YOLOV4-模型训练和代码-pytorch
训练超参
batch,subvision,burn in,学习率等等
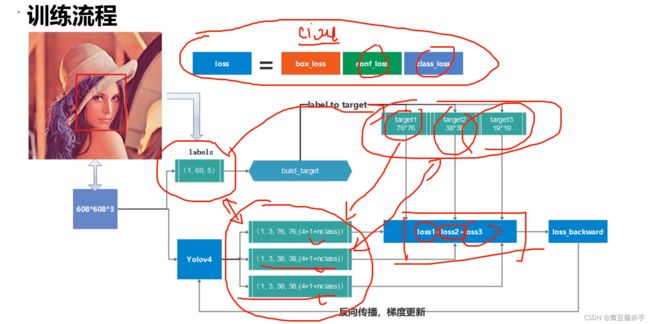
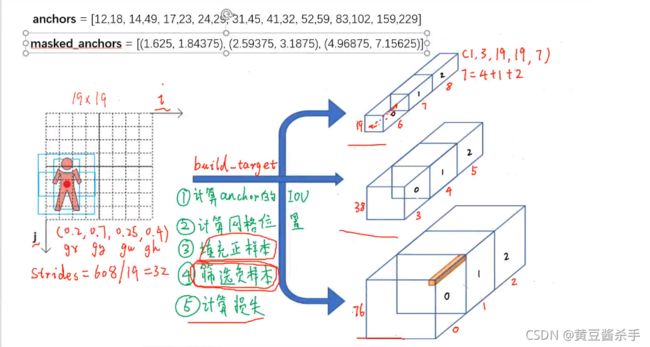
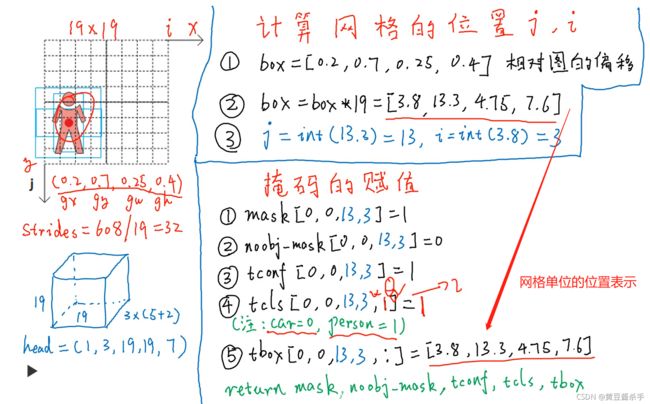
build target
从Ground Truth到target的过程


损失函数
位置回归损失,物体自信度损失(正样本和负样本),类别交叉熵损失
import cv2
from random import shuffle
import numpy as np
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
from PIL import Image
from utils.utils import bbox_iou, merge_bboxes
def iou(_box_a, _box_b):
b1_x1, b1_x2 = _box_a[:, 0] - _box_a[:, 2] / 2, _box_a[:, 0] + _box_a[:, 2] / 2
b1_y1, b1_y2 = _box_a[:, 1] - _box_a[:, 3] / 2, _box_a[:, 1] + _box_a[:, 3] / 2
b2_x1, b2_x2 = _box_b[:, 0] - _box_b[:, 2] / 2, _box_b[:, 0] + _box_b[:, 2] / 2
b2_y1, b2_y2 = _box_b[:, 1] - _box_b[:, 3] / 2, _box_b[:, 1] + _box_b[:, 3] / 2
box_a = torch.zeros_like(_box_a)
box_b = torch.zeros_like(_box_b)
box_a[:, 0], box_a[:, 1], box_a[:, 2], box_a[:, 3] = b1_x1, b1_y1, b1_x2, b1_y2
box_b[:, 0], box_b[:, 1], box_b[:, 2], box_b[:, 3] = b2_x1, b2_y1, b2_x2, b2_y2
A = box_a.size(0)
B = box_b.size(0)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
inter = inter[:, :, 0] * inter[:, :, 1]
# 计算先验框和真实框各自的面积
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
# 求IOU
union = area_a + area_b - inter
return inter / union # [A,B]
#---------------------------------------------------#
# 平滑标签
#---------------------------------------------------#
def smooth_labels(y_true, label_smoothing,num_classes):
return y_true * (1.0 - label_smoothing) + label_smoothing / num_classes
def box_ciou(b1, b2):
"""
输入为:
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
返回为:
-------
ciou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
# 求出预测框左上角右下角
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# 求出真实框左上角右下角
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
# 求真实框和预测框所有的iou
intersect_mins = torch.max(b1_mins, b2_mins)
intersect_maxes = torch.min(b1_maxes, b2_maxes)
intersect_wh = torch.max(intersect_maxes - intersect_mins, torch.zeros_like(intersect_maxes))
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
iou = intersect_area / torch.clamp(union_area,min = 1e-6)
# 计算中心的差距
center_distance = torch.sum(torch.pow((b1_xy - b2_xy), 2), axis=-1)
# 找到包裹两个框的最小框的左上角和右下角
enclose_mins = torch.min(b1_mins, b2_mins)
enclose_maxes = torch.max(b1_maxes, b2_maxes)
enclose_wh = torch.max(enclose_maxes - enclose_mins, torch.zeros_like(intersect_maxes))
# 计算对角线距离
enclose_diagonal = torch.sum(torch.pow(enclose_wh,2), axis=-1)
