Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy(计算机视觉中的GANs:综述与分类)
Abstract:
生成对抗网络(GANs)在过去几年得到了广泛的研究。可以说,他们最重要的影响是在计算机视觉领域,在挑战方面取得了巨大的进步,如可信的图像生成,图像之间的翻译,面部属性操纵和类似领域。尽管到目前为止已经取得了重大的成功,但将GANs应用于现实世界的问题仍然面临着重大的挑战,这里我们将重点讨论其中的三个。 这包括:(1)生成高质量的图像;(2)生成图像的多样性;(3)稳定的训练。重点关注流行的GAN技术在应对这些挑战方面取得进展的程度,我们提供了已发表的科学文献中与GAN相关研究的最新进展的详细综述。我们根据GAN体系结构和损失函数的变化采用了一种方便的分类法,通过这种分类法进一步组织这篇综述。虽然到目前为止已有几篇关于GANs的综述,但没有一篇是基于它们在解决与计算机视觉相关的实际挑战方面的进展来考虑这一领域的现状的。因此,为了应对这些挑战,我们将回顾并批判性地讨论最流行的体系结构变体和loss变体的GANs。我们的目标是根据重要的计算机视觉应用需求的相关进展,对GAN研究的现状进行概述和批判性分析。在此过程中,我们还讨论了在计算机视觉中最引人注目的应用,其中GANs已经展示了相当大的成功,并对未来的研究方向提出了一些建议。在本文中研究的GAN变体相关代码是在https://github.com/sheqi/GAN_Review 上总结的。
INTRODUCTION:
生成对抗网络(GAN)在深度学习社区[1]-[6]中引起了越来越多的关注。GANs已被应用于计算机视觉[7]-[14]、自然语言处理[15]-[18]、时间序列合成[19]-[23],语义分割[24]-[28]等。GANs属于机器学习中的生成模型家族。与其他生成模型(如变分自动编码器)相比,GANs提供了诸如处理精确估计密度函数、有效生成所需样本、消除确定性偏差以及与内部神经结构[29]良好兼容等优点。这些特性使得GANs在计算机视觉领域取得了巨大的成功,可信的图像生成[30]-[34],图像到图像的转换[2],[35] -[41],图像超分辨率[26],[42]-[45]和图像补全[46]-[50]。
然而,GANs并非没有问题。最重要的两个原因是他们很难训练,也很难评估。就训练难度而言,判别器和生成器在训练过程中达到纳什均衡并非易事,生成器不能很好地学习数据集的充分分布也是常见的。还有众所周知的模式崩溃(mode collapse)问题。在这一领域[51]-[54]进行了大量的工作。在评价方面,首要的问题是如何最好地度量目标真实分布Pr与生成分布Pg的不相似性。遗憾的是,pr的准确估计是不可能的。因此,对pr和pg之间的对应关系进行良好的估计是一个挑战。先前的工作已经为GANs[55] -[63]提出了各种评价指标。第一个方面关注GANs的性能,例如图像质量、图像多样性和稳定训练。在这项工作中,我们将研究计算机视觉领域中处理这方面问题的现有GAN变体,而对第二方面感兴趣的读者可以查阅[55][63]。
当前GAN的大部分研究可以考虑以下两个目标:(1)改进训练,(2)为实际应用部署GAN。前者旨在提高GANs的性能,因此是后者(即应用)的基础。考虑到许多已发表的关于GAN训练改进的结果,我们在本文中对关注这方面的最重要的GAN变体进行了一个简明的回顾。训练过程的改进在GANs性能方面带来的好处如下:(1)生成图像多样性(也称模式多样性)的改进;(2)生成图像质量的提高和(3)稳定的训练,如纠正生成器的消失梯度问题。为了如上所述提高性能,可以从架构方面或损失方面对GANs进行修改。我们将研究来自双方的改进GANs性能的GAN变体。论文的其余部分是这样安排的:(1)介绍了GANs的相关综述,并说明了这些综述与本工作的区别;(2)对GANs进行了简要介绍;(3)对现有的GANs结构变体进行了综述;(4)我们回顾了文献中GANs的Loss变体;(5)简要介绍了在计算机视觉领域基于GAN的应用;(6)引入了GANs的评价指标,并使用Inception Score和Frechet Inception Distance(FID)对本文讨论的GANs变量进行了比较;(7)我们总结了本次研究中的GAN变体,说明了它们之间的区别和关系,并讨论了未来研究的几个方向
(8)我们总结了本文的综述,并对未来在GANs领域可能的研究工作进行了展望。
文献中提出了许多GAN变体以提高性能。这些可以分为两种类型:(1)结构变体。第一个提出的GAN使用了全连接神经网络[1],因此特定类型的架构可能有利于特定的应用,例如,卷积神经网络(CNNs)适用于图像和循环神经网络(RNNs)适用于时间序列数据;和(2)Loss变体。这里我们探讨了损失函数(1)的不同变化,以使G的学习更加稳定。
图2展示了我们提出的2014年至2020年期间文献中具有代表性的GANs分类法。我们将当前的GANs分为两种主要的变体,即架构变体和损失变体。在架构变体上,我们分别归纳了网络架构、潜在空间和应用重点三大类。网络架构是指对GAN体系结构的整体改进或修改,如在PROGAN中部署的渐进机制。潜在空间这一类别表明,结构修改是基于潜在空间的不同表示进行的,例如,CGAN涉及编码到生成器和判别器的标签信息。最后一类,应用重点,是指根据不同的应用进行修改,例如CycleGAN有专门处理图像风格迁移的架构。在损失变体方面,我们将其分为损失类型和正则化两类。损失类型是指针对GANs优化的不同损失函数,正则化是指对损失函数设计额外的惩罚或对网络进行任何类型的归一化操作。更具体地说,我们将损失函数分为基于积分概率度量(IPM)的损失函数和基于非积分概率度量的损失函数。在基于IPM的GANs中,判别器被限制在一个特定的函数类[64],例如WGAN中的鉴别器被限制在1-Lipschitz。基于非IPM的GANs中的判别器没有这样的约束。

RELATED REVIEWS
这里有以前的GANs综述论文,例如关于GANs性能的综述[65]。该工作侧重于在LSUN-BEDROOM[66]、CELEBAHQ-128[67]和CIFAR10[68]图像数据集上跨不同类型的GANs基准测试的实验验证。结果表明,原始的GAN[1]光谱归一化[69]是将GANs应用于新数据集的一个良好的初始选择。综述的一个限制是基准数据集没有以一种重要的方式考虑多样性。因此基准结果往往更多地关注于图像质量的评价,而忽略了GANs在生成多样化图像方面的有效性。工作[70]调查不同GANs架构及其评估指标。需要进一步比较不同体系结构变体的性能、应用、复杂性等。论文[71]-[73]主要研究了GANs的最新发展方向和应用。他们通过不同的应用比较GAN变体。
将本文综述与当前文献综述进行比较,我们着重介绍了基于GAN变体的性能,包括它们产生高质量图片和多样化图像的能力、稳定的训练、处理消失梯度问题的能力等。这都是通过采用基于架构和损失函数考虑的视角来完成的。这一观点很重要,因为它涵盖了GAN网络面临的基本挑战,它将帮助研究人员根据具体应用选择合适的GAN结构和合适的损失函数。在研究人员在深入这一领域之前,它也为研究人员如何处理这些问题提供了足迹。我们的搜索策略和搜索结果见附录A。搜索论文的详细信息在此链接列出: https://github.com/sheqi/GAN_Review/blob/master/GAN_CV.csv
综上所述,我们对本次综述的贡献有三个方面:
1.我们通过解决三个重要的问题来关注GANs:(1)高质量的图像生成;(2)图像生成多样化;(3)稳定训练。
2.我们提出了新的GAN分类法,并从两个方面介绍了最近的GANs:(1)生成器和判别器的体系结构,如网络体系结构、潜在空间和应用驱动设计;和(2)目标函数训练,例如,基于IPM和非基于IPM的方法中的损失设计,正规化方法。与其他关于GAN的综述相比,本文对不同GAN变体提供了独特的视角。
3.本文还对各种GAN变体的优缺点进行了比较和分析
GENERATIVE ADVERSARIAL NETWORKS
图1展示了典型GAN的体系结构。该体系结构包括两个部分,其中一个是判别器(D)区分真实图像和生成图像,另一个是生成器(G)创建图像欺骗判别器。对于一个z ~ pz的分布,G定义一个概率分布pg作为样本G(z)的分布。GAN的目标是学习近似于真实数据分布pr的生成器分布pg。GAN的优化是针对D和G的联合损失函数进行的。
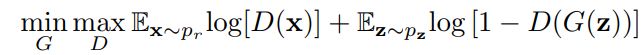
GANs作为深度生成模型(DGM)家族的一员,由于与传统DGMs相比的一些优势,在深度学习社区中引起了指数级增长的兴趣:(1) GANs能够比其他DGMs产生更好的输出。与最著名的DGMs -变分自动编码器(VAE)相比,GANs能够产生任何类型的概率密度,而VAE不能产生清晰的图像[29];(2) GAN框架可以训练任何类型的生成器网络。其他DGMs可能对生成器有前置要求,如生成器的输出层为高斯[29],[74],[75];(3)潜变量的大小没有限制。这些优势导致在生成合成数据特别是图像数据方面得到了最先进的性能。
ARCHITECTURE-VARIANT GANS
文献(见图3)中提出了许多类型的结构变体(见图3)。结构变体的GANs主要用于不同的应用,如:图像到图像传输[35]、图像超分辨率[42]、图像补全[79]和文本到图像生成[80]。在本节中,我们将从前面提到的三个方面(即提高图像多样性、提高图像质量和更稳定的训练)对有助于提高GANs性能的体系结构变体进行综述。对这些体系结构的综述——不同应用程序的变体可以参考work[70]、[72]。

1.Fully-connected GAN (FCGAN)
最初的GAN论文[1]使用全连接神经网络来作为生成器和判别器。这种结构变体被应用于一些简单的图像数据集,如MNIST[81]、CIFAR-10[68]和Toronto face dataset。如果D的优化是在训练的内环内完成的,则建议k步优化D,一步优化G,因为判别器容易过拟合。在实际应用中,式(1)在优化发生器时可能会引起梯度消失问题,最大化训练G的log D(G(z))。这个修改等价地优化了G的pg和pr之间的KL散度,也会导致不对称问题,我们将在第5节详细讨论这个问题。对于架构设置,maxout[82]用于判别器,而ReLU和sigmoid的混合激活用于生成器。对于更复杂的图像类型,它没有表现出良好的泛化性能。
2.Semi-supervised GAN (SGAN)
SGAN是在半监督学习的背景下提出的[83]。半监督学习是介于监督学习和非监督学习之间的一个有前途的研究领域。与监督学习和非监督学习不同的是,半监督学习只对一小部分样本使用标签。监督学习需要为每个样本使用标签,而非监督学习则不提供标签。与FCGAN相比,SGAN的判别器是多头的,即具有softmax和sigmoid功能,分别用于对真实数据进行分类和区分真样本和假样本。作者对SGAN进行了MNIST数据集的训练。结果表明,与原GAN相比,SGAN中的生成器和判别器都得到了改进。我们认为多头判别器的结构相对简单,这限制了模型的多样性,实验只在MNIST数据集上进行。判别器的结构越复杂,模型的性能就越好。

3.Bidirectional GAN (BiGAN)
传统的GANs没有学习逆映射的方法,如将数据投影回潜在空间。BiGAN就是为此设计的[84]。如图5所示,整体架构由编码器(E)、生成器(G)和判别器(D)组成。E将真实样本数据编码成E(x), G解码z成G(z)。因此,D的目的是评估每一对(E(x), x)和(G(z), z)之间的不同。因为E和G不直接交流,也就是说,E从未看到G(z)和G看不到E(x),作者证明了编码器和解码器必须互相学习相互反转才能骗过原论文中的判别器。在未来的工作中,看看这样的模型是否能够处理对抗性的例子将是很有趣的。BiGAN在MNIST和ImageNet的训练。Adam优化器β1 = 0.5和β2 = 0.999用于优化,batch size为128,权重衰减为2.5e−5适用于所有参数。还部署了batch normalization。在未来,研究这样的模型是否有处理对抗性样本的能力将是很有趣的。

