libtorch 1.12.1 cuda11.3 torch1.12.1 visual stdio2019环境搭建
conda 的环境
name: torch1.12.1
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
- https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
- https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
- https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
dependencies:
- blas=1.0=mkl
- brotlipy=0.7.0=py310h2bbff1b_1002
- bzip2=1.0.8=he774522_0
- ca-certificates=2022.10.11=haa95532_0
- certifi=2022.9.24=py310haa95532_0
- cffi=1.15.1=py310h2bbff1b_0
- charset-normalizer=2.0.4=pyhd3eb1b0_0
- cryptography=38.0.1=py310h21b164f_0
- cudatoolkit=11.3.1=h59b6b97_2
- freetype=2.12.1=ha860e81_0
- idna=3.4=py310haa95532_0
- intel-openmp=2021.4.0=haa95532_3556
- jpeg=9e=h2bbff1b_0
- lerc=3.0=hd77b12b_0
- libdeflate=1.8=h2bbff1b_5
- libffi=3.4.2=hd77b12b_4
- libpng=1.6.37=h2a8f88b_0
- libtiff=4.4.0=h8a3f274_1
- libuv=1.40.0=he774522_0
- libwebp=1.2.4=h2bbff1b_0
- libwebp-base=1.2.4=h2bbff1b_0
- lz4-c=1.9.3=h2bbff1b_1
- mkl=2021.4.0=haa95532_640
- mkl-service=2.4.0=py310h2bbff1b_0
- mkl_fft=1.3.1=py310ha0764ea_0
- mkl_random=1.2.2=py310h4ed8f06_0
- numpy=1.23.3=py310h60c9a35_0
- numpy-base=1.23.3=py310h04254f7_0
- openssl=1.1.1s=h2bbff1b_0
- pillow=9.2.0=py310hdc2b20a_1
- pip=22.2.2=py310haa95532_0
- pycparser=2.21=pyhd3eb1b0_0
- pyopenssl=22.0.0=pyhd3eb1b0_0
- pysocks=1.7.1=py310haa95532_0
- python=3.10.6=hbb2ffb3_1
- pytorch=1.12.1=py3.10_cuda11.3_cudnn8_0
- pytorch-mutex=1.0=cuda
- requests=2.28.1=py310haa95532_0
- setuptools=65.5.0=py310haa95532_0
- six=1.16.0=pyhd3eb1b0_1
- sqlite=3.39.3=h2bbff1b_0
- tk=8.6.12=h2bbff1b_0
- torchaudio=0.12.1=py310_cu113
- torchvision=0.13.1=py310_cu113
- typing_extensions=4.3.0=py310haa95532_0
- tzdata=2022f=h04d1e81_0
- urllib3=1.26.12=py310haa95532_0
- vc=14.2=h21ff451_1
- vs2015_runtime=14.27.29016=h5e58377_2
- wheel=0.37.1=pyhd3eb1b0_0
- win_inet_pton=1.1.0=py310haa95532_0
- wincertstore=0.2=py310haa95532_2
- xz=5.2.6=h8cc25b3_0
- zlib=1.2.13=h8cc25b3_0
- zstd=1.5.2=h19a0ad4_0
- pip:
- absl-py==1.3.0
- albumentations==1.3.0
- cachetools==5.2.0
- colorama==0.4.6
- contourpy==1.0.6
- cycler==0.11.0
- ensemble-boxes==1.0.9
- ffmpeg==1.4
- fonttools==4.38.0
- google-auth==2.14.1
- google-auth-oauthlib==0.4.6
- grpcio==1.50.0
- imageio==2.22.4
- joblib==1.2.0
- kiwisolver==1.4.4
- llvmlite==0.39.1
- markdown==3.4.1
- markupsafe==2.1.1
- matplotlib==3.6.2
- networkx==2.8.8
- numba==0.56.4
- oauthlib==3.2.2
- opencv-contrib-python==4.6.0.66
- opencv-python==4.5.5.64
- opencv-python-headless==4.6.0.66
- packaging==21.3
- pandas==1.5.1
