【Co-Scale Conv-Attentional Image Transformers论文解读】
Co-Scale Conv-Attentional Image Transformers论文解读
- 概述
-
- conv-attention机制
- co-scale机制
-
- Serial Block
- Parallel Block
概述
Co-Scale Conv-Attentional Image Transformers是2021年ICCV的文章,主要创新点在于提出co-scale机制和conv-attention机制。co-scale主要是定义了串行块(Serial Block
)与并行块(Parallel Block),这个机制提供了不同尺度粗细粒度的交互。conv-attention机制是对qkv计算的创新,里面还包含了Convolutional Relative Position Encoding机制。将卷积操作引入position encoding.
conv-attention机制


通过改变计算顺序,使计算复杂度降低到O(NC2)
class FactorAtt_ConvRelPosEnc(nn.Module):
def forward(self, x, size):
B, N, C = x.shape
# Generate Q, K, V.
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # Shape: [3, B, h, N, Ch].
q, k, v = qkv[0], qkv[1], qkv[2] # Shape: [B, h, N, Ch].
# Factorized attention.
k_softmax = k.softmax(dim=2) # Softmax on dim N.
k_softmax_T_dot_v = einsum('b h n k, b h n v -> b h k v', k_softmax, v) # Shape: [B, h, Ch, Ch].
factor_att = einsum('b h n k, b h k v -> b h n v', q, k_softmax_T_dot_v) # Shape: [B, h, N, Ch].
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size) # Shape: [B, h, N, Ch].
# Merge and reshape.
x = self.scale * factor_att + crpe
x = x.transpose(1, 2).reshape(B, N, C) # Shape: [B, h, N, Ch] -> [B, N, h, Ch] -> [B, N, C].
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return x
在conv-attention中,除了改变计算顺序这一点,作者还引入了Convolutional Position Encoding 和Convolutional Relative Position Encoding机制,Convolutional Position Encoding其实就是将token reshape成HXWXC后使用depthwise convolution后再次reshape成token.Convolutional Relative Position Encoding则是作者为了增强局部上下文建模,将卷积引入attention模块。V经过depthwise convolution后与Q做的哈达玛积与原来attention输出相加。作者认为可以增强局部上下文建模。
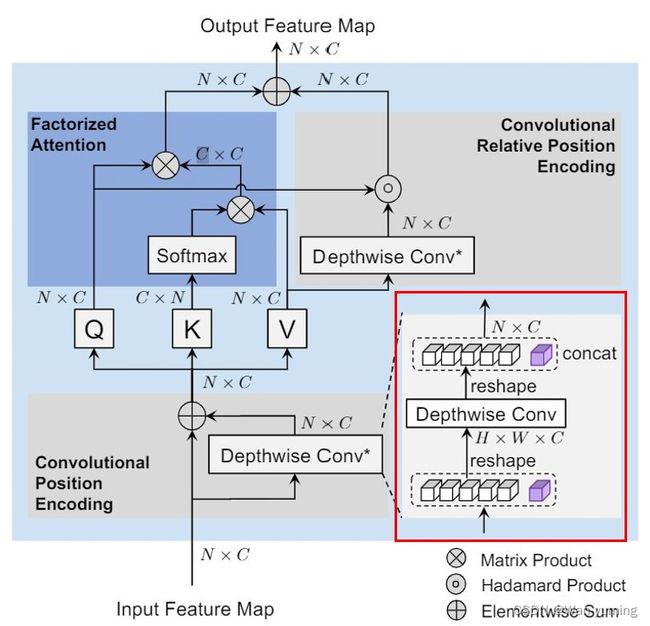
class ConvRelPosEnc(nn.Module):
""" Convolutional relative position encoding. """
def __init__(self, Ch, h, window):
"""
Initialization.
Ch: Channels per head.
h: Number of heads.
window: Window size(s) in convolutional relative positional encoding. It can have two forms:
1. An integer of window size, which assigns all attention heads with the same window size in ConvRelPosEnc.
2. A dict mapping window size to #attention head splits (e.g. {window size 1: #attention head split 1, window size 2: #attention head split 2})
It will apply different window size to the attention head splits.
"""
super().__init__()
if isinstance(window, int):
window = {window: h} # Set the same window size for all attention heads.
self.window = window
elif isinstance(window, dict):
self.window = window
else:
raise ValueError()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items():
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) * (dilation - 1)) // 2 # Determine padding size. Ref: https://discuss.pytorch.org/t/how-to-keep-the-shape-of-input-and-output-same-when-dilation-conv/14338
cur_conv = nn.Conv2d(cur_head_split*Ch, cur_head_split*Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split*Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x*Ch for x in self.head_splits]
def forward(self, q, v, size):
B, h, N, Ch = q.shape
H, W = size
assert N == 1 + H * W
# Convolutional relative position encoding.
q_img = q[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = v[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = rearrange(v_img, 'B h (H W) Ch -> B (h Ch) H W', H=H, W=W) # Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img_list = torch.split(v_img, self.channel_splits, dim=1) # Split according to channels.
conv_v_img_list = [conv(x) for conv, x in zip(self.conv_list, v_img_list)]#做depthwise conv
conv_v_img = torch.cat(conv_v_img_list, dim=1)
conv_v_img = rearrange(conv_v_img, 'B (h Ch) H W -> B h (H W) Ch', h=h) # Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
EV_hat_img = q_img * conv_v_img#哈达玛积
zero = torch.zeros((B, h, 1, Ch), dtype=q.dtype, layout=q.layout, device=q.device)
EV_hat = torch.cat((zero, EV_hat_img), dim=2) # Shape: [B, h, N, Ch].
return EV_hat
创新的attention计算方法factorattention和新引入的Convolutional Relative Position Encoding这两点构成了conv-attention模块。
co-scale机制
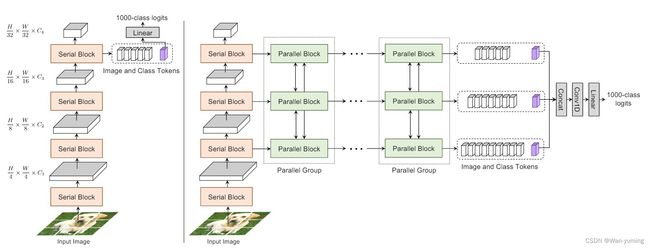
作者提出了两种架构,其中将不带有平行块(Parallel Block)的架构称为coat-lite,带有平行块的架构称为coat.显然右边的coat才是完全体,coat-lite是为了减少计算量而提出的轻量版。这个架构的主要创新点在于串行块(Serial Block)和并行块(Parallel Block),下面来看看这两个模块。
Serial Block