4.Conditional GAN (CGAN)
CGAN是通过引入类标签对判别器和发生器进行调节[85]。如图6所示,CGAN提供额外的信息y (y可以是类标签或其他模态数据)给判别器和生成器。应该注意的是,y通常在与已编码的z和x连接之前在生成器和判别器中进行编码。例如,在原工作中的MNIST实验中,z和y分别映射到层尺寸分别为200和1000的隐藏层,然后在生成器中进行合并(合并的层维数为200 + 1000 = 1200)。通过这样做,CGAN增强了判别器的判别能力。CGAN的损失函数与FCGAN略有不同如式(2)所示,其中x和y受z的制约。受益于额外的y编码信息,CGAN不仅能够处理单模图像数据集,还能够处理多模态数据集,如Flickr,它包含带标签的图像数据及其相关的用户生成元数据(UGM),特别是用户标签,这将GAN带到了多模态数据生成的领域。作者在MNIST和Yahoo Flickr Creative Common 100M (YFCC 100M)上实验了CGAN。对于MNIST,模型采用SGD进行训练,小批规模为100,初始学习率为0.1,然后指数下降到1e−6,衰减系数为1.00004。对于产生器和判别器,Dropout的概率均为0.5。使用momentum的初始值为0.5,最后增加到0.7。类标签编码为one-hot,并馈给G和D。在YFCC 100M实验中,训练超参数与MNIST实验设置相同。尽管CGAN通过引入编码标签增强了判别器的判别能力,但仍有部分生成的标签与图像失去了联系。
![]()

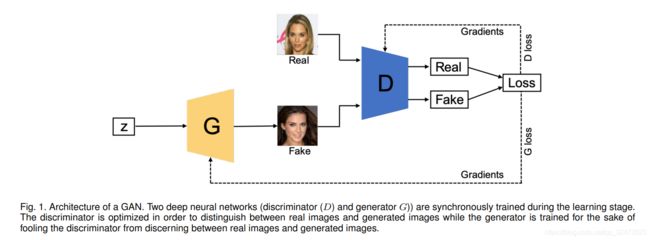
5.InfoGAN
InfoGAN是在CGAN的基础上提出的[86],它通过最大化条件变量与生成数据之间的相互信息来不受监督地学习可解释表示。为了实现这一点,InfoGAN引入了另一个分类器Q(参见图7)来预测G(z|y)给出的y。这里G和Q的组合可以理解为一个自动编码器,其中我们的目标是找到嵌入(G(z|y))最小化y和y'之间的交叉熵。另一方面,D的工作与FCGAN的工作一样,即区分从G生成的样本或从真实数据生成的样本。为了节省计算成本,Q和D分享所有卷积层除了最后完全连接层,使的判别器有能力区分真实和虚假样本和恢复信息y。这相比原来的架构可以改善InfoGAN判别能力。InfoGAN的loss是CGAN的loss的正规化

其中V (D, G)是CGAN的目标,判别器不以y为输入,I(·)为互信息。InfoGAN MNIST, 3D人脸图像[87],3D椅子图像[88],SVHN和CelebA。所有数据集共享相同的训练设置,其中使用Adam optimizer和批量归一化。判别器采用leaky rate为0.1的Leaky ReLU,生成器采用ReLU。D设置学习率2e−4,G的学习率设置为1e−3,λ设为1。这里我们认为模型的多样性非常有限,因为除了最后一层之外,D和Q的参数是共享的。可以研究更复杂的设置Q。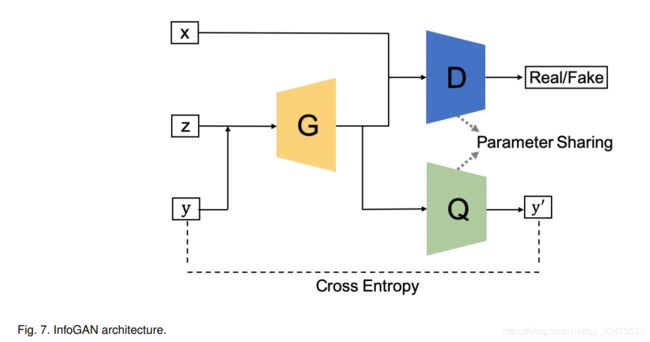
6.Auxiliary Classifier GAN (AC-GAN)
AC-GAN[11]与CGAN和InfoGAN非常相似,它们在体系结构中包含了一个辅助分类器如图8所示。在AC-GAN中,除了z之外,每个生成的样本都有一个相应的类标签c。应该注意的是,AC-GAN与之前的两个体系结构变体(CGAN和InfoGAN)之间的区别是这里的附加信息,它只引用类标签,而之前的两个可以是其他领域数据。因此,我们在AC-GAN中使用c和c‘,以便与之前的两个变体分开。AC-GAN中的判别器由一个判别器D(区分真假样本)和分类器Q(分类真假样本)组成。类似于InfoGAN,判别器和分类器共享除最后一层以外的所有权重。AC-GAN的损失函数可以通过考虑判别器和分类器来构造,可表示为:

其中D是通过最大化LS +LC训练的,G是通过最大化LC - LS训练的。作者对AC-GAN在CIFAR-10和ImageNet的所有1000个类上进行了相关训练。对于CIFAR-10和ImageNet,模型采用Adam,D、G和Q的alpha = 2e−4,β1 = 0.5和β2 = 0.999。Mini-batch size设置为100。模型性能和实验细节可参考原论文[11]。AC-GAN改进了生成图像的视觉质量,具有较高的模型多样性。然而,这些改进依赖于大规模标记数据集,这在实际应用中可能会带来一些挑战。AC-GAN与无监督或自我监督方式的结合有待进一步研究。在第4.13节中,我们还介绍了一种GAN,即标签噪声鲁棒性GANs (rGANs),它处理了噪声标签问题。

7.Laplacian Pyramid of Adversarial Networks (LAPGAN)
LAPGAN被提出用于从低分辨率输入GAN生成高分辨率图像[89]。拉普拉斯金字塔(Laplacian pyramid)[90]是一种图像编码方法,其基本函数是使用多尺度形状相同的局部算子。LAPGAN利用Laplacian金字塔框架内的级联CNN[90]来生成高质量的图像,如图9所示(从右到左)。LAPGAN并没有使用反卷积过程(即DCGAN中使用的)对前一层的核输出进行上采样,而是使用拉普拉斯金字塔对图像进行上采样。首先,LAPGAN使用第一个产生器产生一个非常小的图像,可以缓解产生器不稳定的问题,然后使用拉普拉斯金字塔对该图像进行上采样。然后将上采样后的图像送入下一个发生器产生图像差值,图像差值与输入图像之和即为生成的图像。可以看出,只使用图9中的G3生成图像,但维数很小,有利于稳定的训练。对于像素较大的图像,使用生成器生成图像差值,比相同尺寸的原始图像复杂得多。这种结构有利于更稳定的训练和高分辨率的建模。使用CIFAR10(28×28像素)、STL(96×96像素)和LSUN(64×64像素)进行生成。每个数据集的拉普拉斯金字塔上采样过程分别为8→14→28 (CIFAR10)、8→16→32→64→96 (STL)和
4→8→16→32→64 (LSUN)。该判别器使用3个隐藏层和一个sigmoid输出,而发生器使用5层convnet具有ReLU和批归一化和线性输出层。实验采用初始学习率为0.02的SGD,每个epoch降低1倍(4e−5)。动量从0.5开始,每个epoch增加0.0008,直到最大值0.8。目前的结构包括多个生成图像的生成器,这些生成器之间的连接还没有建立。在第4.10节中,我们介绍了一个更高级的策略,它以渐进的方式训练模型,即PROGAN。

8.Deep Convolutional GAN (DCGAN)
DCGAN是第一个将反卷积神经网络架构应用于G[76]的工作。图10展示了G的架构。反卷积被提出用于可视化CNN的特征,并在CNNs的可视化中显示了良好的性能[91]。DCGAN采用了G的反卷积操作的空间上采样能力,使使用GANs生成更高分辨率的图像成为可能。与原FCGAN相比,DCGAN在体系结构上做了一些重要的改进,有利于高分辨率建模和更稳定的训练。首先,DCGAN将任何池化层替换为判别器的跨步卷积和生成器的反卷积。其次,判别器和生成器都采用批量归一化处理,使生成的样本和真实样本以零为中心定位,即生成的样本和真实样本的统计量相似。第三,对生成器而言,除输出端采用Tanh外,其余各层均采用ReLU激活。对判别器而言,其余各层均采用Leaky ReLU激活。在这种情况下,Leaky ReLU激活将防止网络阻塞在一个“死亡状态”的情况下(例如,在ReLU中输入小于0),因为生成器从判别器接收梯度。DCGANs在大规模场景理解(LSUN)[66]、ImageNet[92]和自定义装配的人脸数据集上进行训练。采用随机梯度下降法(SGD)对所有模型进行训练,小批量为128个。所有的权重都是由标准偏差0.02的零中心正态分布初始化的。采用Adam优化器,学习速率为0.002,动量项是0.5。所有模型的Leaky ReLU的斜率都设置为0.2。模型通过使用64×64像素的图像进行训练。DCGAN是GANs历史上一个非常重要的里程碑,反卷积成为GANs的主要结构。由于模型容量的限制和DCGAN算法的优化,该算法仅适用于低分辨率和多样性较低的图像。

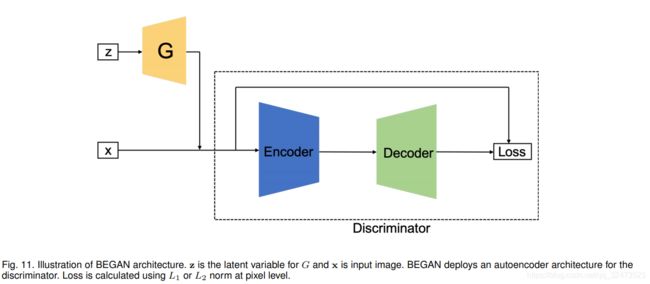
9.Boundary Equilibrium GAN (BEGAN)
BEGAN使用了EBGAN[93]首次提出的自动编码器结构的判别器(见图11)。如图11所示,G和D可以分别产生自动编码器loss。训练自动编码器(D)时,目标是使真实图像的重构损失最大,使生成图像的重构损失最大,即最小化E [L(x)]−E [L(G(z))]。训练G时,目标是最小化E [L(G(z))]。通过引入自编码器,证明了上述重构损失的优化与Wasserstein距离等价。作者还提出了超参数 的使用来控制发生器和判别器损失之间的平衡,即控制生成人脸的多样性。随着γ值的增大,表面的多样性增加,但也会产生伪影。总损失函数如式(5)所示
的使用来控制发生器和判别器损失之间的平衡,即控制生成人脸的多样性。随着γ值的增大,表面的多样性增加,但也会产生伪影。总损失函数如式(5)所示