- protobuf==3.20.3
- pyasn1==0.4.8
- pyasn1-modules==0.2.8
- pyparsing==3.0.9
- python-dateutil==2.8.2
- pytz==2022.6
- pywavelets==1.4.1
- pyyaml==6.0
- qudida==0.0.4
- requests-oauthlib==1.3.1
- rsa==4.9
- scikit-image==0.19.3
- scikit-learn==1.1.3
- scipy==1.9.3
- seaborn==0.12.1
- tensorboard==2.11.0
- tensorboard-data-server==0.6.1
- tensorboard-plugin-wit==1.8.1
- thop==0.1.1-2209072238
- threadpoolctl==3.1.0
- tifffile==2022.10.10
- tqdm==4.64.1
- werkzeug==2.2.2
prefix: C:\Users\20169\.conda\envs\torch1.12.1
cuda环境

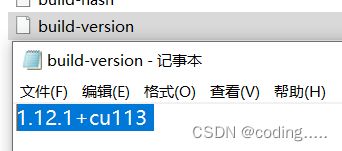
libtorch包 release版本的
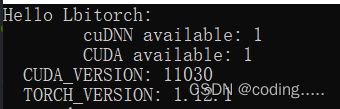
void test_libtorch_version() {
std::cout << "Hello Lbitorch:" << std::endl;
std::cout << " cuDNN available: " << torch::cuda::cudnn_is_available() << std::endl;
std::cout << " CUDA available: " << torch::cuda::is_available() << std::endl;
std::cout << " CUDA_VERSION: " << CUDA_VERSION << std::endl;
std::cout << " TORCH_VERSION: " << TORCH_VERSION << std::endl;
}
visual stdio2019配置
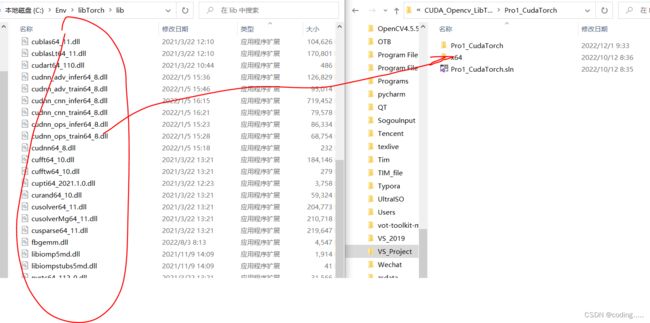
dll库拷贝到 x64/release里面
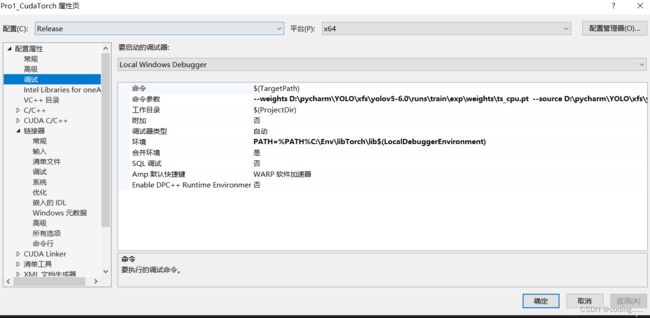
命令参数可以忽略
环境:
PATH=%PATH%
C:\Env\libTorch\lib
VC++目录
包含目录
C:\Env\opencv\buildCuda\install\include
C:\Env\opencv\buildCuda\install\include\opencv2
C:\Env\libtorch\include\torch\csrc\api\include
C:\Env\libtorch\lib
C:\Env\libtorch\include
C:\Env\linearAlgebra\eigen-3.4.0 #这个libtorch用不到可以忽略
库目录:
C:\Env\opencv\buildCuda\install\x64\vc16\lib
C:\Env\libtorch\lib

C/C++附加包含目录
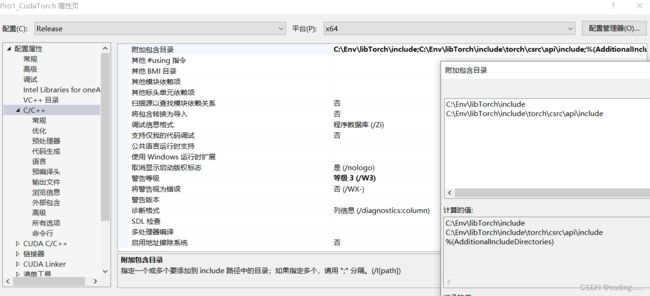
C:\Env\libTorch\include
C:\Env\libTorch\include\torch\csrc\api\include
语言
链接器 —附加库目录

C:\Env\libTorch\lib
附加依赖项
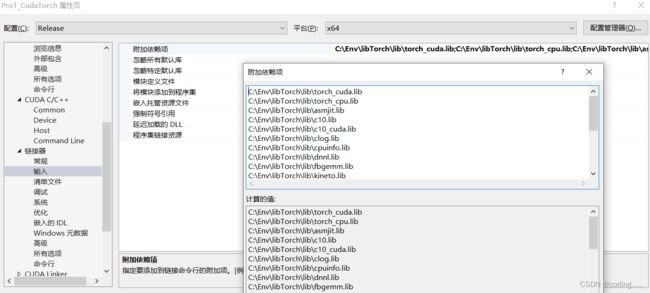
C:\Env\libTorch\lib\torch_cuda.lib
C:\Env\libTorch\lib\torch_cpu.lib
C:\Env\libTorch\lib\asmjit.lib
C:\Env\libTorch\lib\c10.lib
C:\Env\libTorch\lib\c10_cuda.lib
C:\Env\libTorch\lib\clog.lib
C:\Env\libTorch\lib\cpuinfo.lib
C:\Env\libTorch\lib\dnnl.lib
C:\Env\libTorch\lib\fbgemm.lib
C:\Env\libTorch\lib\kineto.lib
C:\Env\libTorch\lib\libprotobuf.lib
C:\Env\libTorch\lib\torch.lib
C:\Env\libTorch\lib\torch_cuda_cpp.lib
C:\Env\libTorch\lib\torch_cuda_cu.lib
C:\Env\libTorch\lib\pthreadpool.lib
C:\Env\libTorch\lib\libprotobuf-lite.lib
C:\Env\libTorch\lib\caffe2_nvrtc.lib
C:\Env\libTorch\lib\XNNPACK.lib
opencv_world460.lib
命令行

/INCLUDE:?warp_size@cuda@at@@YAHXZ /INCLUDE:?_torch_cuda_cu_linker_symbol_op_cuda@native@at@@YA?AVTensor@2@AEBV32@@Z
C++代码
#include
python部分:
yolov5—> export.py
# YOLOv5 by Ultralytics, GPL-3.0 license
"""
