Faster Rcnn详解及代码解读
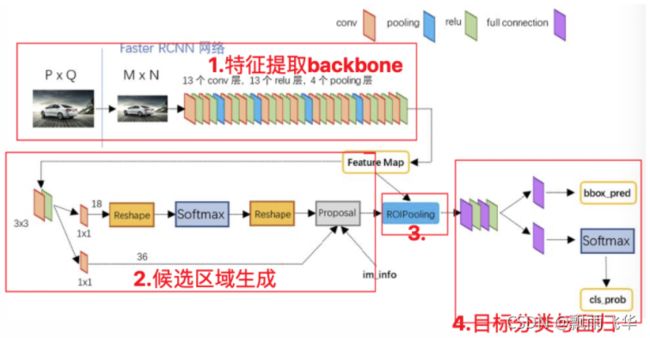
1.backbone含义
backbone用于特征提取,通常使用的是VGG16或者ResNet网络,其中要经过4个pooling层,且经过多层卷积后层数也发生了变化,但仍要保证在进行下一次池化之前,特征图深度为上一次池化之前深度的两倍。故第一个pooling层的strides=4,第二个的strides=2,第三个的pooling层的strides=2,第四个的pooling层的的strides=2,所以得到的特征图的shape分别为:[1, 304, 304, 256]、[1, 152, 152, 512]、[1, 76, 76, 1024]、[1, 38, 38, 2048]。由图可知此时获取到的是C2、C3、C4、C5层是经过池化得到的。C1层未经过池化。
C2,C3,C4,C5 = model.backbone(image,training=False)
#此处的model直接调用backbone()函数,返回为上述的4个特征图2.FPN层及特征金字塔
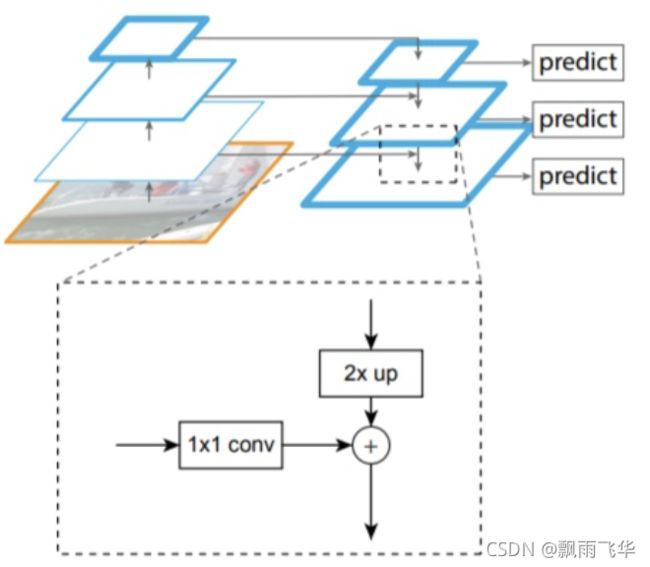
经过backbone获取到了4张特征图,为了更好的检测图像,引入FPN概念,由图可知,[1, 38, 38, 2048]的特征图经过两倍放大的上采样后,与[1, 76, 76, 1024]经过1层的kernel_size=1的卷积核进行卷积。
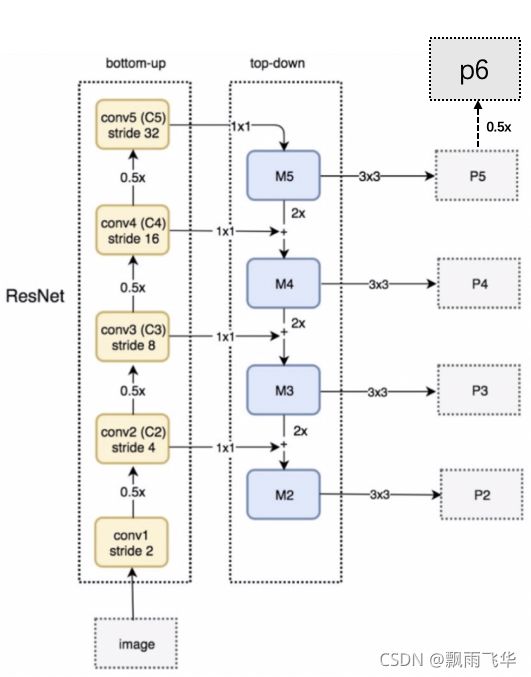
由上图可知,经过FPN层(自上而下的上采样然后与同层相加)后,会获得M5、M4、M3、M2特征图。
P2,P3,P4,P5 = model.neck([C2,C3,C4,C5],training=False)此时获得到的P2、P3、P4、P5,P6的特征图,是M2、M3、M4、M5特征图经一个3*3的卷积核得到的,且P6特征图直接由P5特征图进行下采样得到。5张特征图的shape为:[1, 304, 304, 256]、[1, 152, 152, 512]、[1, 76, 76, 1024]、[1, 38, 38, 2048]、[1, 19, 19, 256]。获得特征融合后的5张特征图
3.RPN层生成候选区域及流程详解
RPN层的主要流程:
1、生成一系列的固定参考框anchors,覆盖图像的任意位置,然后送入后续网络中进行分类和回归
2、分类分支:通过softmax分类判断anchor中是否包含目标
3、回归分支:计算目标框对于anchors的偏移量,以获得精确的候选区域
4、最后的Proposal层则负责综合含有目标的anchors和对应bbox回归偏移量获取候选区域,同时剔除太小和超出边界的候选区域。
详细流程
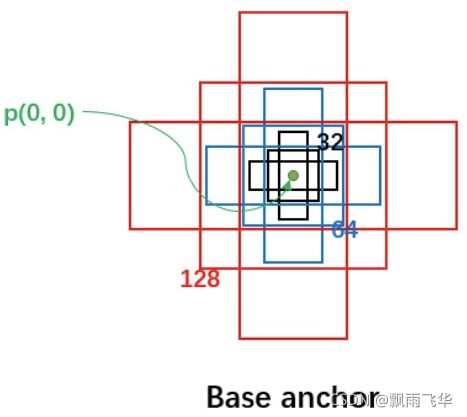