ciou = iou - 1.0 * (center_distance) / torch.clamp(enclose_diagonal,min = 1e-6)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(b1_wh[..., 0]/torch.clamp(b1_wh[..., 1],min = 1e-6)) - torch.atan(b2_wh[..., 0]/torch.clamp(b2_wh[..., 1],min = 1e-6))), 2)
alpha = v / torch.clamp((1.0 - iou + v),min=1e-6)
ciou = ciou - alpha * v
return ciou
def clip_by_tensor(t,t_min,t_max):
t=t.float()
result = (t >= t_min).float() * t + (t < t_min).float() * t_min
result = (result <= t_max).float() * result + (result > t_max).float() * t_max
return result
def MSELoss(pred,target):
return (pred-target)**2
def BCELoss(pred,target):
epsilon = 1e-7
pred = clip_by_tensor(pred, epsilon, 1.0 - epsilon)
output = -target * torch.log(pred) - (1.0 - target) * torch.log(1.0 - pred)
return output
class YOLOLoss(nn.Module):
def __init__(self, anchors, num_classes, img_size, label_smooth=0, cuda=True):
super(YOLOLoss, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.img_size = img_size
self.feature_length = [img_size[0]//8,img_size[0]//16,img_size[0]//32]
self.label_smooth = label_smooth
self.ignore_threshold = 0.7
self.lambda_conf = 1.0
self.lambda_cls = 1.0
self.lambda_loc = 1.0
self.cuda = cuda
def forward(self, input, targets=None):
# input为bs,3*(5+num_classes),13,13
# 一共多少张图片
bs = input.size(0)
# 特征层的高
in_h = input.size(2)
# 特征层的宽
in_w = input.size(3)
# 计算步长
# 每一个特征点对应原来的图片上多少个像素点
# 如果特征层为13x13的话,一个特征点就对应原来的图片上的32个像素点
stride_h = self.img_size[1] / in_h
stride_w = self.img_size[0] / in_w
# 把先验框的尺寸调整成特征层大小的形式
# 计算出先验框在特征层上对应的宽高
scaled_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors]
# bs,3*(5+num_classes),13,13 -> bs,3,13,13,(5+num_classes)
prediction = input.view(bs, int(self.num_anchors/3),
self.bbox_attrs, in_h, in_w).permute(0, 1, 3, 4, 2).contiguous()
# 对prediction预测进行调整
conf = torch.sigmoid(prediction[..., 4]) # Conf
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
# 找到哪些先验框内部包含物体
mask, noobj_mask, t_box, tconf, tcls, box_loss_scale_x, box_loss_scale_y = self.get_target(targets, scaled_anchors,in_w, in_h,self.ignore_threshold)
noobj_mask, pred_boxes_for_ciou = self.get_ignore(prediction, targets, scaled_anchors, in_w, in_h, noobj_mask)
if self.cuda:
mask, noobj_mask = mask.cuda(), noobj_mask.cuda()
box_loss_scale_x, box_loss_scale_y= box_loss_scale_x.cuda(), box_loss_scale_y.cuda()
tconf, tcls = tconf.cuda(), tcls.cuda()
pred_boxes_for_ciou = pred_boxes_for_ciou.cuda()
t_box = t_box.cuda()
