【图像超分辨率】Unpaired Image Super-Resolution using Pseudo-Supervision 阅读笔记 #blind SR
发表在CVPR2020。

Paper:Unpaired Image Super-Resolution using Pseudo-Supervision
Abstract
在大多数基于学习的图像超分辨率(SR)研究中,成对的训练数据集(LR-HR)是用预定操作(例如双三次插值)将高分辨率(HR)图像按比例缩小而创建的。
但是,这些方法无法处理现实世界中的低分辨率(LR)图像,因为这些图像的降质过程更加复杂且未知。(不像bicubic那么简单)
本文提出了一种使用生成对抗网络的unpaired SR方法,该方法不需要成对的训练数据集。
网络由unpaired kernel/noise correction network和pseudo-paired SR network组成。
校正网络去除噪声并调整输入的LR图像的内核。然后,通过SR网络将校正后的clean LR图像放大。在训练阶段,校正网络还从输入的HR图像生成pseudo-clean LR image,然后SR网络以配对的方式学习从pseudo-clean LR image到inputted HR image的映射。
由于我们的SR网络独立于校正网络,因此可以将现有网络体系结构和pixel-wise loss functions与所提出的框架集成在一起。对各种数据集进行的实验表明,该方法优于现有的基于unpaired的SR解决方案。
Introduction
However, in many studies, training image pairs are generated by a pre- determined downscaling operation (e.g., bicubic) on the HR images. This method of dataset preparation is not practical in real-world scenarios because there is usually no HR image corresponding to the given LR one.
然而,在许多研究中,训练图像对(HR-LR)是通过对HR图像进行预定的缩小操作(例如,双三次采样bicubic)来生成的。 这种数据集准备方法在实际场景中不切实际,因为通常没有与给定LR相对应的HR图像。
最近的一些研究提出了克服HR-LR图像对不存在的方法,例如blind SR方法和基于生成对抗网络(GAN)的unpaired SR方法。Blind SR旨在从被任意内核降级的LR图像中重建HR图像。 尽管最近的研究已经对有限形式的退化(例如模糊)实现了“blindness”,但实际的LR图像并不总是以这种退化来表示。
因此,它们在因预期不到的处理而退化的图像上表现不佳。
相比之下,基于GAN的unpaired SR方法可以直接学习从LR到HR图像的映射,而无需假设任何降质过程。
GAN通过生成器和判别器之间的极小极大博弈来学习生成与目标域具有相同分布的图像。 基于GAN的不成对SR方法可以根据它们是从LR图像还是HR图像开始进行粗略分类。
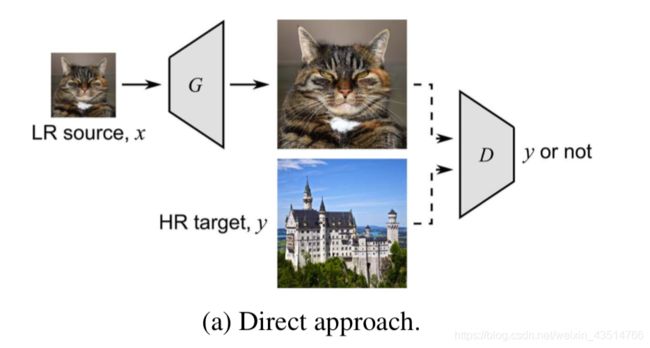
- Direct approach
在这种方法中,生成器放大原始LR图像以欺骗HR判别器。
这种方法的主要缺点是不能使用像素级损失函数来训练生成器。 在成对的SR方法中,重建图像SR和目标图像HR之间的像素级损失不仅在distortion-oriented的方法中而且在perception-oriented的方法中都起着至关重要的作用。
- Indirect approach
在这种方法中,生成器按比例缩小源HR图像,以欺骗LR判别器。 然后将生成的LR图像用于成对训练SR网络。 这种方法的主要缺点是,生成的LR分布与真实LR分布之间的偏差会导致训练与测试的差异,从而降低测试性能。

