Blind Image Super-Resolution: A Survey and Beyond
文章目录
-
- 6 EXPLICIT DEGRADATION MODELLING
-
- 6.1 Classical Degradation Model with External Dataset
-
- 6.1.1 Image-Specific Adaptation without Kernel Estimation
- 6.1.2 Image-Specific Adaptation with Kernel Estimation
- 6.2 Single Image Modelling with Internal Statistics
- 7 IMPLICIT DEGRADATION MODELLING
-
- 7.1 Learning Data Distribution within External Dataset
- 7.2 Implicit Modelling with a Single Image: a Future Direction

我们的贡献主要有三个方面:
1)我们提出了一个关于盲图像超分辨率最新进展的系统调查,包括不同方法的改进和局限性
2)我们提出了一种分类法,以有效地对现有方法进行分类并揭示一些研究差距
3)我们提供对当前研究状态和未来前景的深刻见解。
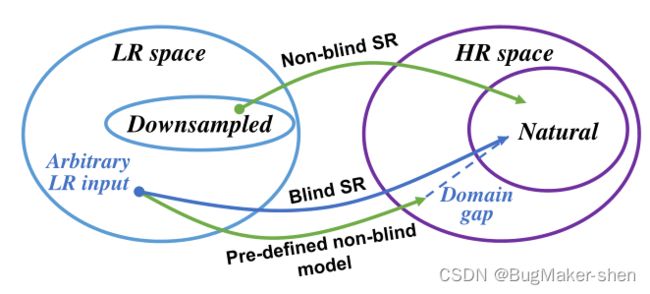
非盲和盲超分之间的域差异。SR结果与所需的高质量HR之间存在较大的域差距,这是由于将预训练的非盲模型应用于LR输入,而退化偏离了预定的方式
从HR到LR的潜在降解过程通常可以建模为 y = f ( x ; s ) y=f(x;s) y=f(x;s)
x表示HR,y表示LR,s表示退化倍数,而SR问题等价于求 f − 1 f^{-1} f−1,在non-blind场景下, f f f通常为bicubic
结合模糊核和加性噪声后,退化可以建模为 y = ( x ⊗ k g ) ↓ s + n y=(x\otimes k_g)\downarrow_s+n y=(x⊗kg)↓s+n
下图展示了用不同模糊核和噪声退化的图像

还可以建模为包含更复杂的JPEG压缩形式: y = ( ( x ⊗ k g ) ↓ s + n ) J P E G q y=((x\otimes k_g)\downarrow_s+n)_{JPEG_q} y=((x⊗kg)↓s+n)JPEGq
另一组方法利用来自经典退化模型的单个图像的内部统计信息,不需要外部数据集进行训练,如ZSSR和DGDML-SR。事实上,内部统计信息只反映了图像patch重复特性

现实世界的退化通常过于复杂,无法用多种退化类型的明确组合进行显式建模,有很多工作绕过显式建模,进行隐式建模。隐式建模方法通过数据分布简单地定义退化过程,需要外部数据集进行训练
通常,这些方法利用GAN来掌握训练数据集中的退化模型,如CinCGAN和FSSR
显式建模基于经典退化算法或其变体,基本思想是学习一个 SR 模型,其中包含涵盖大量退化的外部训练数据,这些退化通常使用模糊核k和噪声n进行参数化。代表性方法包括SRMD、IKC和KMSR。另一组方法利用patch内重复的统计信息,如KernelGAN和ZSSR,它们可以直接在单个输入图像上工作。这种建模主要基于经典的退化模型。
另一方面,具有隐式建模的方法不依赖于任何显式参数化,它们通常通过外部数据集中的数据分布隐式学习底层SR模型。这些方法包括CinCGAN和FSSR
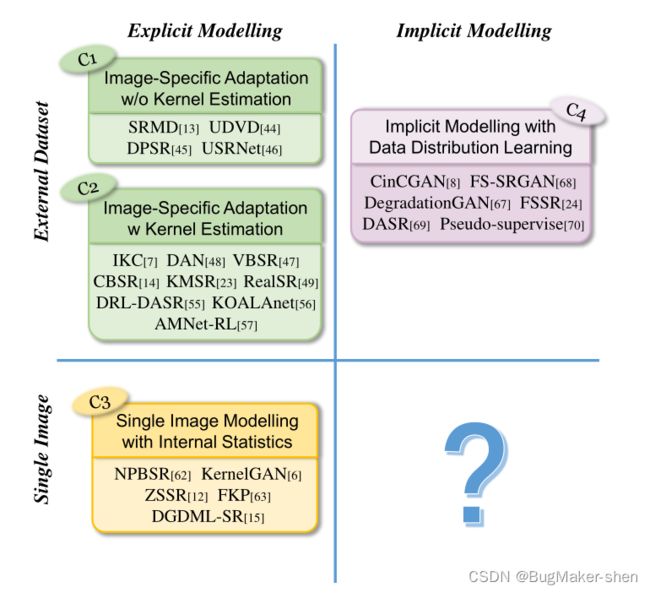
我们采用这种分类的原因有三个方面:首先,区分显式和隐式建模有助于我们理解某种方法的假设,即这种方法旨在处理什么样的退化;第二,无论是使用外部数据集还是单个输入图像,都表明对不同的图像采用使用不同的显式建模策略;最后,在将现有方法归类到这些类别之后,剩下的一个研究缺口自然显露出来——使用单个图像的隐式建模
非盲超分大致流程:

SISR任务中常用的CNN框架包括三个主要模块:将输入LR图像转换为特征映射的浅层特征、基于浅层特征提取深度特征,以及最终的SR输出重建
近年来,在深度特征提取和SR重建模块上有许多改进,例如引入了残差块,递归或递归结构,注意机制,亚像素卷积等。此外,还提出了多个损失函数,以提高SR结果的感知质量,双三次下采样假设的非盲SISR实际上已经成熟。
非盲模型通常难以推广到偏离其假设退化的输入图像,非盲SR网络的一些问题如下所示

基于bicubic训练的SRResNet在输入bicubic输入上表现良好,但不能处理blur和noise的输入图像
6 EXPLICIT DEGRADATION MODELLING
6.1 Classical Degradation Model with External Dataset
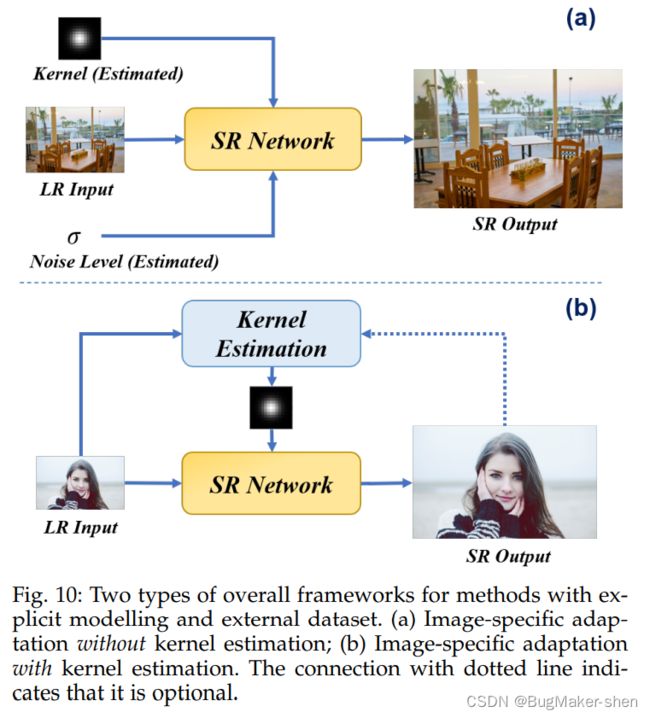
6.1.1 Image-Specific Adaptation without Kernel Estimation
SRMD模型(Super-resolution for multiple degradations)建议将LR输入图像与其退化map直接连接起来,作为SR模型的统一输入

