GAN(生成对抗网络)在合成时间序列数据中的应用
GAN(生成对抗网络)在合成时间序列数据中的应用
(本文基本是对Jansen 的《Machine Learning for Algorithmic Trading》第二版的第21章进行翻译、学习和梳理,此项为课程作业,以此形式进行记录和自我学习)
利用GAN生成合成时间序列数据,所面临的挑战要大于利用GAN生成合成图片。除了要学习每个给定点分布(如某个时间戳上股票价格的分布),GAN还需要学习时间动力学——这种动力学是两个序列相关性背后的驱动力。
Yoon等人在2019年12月介绍了一种新颖的时间序列生成对抗网络(TimeGAN)框架,这种框架同时结合了监督学习和无监督学习,以解释时间上的相关性。这个模型在学习时间序列的内在空间(a time-series embedding space)时,同时对监督学习和对抗训练这两个目标进行优化。这能够使模型能够在对历史数据采样的同时,也能观测到其中的动力学(dynamics observed)。模型的作者将许多时间序列(如股票价格)用于测试模型,结果发现合成数据的质量要好于许多其他的数据。
本文在于展示TimeGAN的工作方式以及关键的实施步骤。
1. TimeGAN文章的摘要与介绍
在Yoon等人的研究发表之前,将GAN作为生成序列数据的方法的研究,都没有对“时间上的动力学”(temporal dynamics,即序列的自相关性)给予足够的重视,而一般的作为解决预测问题的监督学习算法,则天然具有确定性(inherently deterministic)。因此对两种框架取其精华弃其糟粕,则是Yoon等人创新的地方。在文章中,Yoon等人结合了非监督学习的范式灵活的特点和监督学习对于训练过程控制力强的性质,让TimeGAN模型能够把“时间上的动力学”考虑进模型中。
具体而言,序列相关性作为时间序列数据的一种内在性质,对以生成时间序列为目的生成模型提出了一个很大的挑战。一个好的生成模型不仅应该学习到每个时间戳上的特征分布(distributiions of features within each time point),而且还应该学习到不同时点之间变量间的潜在复杂关系(potentially complex dynamics of those variables across time)。用数学的语言表达,就是说如果现在需要对一个序列数据 X 1 : T = ( X 1 , ⋯ , X T ) \textbf{X}_{1:T} = (\textbf{X}_1,\cdots,\textbf{X}_T) X1:T=(X1,⋯,XT)进行建模,那么我们希望模型能够准确地学习到 p ( X t ∣ X 1 : t − 1 ) p(\textbf{X}_t|\textbf{X}_{1:t-1}) p(Xt∣X1:t−1)这一条件分布,而且随着时间的流逝,模型也应该保持优秀的学习能力。
一方面,有大量的工作专注于使用自回归模型去拟合“时间上的动力学”。虽说自回归模型明确地将序列的分布划入了条件分布的乘积( ∏ t p ( X t ∣ X 1 : T ) \prod_tp(X_t|X_{1:T}) ∏tp(Xt∣X1:T))中,而且在解决预测问题上,自相关模型也算有用。但是,归根到底,自相关模型是天然确定性(fundamentally deterministic)的,而且自相关模型并不具备生成性,因为自相关模型的输入是有条件的,它的输入必须是有意义的真实数据。而一个好的生成模型,必须要能够做到自己动手丰衣足食,即使输入是随机噪声,生成模型也能够生成高质量的合成数据。
另一方面,许多研究致力于将GAN的框架直接用于序列数据的生成,这些研究的想法多是以RGANs作为生成器和判别器。然而,这些GAN的对抗训练,仅仅在于直接对 p ( X 1 : T ) p(\textbf{X}_{1:T}) p(X1:T)建模,而不考虑“时间上的动力学”。总之,RGANs的做法是每个时点的特征分布建模,相应的,其loss也仅仅是简单的将每个时点的loss相加,这种训练方法是不足以捕获序列相关性的。
在文章中,Yoon等人结合了上述两条技术路线的优点,并在此基础上提出了一个包含“时间上的动力学”的生成模型——TimeGAN。这个模型的特点:
- 除了基于真实和合成数据的无监督学习的对抗loss之外,作者引入了步进的(stepwise)、基于真实数据的监督学习的loss,因此模型捕获“时间上的动力学”的这一目标便变得十分明确。因为真实数据的信息是1+1>2的效果,整个数据序列所具有的信息要比单个数据具有的信息之和更大,使用基于真实数据的loss能够有效利用潜藏于真实数据序列下的信息。
- 这个模型引入了一个“内在网络”(embedding network)以提供特征(features)和潜在模式(latent representations)之间的可逆映射,这使得对抗训练需要学习的参数空间的维度得到削减(降维处理)。这个降维的思路来自于这个事实——尽管系统,也就是时间戳上单个特征的分布,可能是十分复杂的,但序列相关性的复杂程度可能远远低于系统的复杂程度(原文为“‘时间上的动力学’背后的驱动因子的空间维度可能并不高”)。而模型中监督学习的loss最小化是同时基于内在网络和生成网络的训练的,因此隐藏空间(latent space)的任务就不仅仅是提升参数的有效性,它同时也肩负着督促生成器学习序列相关性这一使命。
在定性上,这一模型利用t-SNE和PCA分析,将生成数据对原始数据分布的模拟程度进行可视化,用以在定性上评价模型的好坏。在定量上,作者利用post-hoc(事后检验)对合成数据和真实数据进行区分以验证模型好坏。文章的最后,作者还用利用TSTR(train on synthetic,test on real)的框架,用以评价生成数据的质量。结论是,TimeGAN在生成时间序列数据这一领域达到了顶级水平。
2. 让模型学习如何通过特征和时间生成数据
2.1 TIMEGAN的结构