(1)anchors,多尺度、多长宽比,例如:尺度为32、64、128,长宽比为:1:1,1:2,2:1的一组anchors。一般有RPN的情况下,每个特征图上生成一个尺度,三个长宽比的anchors即3个anchors。没有RPN的情况下则生成如下图的9个anchors
故,因为使用了FPN,所以每个像素点生成3个anchors,对应于上述经FPN生成的5张特征图上生成anchors,anchors的数量为:3043043+1521523+76763+38383+19193=369303,可通过以下代码获得,其中所传参数为imagemeta是图像的元信息。此处根据generate_pyramid_anchors()函数可知,需要传递图像的元信息,通过5张特征图获取到了所有的anchors。返回的anchors为所有的anchor在原图的坐标,shape为[369303, 4]。
# 产生anchor:输入图像元信息即可,输出anchor对应于原图的坐标值
anchors,valid_flags = model.rpn_head.generator.generate_pyramid_anchors(imagemeta)可以通过visualize模块进行图像绘制,绘制在原图上的所有anchors
visualize.draw_boxes(rgd_image[0],boxes=anchors[:10000,:4])
plt.show()
(2)在5张特征图上分别都声称了anchors后,然后每张特征图再经先做一个1x1的卷积,得到[batchsize,H,W,18]的特征图,然后进行变形,将特征图转换为[batchsize,9xH,W,2]的特征图后,送入softmax中进行分类,得到分类结果(判断)后,再进行reshape最终得到[batchsize,H,W,18]大小的结果,18表示k=9个anchor是否包含目标的概率值。
举例子:P6特征图输出后的shape是[1, 19, 19, 256],此时经过下图的1*1的卷积核后,shape变为[1,19,19,18],此时经过Reshape模块,特征图的shape变为[1,9X19,9X19,2],此时可以理解为特征图的H变为了9倍,即特征图像素变为了原来的9倍。每个像素点都对应了一个anchor。之所以第四维是2,是因为经过softmax后,判断是否存在物体,给出对应的概率。然后在经过Reshape模块,特征图又变为[1,19,19,18]。此时,特征图上9X19X19个anchors均经过softmax后给出了是否存在物体的概率,例如:存在0.6,不存在:0.4,对应的anchors的坐标值都已记录下来,后映射到真实的图像上。所以此时真实图像上的anchors中是否含有物体已经判断出来了。

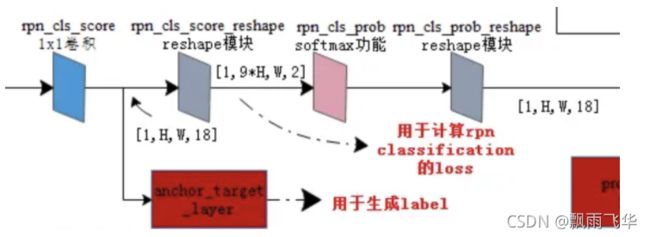
(3)由综合过程图可知,经过FPN后的模型,返回的5张不同尺寸的特征值,又经过下图中的1*1卷积,使得特征图的深度变为36,即为4x9的深度,其中9代表的是每个像素点有9个anchors,4代表的是经过回归后的尺寸变化,即[dx(A),dy(A),dw(A),dh(A)],其中d表示变化率。

