【VoxelNet —— 体素网络】
VoxelNet: 基于体素的端到端目标检测
- 体素
- VoxelNet的框架:
- 一.特征学习网络( Feature learning network)
-
- 1.1体素分块(Voxel Partition)
- 1.2点云分组(Grouping)
- 1.3随机采样(Random Sampling)
- 1.4多层的体素特征编码(Stacked Voxel Feature Encoding)
- 1.5稀疏张量表示(Sparse Tensor Representation)
- 二.卷积中间层(Convolutional middle layers)
- 三.区域提案网络(Region proposal network)
- 附: loss
- 附:高效运行( Efficient Implementation)
体素
体素——————像素
lidar 可以提供可靠的深度信息,用于准确定位对象并表征其形状,由于 3D 空间的非均匀采样、传感器的有效范围、遮挡和相对姿态等因素,LiDAR 点云稀疏且点密度变化很大。
将采集到的点云数据进行网格划分,类似于将图片进行平面划分,可以更加高效的处理点云。
将划分好的点云输送到端到端的网络结构中,以端到端的方式从点云中学习判别性特征表示并预测准确的 3D 边界框,避免了手动特征工程引入的信息瓶颈。
VoxelNet的框架:
特征学习网络( Feature learning network)
卷积中间层(Convolutional middle layers)
区域提案网络(Region proposal network)
一.特征学习网络( Feature learning network)
这一模块的操作主要就是进行点云的处理,分为5个步骤:
1.1体素分块(Voxel Partition)
先用大的3D空间容纳所有的点云数据,其深度、高度和宽度分别为 ( D , H , W )。再在其内部自定义体素尺寸(v D ,v H ,v W ),则整个数据的三维体素化的结果在各个坐标上生成的体素格(voxel grid)的个数为:(D /v D , H/ v H , W /v W)
1.2点云分组(Grouping)
分组就是将所有的点云数据划分到所定义的体素中,但是因为点云是稀疏的,并且在在整个空间中具有高度可变的点密度,所以分组之后体素中的点云个数各不相同,甚至有些体素中就没有点云。
1.3随机采样(Random Sampling)
随机采样就是抽取上面所定义的体素。因为分出的体素比较多,而且很多就没有点云数据,所以随机采样可以减少计算量,有效降低因为点云数据不平衡带来的信息偏差。另外论文中定义了一个体素中所包含最大点云数量T。
1.4多层的体素特征编码(Stacked Voxel Feature Encoding)
这一部分就是对点云进行特征编码,Voxel Feature Encoding简称VFE,是本文的核心思想。
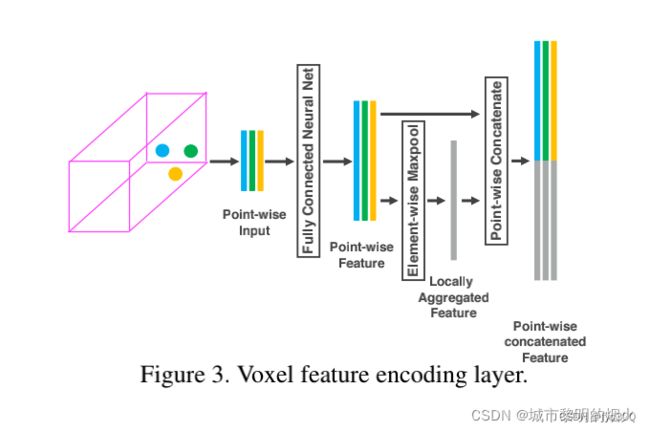
1.5稀疏张量表示(Sparse Tensor Representation)