- Our approach
文章的主要贡献是:通过将整个网络分为 unpaired kernel/noise correction network 和pseudo-paired SR network,我们同时克服了上述两种方法的缺点。
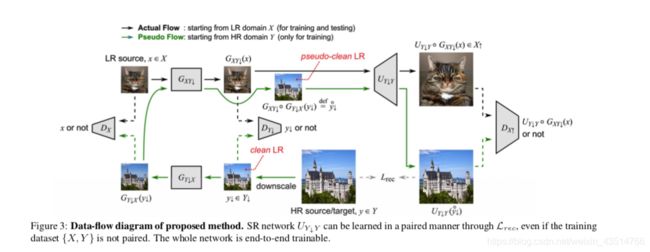
The correction network is a Cycle- GAN-based unpaired LR ↔ clean LR translation.
correction network:unpaired LR到clean LR的转换。
The SR network is a paired clean LR → HR mapping, where the clean LR images are created by downscaling the HR images with a predetermined operation.
SR network:clean LR到HR的映射。
In the training phase, the correction network also generates pseudo-clean LR images by first mapping the clean LR images to the true LR domain and then pulling them back to the clean LR domain.
在训练阶段,校正网络还通过首先将clean LR图像映射到真实LR域,然后将它们拉回到clean LR域,来生成pseudo clean图像。
The SR network is learned to reconstruct the original HR images from the pseudo-clean LR images in a paired manner. SR网络学习以配对方式从pseudo clean LR图像重建原始HR图像。
Related Work
训练数据,网络架构和目标函数是深度网络训练的三个基本要素。
配对图像SR旨在优化网络架构和/或目标函数,以在存在理想训练数据的假设下提高性能。 但是,在许多实际情况下,训练数据(即与源LR图像相对应的目标HR图像)是缺失的。 最近关于blind和unpaired图像SR的研究着重关注了这个问题。 另一种方法,最近的一些work使用专门的硬件和数据校正过程构建了真正成对的SR数据集,这些过程很难scale。
Paired Image Super-Resolution 成对图像超分辨率
比如SRGAN、SRCNN、LapSRN等,这些方法都使用了成对的LR-HR数据集来训练神经网络。
Blind Image Super-Resolution 盲图像超分辨率
尽管盲图像SR在实际应用中具有重要意义,但对其的研究相对较少。
对盲态SR的研究通常集中在仅对模糊内核不敏感的模型上。 例如,ZSSR 利用单个图像内部的信息重复性来放大具有不同模糊内核的图像,而IKC使用中间输出来迭代地校正模糊内核的不匹配。
Unpaired Image Super-Resolution 不成对图像超分辨率
…
Proposed Method

做了几张图简单展示一下:
总体结构:

损失函数:




损失函数有点复杂呢!
Network Architecture 网络结构
GXY↓ and UY↓Y
基于RCAN结构,做了一些简化,并且去除了最后的上采样层。
GY↓ X
we use several residual blocks with 5 × 5 filters and several fusion layers with 1 × 1 filters, where each convolution layer is followed by batch normalization (BN) [16] and LeakyReLU. The two head modules, including the one residual block, independently extract the features of an inputted RGB image and single- channel random noise N (0, 1) that simulates the random- ness of distortions. Then, the two extracted features are concatenated to be inputted to a main module consisting of six residual blocks and three fusion layers.
DX , DY↓ and DX↑
We use PatchGAN for all the discriminators.
Experiments
DIV2K realistic-wild dataset
我们使用了NTIRE 2018 Super-Resolution Challenge的realistic-wild set (Track 4),realistic-wild set是通过对DIV2K进行降级生成的,DIV2K具有800张训练图像,realistic-wild set通过×4缩小比例,运动模糊,像素移位和噪声添加来模拟真实的“野生” LR图像。
我们使用上面的3200张LR和800张HR配对图像训练了我们的模型,但是使用了“unpaired/unaligned”采样,我们在100张真实野生的验证图像上评估了结果,因为没有提供测试图像的ground truth。
Hyperparameters
λcyc=1
λidt=1
λgeo=1
γ=0.1
SR factor was ×4.
Intermediate images

Comparison with state-of-the-art blind methods


后面还有一些ablation study以及其他的补充实验,感兴趣的可以去看看~
内容很丰富的一篇文章。