其中L(·)表示自动编码器重构损失(L2), kt∈[0,1]是一个变量,它控制L(G(z))的重点对损失的惩罚程度。初始化k为0,由λk控制(λk可解释为k的学习率,本文设为1e−3)。
与传统的优化方法相比,BEGAN算法使用来自Wasserstein距离的loss来匹配自动编码器的loss分布,而不是直接匹配数据分布。这种修改有助于G在初始阶段为自动编码器生成易于重构的数据,因为生成的数据接近于0,而真实的数据分布还没有得到准确的学习,这使得D在早期训练阶段无法轻易取胜G。对于编码器和解码器,exponetial线性单位(ELUs)被应用于它们的输出。使用CelebA数据集使用128×128像素的图像对模型进行训练。D和G使用独立Adam优化器,初始学习速率为1e−4,当收敛的度量停止时衰减为2个因子。
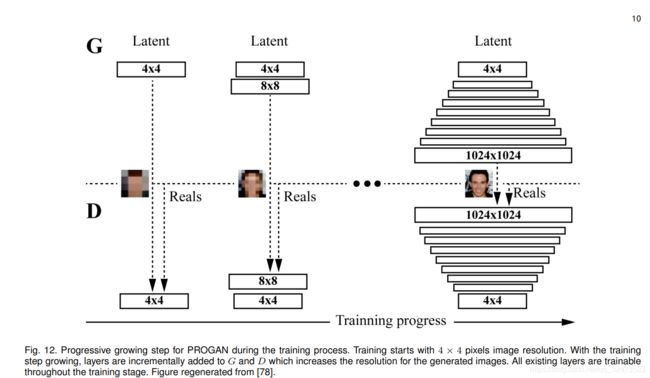
10.Progressive GAN (PROGAN)
PROGAN涉及网络架构扩展的渐进步骤[78]。该体系结构采用了在[94]中首次提出的渐进神经网络的思想。这项技术不会产生遗忘的问题,而且能够通过横向连接将先前学到的特征应用到先前的知识中。因此,它被广泛应用于复杂任务序列的学习。图12展示了PROGAN的训练过程。训练从4×4像素的低分辨率图像开始。G和D都是随着训练的进行而成长的。重要的是,在整个成长过程中,所有变量都是可训练的。这种渐进式训练策略使两个网络的学习更加稳定。通过一点一点地提高分辨率,相对于从潜在向量中发现映射的最终目标,网络被不断地问到一个简单得多的问题。目前所有最先进的GANs都采用这种训练策略,它已经产生了令人印象深刻的、可信的图像[30],[78],[95]。作者开始用4×4像素的图像训练PROGAN,并逐渐将两倍大小的图层添加到G和D中,如图12所示,新图层平滑地褪色。多尺度训练图像是使用拉普拉斯金字塔表示[90]产生的,类似于LAPGAN。模型分别在CIFAR10(32×32像素图像)、LSUN(256×256像素图像)和CelebA-HQ(1024×1024像素图像)上训练。除了最后一层(使用线性激活)外,D层和G层的所有层都使用leakness为0.2的Leaky ReLU。在生成器的每个Conv 3×3层之后,只对特征向量进行像素化归一化,即在任意一个网络中都没有批量归一化、层归一化或权值归一化。Adam优化器的α= 1 e−3,β1 = 0,β2 = 0.99和 = 1−8是用于训练D、G 。为了节省内存预算,随着图像像素的增加,小批量尺寸逐渐减小,即 当图像尺寸为4×4到8×8时batch size为16,256×256时为14→512×512时6→1024×1024时为3。WGAN-GP的[5]loss用于优化D和G。
= 1−8是用于训练D、G 。为了节省内存预算,随着图像像素的增加,小批量尺寸逐渐减小,即 当图像尺寸为4×4到8×8时batch size为16,256×256时为14→512×512时6→1024×1024时为3。WGAN-GP的[5]loss用于优化D和G。
11.Self-attention GAN (SAGAN)
传统CNN只能捕获局部空间信息和感受野不能覆盖整个结构,导致基于CNN的GAN有困难在学习多层次图像数据集(例如,ImageNet)并且生成的图像中关键的部分可能会有偏移,如生成的人脸图片中的鼻子可能没有出现在正确的位置。自注意机制已被提出,以确保大的感受野,而不牺牲CNNs的计算效率[96]。SAGAN在GANs的判别器和产生器架构设计中采用了一种自注意机制[97](见图13)。得益于自我注意机制,SAGAN能够学习全局的、大范围的依赖关系来生成图像。它在基于ImageNet数据集的多类图像生成方面取得了良好的性能。作者在ImageNet数据集(128×128像素图像)上训练SAGAN。D和G均采用光谱归一化[98]。生成器采用条件批归一化,判别器采用批投影。Adam优化器的β1 = 0,β2 = 0.9,判别器的学习率为4e−4,生成器的学习率为1e−4。作者也表明self-attention的机制部署在判别器和生成器的大的特征图谱上更有效即部署self-attention机制在大小为32×32尺寸的特征图使用FID分数达到最好的性能和部署self-attention机制在大小为64×64的特征图使用Inception分数达到最佳性能,这表明自注意机制与卷积机制在大特征地图上是互补的。因此,建议将自注意机制应用于大特征图,以提高GANs的多样性。

12.BigGAN
BigGAN[95]在ImageNet数据集上也取得了最先进的性能。它的设计是基于SAGAN的,它已经证明可以通过扩展GAN训练,即增加每个层的通道数量和增加批量大小,来提高性能。在ImageNet上分别用128×128、256×256和512×512分辨率对模型进行训练。本文的训练设置采用SAGAN算法,学习率减半,每G步训练2个D步。对潜在变量z的不同选择进行了探讨,提出了伯努利方程{0,1}和截尾正态最大值(N (0,i), 0)在不截尾的情况下效果最好。截断技巧涉及在训练期间对发生器的潜在空间使用不同的分布,而不是在推理或图像合成期间。在BigGAN,训练时使用高斯分布,推理时使用截断高斯分布。这种截断技巧提供了图像质量或保真度和图像多样性之间的平衡。采样范围越窄,图像质量越好,而采样范围越大,图像的多样性就越大。我们总结以下操作BigGAN使BigGAN扩大架构:(1)Self-attention模块和Hinge loss:BigGAN使用来自SAGAN并通过Hinge loss训练的带有注意力机制的模型架构,Self-attention有助于模型的多样性和Hinge loss使更稳定的训练;(2)类条件信息:通过类条件批处理标准化将类信息提供给生成器模型;(3)更新判别器多于生成器:BigGAN对判别器模型做了轻微的修改,每次迭代更新生成器模型前都会更新两次判别器模型;(4)模型权值的移动平均:在生成图像进行评价之前,使用移动平均法对之前的训练迭代进行模型权值的平均;(5)网络上的一些操作:正交权值初始化、更大的批处理大小、skip-z连接(从潜在连接跳到多层连接)、共享嵌入等,作者表明这些操作都有助于提高性能。作者还描述了针对这种大尺度的失稳分析的特征。更多细节可以参考原文。
13.Label-noise Robust GANs (rGANs)
我们在第4.4节讨论了CGAN,在第4.6节讨论了AC-GAN,它们具有学习解纠缠表示的能力,提高了GAN的识别能力。然而,训练模型需要大规模的标记数据集,这在现实场景中提出了一些挑战。Kaneko等人[99]提出了一种名为标签-噪声鲁棒GAN(rGANs)的算法家族,该算法集成了一个噪声过渡模型,即使在提供的训练标签是噪声的情况下,也能学习干净标签条件生成分布。我们讨论了两种变体,它们是AC-GAN (rAC-GAN)的扩展和CGAN (rCGAN)的扩展,如图14所示。rGANs是噪声过渡模块的核心部分p(˜y | yˆ)(˜y是带有噪声的的标签和yˆ干净的标签)引入到了判别器,在p (˜y =j | yˆ= i) = T (i, j) ,T是一个噪声过渡矩阵![]() ,c为类数)。作者对rGANs在CIFAR-10和CIFAR-100上进行训练。作者证明了rAC-GAN和rCGAN在CIFAR-10中的性能优于原始结构,并且对标签噪声具有鲁棒性。然而,在CIFAR-100中,当标签被引入高噪音时,它们的性能下降。我们认为这样的框架在遇到更复杂的数据集,如ImageNet时仍有一定的局限性,需要在未来进一步研究。
,c为类数)。作者对rGANs在CIFAR-10和CIFAR-100上进行训练。作者证明了rAC-GAN和rCGAN在CIFAR-10中的性能优于原始结构,并且对标签噪声具有鲁棒性。然而,在CIFAR-100中,当标签被引入高噪音时,它们的性能下降。我们认为这样的框架在遇到更复杂的数据集,如ImageNet时仍有一定的局限性,需要在未来进一步研究。
14.Your Local GAN (YLG)
这项工作[100]引入了一种新的局部稀疏注意层,该层保留了二维几何形状和局部性。为了显示该思想的适用性,他们用新的结构取代了SAGAN[96]的密集注意层。重要的创新之处在于:1)信息流图信息理论框架支持的注意模式;2)引入YLG-SAGAN,取得了更优的性能并且时间减少了40%;3)他们将损失梯度下降的自然反演过程放到在更大的模型上而不是在小的GANs上。作者利用的一种特定技巧称为ESA(枚举,移位,应用)。 他们修改一维稀疏度,以根据其与位置(0,0)处像素的曼哈顿距离(通过使用行优先级断开联系),通过枚举图像的像素来了解图像的二维位置,从而移动任意给定的索引, 三维稀疏化以匹配曼哈顿距离枚举而不是整形枚举,然后将这种尊重二维局部性的新的一维稀疏图案应用于图像的一维整形版本。
然而,我们认为在这项工作中存在两个相互矛盾的目标。这种方法一方面为了提高计算和统计效率,使网络尽可能稀疏,另一方面还需要支持良好的、充分的信息流。

15.AutoGAN
AutoGAN[101]将神经架构搜索(NAS)算法引入生成对抗网络的研究(GANs)如图15所示。图15 (b)中生成器结构变化的搜索空间通过图15 (a)中所示的RNN控制器引导,并结合参数共享和动态复位来加速过程。他们使用Inception分数作为奖励,并引入了一种多级搜索策略,以渐进的方式执行NAS。按照光谱归一化GAN的训练设置,利用hinge loss对共享GAN进行训练。
整个流程是深刻的,但也提出了新的挑战w.r.tNAS和GAN的密切结合。NAS在普通分类问题上仍有待优化,更不用说GANs带来的不稳定训练问题。尽管在本文中AutoGAN显示了在GAN体系结构中使用NAS的有前景的结果,这是手工设计的独特之处,上面介绍的GAN架构。我们认为,它仍有两个关键问题有待解决:
1.生成器的搜索空间是有限的,判别器的搜索策略没有讨论。
2.AutoGAN还没有在高分辨率图像生成数据集上进行测试。因此,我们不能对这种方法的适用性有一个直观的估计。目前的图像生成任务是初步的。

16.MSG-GAN
众所周知,要适应不同的数据集,GANs是非常困难的。Karnewar等人认为造成这一问题的原因之一是当真分布和假分布的支持没有足够的重叠时,从判别器传递到生成器的梯度变得无信息,并提出MSG-GAN[102]来处理这一问题。如图16所示,产生器和判别器的潜在空间是相互连接的,在潜在空间中,产生器和判别器会共享更多的信息。更具体地说,G中每个转置卷积步骤(图16中的3个步骤)中的激活通过操作r映射到不同尺度的图像,如,这里是1×1的卷积。同样,映射后的图像由r编码到激活图,它与由真实图像编码的激活连接。这种连接使得D和G之间可以共享更多的信息,实验结果也证明了这一点。作者对MSG-GAN在多个数据集进行了训练,例如CIFAR10、Oxford flowers、LSUN,Indian Celebs,CelebA-HQ(1024×1024)和FFHQ(1024×1024)。对于所有数据集,超参数设置几乎是相同的。具体来说,![]() 是从标准正态分布中抽取的。RMSprop学习速率为0.003,同时用于D和G。WGAN-GP loss用于训练网络。虽然MSG-GAN在几个图像数据集上都取得了非常好的结果,但是MSG-GAN生成多样化图像的能力还没有经过测试,我们发现在CIFAR10上的结果不如在本研究中进行的其他数据集好。我们猜想这可能是由于G和D之间的连接可能限制了G上的多样性,因为G和D的激活将会连接在一起。图像上的多样性可能导致匹配激活不一致,对训练产生不利影响。在这方面还需要进一步的研究,如增加自注意模块来提高模型的多样性。
是从标准正态分布中抽取的。RMSprop学习速率为0.003,同时用于D和G。WGAN-GP loss用于训练网络。虽然MSG-GAN在几个图像数据集上都取得了非常好的结果,但是MSG-GAN生成多样化图像的能力还没有经过测试,我们发现在CIFAR10上的结果不如在本研究中进行的其他数据集好。我们猜想这可能是由于G和D之间的连接可能限制了G上的多样性,因为G和D的激活将会连接在一起。图像上的多样性可能导致匹配激活不一致,对训练产生不利影响。在这方面还需要进一步的研究,如增加自注意模块来提高模型的多样性。