box_loss_scale = 2-box_loss_scale_x*box_loss_scale_y
# losses.
ciou = box_ciou( pred_boxes_for_ciou[mask.bool()], t_box[mask.bool()])
loss_ciou = 1 - ciou
loss_ciou = loss_ciou * box_loss_scale[mask.bool()]
# ciou = (1 - box_ciou( pred_boxes_for_ciou[mask.bool()], t_box[mask.bool()]))* box_loss_scale[mask.bool()]
loss_loc = torch.sum(loss_ciou / bs)
loss_conf = torch.sum(BCELoss(conf, mask) * mask / bs) + \
torch.sum(BCELoss(conf, mask) * noobj_mask / bs)
# print(smooth_labels(tcls[mask == 1],self.label_smooth,self.num_classes))
loss_cls = torch.sum(BCELoss(pred_cls[mask == 1], smooth_labels(tcls[mask == 1],self.label_smooth,self.num_classes))/bs)
# print(loss_loc,loss_conf,loss_cls)
loss = loss_conf * self.lambda_conf + loss_cls * self.lambda_cls + loss_loc * self.lambda_loc
return loss, loss_conf.item(), loss_cls.item(), loss_loc.item()
def get_target(self, target, anchors, in_w, in_h, ignore_threshold):
# 计算一共有多少张图片
bs = len(target)
# 获得先验框
anchor_index = [[0,1,2],[3,4,5],[6,7,8]][self.feature_length.index(in_w)]
subtract_index = [0,3,6][self.feature_length.index(in_w)]
# 创建全是0或者全是1的阵列
mask = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
noobj_mask = torch.ones(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
tx = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
ty = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
tw = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
th = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
t_box = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, 4, requires_grad=False)
tconf = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
tcls = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, self.num_classes, requires_grad=False)
box_loss_scale_x = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
box_loss_scale_y = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False)
for b in range(bs):
for t in range(target[b].shape[0]):
# 计算出在特征层上的点位
gx = target[b][t, 0] * in_w
gy = target[b][t, 1] * in_h
gw = target[b][t, 2] * in_w
gh = target[b][t, 3] * in_h
# 计算出属于哪个网格
gi = int(gx)
gj = int(gy)
# 计算真实框的位置
gt_box = torch.FloatTensor(np.array([0, 0, gw, gh])).unsqueeze(0)
# 计算出所有先验框的位置
anchor_shapes = torch.FloatTensor(np.concatenate((np.zeros((self.num_anchors, 2)),
np.array(anchors)), 1))
# 计算重合程度
anch_ious = bbox_iou(gt_box, anchor_shapes)
# Find the best matching anchor box
best_n = np.argmax(anch_ious)
if best_n not in anchor_index:
continue
# Masks
if (gj < in_h) and (gi < in_w):
best_n = best_n - subtract_index
# 判定哪些先验框内部真实的存在物体
noobj_mask[b, best_n, gj, gi] = 0
mask[b, best_n, gj, gi] = 1
# 计算先验框中心调整参数
tx[b, best_n, gj, gi] = gx
ty[b, best_n, gj, gi] = gy
# 计算先验框宽高调整参数
tw[b, best_n, gj, gi] = gw
th[b, best_n, gj, gi] = gh
# 用于获得xywh的比例
box_loss_scale_x[b, best_n, gj, gi] = target[b][t, 2]
box_loss_scale_y[b, best_n, gj, gi] = target[b][t, 3]
# 物体置信度
tconf[b, best_n, gj, gi] = 1
# 种类
tcls[b, best_n, gj, gi, int(target[b][t, 4])] = 1
else:
print('Step {0} out of bound'.format(b))
