VGG、RestNet、MobileNet介绍
博客图片来自霹雳吧啦Wz
文章目录
- VGG网络
-
- 亮点
- 感受野
-
- 感受野计算公式
- 不同卷积核的参数大小
- RestNet
-
- Residual残差结构
- BN层
-
- 计算均值和方差
- 使用BN的注意事项
- 迁移学习方式
- MobileNet
-
- V1
- 网络亮点
- 输入特征与卷积核关系
- Depthwise Separable Conv深度可分卷积
- V2
- 网络中的亮点
- 倒残差结构
- V3
-
- 亮点
- 更新Block
-
- se模块
- 重新设计耗时层结构
-
- 重新设计激活函数
- shuffleNet
-
- v1
VGG网络
vgg网络是2014年由牛津大学提出的;

亮点
堆叠多个3 * 3卷积核,来代替大尺度卷积核,减少所需要的参数
两个3 * 3 代替一个5 * 5;三个 3* 3 代替7 *7 ;拥有相同的感受野
16是13个卷积层,以及三个全连接层
感受野

通俗解释:某个输出的Feature map上的一个单元对应输入层的区域大小就叫感受野
感受野计算公式

不同卷积核的参数大小

一个 7* 7参数为49C²,第二个c是卷积核个数,特征图深度与卷积核深度C个数是相同的;三个 3*3 参数为27C²;
输入图片224 * 224 * 3;224 * 224 *64;112 * 112 *128 ;56 * 56 *256;28 *28 *512; 14 *14 *512 ;
最后三个全连接层,以及一个soft max 层
RestNet
在2015年由微软团队提出,获得分类任务,目标检测,图像分割第一名。
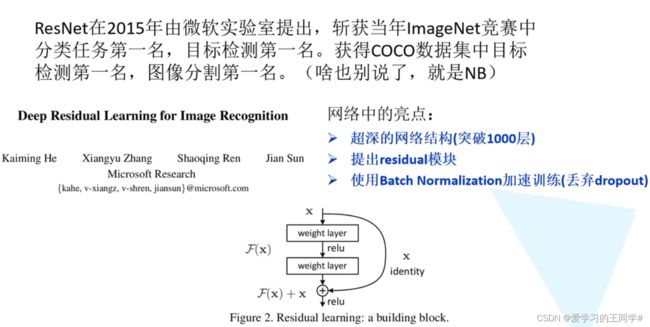
亮点:1、超深网络,超过1000层
2、提出residual
3、使用Batch normalization加速训练
网络加深的问题:
1、梯度消失或梯度爆炸
2、退化问题(层数深的没有浅的效果好)
假设每一层卷积的梯度误差是一个小于1的数,随着网络加深,反向传播是,不断乘以小于1的数,梯度就越趋于消失;梯度误差是大于1的数,网络加深,梯度趋于爆炸趋势。
Residual残差结构

左右两个结构参数个数分别为1179648(118万);69632(7万)
BN层
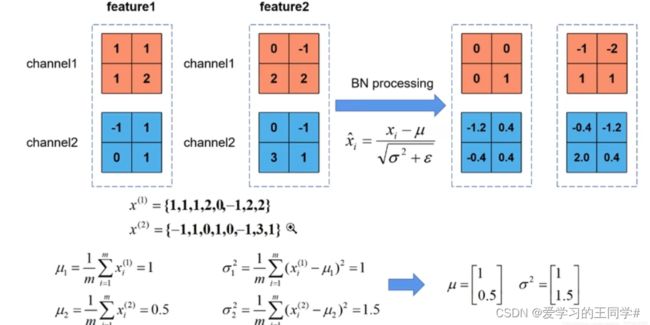
bn操作就是使feature map满足均值为0,方差为1的分布规律;
计算均值和方差

这里的均值是一个向量,不是一个值,每一个元素代表一个维度channel,所有样本的均值;方差也是一个向量,γ,β初始值为1,0;均值,方差是正向传播得到,γ,β是反向传播得到的
使用BN的注意事项