17.Summary
我们已经概述了基于三个关键挑战的架构变体的GANs,这些 。图17展示了本节讨论的架构变体GANs从2014年到2020年的足迹。可见,在不同的GAN变体中存在大量的相互连接。
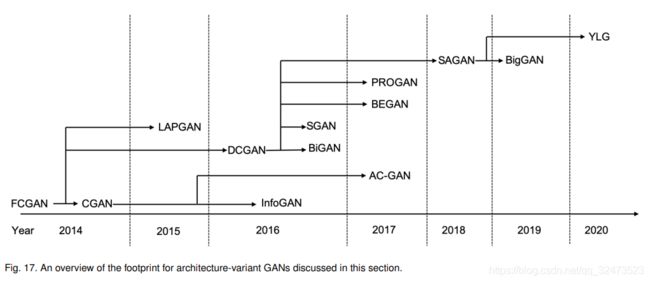
图18显示了三个挑战的相关性能。

由于不同的GAN是为生成不同类型的图像而设计的,例如PROGAN和BEGAN是为生成人脸图像而设计的,这两种模型可能无法生成不同的自然图像,因此很难总结出每种结构变体GAN的量化结果。在此,我们根据文献对不同挑战进行总结。这可能是主观的总结,因为不同的GANs使用不同的图像数据集和不同的评估指标。我们建议读者按照原来的文章,以获得对每个GAN变体的理论和性能的更深入的见解。所有提出的架构变体都能够提高图像质量。SAGAN是为了提高GANs的多类学习能力而提出的,其目标是生成更加多样化的图像。BigGAN的设计得益于SAGAN架构,旨在提高图像质量和图像多样性。应该指出的是,PROGAN和BigGAN两者都能够产生高分辨率的图像。BigGAN通过增加batch size实现了更高的分辨率,作者提到,当batch size足够大(2048)时,渐进增长[78]操作是不必要的。然而,当GPU内存有限时(大量的批处理需要GPU内存),仍然需要一个渐进的增长操作。得益于频谱归一化(SN), SAGAN和BigGAN对消失梯度挑战都是有效的,这将在损失变GANs部分讨论。这些里程碑式的体系结构变体表明了GANs兼容性的强大优势,GAN对任何类型的神经体系结构[29]都是开放的。此属性使GANs可应用于许多不同的应用[27]、[40]、[45]。
关于不同体系结构变体的GANs所实现的改进,接下来我们将分析这里给出的体系结构变体之间的互连和比较。从原始GAN文献中描述的FCGAN开始,这个架构变体只能生成简单的图像数据集。这种限制是由网络体系结构造成的,其中FC网络的能力非常有限。提高GANs性能的研究是从设计更复杂的GANs体系结构开始的。一个更复杂的图像数据集(如ImageNet)与简单的图像数据集(如MNIST)相比具有更高的分辨率和多样性,因此需要更复杂的方法。
在产生更高分辨率的图像的背景下,一个明显的方法是增加生成器的大小。LAPGAN和DCGAN基于这样的观点对生成器进行上采样。得益于DCGAN简洁的反卷积上采样过程和易于推广,DCGAN的体系结构在GANs文献中得到了更广泛的应用。值得注意的是,在计算机视觉领域,大部分的人工神经网络都是使用反卷积神经网络作为生成器,DCGAN最先使用了这种方法。因此,DCGAN是文献中经典的GAN变体之一。
SGAN、BiGAN、CGAN、InfoGAN和AC-GAN具有相似的特性,这些特性被添加到GAN中,提高了GAN的识别能力。CGAN是第一个将编码标签与图像一起添加到判别器和噪声输入到发生器的工作,其中输入噪声和输入图像现在用标签进行编码。在CGAN的基础上,除了区分真样本和假样本,InfoGAN还增加了一个分类器Q估计输入图像(包括生成的图像)属于哪个类。AC-GAN与InfoGAN非常相似。AC-GAN和InfoGAN的不同之处在于,真实图像也受到标签的制约,分类器预测生成的图像和真实图像都属于哪一类。类似于此修改,SGAN在判别器上增加了一个多头的最后一层,该层包含softmax和sigmoid,使判别器能够同时区分真假,并对图像进行分类。BiGAN介绍了学习逆映射,这也显示了对生成图像质量的改善。这里提到的体系结构变体都具有类似的属性,即向GANs添加比原始GAN更多的编码信息。这些类型的性能依赖于应该被良好标记的数据集,这可能会在一些实际应用中带来挑战,例如,数据集未被标记,部分被标记或包含嘈杂标签(章节4.13中的rGANs)。这种体系结构的扩展可以与自我监督学习方式相结合。
生成高质量图像的能力显然是GANs的一个重要方面。这可以通过明智的架构选择得到改进。BEGAN和PROGAN从这个角度展示了方法。在DCGAN的生成器中使用了相同的架构,开始重新设计了包含编码器和解码器的判别器,其中判别器试图区分像素空间中生成的图像和自动编码的图像之间的差异。在这种情况下,图像质量得到了改善。在DCGAN的基础上,PROGAN展示了一种渐进式的方法,以增量的方式训练类似于DCGAN的体系结构。这种新方法不仅可以提高图像质量,而且可以产生更高分辨率的图像。
生成不同的图像是GANs最具挑战性的任务,GANs很难成功生成像ImageNet集合中表示的图像那样的图像。传统的NN很难从图像中学习全局和长期的相关性。由于自注意机制的存在,SAGAN等方法将自机制集成到判别器和生成器中,这在学习多类图像方面帮助了GANs。此外,BigGAN可以被认为是SAGAN的扩展,它引入了更深入的GAN架构,具有非常大的批处理规模,可以产生像ImageNet那样的高质量和多样化的图像,是目前最先进的。
在这里,我们简要介绍了不同架构的GANs如何解决每个挑战:
图像质量 GANs的基本目标之一是生成更逼真的图像,这对图像质量要求较高。原来的GAN (FCGAN)由于架构的能力有限,只能应用于MNIST、Toronto face dataset和CIFAR-10。DCGAN和LAPGAN将反卷积过程和上采样过程分别引入到架构中。这两个过程使模型有更大的容量产生更高分辨率的图像。其余的架构变体(例如,BEGAN, PROGAN, SAGAN和BigGAN)都在损失函数上做了一些修改,例如,使用Wasserstein距离作为损失函数,我们将在本文的后面讨论这方面的问题,这也有利于图像质量。仅就体系结构而言,BEGAN为判别器使用了一个自动编码器体系结构,它在像素级别上比较生成的图像和真实图像。这有助于生成器生成易于重构的数据。PROGAN采用了更深层次的架构,模型随着训练的进展而不断成长。这种渐进式训练策略提高了判别器和生成器的学习稳定性,使模型更容易学习如何生成高分辨率图像。SAGAN主要受益于SN,我们将在下一节讨论。BigGAN演示了高分辨率图像生成可以受益于具有更大批量的更深层次模型。
消除梯度 改变损失函数是解决这一问题的唯一方法。这里的一些架构变体避免了渐变消失的问题,因为使用了不同的损失函数,我们将在下一节中重新讨论这个问题。
模式多样性 这是GANs最具挑战性的问题。人工神经网络很难生成真实多样的图像,比如自然图像。就体系结构变体的GANs而言,只有SAGAN和BigGAN解决了这类问题。利用自注意机制,SAGAN和BigGAN的CNNs可以处理大的感受野,克服了生成图像中成分偏移的问题。这使得这种类型的GANs能够产生不同的图像。
LOSS-VARIANT GANS
GANs中另一个显著影响性能的设计决策是式(1)中损失函数的选择。而原始GAN工作[1]已经证明了GANs训练的全局最优性和收敛性。它仍然突出了训练GAN时可能出现的不稳定问题。这个问题是由[1]中所述的全局最优性准则引起的。当对任意G达到一个最优D时,即达到全局最优,因此当式(1)中损失的D的导数为0时,即达到最优D。所以我们有

其中x为真实数据和生成数据,D (x)为最优判别器,pr(x)为真实数据分布,pg(x)为生成数据分布。到目前为止我们已经得到了最优判别器D。当我们有最优D时,G的损失可以通过将D (x)代入式(1)来表示
![]()
式(7)展示了判别器优化时GAN的损失函数,它与两个重要的概率测量指标有关。一种是Kullback-Leibler (KL)散度,定义为
![]()
另一种是Jensen-Shannon (JS)散度,表示为

因此,对于式(7)中最优D, G的损失可重新表示为

这表明G的loss现在成为了最小化pr和pg之间的JS散度。随着D一步一步的训练,G的优化将接近最小化pr和pg之间的JS散度。我们现在开始解释不稳定的训练问题,在D经常容易赢得G . 这个不稳定的训练问题实际上是方程(9)的JS散度引起的,给出一个最优D,
对式(10)进行优化的目的是使pg向pr靠拢(图19)。

三个图从左到右的JS散度分别为0.693、0.693、0.336,表示如果pr和pg之间没有重叠,JS的散度保持不变(log2=0.693)。图20给出了JS散度随pr到pg距离的变化及其梯度。可以看出JS散度是常数及其梯度几乎是0当距离大于5时,这表明训练过程没有对G有任何影响 。在训练G时,只有当pg和pr拥有大量重叠时JS散度的梯度才是非零的,即G的梯度消失将会出现当D接近最优。在实践中,pr和pg不重叠或具有可忽略重叠的可能性非常高[103]。

原始的GANs工作[1]也强调了![]() 的最小化,以训练G避免消失梯度。但是,这种训练策略会导致另一个问题,即模式下降。首先,让我们检查
的最小化,以训练G避免消失梯度。但是,这种训练策略会导致另一个问题,即模式下降。首先,让我们检查![]() 。利用最优判别器D*, KL(pg||pr)可重新表示为
。利用最优判别器D*, KL(pg||pr)可重新表示为
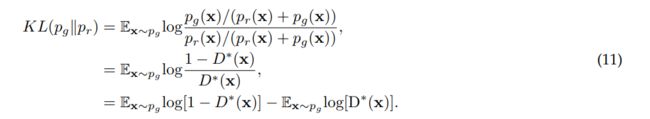
G现在的备选损失形式可以通过交换式(11)中两边的顺序来表述

式(12)中G的备选损失只受前两项的影响(后两项为常数),但由于JS(pr||pg)有界于[0,log 2],如图20(a)所示,因此损失函数由KL(pg||pr)主导。可以注意到,式(12)中的第一项为负的KL发散,其中反向优化的pg与KL散度优化的pg完全不同。图21通过对p使用两个高斯混合和对q使用单个高斯混合说明了这种差异。当p有多个模式时,q试图将所有模式模糊在一起,以便将高概率质量放在所有模式上,如图21(a)所示。但是从图21(b)可以看出,q选择恢复单个高斯函数是为了避免将概率质量放在两个高斯函数中间的低概率区域。

因此对反向KL发散进行优化会导致训练GANs时模式崩溃,如下所示
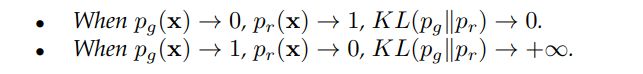
对G产生的两例较差性能的处罚是完全不同的。性能差的第一个例子是G没有生成一个合理的样本范围,但是会受到非常小的惩罚。性能差的第二个例子是G产生不合情理的样品,但惩罚很大。第一个例子关注的是生成的样本缺乏多样性,第二个例子关注的是生成的样本不准确。考虑到第一个例子,G生成了重复但安全的样本,而不是冒险生成多样但不安全的样本,这导致了模态崩溃问题。综上所述,使用式(1)中的原始loss将导致训练G的消失梯度,使用式(12)中的备选loss将导致模式崩溃问题。这类问题不能通过改变GANs体系结构来解决。因此,我们可以认为最终的GANs问题源于损失函数的设计,而重新设计损失函数的创新思想可能会解决这个问题。
为了提高训练GANs的稳定性,人们对GANs的损失变体进行了广泛的研究。
1.Wasserstein GAN (WGAN)
WGAN[104]通过使用Earth mover (EM)或Wasserstein1[105]距离作为损失度量进行优化,成功地解决了原始GAN的这两个问题。EM距离定义为
![]()
其中![]() 表示所有联合分布的集合,
表示所有联合分布的集合,![]() 的边际分布为pr和pg。与KL和JS散度相比,他们能够反映距离即使pr和pg不重叠,也是连续的,因此能够为训练生成器提供有意义的梯度。图31说明了WGAN的梯度与原始GAN相比。
的边际分布为pr和pg。与KL和JS散度相比,他们能够反映距离即使pr和pg不重叠,也是连续的,因此能够为训练生成器提供有意义的梯度。图31说明了WGAN的梯度与原始GAN相比。