print('gj: {0}, height: {1} | gi: {2}, width: {3}'.format(gj, in_h, gi, in_w))
continue
t_box[...,0] = tx
t_box[...,1] = ty
t_box[...,2] = tw
t_box[...,3] = th
return mask, noobj_mask, t_box, tconf, tcls, box_loss_scale_x, box_loss_scale_y
def get_ignore(self,prediction,target,scaled_anchors,in_w, in_h,noobj_mask):
bs = len(target)
anchor_index = [[0,1,2],[3,4,5],[6,7,8]][self.feature_length.index(in_w)]
scaled_anchors = np.array(scaled_anchors)[anchor_index]
# 先验框的中心位置的调整参数
x = torch.sigmoid(prediction[..., 0])
y = torch.sigmoid(prediction[..., 1])
# 先验框的宽高调整参数
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
# 生成网格,先验框中心,网格左上角
grid_x = torch.linspace(0, in_w - 1, in_w).repeat(in_w, 1).repeat(
int(bs*self.num_anchors/3), 1, 1).view(x.shape).type(FloatTensor)
grid_y = torch.linspace(0, in_h - 1, in_h).repeat(in_h, 1).t().repeat(
int(bs*self.num_anchors/3), 1, 1).view(y.shape).type(FloatTensor)
# 生成先验框的宽高
anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0]))
anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1]))
anchor_w = anchor_w.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(w.shape)
anchor_h = anchor_h.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(h.shape)
# 计算调整后的先验框中心与宽高
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x + grid_x
pred_boxes[..., 1] = y + grid_y
pred_boxes[..., 2] = torch.exp(w) * anchor_w
pred_boxes[..., 3] = torch.exp(h) * anchor_h
for i in range(bs):
pred_boxes_for_ignore = pred_boxes[i]
pred_boxes_for_ignore = pred_boxes_for_ignore.view(-1, 4)
if len(target[i]) > 0:
gx = target[i][:, 0:1] * in_w
gy = target[i][:, 1:2] * in_h
gw = target[i][:, 2:3] * in_w
gh = target[i][:, 3:4] * in_h
gt_box = torch.FloatTensor(np.concatenate([gx, gy, gw, gh],-1)).type(FloatTensor)
anch_ious = iou(gt_box, pred_boxes_for_ignore)
for t in range(target[i].shape[0]):
anch_iou = anch_ious[t].view(pred_boxes[i].size()[:3])
noobj_mask[i][anch_iou>self.ignore_threshold] = 0
return noobj_mask, pred_boxes
训练代码构建
代码讲解和实现
import os
import sys
sys.path.append(r'D:\ubuntu_share\yolov4-pytorch1')
import numpy as np
import time
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
from torch.utils.data import DataLoader
from utils.dataloader import train_dataset_collate, test_dataset_collate, TrainDataset, TestDataset
from utils.generator import TrainGenerator, TestGenerator
from yolo_loss import YOLOLoss
from yolo_layer import YoloLayer
from tqdm import tqdm
from darknet.darknet import *
from easydict import EasyDict
from config import Cfg
from Evaluation.map_eval_pil import compute_map
from tensorboardX import SummaryWriter
from utils.utils import *
Cfg.darknet_cfg = 'work_dir/yolo4_train.cfg'
Cfg.train_data = 'work_dir/my_train1.txt'
Cfg.anchors_path = 'work_dir/yolo_anchors.txt'
Cfg.classes_path = 'work_dir/my_classes.txt'
Cfg.weights_path = 'weights/yolov4.weights'
#Cfg.pth_path = 'pth/yolo4_weights_my.pth'
Cfg.pth_path = 'chk_dark/Epoch_050_Loss_7.7722.pth'
Cfg.check = 'chk_dark'
Cfg.use_data_loader = True
Cfg.first_train = False