TimeGAN的关键组成部分是生成器和内在网络,两者都直接关系到loss的最小化过程。而loss则用以衡量模型在学习动力学关系上达到了多“好”的程度。因此,模型会以促进生成器学习序列相关性为条件去学习潜在空间(latent space,也就是真实数据背后的驱动力)。
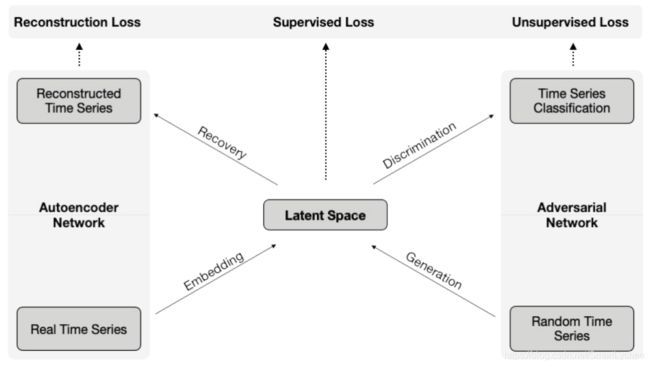
上图阐明了TimeGAN的两个网络及其所包含的四个部分
- 自编码器:含有内在和复现网络(embedding and recovery networks)
- 对抗网络:包含序列生成器和序列判别器
TimeGAN的训练是独特的,因为它是一种联合训练,即依靠三个不同的loss function对自编码器和对抗网络进行训练。Reconstruction Loss用于自编码器参数的优化,Unsupervised Loss用于对抗网络参数的优化,而Supervised Loss则是针对于生成器对“时间动力学”的学习。具体来说,自编码器的embedding network致力于创造出潜在空间,而对抗网络则在潜在空间里进行操作,最后Supervised Loss则要让合成数据的“时间上的动力学”尽可能地向真实数据的“时间上的动力学”靠拢。
自编码器实现的是特征空间和潜在空间之间的可逆映射,它的作用就是让对抗网络能够在更小维度的空间中学习“时间上的动力学”。
而TimeGAN中对抗网络不同于DCGANs的地方有两个
- TimeGAN的对抗网络所需要生成的是时间序列数据,而不是图片。
- 对抗网络要学习的对象——潜在空间不是静止的,而是随着学习过程动态变化的,因为潜在空间是由自编码器的内在网络生成的,随着合成序列的生成,自编码器也在学习,故它所创造的潜在空间也会变化。
2.2 自编码器和对抗网络的联合训练
具体来说,三个loss的具体工作是
- Reconstruction Loss是自编码器的Loss,我们知道,自编码器是对输入数据进行表示学习(representation learning),因此Reconstruction Loss实际上是表示自编码器对输入数据的内在模式的掌握程度,也就是自编码器编的码到底有多好。
- Unsupervised Loss反映的是生成器和判别器的竞争对抗互动。
- Supervised Loss反映的是生成器生成的数据能够在多大程度上逼近真实数据经过自编码编码后的数据。
因此训练的进行要有三个阶段
- 利用真实时间序列数据训练自编码器以优化重构过程。
- 利用真实时间序列数据优化supervised loss以捕获历史数据中的“时间上的动力学”
- 联合训练
3. 利用Tensorflow实现TimeGAN
构建和训练TimeGAN需要以下几个步骤:
- 选择并准备真实的时间序列输入和随机的时间序列输入
- 创建TimeGAN模型的关键组成部分
- 定义用于训练阶段的loss function和训练步骤
- 执行训练循环,并储存结果
- 利用训练好的模型生成合成时间序列数据并评估输出的结果
Original code author: Jinsung Yoon
初始阶段
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from pathlib import Path #导入路径处理库
from tqdm import tqdm
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import GRU, Dense, RNN, GRUCell, Input
from tensorflow.keras.losses import BinaryCrossentropy, MeanSquaredError
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
import seaborn as sns
gpu_devices = tf.config.experimental.list_physical_devices('GPU')
if gpu_devices:
print('Using GPU')
tf.config.experimental.set_memory_growth(gpu_devices[0], True)
else:
print('Using CPU')
sns.set_style('white')
#试验路径
results_path = Path('time_gan')
if not results_path.exists():
results_path.mkdir()
experiment = 0
log_dir = results_path / f'experiment_{experiment:02}'
if not log_dir.exists():
log_dir.mkdir(parents=True)
hdf_store = results_path / 'TimeSeriesGAN.h5'
#数据准备
#参数设置
seq_len = 24
n_seq = 6
batch_size = 128
tickers = ['BA', 'CAT', 'DIS', 'GE', 'IBM', 'KO']
#此处数据来源于Quandl community,在2018年已经停用了,所以这里实际上使用的是历史数据
def select_data():
df = (pd.read_hdf('../data/assets.h5', 'quandl/wiki/prices')
.adj_close #经过调整的价格
.unstack('ticker')
.loc['2000':, tickers]
.dropna())
df.to_hdf(hdf_store, 'data/real')
select_data()
#画图
df = pd.read_hdf(hdf_store, 'data/real')
axes = df.div(df.iloc[0]).plot(subplots=True,
figsize=(14, 6),
layout=(3, 2),
