知识图谱:【知识图谱问答KBQA(一)】——依存分析简介
句法分析
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析以得到句子的句法结构的处理过程。
对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。语义分析通常以句法分析的输出结果作为输入以便获得更多的指示信息。根据句法结构的表示形式不同,最常见的句法分析任务可以分为以下三种:
1.句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
2.依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系。
3.深层文法句法分析,即利用深层文法,例如词汇化树邻接文法(Lexicalized Tree Adjoining Grammar,LTAG)、词汇功能文法(Lexical Functional Grammar,LFG)、组合范畴文法(Combinatory Categorial Grammar,CCG)等,对句子进行深层的句法以及语义分析。
依存句法定义
依存句法是将句子分析成一颗依存句法树,描述出各个词语之间的依存关系。也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的。
在自然语言处理中,用词与词之间的依存关系来描述语言结构的框架称为依存语法(dependence grammar),又称从属关系语法。利用依存句法进行句法分析是自然语言理解的重要技术之一。
什么是依存分析
自然语言处理任务中,有很重要的一块,就是分析语言的结构。语言的结构,一般可以有两 种视角:
组成关系(Constituency)
主要关心的是句子是怎么构成的,词怎么组成短语。所以研究Constituency,主要是研究忽略语义的“ 语法” 结构(content-free grammars) 。
依赖关系(Dependency)
主要关心的是句子中的每一个词, 都依赖于哪个其他的词。 比如下面这个句子:
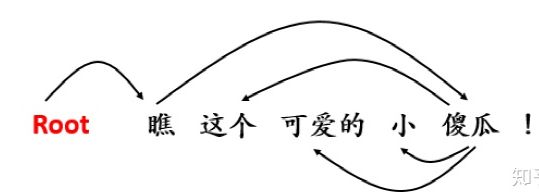
“瞧这个可爱的小傻瓜!”
- “傻瓜”,是“瞧” 这个动作的对象,因此“傻瓜”是依赖于“瞧”的;
- “可爱的”、“小” 都是修饰“傻瓜”的,因此,这两个形容词都是依赖于“ 傻瓜” 的;
- “这个”同样是指示“傻瓜”的,因此它也依赖于“傻瓜” 。
这样,我们就清楚了这个句子中的所有依赖关系,画成依赖关系图则是这样:
如何让机器自动地帮我们来分析句子的结构?
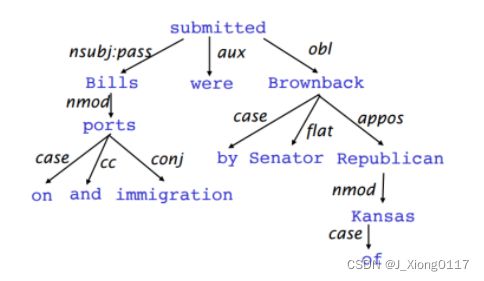
Dependency Structure展示了词语之前的依赖关系,通常用箭头表示其依存关系,有时也会在箭头上标出其具体的语法关系,如是主语还是宾语关系等。
Dependency Structure有两种表现形式:
-
一种是直接在句子上标出依存关系箭头及语法关系

-
另一种是将其做成树状机构(Dependency Tree Graph)
Dependency Parsing可以看做是给定输入句子 S=w_{0}w_{1}…w_{n} (其中w_{0}常常是fake ROOT,使得句子中每一个词都依赖于另一个节点)构建对应的Dependency Tree Graph的任务。而这个树如何构建呢?一个有效的方法是Transition-based Dependency Parsing。
传统的基于转移的依存分析(Transition-based Parsing)
这里主要介绍Nivre在2003年提出的“Greedy Deterministic Transition-based Parsing”方法,一度成为依存分析的标准方法。这里简单地介绍一下它的工作原理。
构造一个三元组,分别是Stack、Buffer和一个Dependency Set
- Stack:最开始只存放一个Root节点;
- Buffer:则装有我们需要解析的一个句子;
- Set:中则保存我们分析出来的依赖关系, 最开始是空的。
state之间的transition有三类:
- SHIFT:将buffer中的第一个词移出并放到stack上;
- LEFT-ARC:将(wj,r,wi)加入边的集合A,其中wi是stack上的次顶层的词,stack上的最顶层的词;
- RIGHT-ARC:将(wi,r,wj)加入边的集合A,其中wi是stack上的次顶层的词,stack上的最顶层的词;
要做的事情,就是不断地把Buffer中的词往Stack中推,跟Stack中的词判断是否有依 赖关系,有的话则输出到Set中,直到Buffer中的词全部推出,Stack中也仅剩一个 Root,就分析完毕了。
示例:

过程理解:
- 比方从第二行,这个时候Stack中只有[Root,I] ,不构成依赖关 系,所以我们需要从Buffer中“进货”了,因此采取的Action是Shift(把Buffer中的首 个词,移动到Stack中),于是就到了第三行。