值得注意的是,WGAN有一个平滑的梯度,用于训练跨越整个空间的生成器。然而,式(13)中的极小值是难以处理的,但作者证明,相反,Wasserstein距离可以被估计为

其中fw可以由D实现,但有一些限制(细节感兴趣的读者可以参考原来的工作[104])和z是G输入噪声。 w是D的参数和D旨在最大化方程(14)为了使优化距离相当于Wasserstein距离。当D被优化时,式(13)将变成Wasserstein距离,G的目标是使其最小。所以G的损失是

WGAN与原GAN的一个重要区别是D的函数。原工作中的D用作二值分类器,而WGAN中使用的D是拟合Wasserstein距离,这是一个回归任务。因此,D最后一层的sigmoid在WGAN中被移除。作者在LSUN数据集上以64 *64分辨率训练WGAN。重要的是,训练的WGAN将是不稳定的时候,一个基于动量的优化器,如Adam(β1 >0被使用)。因此,使用RMSProp对WGAN进行训练。
2.WGAN-GP
尽管WGAN在提高GAN训练的稳定性方面已被证明是成功的,但它还不能很好地推广到更深层次的模型中。实验表明,由于参数裁剪,大多数WGAN参数在-0.01和0.01范围内。对于判别器[57],WGAN-GP提出了使用梯度惩罚来限制![]() ,对判别器的修正损失变为
,对判别器的修正损失变为
![]()
xr是样本数据来自真实的数据分布Pr,xg是样本数据来自生成的数据分布pg,![]() 均匀采样双点之间的直线,从实际数据分布Pr和生成的数据分布pg取样。前两项是原始WGAN损失和后一项是梯度惩罚。与WGAN相比,WGAN- GP的训练参数分布更好(图22),在训练GANs时稳定性表现更好。WGAN-GP之前,在GAN上成功的训练只发生在那些生成器和判别器只有几层的模型上。 WGAN-GP以ResNet-101架构为骨干,成功展示了WGAN-GP的稳定训练,对PROGAN、BigGAN等大规模图像生成的GANs研究产生了影响。如前一节所述,WGAN在使用基于动量的优化器(如Adam)时存在不稳定的问题。WGAN-GP通过使用Adam优化器显示了稳定的训练,使用相同的训练设置甚至更快的收敛。WGAN-GP在ImageNet用32*32分辨率的图像、LSUN数据集用128*128分辨率的图像、CIFAR-10上用32*32分辨率的图像上进行实验。实验采用α= 1e-4,β1 = 0,β2 = 0.9的Adam优化器。学习率为2e-4,批量为64。发现分段线性激活函数ReLU和leaky ReLU以及平滑激活函数Tanh都能稳定地训练WGAN-GP。
均匀采样双点之间的直线,从实际数据分布Pr和生成的数据分布pg取样。前两项是原始WGAN损失和后一项是梯度惩罚。与WGAN相比,WGAN- GP的训练参数分布更好(图22),在训练GANs时稳定性表现更好。WGAN-GP之前,在GAN上成功的训练只发生在那些生成器和判别器只有几层的模型上。 WGAN-GP以ResNet-101架构为骨干,成功展示了WGAN-GP的稳定训练,对PROGAN、BigGAN等大规模图像生成的GANs研究产生了影响。如前一节所述,WGAN在使用基于动量的优化器(如Adam)时存在不稳定的问题。WGAN-GP通过使用Adam优化器显示了稳定的训练,使用相同的训练设置甚至更快的收敛。WGAN-GP在ImageNet用32*32分辨率的图像、LSUN数据集用128*128分辨率的图像、CIFAR-10上用32*32分辨率的图像上进行实验。实验采用α= 1e-4,β1 = 0,β2 = 0.9的Adam优化器。学习率为2e-4,批量为64。发现分段线性激活函数ReLU和leaky ReLU以及平滑激活函数Tanh都能稳定地训练WGAN-GP。

3.Least Square GAN (LSGAN)
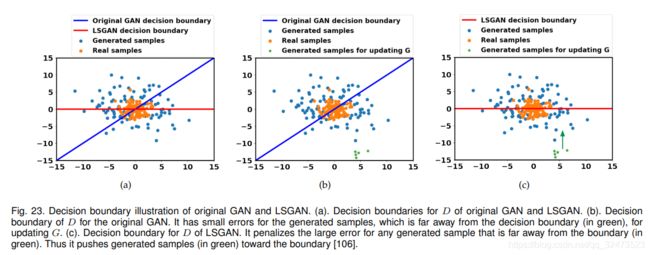
LSGAN是文献[106]中提出的一种从判别器确定的判决边界的角度来修正G梯度消失问题的新方法。这项工作认为,原始GAN的D的决策边界惩罚非常小的错误,以更新G对那些生成的样本远离决策边界。作者提出用最小二乘损失来代替原论文[1]中所述的sigmoid交叉熵损失。本文提出的损失函数定义为

其中a是生成样本的标签,b是真实样本的标签,c是G希望D误将生成的样本识别为真实样本的超参数。这种修改有两个好处:(1)D的新决策边界惩罚了那些生成的样本远离决策边界时产生的较大误差,将那些不良生成的样本推向决策边界。这有利于产生改进的图像质量;(2)惩罚生成的远离决策边界的样本,能够在更新G时提供足够的梯度,弥补了训练G时的梯度消失问题。图23展示了LSGAN和原始GAN的决策边界的比较。用原sigmoid交叉熵损失训练的D的决策边界与提出的最小二乘损失训练的D的决策边界是不同的。文献[106]证明,当a、b、c满足b-c = 1、b-a = 2时,LSGAN的优化等价于使pr + pg与2pg之间的Pearsonχ2散度最小。与WGAN相似,这里的D表现为回归,sigmoid也被移除。LSGAN在LSUN和HWDB1.0[107]上进行评估,其图像分辨率为112*12。使用β1 = 0.5的Adam优化器,LSUN和HWDB1.0的学习率分别为1e-3和2e-4。类似DCGAN, ReLU激活和Leaky ReLU激活分别用于发生器和判别器。
4.f-GAN
f-GAN总结说,GANs可以通过使用f-divergence进行训练[108]。f-divergence ![]() 度量了两个概率分布(pr和pg关于GANs)之间的差异,如前面提到的KL divergence, JS divergence和Pearsonχ2,可以总结为
度量了两个概率分布(pr和pg关于GANs)之间的差异,如前面提到的KL divergence, JS divergence和Pearsonχ2,可以总结为

其中f是凸函数,且f(1) = 0。需要注意的是,在原文[108]中,f被称为生成器函数,这与GANs中的概念生成器G完全不同。因此,为了避免与本文中的生成器 G产生混淆,我们在本节中使用f或f散度函数代替原文章中的生成器函数。f-GAN根据式(18)所示的f发散函数,将GANs的损失函数推广。具有f-散度函数的f-散度列表如表1所示。

然而,式(18)是难以处理的,因此它需要被估计为一种易于处理的形式,如期望形式。利用凸共轭(Fenchel共轭)f(u) = ![]() f-散度可以表示为散度的一个下界
f-散度可以表示为散度的一个下界

其中T是T的任意函数类,满足X R(例如,参数化判别器具有特定的激活函数,如sigmoid)。上面的推导得到Df (pr||pg)的下界是易于处理的,因此可以直接计算。f-GAN首先特点是最大化的优化下界(最后一行在方程(19))鉴别器,旨在使下界的估计f-divergence,然后最小化f-divergence关于发电机为了使pg接近公关。这种优化称为变分散度最小化(VDM)。作者在MNIST(28 28像素图像)和LSUN(96 96像素图像)上训练了基于VDM的生成神经网络采样器。模型体系结构和训练设置与DCGAN中提出的相同。
5.Unrolled GAN (UGAN)
UGAN是为了解决GANs在训练过程中的模式崩溃问题而提出的设计[111]。UGAN的核心设计创新是添加了一个用于更新G的梯度项,该项能够捕捉判别器对生成器变化的响应。
D的最优参数可表示为如下迭代优化过程:

其中ηk为学习速率,θD为D的参数,θG为G的参数。展开k步的代理损失可以表示为:
![]()
然后,这个代理损失用于更新D和G的参数

图24展示了具有三个展开步骤的展开GAN的计算图。
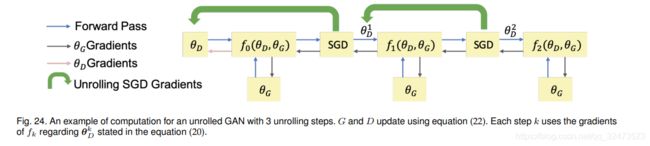
式(23)说明了更新G的梯度

值得注意的是,方程(23)中的第一项是原始GAN的梯度。这里的第二项反映了D如何对G的变化作出反应。如果G趋向于坍缩到一个模态,D将增加G的损失。因此,这种展开的方法能够防止GANs的模态崩溃问题。作者用MNIST和CIFAR10数据集训练UGAN。批处理归一化后,所有卷积的内核大小都是3*3。判别器使用leaky ReLU,leaky rate为0.3,生成器使用ReLU。
生成器由5层组成,其中全连接层、3个反卷积层和1个卷积层。判别器有4层,其中3个卷积层和1个全连接层。实验中使用了生成器学习率为1e-4,判别器学习率为2e-4的Adam优化器。
6.Loss Sensitive GAN (LS-GAN)
LS-GAN被引入来训练生成器通过最小化真实样本和生成样本之间的指定边界来生成真实样本[112]。本研究认为,原始GAN中出现的诸如消失梯度和模态崩溃等问题是由非参数假设引起的,该假设认为判别器能够区分真实样本和生成样本之间的任何类型的概率分布。如前所述,真实样本分布与生成样本分布之间的重叠可以忽略,这是非常正常的。此外,D还能够分离真实样本和生成样本。在这种情况下JS散度将成为一个常数,G的梯度消失出现。在LS-GAN中,D的分类能力受到限制,并且可以通过用θ参数化的损失函数Lθ(x)来学习,D假设真实样本的损失应小于生成样本的损失。 损失函数可以训练为以下约束
![]()
其中∆(x,G(z))是测量实际样本与生成样本之间差异的余量。 该约束条件表明实际样本与生成的样本之间的间隔至少为∆(x,G(z))。 LS-GAN的优化如下:

其中λ是一个正平衡参数,![]() 和θ是D中的参数。根据方程(25)中LD中的第二项,∆(x,G(z))被添加了作为优化D的正则项,以防止D过度拟合真实样本和生成的样本。 图25证明了公式(25)的有效性。
和θ是D中的参数。根据方程(25)中LD中的第二项,∆(x,G(z))被添加了作为优化D的正则项,以防止D过度拟合真实样本和生成的样本。 图25证明了公式(25)的有效性。