这个kernel哪来的??????
虽然SRMD将SR模型的泛化能力扩展到了各种SR核和噪声水平,但它的范围仍然非常有限,因为有效地编码任意核并用单个模型处理它通常是繁琐的,尤其是对于那些具有运动模糊等不规则模式的核。因此,提出了另一种方法,该方法不需要核编码来生成退化map。具体而言,DPSR将SR网络合并到基于map的迭代优化方案中
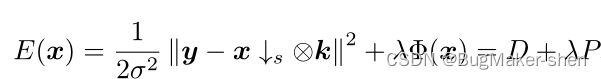
y = ( x ⊗ k g ) ↓ s + n y=(x\otimes k_g)\downarrow_s+n y=(x⊗kg)↓s+n
上述 E ( x ) E(x) E(x)所示的目标函数可以使用半二次分割(HQS)算法分为两个子问题:一个解决去模糊任务,并与参数K的数据项D相关,另一个旨在解析与P相关的,具有一些虚拟噪声级 µ µ µ的双三次降采样图像。幸运的是,第一个子问题可以用快速傅立叶变换以闭合形式求解,无需任何核编码,从而使模型能够处理更复杂的核
此外,由于模糊和下采样操作的解耦,第二个子问题可以由一个能够处理加性噪声的非盲SR网络来建模,并且该网络可以直接从SRMD框架进行调整,使用单个噪声映射作为附加输入
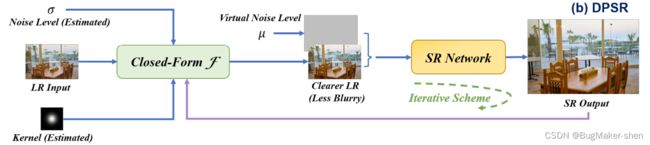
USRNet也采用MAP框架,相应的两个子问题是超分由k模糊的LR图像和对具有虚拟噪声µ的HR图像进行去噪。它将DPSR的迭代优化过程展开为具有迭代方案的端到端可训练网络,从而增强了解决方案框架,实现两个子问题之间的联合优化

上述方法有一个明显的缺点:它们都依赖于退化kernel map的额外输入。然而,从任意LR图像中估计正确的kernel并非易事,不准确的估计输入将导致内核不匹配,并严重破坏SR性能。下图显示了SRMD方法的正确和错误核的SR结果之间的比较

因此,只有可靠退化估计的方法,才能快速获得令人满意的SR输出,否则可能会陷入手动选择适当估计输入以获得更好结果的繁琐工作。因此,我们将在下一部分介绍另一种方法,即将核估计纳入SR框架以获得更稳健的性能
6.1.2 Image-Specific Adaptation with Kernel Estimation
迭代核校正(IKC)提出以迭代的方式校正模糊核,以逐渐接近令人满意的结果。这种方法的重点是利用中间的SR结果,因为由核不匹配引起的SR图像中的伪影往往具有规则的模式
使用更新后的核生成新的SR结果,从而减少伪影。SR网络在每个残差块中包括空间特征变换层,当前核用于生成用于特征自适应的变换参数,这可能比SRMD提出的直接串联输入更有效
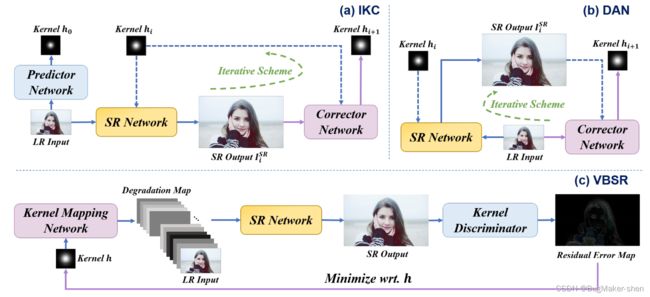
DAN进一步增强了IKC框架。它将校正器和SR网络统一为端到端的可训练网络,而不是像IKC那样单独训练每个子网络。这种联合训练策略可以使两个网络更加兼容
VBSR也利用SR伪影进行核估计,但它训练Kernel Discriminator来估计SR输出的误差图,而不是核本身,并通过在推理阶段最小化SR输出的误差来找到最佳核
IKC和DAN采用的迭代方案可以从域自适应的角度进行很好的解释:在从输入LR到目标HR domain的过程中,它选择了几个中间SR结果作为交换站,没有像SRMD那样在一次就产生最终的SR输出,而逐步穿过域间隙。提高核估计输入的准确性,这两种方法比SRMD框架具有更高的鲁棒性
然而,这种迭代方案通常会消耗更多的推理时间。为了解决这个问题,最近的一些工作通过引入更精确的退化估计或更有效的特征适应策略,提出了非迭代框架。盲SR的无监督退化表示学习DRLDASR尝试在潜在特征空间中使用可训练的编码器来估计退化信息,并以无监督的方式使用对比学习来训练退化编码器。具体来说,与query输入具有相同退化的LR样本被视为正样本,而具有不同退化的LR样本被视为负样本