迁移学习方式

MobileNet
V1
传统卷积神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行。
MobileNet是2017年由Google提出,专注于移动端或者嵌入式设备中的轻量级CNN网络。准确率小幅缩小,大大减小模型参数与运算量。
网络亮点
1、大大减少运算量和参数数量
2、增加超参数α,β
输入特征与卷积核关系
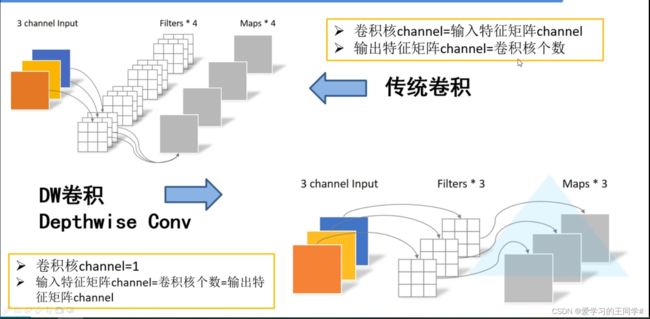
1、普通卷积:上半部分图:输入特征矩阵channel=卷积核channel
输出特征矩阵的channel = 卷积核个数
2、DW卷积:卷积核channel=1
输入特征矩阵channel =卷积核个数 =输出特征矩阵channel
Depthwise Separable Conv深度可分卷积
有两部组成:DW + PW
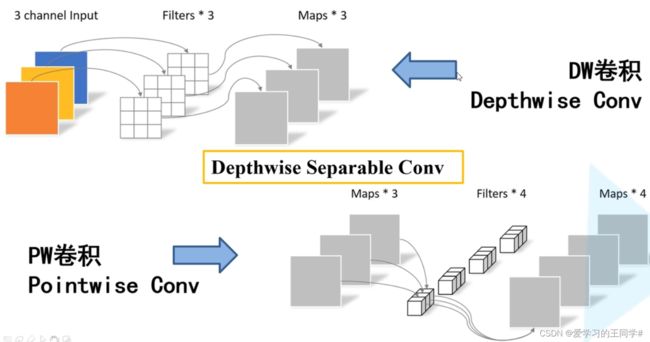
pw模式是普通卷积,但是大小为 1*1 ,深度=输入卷积深度
普通卷积操作与DW+PW,后者能节约8 - 9倍

参数α为卷积核个数的倍率,β为图片分辨率参数
DW操作部分卷积核容易废掉,卷积核参数大部分等于零。
V2
google团队2018年提出的,相比V1网络,准确率更高,模型更小
网络中的亮点
1、Inverted Residuals(倒残差结构)
2、Linear Bottlenecks
倒残差结构
resnet的传统残差结构
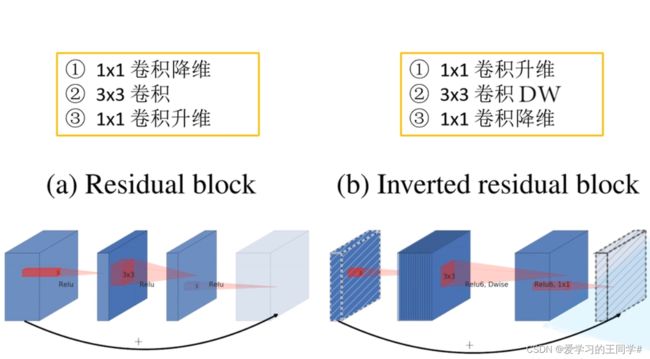
(a)1 * 1 卷积核对特征矩阵降维,3 * 3 卷积处理, 1 *1 卷积核升维,看图也可知两头大,中间小;激活函数RElu
(b)倒残差,先升维,再DW卷积,再降维,两头小,中间大;ReLU(6)
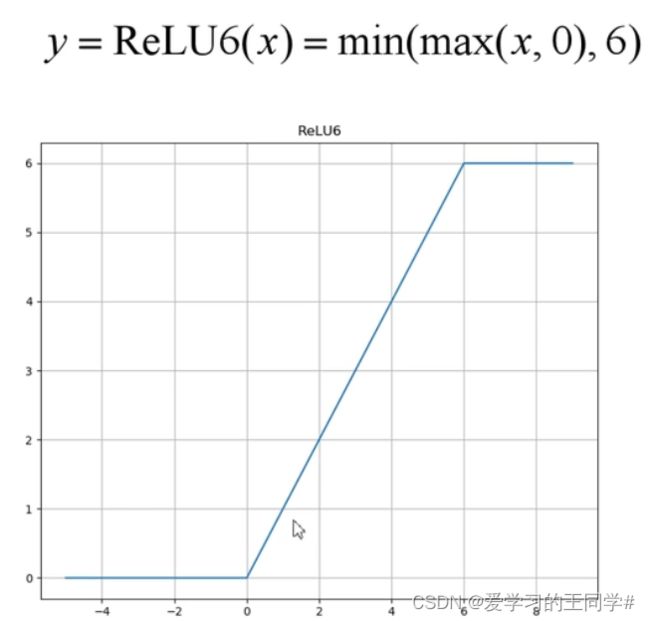
Relu激活函数对低维特征信息造成大量损失