输入特征图经过patch embed后插入CLS token进行数个Conv-attention+FFN后,经过reshape成为输出特征图,这就是一个串行块,如果是coat-lite,在经过4个阶段的串行块后,送入Linear layer即可。由此可以看见串行块在结构上没有什么创新,只是对前面提到的conv-attention的应用。
class SerialBlock(nn.Module):
""" Serial block class.
Note: In this implementation, each serial block only contains a conv-attention and a FFN (MLP) module. """
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
shared_cpe=None, shared_crpe=None):
super().__init__()
# Conv-Attention.
self.cpe = shared_cpe
self.norm1 = norm_layer(dim)
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpe)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# MLP.
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, size):
# Conv-Attention.
x = self.cpe(x, size) # Apply convolutional position encoding.
cur = self.norm1(x)
cur = self.factoratt_crpe(cur, size) # Apply factorized attention and convolutional relative position encoding.
x = x + self.drop_path(cur)
# MLP.
cur = self.norm2(x)
cur = self.mlp(cur)
x = x + self.drop_path(cur)
return x
Parallel Block

平行块用于提供不同尺度下粗细粒度的交互,不同尺度的交互必然要涉及两个问题,一是尺度不同怎么对齐成相同,对齐后怎么交互,本文对于第一个问题是使用双线性插值来进行上采样和下采样来让各个尺度的特征图对齐,第二个问题作者构思了三种方法,一种是各个尺度的特征图直接进行attention+FFN,然后聚合,MPViT对多路径attention的处理思路与它类似,第二种是各个特征图降采样或者升采样到其他所有尺度与其他尺度特征图进行cross-attention,所谓cross-attention文中作者给出的解释是q用本尺度的,k,v使用其他尺度的,然后进行attention.第三种方法是各自attention后将所有的特征图放缩后相加,再执行聚合。
作者根据实验最后选择了第三种方法feature Interpolation,它的效果最好。