- 第三行,我们的Stack变成了[Root,I,love] ,其中I和Love构成了依赖关系,且是Love指 向I,即“向左指”的依赖关系,因此我们将采取“Left Arc”的action,把被依赖的词(此时就是关系中的左边的词)给移除Stack,把这个关系给放入到Dependency Set中。
- 按照这样的方法,我们一直进行,不断地根据Stack和Buffer的情况,来从Shift、Left-arc、Right-arc三种动作中选择我们下一步应该怎么做,直到Stack中只剩一个Root,Buffer也空了,这个时候,分析就结束,我们就得到了最终的Dependency Set 。
神经依存分析(Neural Dependency Parsing)
神经依存分析方法,是斯坦福团队2014年的研究成果,主要就是利用了神经网络的方法代 替了传统机器学习方法、用低维分布式表示来代替传统方法的复杂的高维稀疏特征表示。而 整个解析的过程,依然是根据Transition-based方法。
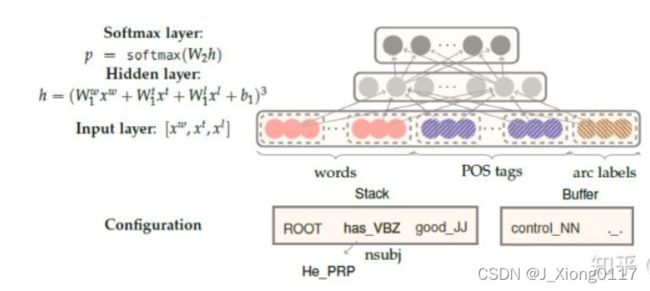
首先明确,我们的预测任务,是「根据当前的状态,即Stack、Buffer、Set的当前状态,来构建特征,然后预测出下一步的动作」。
在神经依存分析中,我们的特征是怎么构建的呢?我们可以利用的信息包括词(word)、词性(postag)和依赖关系的标签(label)。我们对这三者,都进行低维分布式表示,即通过Embedding的方法,把离散的word、label、tag都转化成低维向量表示。
对于一个状态,我们可以选取stack、Buffer、set中的某些词和关系,构成一个集合,然 后把他们所有的embedding向量都拼接起来,这样就构成了该状态的特征表示。
至于选择哪些词、关系,这个就是一个「经验性」的东西了,在斯坦福的论文中可以详细了 解。整个模型的网络结构也十分简洁:
重要概念
依存句法认为“谓语”(动词)是一个句子的中心,其他成分与动词直接或间接地产生联系。
依存句法理论中,“依存”指词与词之间支配与被支配的关系,这种关系不是对等的,这种关系具有方向。确切的说,处于支配地位的成分称之为支配者(governor,regent,head),而处于被支配地位的成分称之为从属者(modifier,subordinate,dependency)。
依存语法本身没有规定要对依存关系进行分类,但为了丰富依存结构传达的句法信息,在实际应用中,一般会给依存树的边加上不同的标记。
依存语法存在一个共同的基本假设:句法结构本质上包含词和词之间的依存(修饰)关系。一个依存关系连接两个词,分别是核心词(head)和依存词(dependent)。依存关系可以细分为不同的类型,表示两个词之间的具体句法关系。
依存分析方法
基于规则的方法
早期的基于依存语法的句法分析方法主要包括类似CYK的动态规划算法、基于约束满足的方法和确定性分析策略等。
基于统计的方法
统计自然语言处理领域也涌现出了一大批优秀的研究工作,包括生成式依存分析方法、判别式依存分析方法和确定性依存分析方法,这几类方法是数据驱动的统计依存分析中最为代表性的方法。
基于深度学习的方法
近年来,深度学习在句法分析课题上逐渐成为研究热点,主要研究工作集中在特征表示方面。传统方法的特征表示主要采用人工定义原子特征和特征组合,而深度学习则把原子特征(词、词性、类别标签)进行向量化,在利用多层神经元网络提取特征。
依存分析器的性能评价
通常使用的指标包括:无标记依存正确率(unlabeled attachment score,UAS)、带标记依存正确率(labeled attachment score, LAS)、依存正确率(dependency accuracy,DA)、根正确率(root accuracy,RA)、完全匹配率(complete match,CM)等。这些指标的具体意思如下:
- 无标记依存正确率(UAS):测试集中找到其正确支配词的词(包括没有标注支配词的根结点)所占总词数的百分比。
- 带标记依存正确率(LAS):测试集中找到其正确支配词的词,并且依存关系类型也标注正确的词(包括没有标注支配词的根结点)占总词数的百分比。
- 依存正确率(DA):测试集中找到正确支配词非根结点词占所有非根结点词总数的百分比。
- 根正确率(RA):有二种定义,一种是测试集中正确根结点的个数与句子个数的百分比。另一种是指测试集中找到正确根结点的句子数所占句子总数的百分比。
- 完全匹配率(CM):测试集中无标记依存结构完全正确的句子占句子总数的百分比。
开源句法分析工具
1.哈工大LTP:https://github.com/HIT-SCIR/ltp
2.StanfordCoreNLP:https://github.com/Lynten/stanford-corenlp
3.HanLP:https://github.com/hankcs/pyhanlp
4.SpaCy:https://github.com/explosion/spaCy
5.FudanNLP:https://github.com/FudanNLP/fnlp