Export a YOLOv5 PyTorch model to TorchScript, ONNX, CoreML, TensorFlow (saved_model, pb, TFLite, TF.js,) formats
TensorFlow exports authored by https://github.com/zldrobit
Usage:
$ python path/to/export.py --weights yolov5s.pt --include torchscript onnx coreml saved_model pb tflite tfjs
Inference:
$ python path/to/detect.py --weights yolov5s.pt
yolov5s.onnx (must export with --dynamic)
yolov5s_saved_model
yolov5s.pb
yolov5s.tflite
TensorFlow.js:
$ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
$ npm install
$ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
$ npm start
"""
import argparse
import os
import subprocess
import sys
import time
from pathlib import Path
import torch
import torch.nn as nn
from torch.jit import ScriptModule
from torch.utils.mobile_optimizer import optimize_for_mobile
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import Conv
from models.experimental import attempt_load
from models.yolo import Detect
from utils.activations import SiLU
from utils.datasets import LoadImages
from utils.general import colorstr, check_dataset, check_img_size, check_requirements, file_size, print_args, \
set_logging, url2file
from utils.torch_utils import select_device
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
try:
print(f'\n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript.pt')
ts = torch.jit.trace(model, im, strict=False)
(optimize_for_mobile(ts) if optimize else ts).save(f)
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'{prefix} export failure: {e}')
def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
try:
check_requirements(('onnx',))
import onnx
print(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
torch.onnx.export(model, im, f, verbose=False, opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# print(onnx.helper.printable_graph(model_onnx.graph)) # print
# Simplify
if simplify:
try:
check_requirements(('onnx-simplifier',))
import onnxsim
print(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=dynamic,
input_shapes={'images': list(im.shape)} if dynamic else None)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
print(f'{prefix} simplifier failure: {e}')
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
print(f"{prefix} run --dynamic ONNX model inference with: 'python detect.py --weights {f}'")
except Exception as e:
print(f'{prefix} export failure: {e}')
def export_coreml(model, im, file, prefix=colorstr('CoreML:')):
# YOLOv5 CoreML export
ct_model = None
try:
check_requirements(('coremltools',))
import coremltools as ct
print(f'\n{prefix} starting export with coremltools {ct.__version__}...')
