Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation 论文理解
论文markdown
目标:论文理解
论文序列
2)Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation
目标:单目相机的rgb图->单目相机的深度图

之前写阅读Depth Map Prediction from a Single Image using a Multi-Scale Deep Network 论文的感想,因为网络架构比较简单,直接将global network 的最后输出直接和refined network 进行concatenate。从另一层面上说这是非常简单粗暴的进行融合global 信息和local 信息。后续的研究在融合global network 和 refine network这一块有很多成果。这是在网络架构上的改进。
Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation 是典型的在这方面的改进。下面解释一下,这条研究线上的进行改进后的网络架构,为什么这样改进会有效果,以及改进后的对比,改进网络后loss函数是否需要改变(因为需求)。
网络的设计的方法:
方法也是拥有global network, refined network。但是这些两个网络架构可以合并,输入都是用同一的rgb图像。只需要将前面的网络层和后面的网络层进行concatenate一下。这个类似于U-net的一层相连。
如下图

上图的网络架构就是将网络中的多个layers输出的features maps fuse 在一起。这个比之前的要复杂一下,多层次的特征图fuse在一起,可以有效的保持局部特征和全局特征的稳定。但是也是简单的采样然后fuse的。
而本篇介绍的论文就是将网络层的多层输出的feature map 进行(fuse)。本篇论文对于融合各个层次的,加入了CRF这个概念,然后如上进行多层次融合。整体的架构如下:
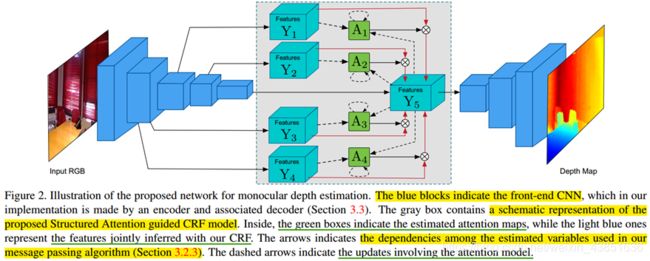
网络架构方法: CNN front network和CRF model的两大模块
网络做了哪些改进?为什么这样改进网络结构效果会比较好?
相对之前的网络,这篇论文对于融合各个层次的feature maps 用了一个CRF model(也就是灰色的框框表示的网络架构单元)。在灰色框框里面可以看到对于各个层次的网络输出feature map 生成对应的estimated attention maps?利用这个estimated attentions maps 去融合原来的特征。加入这个estimated attention maps以及融合这个estimated attention maps称为CRF model融合。细分了这些网络改进。
现在解释为啥这些改进能够让效果更好?
网络中可以看到网络生成的各个层次的特征,满足CRF model 模型,不单单是简单的融合。融合的方式是,让各个层次的feature map 和 最后一个层次的feature map 添加后验的关系。这样的融合,可以看到前几层的 S − 1 S-1 S−1 层次feature map的信息都加入到最后的一层的 S S S 层的feature maps 中,减少信息在卷积中的丢失。各个层次之间特征怎么融合,因为是不同层次之间的resolution 不同,需要downsample 和upsample称为同样大小的feature map。这些同样resolution的feature maps 之间对应关系用CRF model 来建立。具体这样建立方式比较好,我还没有看懂,需要查看论文: Multi-Scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation 它应该给出了用CRFs相对于简单的fuse 各个层次feature maps有更多的好处,但是没有看这篇论文,所以我不是特别明白这样做的优势表现在哪里。而我阅读的这篇论文的主要贡献点在于它的attentions maps 的生成。它主要是用途是对于 S − 1 S-1 S−1 层的feature maps和最后一 S S S层的feature map进行attention maps。用于控制从 S − 1 S-1 S−1 层的feature map 到 S S S 层的feature map 的信息流向。attention maps 模型使得网络可以自动规范不同scale特征信息(feature map)的权重, 学习得到不同scale 的feature maps权重表明不同scale 的feature map 对最后的信息融合的贡献是不同的,需要从数据中获取这个规律。(符合人的认知。)。 这个流向可能是用于控制有些噪声融入,防止最后融合的feature maps太多噪声。 影响最后decode的结果,同时这个attention maps的参数是可以学习,用于选择最适合的从其他层信息流向最后一层信息的方式。
控制其它层次的feature maps 信息流向最后一层feature maps 有好处,attentions maps 网络怎么做到的?
查看了一下灰色框框的网络设计:

为了简单解释,可以放弃各个feature maps的融合,可以看到网络设计,都是由 Y 1 Y_1 Y1 和 A 1 A_1 A1 以及最后融合的 Y 5 Y_5 Y5 等等组成。同时可以看到 Y 5 Y_5 Y5 有一个虚线返回,可以看到用于更新 A 1 A_1 A1 中的值,它是一组binary vector {0,1}值组成。它和 Y 1 Y_1 Y1 组合。可以控制 Y 1 Y_1 Y1 的值融合到最后的 Y 5 Y_5 Y5中。下面给出数学解释的model。有三个部分组成。
E ( Y , A ) = Φ ( Y , X ) + Ξ ( Y , A ) + Ψ ( A ) (1) E(Y,A)=\Phi(Y,X)+\Xi(Y,A)+\Psi(A) \tag{1} E(Y,A)=Φ(Y,X)+Ξ(Y,A)+Ψ(A)(1)
这个优化主要是计算Y,A两个参数,同时X是我们提取的各个层次的网络层的feature map。可以看到其中 attention maps 是 Ξ ( Y , A ) \Xi(Y,A) Ξ(Y,A)。简单介绍一下它们的构成。
Φ ( Y , X ) = ∑ s = 1 S ∑ i ϕ ( y s i , x s i ) = − ∑ s − 1 S ∑ i 1 2 ∣ ∣ y s i − x s i ∣ ∣ 2 (2) \Phi(Y,X) = \sum_{s=1}^S\sum_i\phi(y_s^i,x_s^i)=-\sum_{s-1}^S\sum_i\frac{1}{2}||y_s^i-x_s^i||^2 \tag{2} Φ(Y,X)=s=1∑Si∑ϕ(ysi,xsi)=−s−1∑Si∑21∣∣ysi−xsi∣∣2(2)
从式子(2)可以看出其中生成Y的特征表示,是从X中得到,让X逼近Y。本质上是高斯分布的逼近(大数据训练?)。
Ξ ( Y , A ) = ∑ s ≠ S ∑ i , j ξ ( a s i , y s i , y S j ) (3) \Xi(Y,A)=\sum_{s\neq S}\sum_{i,j}\xi(a_s^i, y_s^i, y_S^j) \tag{3} Ξ(Y,A)=s=S∑i,j∑ξ(asi,ysi,ySj)(3)
ξ ( a s i , y s i , y S j ) = a s i ξ y ( y s i , y S j ) = a s i y s i K i , j s y S j (4) \xi(a_s^i, y_s^i, y_S^j) = a_s^i \xi_y(y_s^i,y_S^j)=a_s^iy_s^iK_{i,j}^sy_S^j \tag{4} ξ(asi,ysi,ySj)=asiξy(ysi,ySj)=asiysiKi,jsySj(4)
从(3)(4)式子可以看到对于这个函数它对应的各个i,j都是特征图的下标,它们都是在全局影响,全连接?这是影响了从s层到S层中的信息流向,它由 a s i a_s^i asi 控制的。其中 K i , j s ∈ R C s × C S K_{i,j}^s \in R^{C_s \times C_S} Ki,js∈RCs×CS ,它表示一系列操作。后续实验给了计算 a s i a_s^i asi 的方法。
最后的一个公式:
Ψ ( A ) = ∑ s ≠ S ∑ i , j ψ ( a s i , a s j ) = ∑ s ≠ S ∑ i , j β i , j s a s i a s j (5) \Psi(A) = \sum_{s\neq S}\sum_{i,j}\psi(a_s^i,a_s^j)=\sum_{s \neq S}\sum_{i,j}\beta_{i,j}^sa_s^ia_s^j \tag{5} Ψ(A)=s=S∑i,j∑ψ(asi,asj)=s=S∑i,j∑βi,jsasiasj(5)
这是用于控制attention maps的约束,表示同样的scale中,相关联的像素具有相似的值。表示在同scale里面的像素具有最好相似的attention maps的值。
因为上述的CRF model 融合,加入了attention maps
的融合,它能很好的融合各个网络层的feature maps.
感想:
1)论文中关于CRF中model的融合,为啥有好处,暂且还没有理解,因为本论文暂且没有提,只是知道它能更好的保证信息不丢失?具体为啥暂且不懂。需要看专门加入这个crf model 的论文。
2)论文中的网络设计是增加了attention maps机制,从而提升了网络的性能。但是网络中的这些信息,只是在encode最后一层使用了这个attention maps机制,同时decode和encode没有额外的链接传递信息。这些为啥不能那样去做,暂且还没有明白。
没有完全理解,所以明天继续补充和修改。