当stride = 1且输入特征矩阵与输出特征矩阵shape相同,才有shortcut连接
V3
亮点
1、更新Block
2、使用NAS搜索参数
3、重新设计耗时层结构
更新Block
1、加入注意力SE
2、更新了激活函数

V3的block进行se操作,先进行池化,再进行两个全连接层操作
se模块

先进行平均池化操作,进行第一次全连接层,节点个数为1,使用Relu激活函数胡;
第二个全连接层节点个数与特征矩阵深度一致,使用Hard-sigmoid激活函数,
最后得到两个元素的向量,每个元素就是对于输入特征的权重,得到输出特征
重新设计耗时层结构
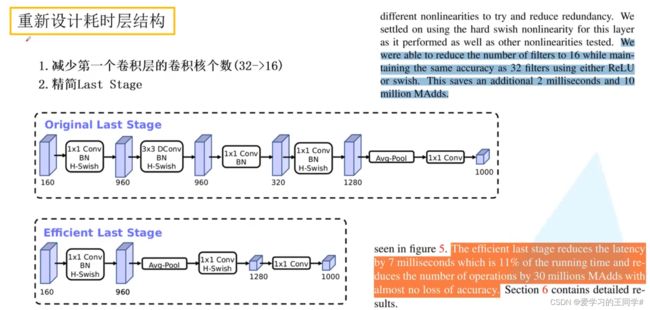
1、减少第一个卷积层的卷积核个数(32-16)
2、精简last stage
重新设计激活函数

红框是是sigmoid激活函数
设计一个h -sigmoid激活函数:及ReLU(6)+sigmoid激活函数
shuffleNet
v1
提出了channel shuffle的思想,ShuffleNet Unit中全是GConv和DWConv.
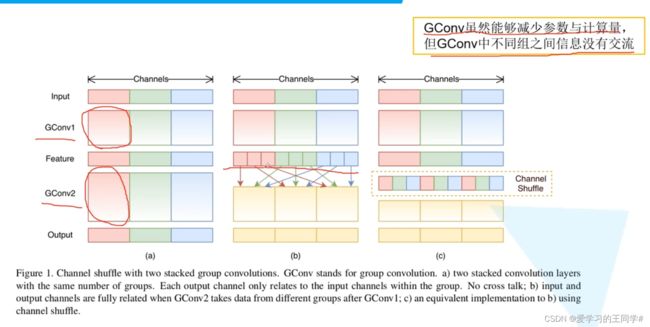
传统的逐步卷积,不同通道之间是没有交流的;
中间图是将每个channel中的第一份放一起,每个第二份放一起,每个第三份放一起,
图三就是channel shuffle(通达洗牌),融合不同channel的信息
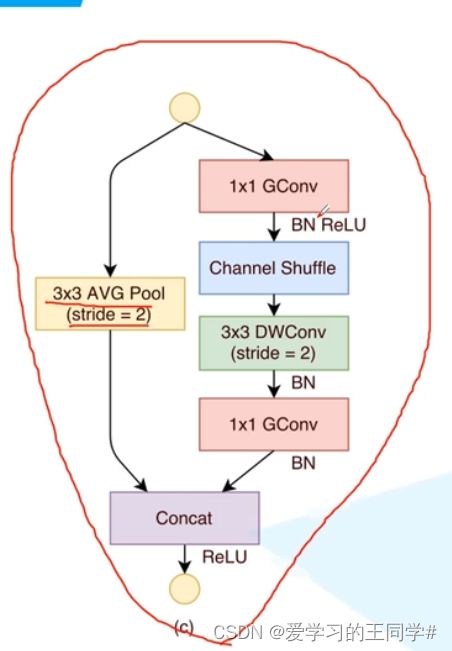
上图是block块,一个残差结构,左边3*3平均池化;右侧1 *1 gconv,channel shuffle ,3 *3DWConv, 1 * 1 GConv
最后左右两次concat,连接