f = file.with_suffix('.mlmodel')
model.train() # CoreML exports should be placed in model.train() mode
ts = torch.jit.trace(model, im, strict=False) # TorchScript model
ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255.0, bias=[0, 0, 0])])
ct_model.save(f)
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'\n{prefix} export failure: {e}')
return ct_model
def export_saved_model(model, im, file, dynamic,
tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
conf_thres=0.25, prefix=colorstr('TensorFlow saved_model:')):
# YOLOv5 TensorFlow saved_model export
keras_model = None
try:
import tensorflow as tf
from tensorflow import keras
from models.tf import TFModel, TFDetect
print(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
f = str(file).replace('.pt', '_saved_model')
batch_size, ch, *imgsz = list(im.shape) # BCHW
tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
im = tf.zeros((batch_size, *imgsz, 3)) # BHWC order for TensorFlow
y = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
inputs = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
keras_model = keras.Model(inputs=inputs, outputs=outputs)
keras_model.trainable = False
keras_model.summary()
keras_model.save(f, save_format='tf')
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'\n{prefix} export failure: {e}')
return keras_model
def export_pb(keras_model, im, file, prefix=colorstr('TensorFlow GraphDef:')):
# YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
try:
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
print(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
f = file.with_suffix('.pb')
m = tf.function(lambda x: keras_model(x)) # full model
m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
frozen_func = convert_variables_to_constants_v2(m)
frozen_func.graph.as_graph_def()
tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'\n{prefix} export failure: {e}')
def export_tflite(keras_model, im, file, int8, data, ncalib, prefix=colorstr('TensorFlow Lite:')):
# YOLOv5 TensorFlow Lite export
try:
import tensorflow as tf
from models.tf import representative_dataset_gen
print(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
batch_size, ch, *imgsz = list(im.shape) # BCHW
f = str(file).replace('.pt', '-fp16.tflite')
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
converter.target_spec.supported_types = [tf.float16]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if int8:
dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
converter.inference_input_type = tf.uint8 # or tf.int8
converter.inference_output_type = tf.uint8 # or tf.int8
converter.experimental_new_quantizer = False
f = str(file).replace('.pt', '-int8.tflite')
tflite_model = converter.convert()
open(f, "wb").write(tflite_model)
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'\n{prefix} export failure: {e}')
def export_tfjs(keras_model, im, file, prefix=colorstr('TensorFlow.js:')):
# YOLOv5 TensorFlow.js export
try:
check_requirements(('tensorflowjs',))
import re
import tensorflowjs as tfjs
print(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
f = str(file).replace('.pt', '_web_model') # js dir
f_pb = file.with_suffix('.pb') # *.pb path
f_json = f + '/model.json' # *.json path
cmd = f"tensorflowjs_converter --input_format=tf_frozen_model " \
f"--output_node_names='Identity,Identity_1,Identity_2,Identity_3' {f_pb} {f}"
subprocess.run(cmd, shell=True)
json = open(f_json).read()
with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
subst = re.sub(
r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}}}',
r'{"outputs": {"Identity": {"name": "Identity"}, '
r'"Identity_1": {"name": "Identity_1"}, '
r'"Identity_2": {"name": "Identity_2"}, '
r'"Identity_3": {"name": "Identity_3"}}}',