title=tickers,
legend=False,
rot=0,
lw=1,
color='k')
for ax in axes.flatten():
ax.set_xlabel('')
plt.suptitle('Normalized Price Series')
plt.gcf().tight_layout()
sns.despine();

#将数据进行标准化处理
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df).astype(np.float32)
#创建滚动窗口序列
data = []
for i in range(len(df) - seq_len):
data.append(scaled_data[i:i + seq_len])
n_windows = len(data)
#创建tf.data.Dataset
real_series = (tf.data.Dataset
.from_tensor_slices(data)
.shuffle(buffer_size=n_windows)
.batch(batch_size))
real_series_iter = iter(real_series.repeat())
#设置随机序列生成器
def make_random_data():
while True:
yield np.random.uniform(low=0, high=1, size=(seq_len, n_seq))
#我们使用 Python 生成器来提供一个 tf.data.Dataset,它会根据需要继续调用随机数生成器并生成所需的批量大小。
random_series = iter(tf.data.Dataset
.from_generator(make_random_data, output_types=tf.float32)
.batch(batch_size)
.repeat())
TimeGAN模型的组成部分
#网络参数
hidden_dim = 24
num_layers = 3
在这段代码里将其设计的非常简单,并且对四个组成部分都使用了一个非常相似的架构(看下方代码);但在实际的应用中,这些架构设计应当根据数据的实际情况进行定制修改。
def make_rnn(n_layers, hidden_units, output_units, name):
return Sequential([GRU(units=hidden_units,
return_sequences=True,
name=f'GRU_{i + 1}') for i in range(n_layers)] +
[Dense(units=output_units,
activation='sigmoid',
name='OUT')], name=name)
#自编码器:内在和复现网络(Embedder & Recovery)
embedder = make_rnn(n_layers=3,
hidden_units=hidden_dim,
output_units=hidden_dim,
name='Embedder')
recovery = make_rnn(n_layers=3,
hidden_units=hidden_dim,
output_units=n_seq,
name='Recovery')
#生成器和判别器(Generator & Discriminator)
generator = make_rnn(n_layers=3,
hidden_units=hidden_dim,
output_units=hidden_dim,
name='Generator')
discriminator = make_rnn(n_layers=3,
hidden_units=hidden_dim,
output_units=1,
name='Discriminator')
supervisor = make_rnn(n_layers=2,
hidden_units=hidden_dim,
output_units=hidden_dim,
name='Supervisor')
TimeGAN的训练
#设置
train_steps = 10000
gamma = 1
#通用损失函数
mse = MeanSquaredError()
bce = BinaryCrossentropy()
一、自编码器的训练
H = embedder(X)
X_tilde = recovery(H)
autoencoder = Model(inputs=X,
outputs=X_tilde,
name='Autoencoder')
#自编码器训练步骤
@tf.function
def train_autoencoder_init(x):
with tf.GradientTape() as tape:
x_tilde = autoencoder(x)
embedding_loss_t0 = mse(x, x_tilde)
e_loss_0 = 10 * tf.sqrt(embedding_loss_t0)
var_list = embedder.trainable_variables + recovery.trainable_variables
gradients = tape.gradient(e_loss_0, var_list)
autoencoder_optimizer.apply_gradients(zip(gradients, var_list))
return tf.sqrt(embedding_loss_t0)
#自编码器训练循环
for step in tqdm(range(train_steps)):
X_ = next(real_series_iter)
step_e_loss_t0 = train_autoencoder_init(X_)
with writer.as_default():
