=1)
print(data5)
运行结果为:
x y z
a 1 4 9
b 4 5 6
c 49 64 81
7.2 apply函数计算日期相减
平时我们会经常用到日期的计算,比如要计算两个日期的间隔,比如下面的一组关于起止日期的数据:

import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件011\计算日期.xlsx'
data=pd.read_excel(path,index_col='序号')
data['间隔']=data['结束日期']-data['起始日期']
print(data)
运行结果为:
起始日期 结束日期 间隔
序号
1 2020-01-01 2020-01-08 7 days
2 2020-03-01 2020-09-07 190 days
3 2020-05-03 2020-08-08 97 days
4 2020-04-08 2020-11-08 214 days
5 2020-07-30 2021-09-03 400 days
八. 排序
格式:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
参数说明
axis:如果axis=0,那么by=“列名”;如果axis=1,那么by=“行号”;
ascending:True则升序,可以是[True,False],即第一字段升序,第二个降序
inplace=True:不创建新的对象,直接对原始对象进行修改;
inplace=False:对数据进行修改,创建并返回新的对象承载其修改结果。
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心
na_position : {‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面
数据如下:

例1:按语文分数降序排列
import pandas as pd
path = 'E:\Desktop\科学计算\Pandas课件\pandas教程\课件012\排序.xlsx'
data = pd.read_excel(path,index_col='序号')
data.sort_values(by='语文',inplace=True,ascending=False)
print(data)
运行结果为:
姓名 语文 数学 英语
序号
4 张伊 69 44 58
1 卢海军 64 49 49
2 丁智敏 61 61 60
3 李平平 58 49 33
6 王松 47 44 62
5 王刚 37 63 42
例2:按语文分数排序降序,数学升序,英语降序
import pandas as pd
path = 'E:\Desktop\科学计算\Pandas课件\pandas教程\课件012\排序.xlsx'
data = pd.read_excel(path,index_col='序号')
data.sort_values(by=['语文','数学','英语'],inplace=True,ascending=[False,True,False])
print(data)
运行结果为:
姓名 语文 数学 英语
序号
4 张伊 69 44 58
1 卢海军 64 49 49
2 丁智敏 61 61 60
3 李平平 58 49 33
6 王松 47 44 62
5 王刚 37 63 42
例3:按索引进行排序
import pandas as pd
path = 'E:\Desktop\科学计算\Pandas课件\pandas教程\课件012\排序.xlsx'
data = pd.read_excel(path,index_col='序号')
data.sort_index(inplace=True)
print(data)
运行结果为:
姓名 语文 数学 英语
序号
1 卢海军 64 49 49
2 丁智敏 61 61 60
3 李平平 58 49 33
4 张伊 69 44 58
5 王刚 37 63 42
6 王松 47 44 62
进阶排序篇:
数据如下:

按a列降序排序
import pandas as pd
path = 'E:\Desktop\科学计算\Pandas课件\pandas教程\课件012\排序进阶.xlsx'
data = pd.read_excel(path)
data.sort_values(by='a',inplace=True,ascending=False)
print(data)
运行结果为:
a b c
3 8 7 9
1 6 4 2
0 3 5 6
2 2 3 1
按 2 行降序排序
import pandas as pd
path = 'E:\Desktop\科学计算\Pandas课件\pandas教程\课件012\排序进阶.xlsx'
data = pd.read_excel(path)
data.sort_values(by=1,inplace=True,ascending=False,axis=1)
print(data)
运行结果为:
a b c
0 3 5 6
1 6 4 2
2 2 3 1
3 8 7 9
九. 查询数据 【loc】
注意:如果查询的数据里面牵扯到日期的查询,那么一定要把日期指定为索引再去查
首先先将日期作为索引看一下数据:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='出生日期')
print(data)
运行结果为:
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1983-01-05 1 卢海军 男 64 49 49 162 上海市某某区某某小区A座
1983-10-27 2 丁智敏 女 61 61 60 182 冀州市某某区某某小区a座
1994-01-07 3 李平平 女 58 49 33 140 襄阳市某某区某某小区c座
1987-02-06 4 张伊 女 69 44 58 171 河南省信阳市某某区某某小区C座
1989-07-08 5 王刚 男 37 63 42 142 信阳市某某区某某小区B座
1987-03-06 6 王松 男 47 44 62 153 襄阳市某某区某某小区F座
9.1 单条件查询
语法:loc[行标签,列标签]
查看 1983-10-27 的语文成绩
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='出生日期')
print(data.loc['1983-10-27','语文'])
运行结果为:
出生日期
1983-10-27 61
Name: 语文, dtype: int64
9.2 多条件查询
查看 1983-10-27的 语文 数学 英语成绩
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='出生日期')
print(data.loc['1983-10-27',['语文','数学','英语']])
运行结果为:
语文 数学 英语
出生日期
1983-10-27 61 61 60
9.3 使用数据区间范围进行查询
查看1983-10-27 到 1990-12-31的语文 数学 英语成绩
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='出生日期')
print(data.loc['1983-10-27':'1990-12-31',['语文','数学','英语']])
运行结果为:
语文 数学 英语
出生日期
1983-10-27 61 61 60
1987-02-06 69 44 58
1989-07-08 37 63 42
1987-03-06 47 44 62
9.4 使用条件表达式进行查询
查询 语文成绩大于60 英语成绩小于60的信息
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='出生日期')
print(data.loc[(data['语文'] > 60) & (data['英语'] < 60),:])
这里的 ,: 指的是列取全部
运行结果为:
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1983-01-05 1 卢海军 男 64 49 49 162 上海市某某区某某小区A座
1987-02-06 4 张伊 女 69 44 58 171 河南省信阳市某某区某某小区C座
9.5 loc实现条件判断
添加称呼列,将 男性 赋值为 先生 ,女性 赋值为 女士
import pandas as pd
import datetime as dt
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\条件判断.xlsx'
data = pd.read_excel(path,index_col='序号')
data.loc[data['性别'] == "男","称呼"] = "先生"
data.loc[data['性别'] == "女","称呼"] = "女士"
print(data)
运行结果为:
姓名 性别 语文 数学 英语 称呼
序号
1 张三 男 89 60 88 先生
2 李四 女 60 71 98 女士
3 王五 男 73 84 68 先生
4 小孙 男 85 96 96 先生
5 小刘 女 70 63 97 女士
6 小赵 女 63 63 91 女士
十. 筛选
1.加载数据
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
print(data)
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
1 卢海军 男 1983-01-05 64 49 49 162 上海市某某区某某小区A座
2 丁智敏 女 1983-10-27 61 61 60 182 冀州市某某区某某小区a座
3 李平平 女 1994-01-07 58 49 33 140 襄阳市某某区某某小区c座
4 张伊 女 1987-02-06 69 44 58 171 河南省信阳市某某区某某小区C座
5 王刚 男 1989-07-08 37 63 42 142 信阳市某某区某某小区B座
6 王松 男 1987-03-06 47 44 62 153 襄阳市某某区某某小区F座
2.按位置筛选,筛选第2行至第4行数据
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
data2=data.loc[2:4]
print(data2)
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
2 丁智敏 女 1983-10-27 61 61 60 182 冀州市某某区某某小区a座
3 李平平 女 1994-01-07 58 49 33 140 襄阳市某某区某某小区c座
4 张伊 女 1987-02-06 69 44 58 171 河南省信阳市某某区某某小区C座
3.按值过滤,筛选所有男性
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
choose = data['性别'] == '男'
print(data[choose])
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
1 卢海军 男 1983-01-05 64 49 49 162 上海市某某区某某小区A座
5 王刚 男 1989-07-08 37 63 42 142 信阳市某某区某某小区B座
6 王松 男 1987-03-06 47 44 62 153 襄阳市某某区某某小区F座
4.多条件筛选,男性和总分大于等于150
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
choose = "性别 == '男' and 总分 >= 150"
print(data.query(choose))
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
1 卢海军 男 1983-01-05 64 49 49 162 上海市某某区某某小区A座
6 王松 男 1987-03-06 47 44 62 153 襄阳市某某区某某小区F座
query 方法,可以直接接受一个查询字符串,是不是很像 Sql 呢.指定多个值也很简单,使用in 或not in,如下:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
choose="姓名 in['王松','王刚']"
print(data.query(choose))
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
5 王刚 男 1989-07-08 37 63 42 142 信阳市某某区某某小区B座
6 王松 男 1987-03-06 47 44 62 153 襄阳市某某区某某小区F座
10.1 文本筛选:开头与结尾
startswith( ) endwith( )
startswith()函数
描述:判断字符串是否以指定字符或子字符串开头。
语法:str.endswith(“suffix”, start, end) 或 str[start,end].endswith(“suffix”) 用于判断字符串中某段字符串是否以指定字符或子字符串结尾。
—> bool 返回值为布尔类型(True,False)
suffix — 后缀,可以是单个字符,也可以是字符串,还可以是元组("suffix"中的引号要省略)。
start —索引字符串的起始位置。
end— 索引字符串的结束位置。
str.endswith(suffix) star默认为0,end默认为字符串的长度减一(len(str)-1)
注意:空字符的情况。返回值通常也为True
例:姓名列开头姓王的
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
choose = data['姓名'].str.startswith('王') # 如果是结尾,就改成endwith
print(data[choose])
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
5 王刚 男 1989-07-08 37 63 42 142 信阳市某某区某某小区B座
6 王松 男 1987-03-06 47 44 62 153 襄阳市某某区某某小区F座
10.2 文本筛选:包含
str.contains(pat, case=True, flags=0, na=nan, regex=True)#是否包含查找的字符串
参数:
pat : 字符串/正则表达式
case : 布尔值, 默认为True.如果为True则匹配敏感
flags : 整型,默认为0(没有flags)
na : 默认为NaN,替换缺失值.