Cfg.cur_epoch = 0
Cfg.total_epoch = 80
Cfg.freeze_mode = False
#valid
Cfg.valid_mode = False
Cfg.confidence = 0.3
Cfg.nms_thresh = 0.4
Cfg.draw_box = True
Cfg.save_error_miss = False
Cfg.input_dir = r'D:\ubuntu_share\yolov4-pytorch\object-detection-crowdai'
Cfg.save_err_mis = True
#调用Evaluation模块, 进行map计算和类别准召率计算
def make_labels_and_compute_map(infos, classes, input_dir, save_err_miss=False):
out_lines,gt_lines = [],[]
out_path = 'Evaluation/out.txt'
gt_path = 'Evaluation/true.txt'
foutw = open(out_path, 'w')
fgtw = open(gt_path, 'w')
for info in infos:
out, gt, shapes = info
for i, images in enumerate(out):
for box in images:
bbx = [box[0]*shapes[i][1], box[1]*shapes[i][0], box[2]*shapes[i][1], box[3]*shapes[i][0]]
bbx = str(bbx)
cls = classes[int(box[6])]
prob = str(box[4])
img_name = os.path.split(shapes[i][2])[-1]
line = '\t'.join([img_name, 'Out:', cls, prob, bbx])+'\n'
out_lines.append(line)
for i, images in enumerate(gt):
for box in images:
bbx = str(box.tolist()[0:4])
cls = classes[int(box[4])]
img_name = os.path.split(shapes[i][2])[-1]
line = '\t'.join([img_name, 'Out:', cls, '1.0', bbx])+'\n'
gt_lines.append(line)
foutw.writelines(out_lines)
fgtw.writelines(gt_lines)
foutw.close()
fgtw.close()
args = EasyDict()
args.annotation_file = 'Evaluation/true.txt'
args.detection_file = 'Evaluation/out.txt'
args.detect_subclass = False
args.confidence = 0.2
args.iou = 0.3
args.record_mistake = True
args.draw_full_img = save_err_miss
args.draw_cut_box = False
args.input_dir = input_dir
args.out_dir = 'out_dir'
Map = compute_map(args)
return Map
# ---------------------------------------------------#
# 获得类和先验框
# ---------------------------------------------------#
def get_classes(classes_path):
'''loads the classes'''
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
'''loads the anchors from a file'''
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape([-1, 3, 2])
# return np.array(anchors).reshape([-1, 3, 2])[::-1, :, :]
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def gen_lr_scheduler(lr, cur_epoch, model):
init_lr = lr*pow(0.9, cur_epoch)
print('init learning rate:', init_lr)
optimizer = optim.Adam(model.parameters(), init_lr, weight_decay=5e-4)
if Cfg.cosine_lr:
lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5, eta_min=1e-5)
else:
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.9)
return lr_scheduler,optimizer
def gen_burnin_lr_scheduler(lr, cur_batch, model):
# learning rate setup
def burnin_schedule(i):
i = i+1
if i < Cfg.burn_in:
factor = pow(i / Cfg.burn_in, 4)
elif i < Cfg.steps[0]:
factor = 1.0
elif i < Cfg.steps[1]:
factor = 0.1
else:
factor = 0.01
return factor
if Cfg.TRAIN_OPTIMIZER == 'adam':
optimizer = optim.Adam(
[{'params': model.parameters(), 'initial_lr': lr}],
lr=lr,
betas=(0.9, 0.999),
eps=1e-08,
)
elif Cfg.TRAIN_OPTIMIZER == 'sgd':
optimizer = optim.SGD(
[{'params': model.parameters(), 'initial_lr': lr}],
lr=lr,
momentum=Cfg.momentum,
weight_decay=Cfg.decay,
)
else:
print('optimizer must be adam or sgd...')