该数值进行结合,求出预测的是anchor与真实值之间的平移因子和尺度因子。其中[dx(A),dy(A),dw(A),dh(A)]分别等于下图的tx、ty、tw、th,其中xa、ya、wa、ha表示anchor框的中心点x、y、w、h的值。
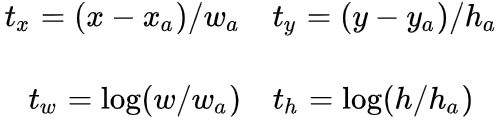
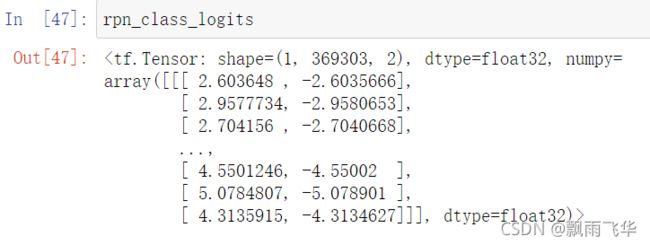
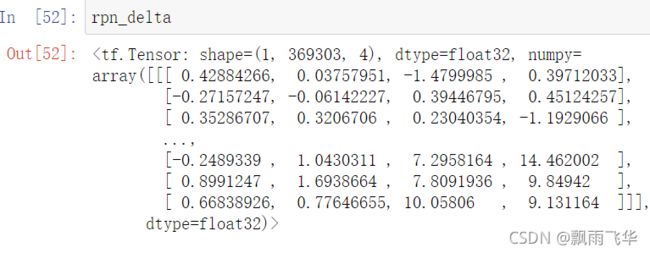
可以通过以下代码进行获取:其中model.rpn_head()出入的是特征图金字塔,返回:rpn_class_logits.shape=[1, 369303, 2]、rpn_probs.shape=[1, 369303, 2]、rpn_deltas.shape=[1, 369303, 4]
# RPN网络的输入:FPN网络获取的特征图
rpn_feature_maps = [P2,P3,P4,P5,P6]
# RPN网络预测,返回:logits送入softmax之前的分数,包含目标的概率,对框的修正结果
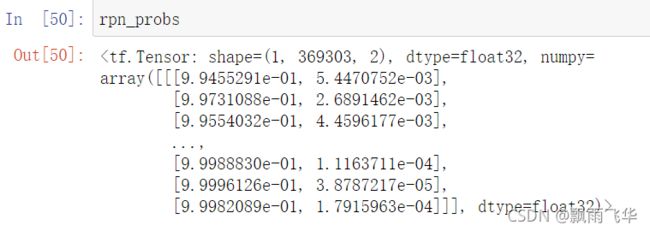
rpn_class_logits,rpn_probs,rpn_deltas = model.rpn_head(rpn_feature_maps,training = False)其中rpn_class_logits表示每个anchor进行分类处理后的分类之后结果,即样本标签。rpn_probs为经过softmax后输出的概率,同时也反映了anchor中存在检测物体的置信度,其中第一列为存在物体的置信度,第二列为不存在物体的置信度,rpn_deltas返回的是上述的[dx(A),dy(A),dw(A),dh(A)]回归后的结果
经过回归函数,此时能够获得每个anchor的置信度,我们可以通过代码,将置信度高的anchor绘制在图像上。
# 获取分类结果中包含目标的概率值
rpn_probs_tmp = rpn_probs[0,:,1]
# 获取前100个较高的anchor
limit = 100
ix = tf.nn.top_k(rpn_probs_tmp,k=limit).indices[::-1]
# 获取对应的anchor绘制图像上,那这些anchor就有很大概率生成候选区域
visualize.draw_boxes(rgd_image[0],tf.gather(anchors,ix).numpy()) 
(4)Proposal层,经过了RPN的分类和回归,我们获得了如下的信息:所有的anchors是否存在物体的置信度,及[dx(A),dy(A),dw(A),dh(A)]的平移因子和尺度因子。通过model.rpn_head()函数获得了上述的两个结果。然后图像及特征图要经过Proposal层,进行anchor的修正获得最终的候选框。