D的损失限制了D的能力,即,它挑战了D从真实样本中分离出良好生成的样本的能力,这是梯度消失的最初原因。 更正式地说,LS-GAN假定pr位于一组紧凑支撑的Lipschitz密度中。
这些模型在mini-batch 为64的CIFAR-10,SVHN [113]和CelebA数据集上训练。 所有权重均从零均值高斯分布初始化,标准偏差为0.02。 使用Adam优化器对模型进行训练,初始学习率为1e-3,β1为0.5,而学习率每25个周期减少0.8倍。
7.Mode Regularized GAN (MRGAN)
MRGAN提出了度量正则化以惩罚丢失模式[114],然后将其用于解决模式崩溃问题。 这项工作背后的关键思想是使用编码器E(x):x→z产生G的潜变量z而不是使用噪声。 该过程有两个好处:(1)编码器重构可以向G添加更多信息,因此D很难区分生成的样本和真实样本。 (2)编码器确保x和z(E(x))之间的对应关系,这意味着G可以覆盖x空间中的不同模式。 这样可以避免模式崩溃的问题。 该模式正则GAN的损失函数为
![]()
其中d是一种几何度量,可以从许多选项中选择,如像素级的![]() 和提取特征的距离。作者评价了包括模式正则化在MNIST, CelebA(64*64)数据集上的性能。
和提取特征的距离。作者评价了包括模式正则化在MNIST, CelebA(64*64)数据集上的性能。
8.Geometric GAN
使用SVM分离超平面提出了Geometric GAN [115],它在两个类别之间具有最大的空白。 图26展示了基于SVM超平面的判别器和生成器的更新规则。
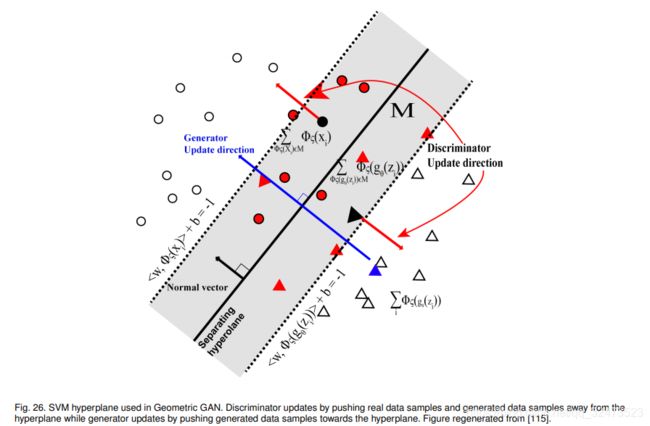
Geometric GAN的损失函数可以通过使hinge loss最小
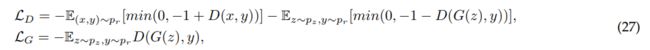
这种hinge loss方式也部署在第4.11节中提到的SAGAN和第4.12节中提到的BigGAN中,与其他损失函数相比,作者证明了hinge loss在处理高维低样本量(HDLSS)问题[116]-[118]的功效。这是由小批量大小引起的分类问题,它比特征空间的尺寸小得多。 本文中,基于软边界SVM线性分类器而不是硬边界SVM线性分类器设计Geometric GAN。
对网络在MNIST(64×64分辨率),CelebA(64×64分辨率)和LSUN(64×64分辨率)数据集上进行了训练。 通过使用RMSprop优化器以学习速率2e-4和最小批处理大小64训练的DCGAN体系结构已部署在这项工作中。 作者证明,Geometric GAN对训练更稳定,并且不易发生模式崩溃。
9.Relativistic GAN (RGAN)
RGAN[64]是在现有代价函数的基础上设计新的代价函数的一种通用方法,如它可以推广到所有的积分概率度量(IPM) [119], [120] GANs。原始GAN中的判别器测量给定的真实样本或生成样本的概率。作者认为,原始GAN中缺少真实数据和生成数据之间的关键相对判别信息。RGAN中的判别器考虑到一个给定的真实样本如何比一个给定的随机生成的样本更真实。RGAN应用于原始GAN的损失函数表示为

其中C(x)是非变换层。 图27展示了与原始GAN相比,使用RGAN方法对D的影响。

对于最初的GAN,优化的目标是将D(x)推到1(右图)。对于RGAN,优化的目标是将D(x)推到0.5(左图),这比原来的GAN更稳定。作者还声称,如果损失函数属于IPMs,则RGAN可以推广到其他类型的损失变体GANs。泛化损失表述为

其中f1(y) = g2(y) =-y, f2(y) = g1(y) = y。其他GANs的损失概化细节参考原始文献[64]。
作者在CIFAR-10和CAT数据集上使用不同大小的图像(64*64、128*128和256*256)训练网络。使用了带有Adam优化器的DCGAN体系结构。我们已经探索了各种训练设置,更多的细节可以参考原始文献[64]。作者成功地证明了相对性的判别器提供了一种修正和改进标准GAN的方法,并能够通过光谱归一化、梯度惩罚等其他手段获得更好的性能。更重要的是,作者论证了这种方法的可生成性,在这种方法中,任何类型的GAN都可以通过RGAN方式进行训练。
10.Spectral normalization GAN (SN-GAN)
SN-GAN[98]提出使用权值归一化来更稳定地训练判别器。这种技术计算量很轻,很容易应用于现有的GAN。以往关于稳定GANs[57],[104],[112]训练的工作强调了D应该来自K-Lipshitz连续函数集的重要性。一般来说,Lipschitz连续性[121][123]比连续性更严格,它描述了函数不快速变化。这种平滑的D有助于稳定GAN的训练。前面提到的工作主要集中在对判别器函数的Lipschitz常数的控制上。这一工作证明了一种更简单的控制Lipschitz常数的方法,通过对每一层的光谱归一化来实现。光谱归一化方法为

其中W代表D在每一层上的权值,σ(W)是W的L2矩阵范数,本文证明这将使 。本文还证明了σ(W)的快速近似。
。本文还证明了σ(W)的快速近似。
作者在CIFAR-10(32*32分辨率)、STL-10(48*48分辨率)[124]和ImageNet(128*128分辨率)上评估SN-GAN性能,通过比较现有的正规化、归一化技术包括weight clipping [104], gradient penalty [5], batch normalization [125], weight normalization [126], layer normalization [127] and orthonormal regularization [128]。为了全面比较,已经进行了几次训练设置。与之前提出的方法相比,作者证明了光谱归一化对生成图像的多样性和质量的有效性。
11.RealnessGAN
目前,GANs中的判别器只能输出0和1即real和fake,而不能用连续分布来衡量真伪。Xiangli等人[129]提出了RealnessGAN来处理这个新视角,它将真实性视为一个可以从多个角度估计的随机变量。传统的GAN采用单个标量(判别器输出)作为真实度的度量。作者认为,在图像的情况下,真实是更复杂的,包括多种因素,如纹理和整体配置。根据这个观察,判别器被重新设计来学习一个真实分布,而不是一个单一的标量。为了实现这一点,RealnessGAN用一个分布prealness代替单个标量,使![]() 由输入样本给出,其中
由输入样本给出,其中 是
是![]() 结果的集合,每个结果u可以被看作是一个潜在的真实度衡量标准所选择的真实度。在原论文中,对于这N个结果= {u0, u1,···,uN 1},判别器返回N个概率:
结果的集合,每个结果u可以被看作是一个潜在的真实度衡量标准所选择的真实度。在原论文中,对于这N个结果= {u0, u1,···,uN 1},判别器返回N个概率:

其中![]() 是D的参数,除结果
是D的参数,除结果 外,还定义了两个分布A1 (real)和A0 (fake)。在实际实现中,给定一个mini-batch
外,还定义了两个分布A1 (real)和A0 (fake)。在实际实现中,给定一个mini-batch ![]() 例如,判别器分对数计算的第i个结果,一个高斯分布
例如,判别器分对数计算的第i个结果,一个高斯分布![]() 是安装在
是安装在![]() 和重新计算新的分对数
和重新计算新的分对数![]() ;(这里没太看懂)增加的结果数量将使D更加严格,对G的限制也更多。换句话说,对于更复杂的数据集,建议使用更多的结果数量。最小损失最终可以表示为
;(这里没太看懂)增加的结果数量将使D更加严格,对G的限制也更多。换句话说,对于更复杂的数据集,建议使用更多的结果数量。最小损失最终可以表示为
![]()
作者使用Adam优化器对RealnessGAN在CIFAR10和CelebA上进行的训练。RealnessGAN的网络架构与带有![]() 的DCGAN架构相同。G采用批量归一化,D采用光谱归一化。CelebA数据集结果数设置为51个,CIFAR10数据集结果数设置为3个。
的DCGAN架构相同。G采用批量归一化,D采用光谱归一化。CelebA数据集结果数设置为51个,CIFAR10数据集结果数设置为3个。
12.Sphere GAN
Sphere GAN[130]是一种新的基于积分概率度量(IPM)的GAN,它利用超球将IPMs绑定在目标函数中,从而使训练稳定。通过几何矩匹配利用数据的高阶统计信息,GAN模型可以提供更准确的结果。Sphere GAN的目标函数定义为
![]()
对于r = 1 , · · · , R 其中的函数![]() 用来衡量第r时刻每个样本和超球面的北极N.的距离,注意下标s表明
用来衡量第r时刻每个样本和超球面的北极N.的距离,注意下标s表明![]() 是在
是在![]() 上定义的。不同于基于Wesserstein距离需要Lipschitz约束传统判别器,这迫使判别器属于1-Lipschitz函数。Sphere GAN通过在超球体上定义IPMs来缓解约束。图28显示了Sphere GAN的流程。
上定义的。不同于基于Wesserstein距离需要Lipschitz约束传统判别器,这迫使判别器属于1-Lipschitz函数。Sphere GAN通过在超球体上定义IPMs来缓解约束。图28显示了Sphere GAN的流程。

与传统方法(如WGAN-GP、WGAN-CT和WGANL)不同,sphere GAN不需要任何额外的约束来迫使判别器位于所需的函数空间中。通过几何变换,球面GAN保证了距离函数在一个期望的函数空间中,没有附加的约束项。
13.Self-supervised GAN (SS-GAN)
尽管有条件的GAN在自然图像合成中取得了巨大的成功。条件式gan的主要缺点是需要标记数据。自我监督GANs[131]利用对抗训练和自我监督来弥合条件和无条件GANs之间的差距。
这项工作给判别器注入了一种机制来学习有用的表示,而不依赖于当前发生器的质量。在一种自我监督的方式下,他们训练了一个预测旋转角度的模型来从产生的网络中提取表征,然后提出在判别器中添加一个自我监督的任务(基于旋转的损失)

其中V (G, D)是原始值函数[1],![]() 是从一组可能的旋转中选择的旋转(r ={0,90,180,270})。图像x旋转r度表示为
是从一组可能的旋转中选择的旋转(r ={0,90,180,270})。图像x旋转r度表示为![]() ,
, ![]() 为判别器对样本旋转角度的预测分布。其实现技巧是利用最后一层判别器的输出加上线性层来预测旋转类型。本工作试图通过学习旋转信息,使判别器学习到良好的表示。
为判别器对样本旋转角度的预测分布。其实现技巧是利用最后一层判别器的输出加上线性层来预测旋转类型。本工作试图通过学习旋转信息,使判别器学习到良好的表示。
14.Summary
我们解释了原始GAN中的训练问题(G的模式崩溃和消失梯度),并在文献中引入loss变体GAN,主要是为了从三个关键方面改进GAN的性能。图29说明了本节中讨论的loss变体的发展。

图30总结了loss-variant GANs应对挑战的有效性。定量结果的更多细节见第7节。LSGAN、RGAN和WGAN的loss与原始GAN的loss非常相似。我们使用一个玩具样例(即图19中使用的两个分布)来演示图31中真实数据分布与生成数据分布之间距离的G损失。可见,在对判别器进行优化时,RGAN和WGAN天生就能解决生成器的消失梯度问题。相反,LSGAN对于生成器来说仍然有一个逐渐消失的梯度,但是当实际数据分布与生成的数据分布之间的距离相对较小时,它可以提供比图20中原始GAN更好的梯度。这在原始论文[106]中得到了证明,其中LSGAN更容易将生成的样本推到由判别器做出的边界。