return None,None
scheduler = optim.lr_scheduler.LambdaLR(optimizer, burnin_schedule, last_epoch=cur_batch-1)
print('update learning rate:', scheduler.get_last_lr()[0])
return scheduler, optimizer
def get_train_lines(train_data):
# 0.1用于验证,0.9用于训练
val_split = 0.1
with open(train_data) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines) * val_split)
num_train = len(lines) - num_val
return lines, num_train, num_val
def freeze_training_dark(model, flag=False, layers=137):
for name, param in model.named_parameters():
if int(name.split('.')[1]) <= layers:
print(int(name.split('.')[1]))
param.requires_grad = flag
def print_model(model):
model_dict = model.state_dict() # 会返回网络结构参数的名称,作为字典键值,参数权重作为值
for key in model_dict:
print('model items:', key, '---->', np.shape(model_dict[key]))
def load_model_pth(model, pth):
print('Loading weights into state dict, name: %s'%(pth))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(pth, map_location=device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
for key in pretrained_dict:
print('pretrained items:', key)
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
return model
def get_epoch_by_pth():
try:
pth = Cfg.pth_path
epoch = os.path.split(pth)[-1].split('_')[1]
epoch = int(epoch)
except Exception as e:
print(e, 'start epoch: %d'%Cfg.cur_epoch)
return Cfg.cur_epoch
return epoch
def find_pth_by_epoch(epoch, path):
pth_list = os.listdir(path)
for name in pth_list:
curpo = name.split('_')[1]
if curpo == '%03d'%(epoch):
return os.path.join(path, name)
return ''
def valid(epoch_lis, classes, draw=True, cuda=True, anchors=[]):
writer = SummaryWriter(log_dir='valid_logs',flush_secs=60)
epoch_size_val = num_val // gpu_batch
model = Darknet(Darknet_Cfg)
anchor_masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
yolo_decodes = []
anchors = anchors.reshape([-1])
for i in range(3):
head = YoloLayer((Cfg.width, Cfg.height), anchor_masks, len(classes),
anchors, anchors.shape[0] // 2).eval()
yolo_decodes.append(head)
if Use_Data_Loader:
val_dataset = TestDataset(lines[num_train:], (input_shape[0], input_shape[1]))
gen_val = DataLoader(val_dataset, batch_size=gpu_batch, num_workers=8, pin_memory=True,
drop_last=True, collate_fn=test_dataset_collate)
else:
gen_val = TestGenerator(gpu_batch, lines[num_train:],
(input_shape[0], input_shape[1])).generate()
for epo in epoch_lis:
pth_path = find_pth_by_epoch(epo, Cfg.check)
if not pth_path:
print('pth_path is error...')
