(八)隐私计算--联邦学习
目录
联邦学习
联邦学习系统构架
联邦学习开源框架
联邦学习分类
横向联邦学习
纵向联邦学习
联邦迁移学习
联邦学习特点
参考推荐:
联邦学习概念及应用
联邦学习(Federated Learning)_草棚的博客-CSDN博客_联邦学习
联邦学习综述_NeverMoreH的博客-CSDN博客_联邦学习综述
联邦学习笔记(二)_feng_zhiyu的博客-CSDN博客_联邦学习
联邦学习综述总结_河大吴彦祖的博客-CSDN博客_联邦学习综述
初识联邦学习_AI浩的博客-CSDN博客
联邦学习相关资料_thormas1996的博客-CSDN博客
联邦学习概念_yongrl的博客-CSDN博客_联邦学习
什么是联邦学习_hellompc的博客-CSDN博客_联邦学习
联邦学习笔记(一)_feng_zhiyu的博客-CSDN博客_联邦学习
【联邦学习】联邦学习_CS正阳的博客-CSDN博客_样本对齐
【联邦学习】读书笔记(二) 隐私保护技术_牧心.的博客-CSDN博客_隐私保护技术
只看这一篇就够:快速了解联邦学习技术及应用实践_FedAI Ecosystem的博客-CSDN博客_联邦学习
联邦学习笔记(三)_feng_zhiyu的博客-CSDN博客
联邦学习
联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。其中,联邦学习可使用的机器学习算法不局限于神经网络,还包括随机森林等重要算法。联邦学习有望成为下一代人工智能协同算法和协作网络的基础。
在联邦学习白皮书中给出了明确的联邦学习的定义:
- 各方数据都保留在本地,不泄露隐私也不违反法规;
- 多个参与者联合数据建立虚拟的共有模型,并且共同获益的体系;
- 在联邦学习的体系下,各个参与者的身份和地位平等;
- 联邦学习的建模效果和将整个数据集放在一处建模的效果相同,或相差不大(在各个数据的用户对齐或特征对齐的条件下);
- 迁移学习是在用户或特征不对齐情况下,也可以在数据间通过交换加密参数达到知识迁移的效果。
综上,联邦学习的目的是:使多个参与方在保护数据隐私、满足合法合规要求的前提下继续进行机器学习,解决数据孤岛问题。在实际中,孤岛数据具有不同的分布特点,根据这些特点,可以提出相应的联邦学习方案。以孤岛数据的分布特点为依据可将联邦学习分为三类:横向联邦学习、纵向联邦学习和联邦迁移学习。
联邦学习是使得多方在不共享本地数据的前提下,进行多方协同训练的机器学习方式。因此,他在实现功能的同时,能够很好的保护数据隐私。目前联邦学习支持的算法:SecureBoost,线性回归,逻辑回归,神经网络算法等。
1、联邦学习优势
- 数据隔离,数据不会泄露到外部,满足用户隐私保护和数据安全的需求;
- 能够保证模型质量无损,不会出现负迁移,保证联邦模型比割裂的独立模型效果好;
- 参与者地位对等,能够实现公平合作;
- 能够保证参与各方在保持独立性的情况下,进行信息与模型参数的加密交换,并同时获得成长。
联邦学习系统构架
以包含两个数据拥有方(即企业 A 和 B)的场景为例介绍联邦学习的系统构架。该构架可扩展至包含多个数据拥有方的场景。假设企业 A 和 B 想联合训练一个机器学习模型,它们的业务系统分别拥有各自用户的相关数据。此外,企业 B 还拥有模型需要预测的标签数据。出于数据隐私保护和安全考虑,A 和 B 无法直接进行数据交换,可使用联邦学习系统建立模型。联邦学习系统构架由三部分构成:

第一部分:加密样本对齐。由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户,以便联合这些用户的特征进行建模。
第二部分:加密模型训练。在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。以线性回归模型为例,训练过程可分为以下 4 步:
- 协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密。
- A 和 B 之间以加密形式交互用于计算梯度的中间结果。
- A 和 B 分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并把结果汇总给 C。C 通过汇总结果计算总梯度值并将其解密。
- C 将解密后的梯度分别回传给 A 和 B,A 和 B 根据梯度更新各自模型的参数。
迭代上述步骤直至损失函数收敛,这样就完成了整个训练过程。在样本对齐及模型训练过程中,A 和 B 各自的数据均保留在本地,且训练中的数据交互也不会导致数据隐私泄露。因此,双方在联邦学习的帮助下得以实现合作训练模型。
第三部分:效果激励。联邦学习的一大特点就是它解决了为什么不同机构要加入联邦共同建模的问题,即建立模型以后模型的效果会在实际应用中表现出来,并记录在永久数据记录机制(如区块链)上。提供数据多的机构所获得的模型效果会更好,模型效果取决于数据提供方对自己和他人的贡献。这些模型的效果在联邦机制上会分发给各个机构反馈,并继续激励更多机构加入这一数据联邦。以上三部分的实施,既考虑了在多个机构间共同建模的隐私保护和效果,又考虑了以一个共识机制奖励贡献数据多的机构。所以,联邦学习是一个「闭环」的学习机制。
