NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination光场及三维成像重建
论文地址:
[2106.01970] NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination (arxiv.org)
本文在NeRF的基础上提出了NeRFactor的改进,即基于NeRF的因式分解。将NeRF的输出送入到几个MLP之中,用MLP再次进行因式分解,获得光照,物体表面法向,光场等信息,从而提升NeRF的重建效果。
目录
关键词
贡献点
贡献点
输入与输出
形状
物体表面
曲面法向 surface normals
光照信息Light visibility
反射与BRDF
获取BRDF先验
网络输出
光照
Rendering
训练阶段
总结
关键词
rendering: 通过图片预测出空间信息,可以理解为渲染。
normal:切面法向
non-diffuse reflection:非漫反射
diffuse reflection : 漫反射
albedo:反照率。物体分为反射和反照,反射就是光直接反射,反照就是根据物体表面粗糙发生了漫反射。
σ-volume:应该是NeRF中的概念,通过NeRF估算出的物体的空间分布。
BRDF:Bidirectional Reflectance Distribution Functions,双向反射分布函数。可以理解为漫反射和反射两个反射的分布。
NeRFactor: Neural Radiance Factorization。基于神经网络的因式分解,用于将图片分解为光照和物体。是NeRF的一个改进。
贡献点
给出一系列图片,这些图片是不同位置的图片,能够估算出物体形状和光场信息。
本文指出了Nerf的一些缺点:
缺点1, NeRF models shape as a volumetric field, and as such it is computationally expensive to compute shading and visibility at each point along a camera ray for a full hemisphere of lighting. 根据相机的视线球面给出物体的估算,因此运算复杂度较高。
缺点2, the geometry estimated by NeRF contains extraneous high-frequency content that, while unnoticeable in view synthesis results, introduces high-frequency artifacts into the sur-
face normals and light visibility computed from NeRF’s geometry.NeRF获得了大量高频的无用信息
解决缺点1,作者提出了“hard surface”的近似,
解决缺点2,作者通过MLP获得连续的光照和空间信息。并且尽可能让这两个与之前NeRF的获得近似
作者提出的框架有4个预测输出,
- surface normals(物体曲面法线),
- light visibility, (光照,直线的光源)
- albedo, (漫反射)
- spatially-varying BRDFs(光场信息,可能是一系列光源)

贡献点
作者将图片因式分解为三个项目:形状、反射、光照
A strategy to distill NeRF-estimated volume density into surface geometry (with normals and light visibility)
A novel data-driven BRDF prior based on training a latent code model on real measured BRDFs
输入与输出
任务:inverse rendering: 表示将图片分解为几何geometry、材料特性material properties,光场信息lighting conditions。
输入是一系列相机图片,未知光场信息,未知相机位置。
基于单张图片的inverse rendering,需要一点的先验信息,大多数需要大量图片进行训练。例如:几何学、反射,光照等。
本文提出的方法,可以通过,单一光照的图片,依然可以较好的重建。
形状
物体表面
表示一个ray,其中,t是距离,o是摄像机的位置,d是方向。(可否理解为从d方向射向摄像机的光照?光经过的距离是t)
最终物体表面表示为:
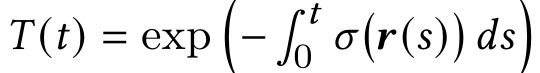
本文通过优化的NeRF获得此表面。上面这个公式也是NeRF的核心公式其中,
表示ray在距离t上被阻挡的概率。其中,sigma表示密度。
物体表面的公式没太理解,貌似是通过光照被遮挡的概率,估算出相机到物体的深度,从而估算出物体表面。
曲面法向 surface normals
法线用na表示,通过NeRF获得切向法线。但是切向法线的获得可能充满噪声。创建MLP fn用于从法向之中减少噪声。 通过物体表面,Xsurf获得n
(1) to stay close to the normals produced from the pretrained NeRF, 与物体表面近似
(2) to vary smoothly in the 3D space, 尽可能平滑
(3) to reproduce the observed appearance of the object, 重新生成物体表面信息
近似和光滑的loss:
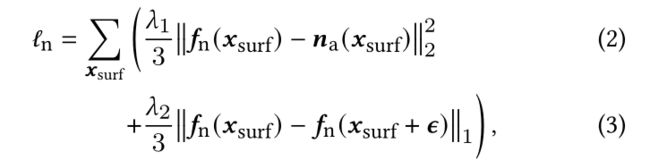
Loss中的(2),即物体通过神经网络预测得到的法线,与物体表面的法线尽可能接近。
Loss中的(3),物体的表面经过eps的扰动之后,也要与之前尽可能接近,就是平滑的目的。
光照信息Light visibility
用v下标a表示光源。NeRF会在每个光照点上获得一个 σ-volume,但是此volume充满了噪音。通过物体表面Xsurf和光源信息Wi获得可视的信息。根据MLP fv获得下面的映射:
![]()
光照信息需要尽可能满足下面的要求:
(1) to be close to the visibility traced from the NeRF, 尽可能接近NeRF获得的可视化信息
(2) to be spatially smooth, and 尽可能空间光滑。
(3) to reproduce the observed appearance。重新根据此生成物体表面。