面向核的自适应局部调整(KOALAnet)还利用了类似的动态核策略,使SR网络适应特定的退化,并进一步将非迭代框架扩展到空间变化退化,使用降采样网络进行局部核估计
另一项工作,带强化学习的自适应调制网络AMNet RL,提出了一种改进的自适应实例范数AdaIN,以将核估计纳入SR网络,并且它还率先在强化学习框架下使用可微感知度量(如NIQE)优化盲SR模型
通常,在训练过程中,SR模型将隐含地被赋予更多的核估计能力,从而避免了框架中的显式核估计。然而,这种直接方式可能不会带来最佳性能。RealSR和RealSRGAN中采用了类似的策略,以构建具有多种真实内核的通用训练集,该过程如下图所示

与没有核估计的方法相比,这些方法实际上省去了我们寻找核估计算法,尤其是在推理阶段,并且表现出了令人印象深刻的性能。然而,核估计仍然无法避免显式建模的固有缺点:对于模型未见过的退化图像,无法给出令人满意的结果。
这个限制对于复杂的真实图像来说实在太难了。即使我们愿意用更多退化类型的LR训练模型,我们也收集足够的外部训练数据
6.2 Single Image Modelling with Internal Statistics
单幅图像的SR建模基于自然图像的内部统计信息:单幅图像的patch往往会在该图像的不同尺度内重复出现。对于许多自然图像,内部统计量已被量化,并被证明比外部统计量具有更强的预测能力

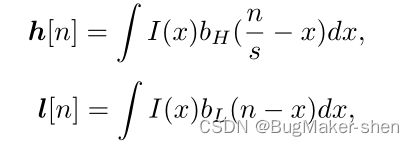
h h h和 l l l表示用同一个相机拍摄的HR和LR, I ( x ) I(x) I(x)是图像, b H b_H bH和 b L b_L bL是光学变焦系数

h h h和 l l l之间的关系为:
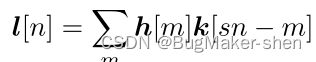
对于给定的LR图像,让q和r在连续场景中使用两个局部patch,其中r大于q,那么就会有
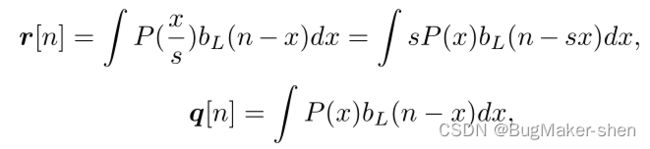

这意味着同一LR的q和r之间的关系相当于由kernel关联的HR及其LR版本的两个patch,此属性可用于估计和求解未知HR
局限性: 使用内部统计信息进行自监督对于解决具有不同退化类型的LR的SR图像似乎有用,因为它不需要大量外部训练数据集。但是图像内部纹理并不重复时,就很难进行SR
到目前为止,我们已经对显式退化建模方法及其优缺点进行了概述。显式建模清晰而直接,但除了模糊和加性噪声外,可能无法建模更复杂的退化。事实上,现实世界中的图像通常包含多次退化,我们很难用明确定义的函数来建模。
因此,另一组方法建议通过数据分布学习隐式建模退化。据我们所知,到目前为止,只有基于外部数据集的方法用于隐式建模,我们将在下一节中讨论它们
7 IMPLICIT DEGRADATION MODELLING
7.1 Learning Data Distribution within External Dataset
这种方法的目的是通过学习外部数据集,隐式地掌握潜在的退化模型。对于具有成对HR-LR图像的数据集,监督学习和SR网络已经足以实现令人满意的结果,就像NTIRE 2018和AIM 2020挑战中提出的解决方案一样
一个更困难的场景是使用不配对数据进行学习,其中具有真实退化的LR图像对应的GT不可用。现有方法通常利用GAN学习数据分布,使用一个或多个Discriminator来区分生成的图像和真实的图像,从而将生成器学习到合适的建模方向。在大多数情况下,使用两个数据集来训练模型,包括HR和不配对LR,可以将这两个数据集视为代表目标域和源域,以学习域适应

CinCGAN是使用未配对数据进行隐式建模的最早尝试之一,在SR之前先将输入的未知退化的LR转换到bicubic的domain,bicubic domain同时也是clean domain,因为通过HR双三次下采样得到的LR没有噪声
在训练期间不需要配对的数据,从而形成无监督的训练方案。然而,无监督的域适应并非容易,因为由鉴别器通常很难分离正确的目标域