return False
model = load_model_pth(model, pth_path)
cudnn.benchmark = True
model = model.cuda()
model.eval() # 将模型设置为验证模式,就不会计算梯度,节省显存
with tqdm(total=epoch_size_val, mininterval=0.3) as pbar:
infos = []
for i, batch in enumerate(gen_val):
images_src, images, targets, shapes = batch[0], batch[1], batch[2], batch[3]
with torch.no_grad():
if cuda:
images_val = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
else:
images_val = Variable(torch.from_numpy(images).type(torch.FloatTensor))
outputs = model(images_val)
output_list = []
for i in range(3):
output_list.append(yolo_decodes[i](outputs[i]))
output = torch.cat(output_list, 1)
batch_detections = non_max_suppression(output, len(classes),
conf_thres=Cfg.confidence,
nms_thres=Cfg.nms_thresh)
#print(batch_detections)
boxs = [box.cpu().numpy() for box in batch_detections if box != None]
#boxs = utils.post_processing(images_val, Cfg.confidence, Cfg.nms_thresh, outputs)
infos.append([boxs, targets, shapes])
if draw:
for x in range(len(boxs)):
os.makedirs('result_%d'%epo, exist_ok=True)
savename = os.path.join('result_%d'%epo, os.path.split(shapes[x][2])[-1])
plot_boxes_cv2(images_src[x], boxs[x], savename=savename, class_names=class_names)
pbar.update(1)
print()
print('===========================================================================================================')
print('++++++++cur valid epoch %d, pth_name: %s++++++++'%(epo, pth_path))
Map = make_labels_and_compute_map(infos, classes, Cfg.input_dir, save_err_miss=Cfg.save_err_mis)
writer.add_scalar('MAP/epoch', Map, epo)
print()
return True
def train(cur_epoch, Epoch, cuda=True, anchors=[]):
#使用tensorboardX来可视化训练指标
writer = SummaryWriter(log_dir='train_logs',flush_secs=60)
model = Darknet(Darknet_Cfg)
model.print_network() # 打印网络结构,同样可以采用model.print_model()
#第一次训练直接导入darknet的权重
#中间训练导入check_point里的权重
#cut:
# 默认: 137, 推荐104(only backbone), 116(backbone+SPP), 126(backbone+SPP+1_concat)
# cut必须 < 138,因为138刚好是76的1X1卷积头部,不同类别数的检测任务,1X1预测卷积的权重参数是不一样的
if Cfg.first_train:
model.load_weights(weights_path, pretrained=True, cut=116)
else:
model = load_model_pth(model, pth_path)
cudnn.benchmark = True
model = model.cuda()
# 建立loss函数
yolo_losses = []
for i in range(3):
yolo_losses.append(YOLOLoss(np.reshape(anchors, [-1, 2]), num_classes,
(input_shape[1], input_shape[0]), smoooth_label)) # 每三个头计算LOSS的时候就会调用前向传播
#lr_scheduler, optimizer = gen_lr_scheduler(lr, cur_epoch, model)
#使用darknet框架里的burn_in训练方法,调整学习率
lr_scheduler, optimizer = gen_burnin_lr_scheduler(lr, cur_batch, model)
# if Cfg.freeze_mode:
# freeze_training_dark(model, flag=False, layers=137)
# else:
# freeze_training_dark(model, flag=True, layers=137)
if Use_Data_Loader:
train_dataset = TrainDataset(lines[:num_train], (input_shape[0], input_shape[1]), mosaic=mosaic) # 检查batch中的图像是不是会出错,如果出错的话定位到出错图像
gen = DataLoader(train_dataset, batch_size=gpu_batch, num_workers=8, pin_memory=True,
drop_last=True, collate_fn=train_dataset_collate) # 在这里进行了数据增强
else:
gen = TrainGenerator(gpu_batch, lines[:num_train],
(input_shape[0], input_shape[1])).generate(mosaic=mosaic) # 检查batch中的图像是不是会出错,如果出错的话定位到出错图像
epoch_size = max(1, num_train // gpu_batch)
for epoch in range(cur_epoch, Epoch):
total_loss = 0
cur_step = 0