联邦学习开源框架
目前业界中主要的联邦学习框架有FATE、TensorFlow Federated、PaddleFL、Pysyft等。
2019年2月,微众银行开源FATE开源项目,截止2019年12月发布FATE vl.2版本,覆盖横向联邦学习,纵向联邦学习,联邦迁移学习,得到了社区内广泛的关注与应用。同时,FATE 提供20多个联邦学习算法组件,涵盖LR、GBDT、DNN等主流算法,覆盖常规商业应用场景建模需求。尤真值得注意的是,FATE提供了一站式联邦模型服务解决方案,涵盖联邦特征工程,联邦机器学习模型训练,联邦模型评估,联邦在线推理,相比真他开源框架,在工业应用上高显著的优势。
Open Minded开源的Pysyft框架,较好地支持横向联邦学习。该框架同时支持Tensorflow、Keras、Pytorch,为使用人员快速上手提供了较多的选择。Pysyft提供了安全加密算子,数值运算算子,及联邦学习算法,用户也可以高效搭建自己的联邦学习算法。相比较FATE,OpenMinded尚未提供高效的部署方案及serving端解决方案,相比工业应用,更适合作为高效的学术研究、原型开发的工具。
谷歌开源的TensorFlow Federated框架,截止2019年12月已发布至0.11版本,较好地支持横向联邦学习。其中,可以通过 Federated Learning (FL) API,与Tensorflow/Keras交互,完成分类、回归等任务。用户也可以通过真提供的Federated Core (FC) API,通过在强类型函数编程环境中将TensorFlow与分布式通信运算符相结合,简洁地表这新的联合算法。目前TensorFlow Federated在安全加密算子上缺少开放实现,同时缺少对线上生产的完善支撑。
2019年11月,百庭宣布开源真联邦学习框架PaddleFL。PaddleFL开源框架中包含了DiffieHellman等安全算子,及LR等机器学习算法。由于真开源时间较短,算子丰富程度逊于上述三个框架。PaddleFL的优势在于通过与百度机器学习开源框架Paddle Paddle的交互,吸引相关生态开发者加入开发。
联邦学习分类
我们用数据集(I,X,Y)表示训练样本,按照样本和特征的分布情况,可以将联邦学习分为:
- 横向联邦学习(Horizontal Federated Learning,HFL),适用于特征信息重叠较多的场景,通过提升样本数量达到训练模型效果的提升。比如两个异地的银行之间就可以构建横向联邦学习模型。
- 纵向联邦学习(Vertical Federated Learning,VFL),适用于参与双方样本重叠较多时的场景,通过丰富样本特征维度,实现机器学习模型的优化。比如银行和商业公司之间可以构建纵向联邦学习模型。
- 联邦迁移学习(Federated Transfer Learning,FTL),样本和特征重叠都较少时,需要进行数据迁移。

横向联邦学习
横向联邦学习在两个数据集的用户特征重叠较多,而用户重叠较少的情况下,我们把数据集按照横向(即用户维度)切分,并取出双方用户特征相同而用户不完全相同的那部分数据进行训练。这种方法叫做横向联邦学习。比如有两家不同地区的银行,它们的用户群体分别来自各自所在的地区,相互的交集很小。但是,它们的业务很相似,因此,记录的用户特征是相同的。此时,我们就可以使用横向联邦学习来构建联合模型。谷歌在2016年提出了一个针对安卓手机模型更新的数据联合建模方案:在单个用户使用安卓手机时,不断在本地更新模型参数并将参数上传到安卓云上,从而使特征维度相同的各数据拥有方建立联合模型。
- 参与方拥有的数据特征相同(包括标签),即数据特征是对齐的;训练样本ID不同(或者交集很少)。
- 横向联邦学习也称为“样本横向划分的联邦学习”,或者跨样本的联邦学习。
- 横向联邦学习可以增加训练样本的总量。

横向联邦模型
训练步骤:
- participants locally compute training gradients, mask a selection of gradients withencryption, differential privacy or secret sharing techniques, and send maskedresults to server;
- Server performs secure aggregation without learning information about any participant;
- Server send back the aggregated results to participants;
- Participants update their respective model with the decrypted gradients.