json)
j.write(subst)
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'\n{prefix} export failure: {e}')
@torch.no_grad()
def run(data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
weights=ROOT / 'yolov5s.pt', # weights path
imgsz=(640, 640), # image (height, width)
batch_size=1, # batch size
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
include=('torchscript', 'onnx', 'coreml'), # include formats
half=False, # FP16 half-precision export
inplace=False, # set YOLOv5 Detect() inplace=True
train=False, # model.train() mode
optimize=False, # TorchScript: optimize for mobile
int8=False, # CoreML/TF INT8 quantization
dynamic=False, # ONNX/TF: dynamic axes
simplify=False, # ONNX: simplify model
opset=12, # ONNX: opset version
topk_per_class=100, # TF.js NMS: topk per class to keep
topk_all=100, # TF.js NMS: topk for all classes to keep
iou_thres=0.45, # TF.js NMS: IoU threshold
conf_thres=0.25 # TF.js NMS: confidence threshold
):
t = time.time()
include = [x.lower() for x in include]
tf_exports = list(x in include for x in ('saved_model', 'pb', 'tflite', 'tfjs')) # TensorFlow exports
imgsz *= 2 if len(imgsz) == 1 else 1 # expand
file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights)
# Load PyTorch model
device = select_device(device)
assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
model = attempt_load(weights, map_location=device, inplace=True, fuse=True) # load FP32 model
nc, names = model.nc, model.names # number of classes, class names
# Input
gs = int(max(model.stride)) # grid size (max stride)
imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
# Update model
if half:
im, model = im.half(), model.half() # to FP16
model.train() if train else model.eval() # training mode = no Detect() layer grid construction
for k, m in model.named_modules():
if isinstance(m, Conv): # assign export-friendly activations
if isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, Detect):
m.inplace = inplace
m.onnx_dynamic = dynamic
# m.forward = m.forward_export # assign forward (optional)
for _ in range(2):
y = model(im) # dry runs
print(f"\n{colorstr('PyTorch:')} starting from {file} ({file_size(file):.1f} MB)")
# Exports
if 'torchscript' in include:
export_torchscript(model, im, file, optimize)
if 'onnx' in include:
export_onnx(model, im, file, opset, train, dynamic, simplify)
if 'coreml' in include:
export_coreml(model, im, file)
# TensorFlow Exports
if any(tf_exports):
pb, tflite, tfjs = tf_exports[1:]
assert not (tflite and tfjs), 'TFLite and TF.js models must be exported separately, please pass only one type.'
model = export_saved_model(model, im, file, dynamic, tf_nms=tfjs, agnostic_nms=tfjs,
topk_per_class=topk_per_class, topk_all=topk_all, conf_thres=conf_thres,
iou_thres=iou_thres) # keras model
if pb or tfjs: # pb prerequisite to tfjs
export_pb(model, im, file)
if tflite:
export_tflite(model, im, file, int8=int8, data=data, ncalib=100)
if tfjs:
export_tfjs(model, im, file)
# Finish
print(f'\nExport complete ({time.time() - t:.2f}s)'
f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
f'\nVisualize with https://netron.app')
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', type=str, default=r'D:\pycharm\YOLO\xfs\yolov5-6.0\runs\train\exp\weights\best.pt', help='weights path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=13, help='ONNX: opset version')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
parser.add_argument('--include', nargs='+',
default=['torchscript'],
help='available formats are (torchscript, onnx, coreml, saved_model, pb, tflite, tfjs)')
opt = parser.parse_args()
print_args(FILE.stem, opt)
return opt
def main(opt):
set_logging()
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)