tf.summary.scalar('Loss Autoencoder Init', step_e_loss_t0, step=step)
二、监督训练
#训练步骤
@tf.function
def train_supervisor(x):
with tf.GradientTape() as tape:
h = embedder(x)
h_hat_supervised = supervisor(h)
g_loss_s = mse(h[:, 1:, :], h_hat_supervised[:, :-1, :])
var_list = supervisor.trainable_variables
gradients = tape.gradient(g_loss_s, var_list)
supervisor_optimizer.apply_gradients(zip(gradients, var_list))
return g_loss_s
#训练循环
for step in tqdm(range(train_steps)):
X_ = next(real_series_iter)
step_g_loss_s = train_supervisor(X_)
with writer.as_default():
tf.summary.scalar('Loss Generator Supervised Init', step_g_loss_s, step=step)
三、联合训练(Joint Training)
- 1、生成器
#对抗性架构--监督(supervised)
E_hat = generator(Z)
H_hat = supervisor(E_hat)
Y_fake = discriminator(H_hat)
adversarial_supervised = Model(inputs=Z,
outputs=Y_fake,
name='AdversarialNetSupervised')
#在潜在空间(latent space)的对抗性架构
Y_fake_e = discriminator(E_hat)
adversarial_emb = Model(inputs=Z,
outputs=Y_fake_e,
name='AdversarialNet')
#均值-方差损失
X_hat = recovery(H_hat)
synthetic_data = Model(inputs=Z,
outputs=X_hat,
name='SyntheticData')
- 2、判别器
#架构--实际的数据
Y_real = discriminator(H)
discriminator_model = Model(inputs=X,
outputs=Y_real,
name='DiscriminatorReal')
#生成器的训练步骤
@tf.function
def train_generator(x, z):
with tf.GradientTape() as tape:
y_fake = adversarial_supervised(z)
generator_loss_unsupervised = bce(y_true=tf.ones_like(y_fake),
y_pred=y_fake)
y_fake_e = adversarial_emb(z)
generator_loss_unsupervised_e = bce(y_true=tf.ones_like(y_fake_e),
y_pred=y_fake_e)
h = embedder(x)
h_hat_supervised = supervisor(h)
generator_loss_supervised = mse(h[:, 1:, :], h_hat_supervised[:, 1:, :])
x_hat = synthetic_data(z)
generator_moment_loss = get_generator_moment_loss(x, x_hat)
generator_loss = (generator_loss_unsupervised +
generator_loss_unsupervised_e +
100 * tf.sqrt(generator_loss_supervised) +
100 * generator_moment_loss)
var_list = generator.trainable_variables + supervisor.trainable_variables
gradients = tape.gradient(generator_loss, var_list)
generator_optimizer.apply_gradients(zip(gradients, var_list))
return generator_loss_unsupervised, generator_loss_supervised, generator_moment_loss
#内在网络(embedding)的训练步骤
@tf.function
def train_embedder(x):
with tf.GradientTape() as tape:
h = embedder(x)
h_hat_supervised = supervisor(h)
generator_loss_supervised = mse(h[:, 1:, :], h_hat_supervised[:, 1:, :])
x_tilde = autoencoder(x)
embedding_loss_t0 = mse(x, x_tilde)
e_loss = 10 * tf.sqrt(embedding_loss_t0) + 0.1 * generator_loss_supervised
var_list = embedder.trainable_variables + recovery.trainable_variables
gradients = tape.gradient(e_loss, var_list)