Proposal层的处理流程如下:model.rpn_head.get_proposals(rpn_probs,rpn_deltas,imagemeta)
-
利用RPN网络回归的结果
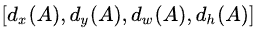 对所有的anchors进行修正,得到修正后的检测框
对所有的anchors进行修正,得到修正后的检测框 -
根据RPN网络分类的softmax输出的概率值由大到小对检测框进行排序,提取前6000个结果,即提取修正位置后的检测框
-
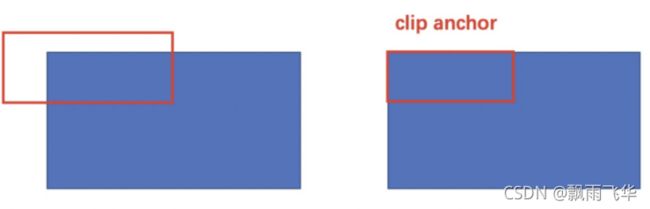
限定超出图像边界的检测框为图像边界,防止后续roi pooling时候选区域超出图像边界。
- 对剩余的检测框进行非极大值抑制NMS,即将6000个框进行极大值抑制。由下面的代码可知此时的框的个数为1533个。
- Proposal层的输出是对应输入网络图像尺度的归一化后的坐标值[x1, y1, x2, y2]。到此RPN网络的工作就结束。
代码表示:
# 获取候选区域
proposals_list = model.rpn_head.get_proposals(rpn_probs,rpn_deltas,imagemeta)
#结果
proposals_list
[] 返回的proposals_list就是经过回归处理后的候选框坐标。但是此时的坐标是经过了归一化处理了 所以绘制图像的时候 要乘以像素值1216。
visualize.draw_boxes(rgd_image[0],boxes=proposals_list[0].numpy()[:,:4]*1216)
plt.show()4.ROIPooling
RoI Pooling层则负责收集RPN网络生成的候选区域,并将其映射到特征图中并固定维度,送入后续网络中进行分类和回归。
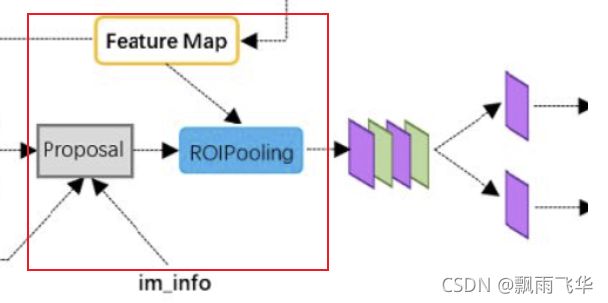
RoI Pooling 的作用过程,如下图所示:
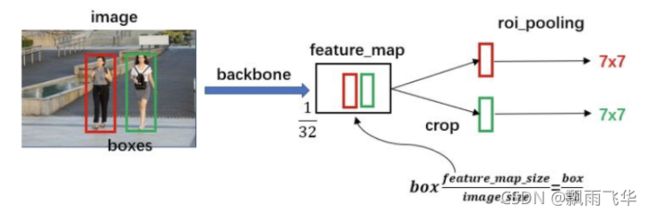
Proposal层给出了候选框,此时的候选框中存在物体,且具有1533个,且类似于抠图的操作,相当于在原图上接触1533个图片。图片的H和W各不相同。ROIPooling层的作用就是将这些不同尺寸的图片,转化为统一尺寸的pool_H和pool_W。此处的尺寸改变是通过池化的方式改变的,如下图所示,所有的候选框都转变为7*7(该参数是超参数,可以改变)的格式,且每个小格内部取最大值。
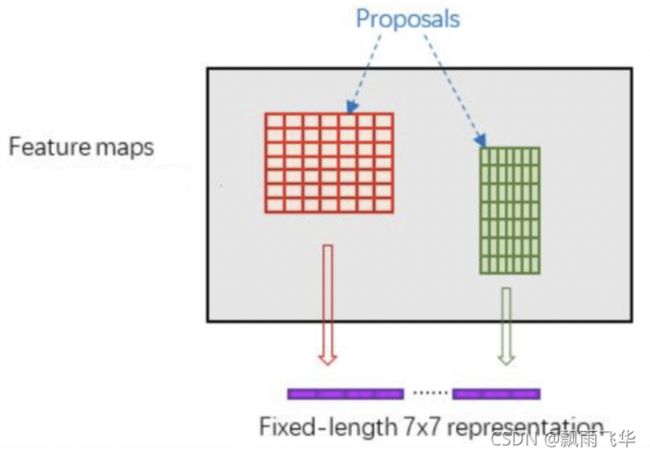
此时要思考一个问题,FPN层给出了多种尺寸的特征图,Proposal层得到了多种尺寸的候选框,请问不同尺寸的候选框分别映射到了哪个特征图上了呢?