with tqdm(total=epoch_size, desc=f'Epoch {epoch + 1}/{Epoch}', postfix=dict, mininterval=0.3) as pbar:
model.train()
start_time = time.time()
for iteration, batch in enumerate(gen):
if iteration >= epoch_size:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
else:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
outputs = model(images)
losses = []
losses_loc = []
losses_conf = []
losses_cls = []
for i in range(3):
loss_item = yolo_losses[i](outputs[i], targets)
losses.append(loss_item[0])
losses_loc.append(loss_item[3])
losses_conf.append(loss_item[1])
losses_cls.append(loss_item[2])
loss = sum(losses) / Cfg.subdivisions
loss_loc = sum(losses_loc)
loss_conf = sum(losses_conf)
loss_cls = sum(losses_cls)
loss.backward()
waste_time = time.time() - start_time
total_loss += loss
cur_step += 1
#将第五个Epoch开始写入到tensorboard,每一步都写
if epoch > 2:
writer.add_scalar('total_loss/gpu_batch', loss*Cfg.subdivisions, (epoch * epoch_size + iteration))
writer.add_scalar('loss_loc/gpu_batch', loss_loc, (epoch * epoch_size + iteration))
writer.add_scalar('loss_conf/gpu_batch', loss_conf, (epoch * epoch_size + iteration))
writer.add_scalar('loss_cls/gpu_batch', loss_cls, (epoch * epoch_size + iteration))
if cur_step % Cfg.subdivisions == 0:
optimizer.step()
if Cfg.burn_in > 0:
lr_scheduler.step()
model.zero_grad()
pbar.set_postfix(**{'loss_cur': loss.item()*Cfg.subdivisions,
'loss_total': total_loss.item() / (iteration + 1)*Cfg.subdivisions,
'lr': get_lr(optimizer),
'step/s': waste_time})
pbar.update(1)
start_time = time.time()
# if Cfg.burn_in == 0:
# lr_scheduler.step()
print('Epoch:' + str(epoch + 1) + '/' + str(Epoch))
print('Total Loss: %.4f || Last Loss: %.4f ' % (total_loss / (epoch_size + 1)*Cfg.subdivisions, loss.item()*Cfg.subdivisions))
print('Saving state, iter:', str(epoch + 1))
torch.save(model.state_dict(), '%s/Epoch_%03d_Loss_%.4f.pth' % (Cfg.check,
(epoch + 1), total_loss / (epoch_size + 1)*Cfg.subdivisions))
if __name__ == "__main__":
# 一般为608
input_shape = (Cfg.h, Cfg.w)
# 是否使用余弦学习率
Cosine_lr = Cfg.cosine_lr
# 是否使用马赛克数据增强
mosaic = Cfg.mosaic
# 用于设定是否使用cuda
Cuda = True
smoooth_label = Cfg.smoooth_label
# -------------------------------#
# Dataloder的使用
# -------------------------------#
Use_Data_Loader = Cfg.use_data_loader
Darknet_Cfg = Cfg.darknet_cfg
train_data = Cfg.train_data
# -------------------------------#
# 获得先验框和类
# -------------------------------#
class_names = get_classes(Cfg.classes_path)
num_classes = len(class_names)
print('classes:', class_names, num_classes)
lr = Cfg.learning_rate
batch_size = Cfg.batch
#是否为首次训练
if Cfg.first_train:
cur_epoch = 0
else:
cur_epoch = get_epoch_by_pth()
total_epoch = Cfg.total_epoch
# 一次送入GPU的数据量
gpu_batch = Cfg.batch // Cfg.subdivisions # gpu_batch=8
lines, num_train, num_val = get_train_lines(train_data)
# 当前的训练batch数,用于调节是否burn_in,以及学习率,恢复训练时会使用到
# 首次训练为0
cur_batch = num_train * cur_epoch // batch_size
# 1.需要生成的先验框尺寸,如果用darknet权重和cfg加载,会使用yolov4.cfg里的anchors
# 2.对于计算训练损失,不论是darknet权重加载还是pth加载,都需要使用这个参数
anchors = get_anchors(Cfg.anchors_path)
weights_path = Cfg.weights_path
pth_path = Cfg.pth_path
if Cfg.valid_mode:
valid([50], classes={0: 'car', 1: 'pedestrian'}, draw=Cfg.draw_box, anchors=anchors)
else:
train(cur_epoch, total_epoch, cuda=True, anchors=anchors)