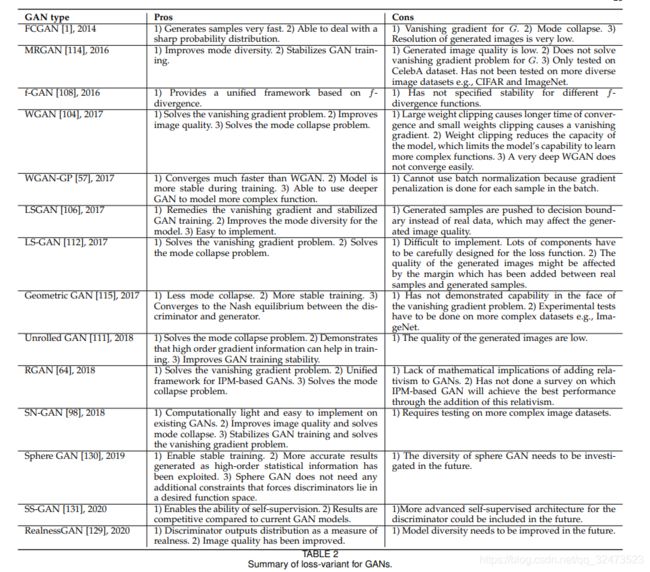
表2给出了每个GAN损失变体的详细属性。GAN,WGAN, LSGAN, LS-GAN, RGAN和SN-GAN被提出来克服G的消失梯度。LSGAN认为消失梯度主要是由判别器中的sigmoid函数引起的,所以它使用最小二乘损失来优化GAN。结果表明,LSGAN是对皮尔逊χ2散度的优化,解决了消失梯度问题。WGAN使用Wasserstein(或Earth mover)距离作为损失。与JS发散相比,Wasserstein距离更平滑,真实样本与生成样本之间的距离没有突然变化。为了能够使用Wasserstein距离作为损失,判别器必须是Lipschitz连续的(对判别器的约束,即基于IPM的),其中WGAN通过参数裁剪来强制判别器满足Lipschitz连续。但这也会导致判别器的大部分参数都位于剪切范围的边缘,从而导致判别器判别能力有所下降。提出了利用梯度罚使判别器为Lipschitz连续的WGAN- GP算法,成功地解决了WGAN算法中的问题。LS-GAN提出使用边界来强制分离真实样本和生成样本,这限制了判别器的建模能力。它解决了生成器的消失梯度问题,因为这个问题是在判别器优化时产生的。RGAN是一个统一的框架,适用于所有基于IPM的GAN,例如WGAN。RGAN为GANs添加了判别信息,以便更好地学习。SN-GAN提出了一种优化GAN的优雅方式。如前所述,Lipschitz连续判别器对于稳定学习、梯度消失等是很重要的。SN-GAN提出了光谱归一化[69]来约束在Lipschitz连续要求下的判别器。SN-GAN是第一个已经成功应用于ImageNet数据集的GAN(我们不认为AC-GANs是[11],因为ImageNet数据集使用了100个AC-GANs[92])。理论上,光谱归一化可以应用于所有GAN类型。SAGAN和BigGAN[95],[97]都利用ImageNet进行了光谱归一化,取得了很好的效果。
损失变体GANs可以应用于架构变体。然而,SN-GAN和RGAN与其他损失变体相比显示出更强的泛化能力,这两种损失变体可以被其他类型的损失变体部署。光谱归一化可应用于任何GAN变体[98],而RGAN概念可应用于任何基于ipm的GAN[64]。我们强烈建议在这里描述的所有GANs应用中使用光谱标准化。文中提出的几种损失变体GANs能够解决模式崩溃和不稳定训练问题。详情见表2。
APPLICATIONS
1.Data Augmentation
无监督学习方法的一个著名应用是数据增强。在现实中,有三种情况下要求数据增强:(1)训练一个又大又深的神经网络,但带标签的数据非常有限,(2)当前数据缺乏变化如不包括各种光照和外观变化,和(3)访问数据库是严格限制例如,数据库包含敏感信息。前两种情况可以有替代的解决方案,而不使用无监督的方式,但它们将花费大量额外的时间,并需要大量的人员参与,例如收集数据和标签数据。GANs是帮助我们增加数据的可靠方法。半监督GAN (SGAN)[28]提供了这样一种GAN架构,能够自动生成带注释的图像,这可以作为缺乏训练数据的情况的解决方案。第二种情况在现实世界中可能更为广泛。大量的心理学或神经科学实验需要广泛的变分数据作为刺激。例如,人类的EEG对不同类型的人脸图像非常敏感,如笑脸和悲伤的脸[132]。在传统的心理学和神经科学实验中,研究者需要花费大量的时间来准备刺激。基于风格的人脸图像生成器[30]可以产生不同类型的人脸图像作为刺激。更重要的是,这些生成的图像可以根据不同程度的变化如不同的快乐程度生成,这可以用于实验的定量研究。幸运的是,我们兴奋地看到神经科学领域的研究人员开始部署GANs来产生实验的刺激,如Wang等人[60][61]使用GANs生成不同类型的面孔,研究EEG实验中的P300成分[133],如图32所示。

相比前两个视角,可以不用无监督的方式解决,最后一个方面没有一个无需借助无监督学习方法的解决方案,这给一些研究施加了很大难度,如脑电图癫痫发作检测,因为隐私问题,癫痫发作脑电图的数据只能被很少研究人员获取。得益于GANs的数据生成,现在可以合成那些敏感数据。我们已经看到一些研究者将GANs应用于这些领域[20],[23],[134]。看到一些研究领域可以从深度学习研究中受益,这是令人兴奋的。图33是真实心电图的例子(红色)和GANs生成的合成心电图(蓝色),可以看出生成的心电图与真实心电图非常相似。

2.Image Synthesis
图像合成是目前研究的一个主要领域,已经提出了许多GAN变体。在本节中,我们将所有与图像相关的应用分类在图像合成类别下,如图像超分辨率,图像到图像转换和图像抠图。
图像超分辨率 图像超分辨率图像通过上采样从低分辨率图像生成高分辨率图像。SRGAN[42]是利用GANs实现图像超分辨率的代表性框架。除了GANs中一般的对抗性损失外,SRGAN还通过在超分辨率区域添加内容损失(例如,像素级的MSE损失)来扩展这种损失,这将导致如下所示的感知损失
![]()
其中![]() 为内容损失,
为内容损失,![]() 为GAN损失。在实践中,内容损失
为GAN损失。在实践中,内容损失![]() 是根据应用选择的。SRGAN提出了三种内容损失(1)标准像素级MSE损失
是根据应用选择的。SRGAN提出了三种内容损失(1)标准像素级MSE损失 ,(2)在代表低级特征的特征映射上定义的损失
,(2)在代表低级特征的特征映射上定义的损失![]() ,(3)在代表高级特征的特征映射上定义的损失
,(3)在代表高级特征的特征映射上定义的损失![]() 。作者指出,不同的内容损失根据不同的评价指标表现不同。SRGAN中的发生器是由低分辨率图像调节的,这是由4个放大因子推断出来的。与传统方法相比,SRGAN方法具有更好的感知性能。
。作者指出,不同的内容损失根据不同的评价指标表现不同。SRGAN中的发生器是由低分辨率图像调节的,这是由4个放大因子推断出来的。与传统方法相比,SRGAN方法具有更好的感知性能。
图像补全/修复 图像补全/修复是一种常见的图像编辑操作,其目的是用合成的内容填充图像中的缺失或掩蔽区域。传统补全算法效率最高的算法[135],[136]依赖于低级线索,低级线索用于从同一幅图像的已知区域中搜索patch,并合成局部出现与匹配patch相似的内容。这些方法可以很好地完成背景补全,因为来自背景的模式彼此相似。在某些情况下,缺失的部分与图像中其他部分是相似的这种假设可能会不成立,例如,为一个面部图像填充缺失的部分,其中许多物体都有独特的模式。Li等人提出[50]使用与GANs结合的自动编码器。网络架构如图所示。

采用DG和DL两种判别器(一种用于全局图像内容,另一种用于局部图像内容),利用两种对抗性损失进行优化。总损失函数表示为![]() ,其中Lr为自动编码器输出与原始图像之间的L2距离,LDG和LDL为DG和DL的对抗性损失,Lp为解析网络[137],[138]的像素级softmax。λ1、λ2、λ3为控制不同loss引起的影响的超参数。图35显示了使用原始论文中的CelebA数据集完成的结果。
,其中Lr为自动编码器输出与原始图像之间的L2距离,LDG和LDL为DG和DL的对抗性损失,Lp为解析网络[137],[138]的像素级softmax。λ1、λ2、λ3为控制不同loss引起的影响的超参数。图35显示了使用原始论文中的CelebA数据集完成的结果。
图像抠图 自然图像抠图的定义是准确估计图像或视频流中前景对象的不透明度[139]。这一领域的应用越来越广泛,如图像编辑和电影后期制作。抠图方法形式上要求输入一幅具有前景对象和图像背景的图像,其数学表达式为![]() ,其中αi是一个标量值,定义了前景像素i的不透明性,Fi是前景对象在像素i处的一个标量值,Bi是背景对象在像素i处的一个标量值。Lutz等人把GANs引入到这一领域,并提出AlphaGAN可以产生视觉上吸引人的作品。在他们的工作中,他们用真实alpha和预测alpha合成的图像训练判别器,然后用生成器生成合成。图36说明了与文献中其他方法相比AlphaGAN的性能。
,其中αi是一个标量值,定义了前景像素i的不透明性,Fi是前景对象在像素i处的一个标量值,Bi是背景对象在像素i处的一个标量值。Lutz等人把GANs引入到这一领域,并提出AlphaGAN可以产生视觉上吸引人的作品。在他们的工作中,他们用真实alpha和预测alpha合成的图像训练判别器,然后用生成器生成合成。图36说明了与文献中其他方法相比AlphaGAN的性能。

图像到图像的翻译 图像到图像的翻译是一类图形问题,其中的目标是学习输出图像与输入图像之间的映射使用一组对齐的图像对训练集。Isola等人[39]提出,当成对训练数据可用时,使用CGAN进行图像到图像的翻译。提出了CycleGAN[35]来解决未成对训练数据不可用于图像间转换的问题CycleGAN通过引入周期一致性损失来实现这一点,以强制从一个域X和另一个域Y的映射大致相同。图37显示了CycleGAN生成的一些结果,它被证明能够应用于许多图形问题。其他的工作如DiscoGAN[143]和DualGAN[144]也被提出来解决图像到图像转换领域缺少成对训练数据的问题。更多细节可以参考原始论文。
3.Video Generation
在自然图像生成方面,GANs已经取得了惊人的成果。最近的一些工作试图将这一成功带到视频生成领域[145][147]。使用GANs有效的视频生成仍然是一个重大的挑战,因为它加剧了所有与使用GANs生成图像相关的问题。此外,由于视频的3D特性和时间建模的要求,它还存在内存和计算成本增加的问题。此外,由于记忆和训练稳定性的限制,随着视频分辨率/时长的增加,生成的难度也越来越大。
我们认为目前通过GANs进行的视频生成研究的主流是:1)产生高分辨率视频,例如,高达/大于256*256;2)将生成的视频长度增加到/超过48帧,3)生成更真实的视频,使大部分生成的视频内容不模糊,不朦胧,甚至不超现实。基于GANs的视频不仅需要考虑空间建模,还需要时间建模,如视频序列中相邻帧之间的运动。MoCoGAN[145]提出以无监督的方式学习运动和内容,将图像潜空间分为内容空间和运动空间。DVDGAN[146]能够基于BigGAN架构生成更长、更高分辨率的视频,同时引入了可扩展的、视频特定的生成器和判别器架构。DVD-GAN包括两个判别器DS (spatial discriminators)和DT (temporal discriminators),其中DS从空间角度对输入帧进行评分,DT从时间角度(motion)对输入帧进行评分。
4.Feature Generation
机器能思考吗?这是Alan Turing在1950年发表的题为《计算机器与智能》的开创性论文中提出的问题。机器的最终目标是像人一样聪明。目前的人工智能依赖于大数据集,而不是从小数据集泛化,在顺序学习任务时存在灾难性的遗忘问题[149]。近年来,小样本学习和持续学习引起了科学界的广泛关注,旨在填补人工智能与人类之间的空白。这两个领域都存在数据缺乏的问题,即小样本学习每一类都使用了很少的样本(如1个或5个样本),而持续学习在连续任务中遇到了看不见的数据。Mandal等人[150]提出使用条件Wasserstein GAN加上两个额外的术语,即余弦嵌入和周期一致性损失,来合成不可见的动作特征,用于零样本动作识别。Shin等人[151]提出了一种用于持续学习的深度生成式回放框架,其中,生成器对之前任务的训练数据进行采样,并将其与新任务的训练数据交织在一起。这些表明GANs有潜在的能力为其他机器学习问题提供解决方案。
NOTES ON EVALUATION OF GANS
众所周知,在生成模型之间进行比较具有挑战性[63],文献[55]中提出了一些评价标准。一般来说,对GANs的评价主要分为两大类,分别是定性测量和定量测量。定性测量是为了从人的感知角度确定生成图像的视觉质量。最具代表性的定性测量是人工标注。 由于人为的注释方法是费时的,也就是说,这需要评估者在逐个图像的基础上产生行为反应。有几种方法已经被提出并被证明与人类注释相关,如Inception Score (IS) [3], Frechet Inception Distance (FID) [58], Neuroscore[60]。相比之下,定量指标的主观性较弱,但其表现的稳健性受到了损害。定量测量,如核最大平均差(MMD)[59],切片Wasserstein距离(SWD)[78],分类器双样本测试(C2ST)[152],可用于检测问题,如过拟合或记忆,低多样性,模式下降的GANs[55]。尽管有许多用于评估GANs的度量标准,Inception Score和FID是最广泛使用的度量标准,因为这两个度量都可以表明生成图像的质量和多样性[3]、[58]。这两个指标成为评估不同GANs性能的主要评估指标。显然,人是对生成图像的质量进行评估最可靠的。然而,在文献中缺少人类标注和评估指标之间的直接比较。我们设计了一个综合比较人类,人类的神经信号(神经评分)和评估指标,已发表于[60]。具体来说,我们在CelebA上训练了DCGAN、BEGAN和PROGAN三个GANs,选取Inception评分、MMD和FID三个评价指标进行对比,并收集12名参与者进行实验。我们有一个行为任务,记录参与者对GAN生成的每一种图像的反应,在这个任务中,参与者在看到屏幕上呈现的图像时回答“真实”或“虚假”。每种GAN的准确性如表3所示。GAN生成图像更低的准确性意味着更好的图像质量,也就是说,参与者经常相信合成的人脸是真实的。可以看出,PROGAN的表现最好,其次是begin,最后是DCGAN。表4总结了使用不同指标评估的三种GANs的不同结果。为了与其他指标保持一致(得分越小表示GAN性能越好),我们使用1/IS (1/Inception得分)来进行比较。可以看出,三种方法相互之间是一致的,它们将GANs按照PROGAN、DCGAN的顺序进行排序,并从高到低排列。通过将三种传统的评价指标与人进行比较,可以看出,这三种指标与人对GAN绩效的判断并不一致。需要指出的是,我们并不是在争论哪个指标是最好的,我们理解像Inception分数和MMD这样的指标,也考虑其他因素,如模型多样性。然而,这些指标可能不能完全解释GAN生成的图像质量。
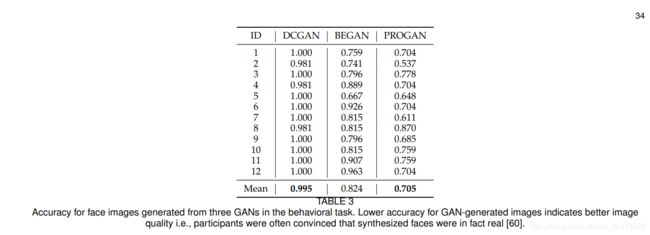
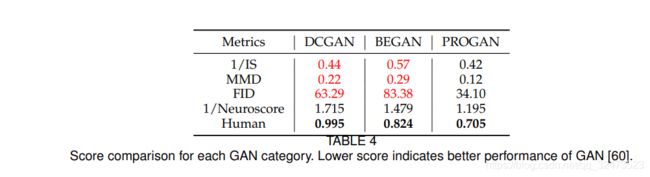
表5通过使用Inception Score和文献中的FID演示了我们在本工作中对所呈现的GANs性能的总结。本文总结了目前应用最广泛的对标数据集CIFAR10、ImageNet、LSUN和CelebA 4个图像数据集。