在这里,不同尺度的ROI使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P3,我们使用下面的公式确定ROI所在的特征层:
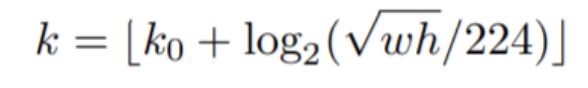
其中,224是ImageNet的标准输入,k0是基准值,设置为4,w和h是ROI区域的长和宽,假设ROI是112x112的大小,那么k = k0-1 = 4-1 = 3,意味着该ROI应该使用P3的特征层。k值会做取整处理,防止结果不是整数,而且为了保证k值在2-5之间,还会做截断处理。由此可知根据ROI候选区域的长和宽确定映射到的特征图。
# ROI Pooling层实现:输入是候选区域,特征图,图像的元信息
pool_region_list = model.roi_align((proposals_list,rcnn_feature_maps,imagemeta),training = False)
#输出结果为:每一个候选区域都被固定为7x7大小
[5.目标分类和回归
经过了ROIPooling层后,获得了统一H*W的特征图,此时经过后续的分类得到每个特征图都对应于哪个类别,该部分利用获得的候选区域的特征图,通过全连接层与softmax计算每个候选区域具体属于的类别(如人,车,电视等),输出概率值;同时再次利用回归方法获得每个候选区域的位置偏移量,用于回归更加精确的目标检测框。该部分网络结构如下所示:
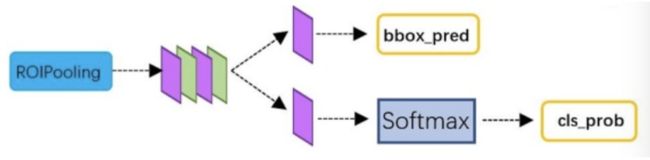
从RoI Pooling层获取到固定大小的特征图后,送入后续网络,可以看到做了如下2件事:
-
通过全连接和softmax对候选区域进行分类
-
再次对候选区域进行回归修正,获取更高精度的检测框
实现流程如下:
首先获取网络分类和回归的结果:
# RCNN网络的预测:输入是ROIPooling层的特征,输出:类别的score,类别的概率值,回归结果
rcnn_class_logits,rcnn_class_probs,rcnn_deltas_list=model.bbox_head(pool_region_list,training=False)利用结果对候选区域进行修正:
# 获取预测结果:输入:rcnn返回的分类和回归结果,候选区域,图像元信息,输出:目标检测结果detection_list = model.bbox_head.get_bboxes(rcnn_class_probs,rcnn_deltas_list,proposals_list,imagemeta)结果为:一共检测出17个目标,前四个数据为每个目标的坐标位置,第五个数据为目标类别id,第六个数据为目标类别置信度。6个值构成。此处对生成的检测框做了NMS
[] 可以将其绘制在图像上:
# 绘制在图像上
visualize.draw_boxes(rgd_image[0],boxes=detection_list[0][:,:4])
plt.show() 