此loss中,(4)满足MLP预测与NeRF接近,(5)满足物体表面光滑,物体的表面经过eps的扰动之后,也要与之前尽可能接近。
利用NeRF的输出作为监督信息,训练几个MLP,同时要求MLP的预测输出比NeRF更加平滑。
反射与BRDF
BRDF model R由diffuse component(Lambertian)组成,即通过漫反射和反射共同组成。

输入光线wi,反射光线wo, 物体表面Xsurf,
BRDF是双向的光照分布,所以比单向的物体反射fr多了一项,即a(Xsurf),根据物体反照率(漫反射)发出的光源。
与BRDF不同,NeRFactor用于根据现实世界预训练的大量的图片获得具体的反射信息。
反照率也通过预测MLP fr预测得出:
反射是fr,反照是fa
获取BRDF先验
通过MERL dataset数据集和预训练模型获得BRDF的先验信息。先验信息用Rusinkiewicz坐标,鲁氏坐标。表示,三个自由度。

最终根据BRDF和鲁氏坐标获得反照率r
在这里,为了预测BRDF,作者又设计了一个模型
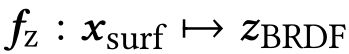
最终模型优化BRDF的loss如下:
![]()
网络输出
最终网络的non-diffuse reflectance(非漫反射)如下:

- R是所有的反射,包括漫反射和反射。
- fa即反照albedo,
- fz获得BRDF信息,
- fn根据物体表面输出法向信息,
- g用于将光照和法线转换为鲁氏坐标。
- f’用于根据法向信息和光场BRDF信息获得物体的反射
最终物体的反射和反照共同形成了输出光照。
光照
根据光照探头分别获得水平和垂直的光照信息

Rendering
将几个预测输出之后,最终的rendering equation为:

R表示所有的反射,L表示光照,n表示物体表面法向。
(12)表示,所有光源,照射到物体方向在物体表面发生的反射的积分。
(14)将R分解为漫反射fa和反射f’
网络训练时是几个loss共同作用:
![]()
分别是前面提到的,
- l recon 识别loss?
- ln法向loss
- lv光源loss
- la漫反射loss
- lz BRDF loss
- li 光源loss
训练阶段
阶段1:先用训练好的NeRF在MERL数据集上训练BRDF MLP。此时,其他的MLP是被固定的,NeRF只是提供一个形状初始化。BRDF的MLP用于提供潜在的空间信息。
阶段2:运用NeRF优化normal and visibility MLPs,此过程中暂时没有平滑的loss。
阶段3:we jointly optimize the albedo MLP, BRDF identity MLP, and light probe pixels from cratch, along with the pretrained normal and visibility MLPs
总结
总结起来,先用NeRF获得空间信息和BRDF训练,然后加入normal and visibility MLPs,最后加入平滑。
类似于在NeRF的基础上,把BRDF信息分为了漫反射和反射,并且多做了一个平滑处理,去掉了噪声。