虽然一次lidar扫描包含接近10万个点,但是超过90%的体素格都是空的,使用稀疏张量来描述非空体素格在于能够降低反向传播时的内存和计算消耗。
上述得到的特征可以用4维的稀疏张量表示:C × D’ × H’ × W’。
二.卷积中间层(Convolutional middle layers)
我们使用ConvMD ( cin,cout, k , s , p ) 来表示一个M维卷积算子,其中cin和cout 是输入和输出通道的数量,k,s和p是m维向量分别根据内核大小、步幅大小和填充大小来确定。当m维的大小相同时,我们使用一个标量来表示例如k=(k,k,k)的大小。
三.区域提案网络(Region proposal network)
RPN 这个概念来源于 Faster R-CNN 系列,VoxelNet 中也运用到了 RPN,但经过了改良。
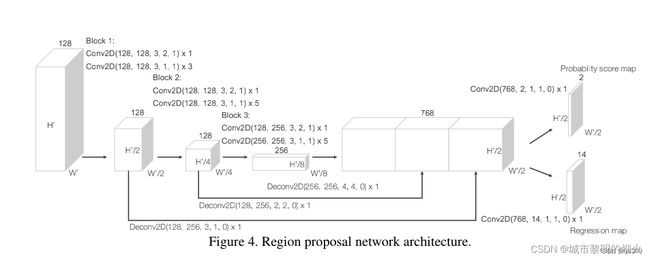
输入是卷积中间层提供的特征,整个网络包含三个全卷积块,每个块的第一层通过步长为2的卷积将特征图采样为一半,之后是三个步长为1的卷积层,每个卷积层都包含BN层和ReLU操作。
将每一个块的输出都上采样到一个固定的尺寸并串联构造高分辨率的特征图。最后,该特征图通过两种二维卷积被输出到期望的学习目标:
概率评分图(Probability Score Map )
回归图(Regression Map)
附: loss
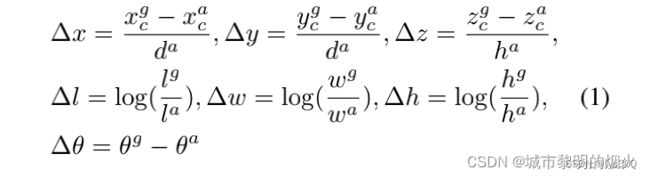
其中 (d ^a )^2= ( l ^a ) ^2 + ( w ^a ) ^2 是锚盒底部的对角线。
则最终的损失函数为:
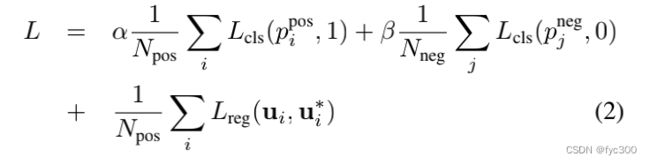
附:高效运行( Efficient Implementation)
gpu被优化用于处理致密张量结构。但是点云分布稀疏。
论文设计了一种将点云转换为密集张量结构的方法,其中堆叠的VFE操作可以在点和体素之间并行处理。
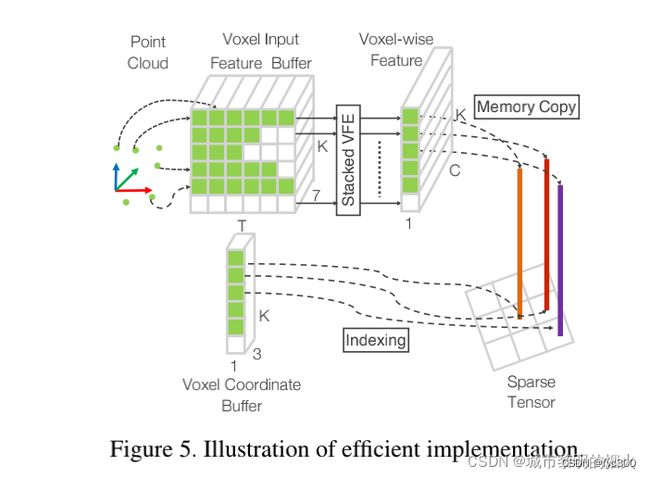
初始化一个K×T×7维张量结构来存储体素输入特征缓冲区,其中K是是非空体素的最大数量,T是最大值每个体素的点数,7是每个点的输入编码维度。
这些点在处理前是随机化的。对于点云中的每个点,我们检查是否有相应的体素已经存在。这个查找操作是在O(1)中使用一个哈希表有效地执行的,其中体素坐标被用作哈希键。
如果体素已经初始化,那么我们将点插入到体素位置,如果有小于T个点,否则该点将被忽略。如果体素没有被初始化,我们将初始化一个新的体素,将它的坐标存储在体素坐标缓冲区中,然后in插入该点到这个体素位置。
体素输入特征和坐标缓冲区可以通过通过点列表来构造,因此其复杂度为O(n)。为了进一步提高内存/计算效率,可以只存储有限数量的体素(K),并忽略来自具有很少点的体素的点。
————————————————
参考连接:https://blog.csdn.net/qingliange/article/details/122783278