深度学习:正则化-权重衰减-(1). 原理及实现
摘要:介绍权重衰减的基本原理,及其和 L 2 L_2 L2正则化的不同,并分别给出 L 2 L_2 L2正则化和权重衰减的Tensorflow实现方式。使用两者能够等效的随机梯度下降作为例子说明两者的不同。在使用一些自适应优化算法时最好使用解耦的权重衰减而不是 L 2 L_2 L2正则化。
目录
-
基本原理
-
L 2 L_2 L2正则化实现
-
解耦权重衰减实现
-
小结
主要参考文献
【1】“Comparing biases for minimal network construction with back-propagation”
【2】“Decoupled Weight Decay Regularization”
【3】“Dive into Deep Learning”
1. 基本原理
由参考文献【1】,权重衰减的表示形式为:
θ t + 1 = ( 1 − λ ) θ t − α ∇ f t ( θ t ) , \theta_{t+1}=(1-\lambda)\theta_{t}-\alpha\nabla f_t(\theta_t), θt+1=(1−λ)θt−α∇ft(θt),
其中 λ \lambda λ为权重衰减的比率, α \alpha α为学习率。
一般深度学习框架及很多书本中将权重衰减等效为 L 2 L_2 L2正则化。这在随机梯度下降中是成立的,只要在代价函数中增加一项: λ 2 α ∣ ∣ θ ∣ ∣ 2 2 \frac{\lambda}{2\alpha}||\theta||_2^2 2αλ∣∣θ∣∣22,两者在数学上就是等价的。
但在其他自适应学习率的方法中,其实不能简单地将 L 2 L_2 L2正则化当成权重衰减来使用,这就导致在实际使用中自适应优化算法通常会比随机梯度下降的泛化精度差很多。
参考文献【2】提出一种解耦的权重衰减方式,能在自适应方法中实现权重衰减。本质就是回归权重衰减的最初形式,在权重更新的步骤中进行衰减,而不是在代价函数中加上 L 2 L_2 L2正则化。
下图为文献【2】给出的权重衰减以及 L 2 L_2 L2正则化下的随机梯度下降算法,下文给出具体实现。

2. L 2 L_2 L2正则化实现
使用Tensorflow框架,底层设计随机梯度下降算法,并计算代价函数和 L 2 L_2 L2范数。
下面按照准备数据——选择模型——计算代价函数、梯度,进行训练的顺序进行实现。
首先准备高维回归数据集,特征数量远高于训练样本数,十分容易过拟合。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
num_train, num_test = 20, 100
num_features = 200
true_w, true_b = tf.ones((num_features, 1)) * 0.01, 0.05
features = tf.random.normal((num_train + num_test, num_features))
noises = tf.random.normal((num_train + num_test, 1)) * 0.01
labels = tf.matmul(features, true_w) + tf.convert_to_tensor(true_b) + noises
train_data, test_data = features[:num_train, :], features[num_train:, :]
train_labels, test_labels = labels[:num_train], labels[num_train:]
其次选择模型类型,这里使用线性模型。
class Model(object):
def __init__(self):
self.W = tf.Variable(np.random.random((200, 1)), dtype=tf.float32)
self.b = tf.Variable(0.0)
def __call__(self, x):
return tf.matmul(x, self.W) + self.b
然后定义代价函数和梯度,对模型进行训练。代价函数采用均方误差。
这部分是 L 2 L_2 L2正则化和权重衰减的主要区别所在。
首先我们使用比率为0的 L 2 L_2 L2正则化,观察一下过拟合。
def loss(y_true, y_pred):
return tf.reduce_mean(tf.square(y_true - y_pred))
def l2_reg(ws):
return tf.norm(ws) ** 2
def train(model, inputs, outputs, lr):
with tf.GradientTape() as g:
current_loss = loss(outputs, model(inputs)) + 0 * l2_reg(model.W)
grad_w, grad_b = g.gradient(current_loss, [model.W, model.b])
model.W.assign_sub(lr * grad_w)
model.b.assign_sub(lr * grad_b)
model = Model()
ws, bs = [], []
train_losses, test_losses = [], []
epochs = range(120)
for epoch in epochs:
ws.append(model.W.numpy())
bs.append(model.b.numpy())
train(model, train_data, train_labels, 0.01)
train_losses.append(loss(train_labels, model(train_data)))
test_losses.append(loss(test_labels, model(test_data)))
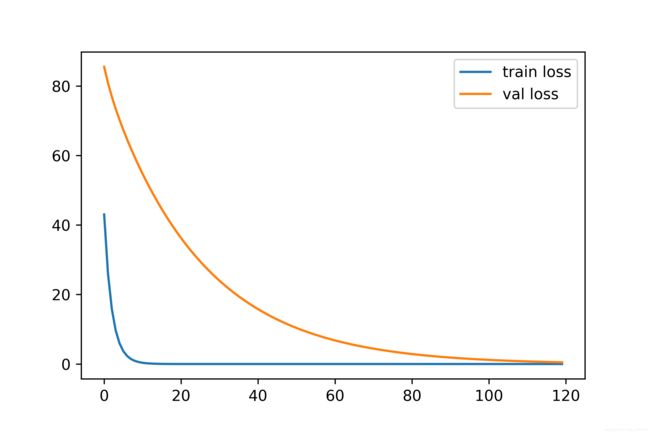
观察过拟合时的训练损失和验证损失之间的变化。可以看出,训练损失较小但验证损失一直很大,明显的过拟合现象。

下面将 L 2 L_2 L2正则化的比率调为1,观察训练损失和验证损失。此时随着训练的进行,验证损失慢慢也和训练损失一样小。 L 2 L_2 L2正则化确实能有效缓解过拟合。
current_loss = loss(outputs, model(inputs)) + 1 * l2_reg(model.W)
3. 解耦权重衰减实现
权重衰减的比率和 L 2 L_2 L2正则化比率之间的关系如下,因此比率为1的的 L 2 L_2 L2正则化对应0.02的权重衰减。
λ L 2 = λ w d 2 α \lambda_{L_2}=\frac{\lambda_{wd}}{2\alpha} λL2=2αλwd
程序大体相同,改动如下,即将代价函数中的 L 2 L_2 L2范数删除,然后在权重更新时减去权重衰减项。
current_loss = loss(outputs, model(inputs))
# ...
model.W.assign_sub(lr * grad_w + 0.02 * model.W)
此时的训练和验证损失如下图,和 L 2 L_2 L2正则化起的效果基本相同。

4. 小结
-
权重衰减,以及 L 2 L_2 L2正则化均能有效缓解过拟合。
-
随机梯度下降中 L 2 L_2 L2正则化和权重衰减等价。
-
其他自适应算法中两者不等价,要实现权重衰减只能用原始定义。