embedding_optimizer.apply_gradients(zip(gradients, var_list))
return tf.sqrt(embedding_loss_t0)
#判别器的训练步骤
@tf.function
def get_discriminator_loss(x, z):
y_real = discriminator_model(x)
discriminator_loss_real = bce(y_true=tf.ones_like(y_real),
y_pred=y_real)
y_fake = adversarial_supervised(z)
discriminator_loss_fake = bce(y_true=tf.zeros_like(y_fake),
y_pred=y_fake)
y_fake_e = adversarial_emb(z)
discriminator_loss_fake_e = bce(y_true=tf.zeros_like(y_fake_e),
y_pred=y_fake_e)
return (discriminator_loss_real +
discriminator_loss_fake +
gamma * discriminator_loss_fake_e)
@tf.function
def train_discriminator(x, z):
with tf.GradientTape() as tape:
discriminator_loss = get_discriminator_loss(x, z)
var_list = discriminator.trainable_variables
gradients = tape.gradient(discriminator_loss, var_list)
discriminator_optimizer.apply_gradients(zip(gradients, var_list))
return discriminator_loss
#训练循环
step_g_loss_u = step_g_loss_s = step_g_loss_v = step_e_loss_t0 = step_d_loss = 0
for step in range(train_steps):
# Train generator (twice as often as discriminator)
for kk in range(2):
X_ = next(real_series_iter)
Z_ = next(random_series)
# Train generator
step_g_loss_u, step_g_loss_s, step_g_loss_v = train_generator(X_, Z_)
# Train embedder
step_e_loss_t0 = train_embedder(X_)
X_ = next(real_series_iter)
Z_ = next(random_series)
step_d_loss = get_discriminator_loss(X_, Z_)
if step_d_loss > 0.15:
step_d_loss = train_discriminator(X_, Z_)
if step % 1000 == 0:
print(f'{step:6,.0f} | d_loss: {step_d_loss:6.4f} | g_loss_u: {step_g_loss_u:6.4f} | '
f'g_loss_s: {step_g_loss_s:6.4f} | g_loss_v: {step_g_loss_v:6.4f} | e_loss_t0: {step_e_loss_t0:6.4f}')
with writer.as_default():
tf.summary.scalar('G Loss S', step_g_loss_s, step=step)
tf.summary.scalar('G Loss U', step_g_loss_u, step=step)
tf.summary.scalar('G Loss V', step_g_loss_v, step=step)
tf.summary.scalar('E Loss T0', step_e_loss_t0, step=step)
tf.summary.scalar('D Loss', step_d_loss, step=step)
生成合成时间序列数据
generated_data = []
for i in range(int(n_windows / batch_size)):
Z_ = next(random_series)
d = synthetic_data(Z_)
generated_data.append(d)
#绘制样本序列
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(14, 7))
axes = axes.flatten()
index = list(range(1, 25))
synthetic = generated_data[np.random.randint(n_windows)]
idx = np.random.randint(len(df) - seq_len)
real = df.iloc[idx: idx + seq_len]
for j, ticker in enumerate(tickers):
(pd.DataFrame({'Real': real.iloc[:, j].values,
'Synthetic': synthetic[:, j]})
.plot(ax=axes[j],
title=ticker,
secondary_y='Synthetic', style=['-', '--'],
lw=1))
sns.despine()
fig.tight_layout()