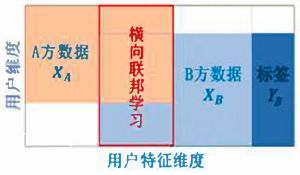
在两个数据集的用户特征重叠较多,而用户重叠较少的情况下,可将数据集按照横向(用户维度)进行切分,并取出双方用户特征相同而用户不完全相同的那部分数据进行训练,这种方法叫做横向联邦学习。Google在2016年提出了针对安卓手机模型更新的数据联合建模方案[2, 3],在不同的用户使用手机时,在手机本地持续地更新模型参数,并将参数上传至云端。从而利用不同用户的、特征维度相同的这些数据建立一个横向联邦学习方案。
纵向联邦学习
纵向联邦学习在两个数据集的用户重叠较多而用户特征重叠较少的情况下,我们把数据集按照纵向(即特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练。这种方法叫做纵向联邦学习。比如有两个不同的机构,家是某地的银行,另一家是同一个地方的电商。它们的用户群体很有可能包含该地的大部分居民因此用户的交集较大。但是,由于银行记录的都是用户的收支行为与信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力。目前,逻辑回归模型、树形结构模型和神经网络模型等众多机器学习模型已经逐渐被证实能够建立在此联邦体系上。
- 各个参与者拥有的样本ID相同,数据特征不同纵向联邦学习也称为“按特征划分的联邦学习”。
- 参与方拥有相同的样本ID。
- 参与者之间需要交换中间结果,不交换原始数据。
- 通常应用于企业间的联邦学习场景。
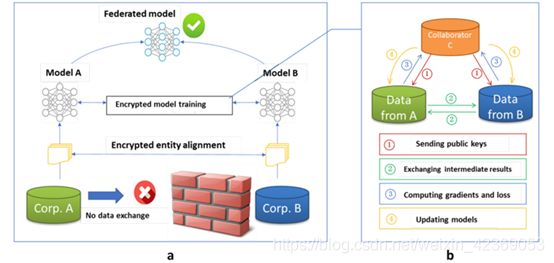
纵向联邦模型
训练步骤:
part1:Encrypted entity alignment,即隐私求交(PSI);part2:Encrypted model training.
- collaborator C creates encryption pairs, send public key to A and B;
- A and B encrypt and exchange the intermediate results for gradient and loss calculations;
- A and B computes encrypted gradients and adds additional mask, respectively,and B also computes encrypted loss; A and B send encrypted values to C;
- C decrypts and send the decrypted gradients and loss back to A and B; A and B unmask the gradients, update the model parameters accordingly.

在两个数据集的用户重叠较多,而用户特征重叠较少的情况下,可将数据集按照纵向(特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练,这种方法叫做纵向联邦学习[1]。一个常见的例子是:有两个不同机构,一家是某地的银行,另一家是同一个地方的电商。它们的用户群体很有可能包含该地的大部分居民,因此用户的交集较大。但是,由于银行记录的都是用户的收支行为与信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力的联邦学习。
目前,逻辑回归模型、树型结构模型和神经网络模型等众多机器学习模型已经逐渐被证实能够建立在这个纵向联邦学习体系上。
联邦迁移学习
联邦迁移学习在两个数据集的用户与用户特征重叠都较少的情况下,我们不对数据进行切分,而利用迁移学习国来克服数据或标签不足的情况。这种方法叫做联邦迁移学习。比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习,来解决单边数据规模小和标签样本少的问题,从而提升模型的效果。
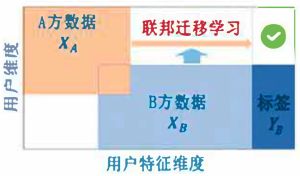
在两个数据集的用户与用户特征重叠都较少的情况下,我们部队数据进行切分,而利用迁移学习克服数据或标签不足的情况,这种方法叫做联邦迁移学习。还是借用在纵向联邦学习小节中银行和电商的例子,不同的是,银行和电商不在同一个地方,而是相去甚远。这导致,受到地域的限制,银行和电商的用户交集很小。同时,二者的数据特征交集也很小。在这种情况下,需要在联邦学习中引入迁移学习,用于解决单边数据规模小、标签样本少的问题,来提升模型的效果。
联邦学习特点
- 数据绝对掌握:每一个参与方数据都不离开本地,模型信息在各参与方之间以加密的形式传输,且
- 保证不能由模型推测出原始数据;
- 参与方不稳定:不同参与方在计算能力、通信稳定性方面存在差异,导致联邦学习相对于分布式机器学习存在不稳定情况;
- 通信代价高:参与方不稳定造成通信代价高;
- 数据非独立同分布:不同参与方数据分布不同;
- 负载不均衡:参与方在数据量级上存在差异,但联邦学习中无法实现负载均衡。
注:仅作资料整理!!
如有错误、侵权,请联系笔者更改删除!!!