利用GAN进行监督学习和数据分布学习,一些方法侧重于学习从HR到LR的退化过程,并使用生成的接近于真实退化的LR成对地训练SR模型
在该模型中,有HR->LR的退化网络和LR->SR的超分网络,SR网络主要使用像素级损失进行监督
FSSR和FS-SRGAN都属于这种使用未配对数据进行训练的网络,这两种方法都只对高频纹理做对抗性损失,以降低使用对抗性训练的难度。此外,FS-SRGAN在生成LR的过程中引入了color attention模块,以缓解域适应过程中的颜色偏移问题
然而,上述方法都和GAN相关。生成的LR可能与real LR存在较大的域间隙,从而影响SR性能。为了解决这个问题,DASR(Y. Wei)提出了一种域间隙感知训练策略,其中生成的LR和数据集中的real LR都用于训练SR模型

还采用了另一种称为域距离加权监督的策略,根据LR输入到real LR的域距离,为LR输入分配不同的损失权重,有助于减少产生的远距离LR造成的负面影响。具体而言,LR Discriminator的预测用于定量测量每个LR的域距离
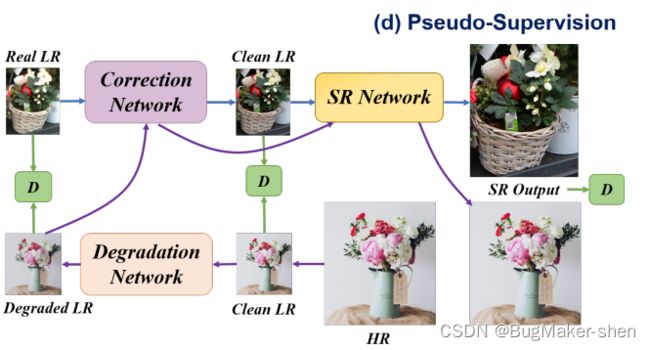
另一项工作是伪监督(pseudo supervision),它将CinCGAN结构中的前向SR过程与退化过程相结合,以处理域间隙引起的问题。这种方法保留了CinCGAN中LR到SR的路径,并添加了一条用伪对监督的路径
这条受监督的路径从HR开始到退化的LR,然后跨中间层LR domain返回到HR。如果将具有真实LR的CinCGAN路径视为真实LR图像的附加路径,则该思想实际上与DASR中的域间隙感知训练有点相似
局限性: 虽然这种方法看似灵活且强大,但对于盲SR来说,还远不能包治百病。一方面,这些方法必须依靠大量外部数据集通过隐式数据分布来训练,但这种需要大量数据的方式不适合某些任务,包括旧照片恢复。另一方面,他们大多利用GAN框架进行无监督的数据分布学习。基于GAN的框架可能很难训练,并且在SR结果中经常会产生严重的伪影。这些伪影对许多实际应用有害,例如高清显示和旧照片/胶片恢复
7.2 Implicit Modelling with a Single Image: a Future Direction
只要提供源LR和目标HR数据集,隐式建模的想法似乎有希望处理复杂的真实世界退化。然而,由于现有的方法主要依赖于GAN框架进行数据分布学习,并且GAN产生的伪影对许多实际应用都是有害的,因此还有很长的路要走。除了探索更稳健的生成模型外,另一个方向也值得注意,这是迄今为止从未提出过的:使用单个LR图像进行隐式建模。
如前几节所述,现有的方法都有其局限性,尤其是对于具有复杂现实世界退化的内部统计数据的异常值。此类示例包括监控视频、旧照片和乳胶类文件等,这些图像在我们的日常生活中很常见,它们对现有的方法提出了巨大的挑战:它们不仅缺乏跨尺度的斑块冗余,无法进行显式建模,而且由于不可预测退化的复杂性,无法被少数外部数据集覆盖。我们认为,这一研究空白可以通过基于单输入图像隐式建模的方法来填补。到目前为止,在这一领域还没有相关的工作,但我们相信这是一个值得研究的方向
这方面的主要困难在于缺乏有效的SR先验知识,一种可能的解决方案是将人为干预作为附加信息。这些建议的关键是增加有用信息的数量,使盲SR成为可能