regex : 布尔值, 默认为True.如果为真则使用re.research,否则使用Python
返回值:
布尔值的序列(series)或数组(array)
例1:筛选地址包含信阳市
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
choose = data['地址'].str.contains('信阳市')
print(data[choose])
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
4 张伊 女 1987-02-06 69 44 58 171 河南省信阳市某某区某某小区C座
5 王刚 男 1989-07-08 37 63 42 142 信阳市某某区某某小区B座
10.3 筛选值范围
例1:语文分数在60至100之间的女性
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
choose = " 60 <= 语文 <= 100 and 性别 == '女'"
print(data.query(choose))
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
2 丁智敏 女 1983-10-27 61 61 60 182 冀州市某某区某某小区a座
4 张伊 女 1987-02-06 69 44 58 171 河南省信阳市某某区某某小区C座
10.4 筛选日期
10.4.1 获取某年某月数据
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='出生日期',parse_dates=['出生日期'])
print(data['1989'].head())
print(data['1983-10'].head())
运行结果为:
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1989-07-08 5 王刚 男 37 63 42 142 信阳市某某区某某小区B座
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1983-10-27 2 丁智敏 女 61 61 60 182 冀州市某某区某某小区a座
10.4.2 获取某个时期之前或之后的数据
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path,index_col='出生日期',parse_dates=['出生日期'])
data2 = data.sort_values('出生日期')
# 获取某个时期之前或之后的数据
# 获取1980年以后的数据
print(data2.truncate(before='1980').head())
print('==='*20)
# 获取1990-12之前的数据
print(data2.truncate(after='1990-12').head())
print('==='*20)
# 获取1990-02年以后的数据
print(data2.truncate(before='1990-02').head())
print('==='*20)
# 获取1984-01-01年以后的数据
print(data2.truncate(before='1984-01-1').head())
print('==='*20)
# 获取指定时间区间
print(data2['1983':'1990'])
print(data2['1983-01-1':'1990-12-31'])
运行结果为:
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1983-01-05 1 卢海军 男 64 49 49 162 上海市某某区某某小区A座
1983-10-27 2 丁智敏 女 61 61 60 182 冀州市某某区某某小区a座
1987-02-06 4 张伊 女 69 44 58 171 河南省信阳市某某区某某小区C座
1987-03-06 6 王松 男 47 44 62 153 襄阳市某某区某某小区F座
1989-07-08 5 王刚 男 37 63 42 142 信阳市某某区某某小区B座
============================================================
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1983-01-05 1 卢海军 男 64 49 49 162 上海市某某区某某小区A座
1983-10-27 2 丁智敏 女 61 61 60 182 冀州市某某区某某小区a座
1987-02-06 4 张伊 女 69 44 58 171 河南省信阳市某某区某某小区C座
1987-03-06 6 王松 男 47 44 62 153 襄阳市某某区某某小区F座
1989-07-08 5 王刚 男 37 63 42 142 信阳市某某区某某小区B座
============================================================
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1994-01-07 3 李平平 女 58 49 33 140 襄阳市某某区某某小区c座
============================================================
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1987-02-06 4 张伊 女 69 44 58 171 河南省信阳市某某区某某小区C座
1987-03-06 6 王松 男 47 44 62 153 襄阳市某某区某某小区F座
1989-07-08 5 王刚 男 37 63 42 142 信阳市某某区某某小区B座
1994-01-07 3 李平平 女 58 49 33 140 襄阳市某某区某某小区c座
============================================================
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1983-01-05 1 卢海军 男 64 49 49 162 上海市某某区某某小区A座
1983-10-27 2 丁智敏 女 61 61 60 182 冀州市某某区某某小区a座
1987-02-06 4 张伊 女 69 44 58 171 河南省信阳市某某区某某小区C座
1987-03-06 6 王松 男 47 44 62 153 襄阳市某某区某某小区F座
1989-07-08 5 王刚 男 37 63 42 142 信阳市某某区某某小区B座
序号 姓名 性别 语文 数学 英语 总分 地址
出生日期
1983-01-05 1 卢海军 男 64 49 49 162 上海市某某区某某小区A座
1983-10-27 2 丁智敏 女 61 61 60 182 冀州市某某区某某小区a座
1987-02-06 4 张伊 女 69 44 58 171 河南省信阳市某某区某某小区C座
1987-03-06 6 王松 男 47 44 62 153 襄阳市某某区某某小区F座
1989-07-08 5 王刚 男 37 63 42 142 信阳市某某区某某小区B座
10.4.3 【推荐】多条件日期范围
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件013-014\筛选.xlsx'
data = pd.read_excel(path, index_col='序号', parse_dates=['出生日期'])
choose = (
'@data.出生日期.dt.year > 1980 and'
'@data.出生日期.dt.year < 1990'
'and 性别 == "男"'
)
print(data.query(choose))
运行结果为:
姓名 性别 出生日期 语文 数学 英语 总分 地址
序号
1 卢海军 男 1983-01-05 64 49 49 162 上海市某某区某某小区A座
5 王刚 男 1989-07-08 37 63 42 142 信阳市某某区某某小区B座
6 王松 男 1987-03-06 47 44 62 153 襄阳市某某区某某小区F座