DISCUSSION
我们已经介绍了最初GAN设计中存在的最重要的问题,即用于更新G时的模式崩溃和消失梯度。我们已经调查了通过两个设计考虑来弥补这些问题的重要GAN变体:(1)架构变体。这个方面主要关注GANs的架构选择。这种方法使GANs能够成功地应用于不同的应用,但不能完全解决上面提到的问题;(2) Loss-variant。我们已经详细解释了为什么在原来的GAN中会出现这些问题。这些问题本质上是由原GAN中的损失函数引起的。因此,修改这个损失函数可以解决这个问题。应该注意的是,对于某些体系结构变体,损失函数可能会发生变化。然而,这个损失函数根据架构而改变,因此它是特定于架构的损失。它不能推广到其他架构。
通过比较本研究中不同的架构方法,可以清楚地看到GAN架构的修改对生成的图像质量及其多样性有显著的影响。最近的研究表明,GANs的能力和性能与网络大小和批处理大小有关[95],这表明良好的架构设计对良好的GANs性能至关重要。然而,仅仅对体系结构进行修改并不能消除GANs固有的所有训练问题。重新设计损失函数,包括正则化和归一化,可以使GANs的训练更加稳定。本文介绍了GANs损失函数设计的各种方法。基于对每种loss变体的比较,我们发现SN-GAN中首次演示的光谱归一化带来了许多好处,包括易于实现、相对较轻的计算要求和几乎所有GAN的良好工作能力。我们建议寻求将GANs应用于实际问题的研究人员将光谱归一化应用于判别器。
对于哪一种GAN是最好的这个问题,没有答案。特定GAN类型的选择取决于应用。例如,如果一个应用需要生成自然场景图像(这需要生成各种各样的图像)。应用了频谱归一化的DCGAN,SAGAN和BigGAN可以是很好的选择。与其他两位相比,BigGAN能够拍出最逼真的图像。然而,BigGAN的计算强度要大得多。因此,它依赖于实际应用设置的实际计算需求。
结构与损失之间的相互联系 :在本文中,我们强调了原文所固有的问题。为了突出后续研究人员是如何补救这些问题的,我们分别探讨了GAN设计中的结构变体和loss变体。然而,应该注意的是,这两种GAN变体之间存在着相互联系。如前所述,损失函数很容易集成到不同的体系结构中。通过重新设计的损失函数,受益于改进的收敛性和稳定性,体系结构变体能够实现更好的性能,并完成对更困难问题的解决方案。例如,BEGAN和PROGAN 用Wasserstein距离而不是JS散度。SAGAN和BigGAN采用光谱归一化,在多类图像生成的基础上实现了良好的性能。这两种类型的变体同样有助于GANs的发展。
未来方向:GANs最初被提出是为了生成可信的合成图像,并在计算机视觉领域取得了令人兴奋的性能。GANs已经被应用于其他一些领域,如时间序列生成[20],[21],[23],[157]和自然语言处理[15],[158]-[160],并取得了一些成功。与计算机视觉相比,GANs在其他领域的研究还比较有限。这种限制是由图像数据与非图像数据固有的不同属性造成的。例如,GANs的工作是生成连续值数据,但是自然语言是基于离散值(如字、字符和字节)的,因此很难将GANs应用于自然语言应用。由于这也是一个非常有前途的领域,在这一领域的成功将导致许多应用程序,如生成字幕和生成直播流的评论。如第6.1节所述,神经科学等研究领域可能存在数据隐私问题,而成功的数据扩充将对这些领域产生重大影响。然而,使用GANs生成时间序列数据等其他模态数据的研究有限,即使缺乏有效的评估指标来评估GANs在这些领域的性能。鼓励在这些领域进行更多的研究。
自2014年第一个GAN被提出以来,GANs的发展无论在研究还是在现实生活中都给我们带来了很多好处。然而,对GANs的不当使用也会给社会带来隐患,例如,GANs可以被用来为特定的人和不适当的事件生成被篡改的视频,生成对特定的人有害的图像,甚至可能影响个人安全[161]、[162]。我们还应该致力于开发伪造检测器来高效、有效地检测人工智能生成的图像(包括使用GANs)。
CONCLUSION
在这篇文章中,我们回顾了基于性能改进的GAN变体在更高的图像质量、更多样化的图像和更稳定的训练方面提供的性能改进。我们从架构和损失的基础上回顾了与GAN相关的研究的现状。批量越大,结构越复杂,图像质量越高,图像多样性越高,如:BigGAN。然而,有限的gpu内存可能是处理大批图像的一个问题,在PROGAN中使用的渐进训练策略可以在不需要非常大批图像的情况下提高图像质量。在图像多样性方面,在图像生成器和判别器中加入自注意机制取得了令人兴奋的效果,SAGAN算法已成功应用于ImageNet。在稳定训练方面,损失函数在这里起着重要作用,不同类型的损失函数被提出来处理这一观点。通过对不同类型的损失函数的分析,发现谱归一化具有较好的泛化性,可适用于各种GAN,易于实现,计算代价很低。目前最先进的GANs模型如BigGAN和PROGAN能够在计算机视觉领域生成高质量的图像和多样化的图像。然而,将GANs应用于视频的研究是有限的。此外,在时间序列生成、自然语言处理等其他领域的GAN相关研究在性能和能力上都落后于计算机视觉。我们的结论是,未来在这些领域的研究和应用有明显的机会。
ACKNOWLEDGMENT
这项工作是数据分析洞察中心的一部分,该中心由爱尔兰科学基金会资助,资助编号为SFI/12/RC/2289。作者要感谢在知乎、Quora、Medium等网站上发表的博客,它们为GAN相关研究提供了翔实的见解。
APPENDIX
对文献进行了回顾,以确定描述GAN的研究工作。论文首先通过使用关键字生成对抗网络对在线数据集(谷歌Scholar和IEEE Xplore)进行手动搜索来识别。其次,人工选择了与计算机视觉相关的论文。这次搜索于2020年6月10日结束。
共识别出463篇描述与计算机视觉相关的GAN的论文。最早的论文发表于2014年[1]。论文资源库分为会议、arXiv和期刊三类。超过一半的论文是在会议上发表的(267,57.7%)。其余为期刊文章(116,25.1%)和arXiv预印本(80,17.3%)。图38、图39为搜索到的论文的详细内容。图38展示了2014年至2020年每年的论文数量

可以看出,从2014年到2019年,论文数量每年都在增加。由于我们的搜索截止到2020年6月10日,这个数字不能代表2020年的论文总数。特别是一些即将召开的顶级会议,如CVPR、NeurIPS和ICML,今年晚些时候可能会有更多的论文问世。即使在这种情况下,2020年的论文数量已经超过了2016年。可以看到,2016年和2017年的论文数量显著上升。的确,这两年我们看到了很多令人兴奋的研究,例如2016年的CoGAN、f-GAN和2017年的WGAN、PROGAN,推动了GANs研究,并将GANs公之于众。2018年,GANs仍然吸引了大量的关注,论文数量也比往年多。
图39显示了在三个知识库上发表的论文数量,即conference、arXiv和journal。

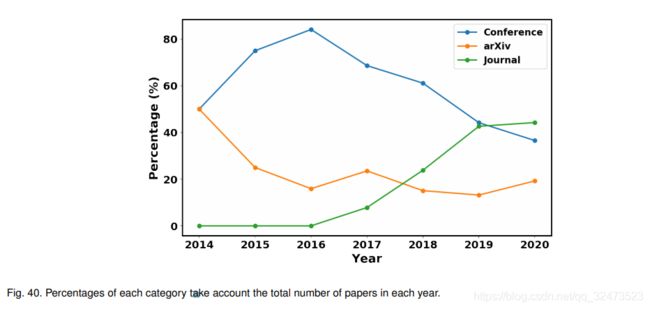
2015年至2019年的会议数量最多,2016年和2017年的会议数量显著增加。从2017年开始,期刊上发表的论文开始增加,这可能是由于期刊论文的评审时间比会议论文长,当然也比arXiv论文长得多。由于GANs在今天已经非常发达,并且为不同领域的研究人员所熟知,预计到2020年,与GANs相关的期刊论文数量将保持增长趋势。有趣的是,arXiv预印本的数量在2017年达到峰值,然后开始下降。我们推测这是由于越来越多的论文被会议和期刊接受,arXiv预印本对出版细节有要求,导致了arXiv预印本数量的减少。另一方面,这也表明近年来GANs的研究质量有所提高。图40说明了每一类别占每年论文总数的百分比。支持结果如图39所示,期刊论文数量呈上升趋势。会议论文数量的百分比在2016年达到峰值,然后开始下降。应该指出的是,这并不意味着会议论文数量的减少。这是由于其他类别(如arXiv和期刊论文)开始增加。
A detail of searched papers are listed on this link:https://github.com/sheqi/GAN_Review/blob/master/GAN_CV.csv