目标检测 YOLO 系列: 更快更准 YOLO v2
目标检测 YOLO 系列: 更快更准 YOLO v2
- 目标检测 YOLO 系列: 开篇
- 目标检测 YOLO 系列: 开宗立派 YOLO v1
- 目标检测 YOLO 系列: 更快更准 YOLO v2
- 目标检测 YOLO 系列: 持续改进 YOLO v3
- 目标检测 YOLO 系列: 你有我有 YOLO v4
- 目标检测 YOLO 系列: 快速迭代 YOLO v5
- 目标检测 YOLO 系列:你有我无 YOLOX
作者:Joseph Redmon, Ali Farhadi
发表时间:2016
Paper 原文: YOLO9000: Better, Faster, Stronger
Joseph Redmon 等于 2016 年在 YOLO9000: Better, Faster, Stronger 中提出了 YOLO 的改进版本 YOLO V2 和 YOLO9000,其中 YOLO9000 是在 YOLO V2 的基础上采用联合训练的方式,使其可以检测超过 9000 个种类的物体的检测模型。这里重点介绍 YOLO V2。
YOLO V2 出来的时候 SSD 已经提出来了,Faster RCNN 就更早了,所以 V2 论文中以 Faster RCNN 和 SSD 作为 benchmark。
1 网络结构
首先是 backbone, V2 的 backbone 不再是 GoogLeNet v1,而是作者自己设计的一个网络,叫做 Darknet-19,这个网络的特点是网络结构小巧,但是性能表现却很不错。更多关于 Darknet-19 的介绍可以参考 CV 经典主干网络 (Backbone) 系列: Darknet-19。
先来看一下 YOLO v2 的网络结构图。如下所示。

从上图可以发现,v2 的整体结构依然清爽。和 v1 相比除了 backbone 从 GoogLeNet v1 变为了 Darknet-19 之外,还有如下两点变化:
- 网络中没有 fc 层了
- 多了一条类似 ResNet 中的 shortcut(图中红色的连接),作者表示这一操作提升了1%的成绩。

更详细的网络结构如下。v2 总共有 22 个 conv. 层,没有 fc 层。相比 v1 的 24 个 conv. ,2 个 fc 层相比, v2 网络更小,这也是为什么v2 的速度能够更快的原因。
从下表可以发现,网络的输入图片尺寸发生了变化,v1 的输入尺寸是 448x448,但是 v2 这里是 416×416,这主要是为了让网络最后得到一个奇数的 feature map(13x13)。

此外和 v1 相比 stride 变为 32(v1 为 64),可以得到更大的 feature map(13x13, v1 为 7x7),这样将有利于检测小目标。
更进一步的,以 Convolution-22 层为例,可以看到作者引入了 BN 操作。作者在论文中表示这一改进提升了2%的成绩。
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
除了上面在网络结构中体现的涨分点之外,作者还采用了如下的训练技巧。
- High Resolution Classifier,训练分类预训练模型时采用 224x224,但是在训练检测模型的时候用的是 448x448,但是这种直接切换分辨率的做法,检测模型可能难以快速适应高分辨率,所以作者在训练完预训练分类模型后,采用 448x448 的输入再 finetune 10 个 epoch,这样有助于改善这一状况。使用高分辨率分类器后,YOLOv2 的 mAP 提升了约 4%。
- Multi-Scale Training,由于 YOLOv2 模型中只有卷积层和池化层,所以 YOLOv2 的输入可以不限于 416x416 大小的图片。为了增强模型的鲁棒性,YOLOv2 采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的 iterations(作者取 10) 之后改变模型的输入图片大小。由于 YOLOv2 的下采样总步长为 32,输入图片大小选择一系列为32倍数的值: 320 , 352 , . . . 608 {320,352,...608} 320,352,...608,通过这种方式 YOLOv2 可以训练一个模型,根据需要选择不同大小的输入,小的输入速度快,但是精度略低,大的输入精度高,但是速度略慢。
为了实现上面的网络结构,作者实现了 “route” 层和 “reorg” 层。在 yolov2.cfg 文件中可以看到它们的用法。
[reorg]
stride=2
[route]
layers=-1,-4
“reorg” 层就是进行 reshape 操作,比如把 “26x26x512" 的 feature map resize 为 “13x13x2048",方便后面进行 concatenate 操作。
“route” 层的作用就是实现shortcut 和 concatenate 的作用,layers 则是指定输入的 layer ID,这里可以是绝对 ID(正值),也可以是相对 “route” 层当前位置的相对 ID(负值,-1 表示 “route” 层 的前一层)。
2 网络原理
网络输入图像(416x416x3)最后得到的 feature map 的 size 为 13x13*B(C+5),其中 C 是 classes 的个数,这里是 20,B 是每个 ceil 预测的 bbox 数量,这里是 5。
明显,在 v1 中每个 ceil 仅仅预测 2 个 bbox,这里预测了 5 个。这很好理解,因为预测更多的 bbox 可以减少漏检,提高召回率。
另外还有一点是 v1 中是针对每个 ceil 直接预测的 bbox,而这里预测的是针对 每一个 anchor 的。anchor 的概率是借鉴的 two stage 方法的概念,比如 Faster RCNN 里面就有 9 种不同的 anchor,这些 anchor 是人为挑选的,但这里作者是通过 k-means 的方法计算得到的。更多关于如何利用 k-means 计算 anchor size,可以参考K-means 计算 anchor boxes,代码可以参考kmeans-anchor-boxes。
v2 预测的结果构成和 v1 相同——C+5,这里的 5 依然是( t x , t y , t w , t h , t o t_x,t_y,t_w,t_h,t_o tx,ty,tw,th,to),但是由于引入了 anchor,所以从预测值计算 bbox 位置的方法是不同的。
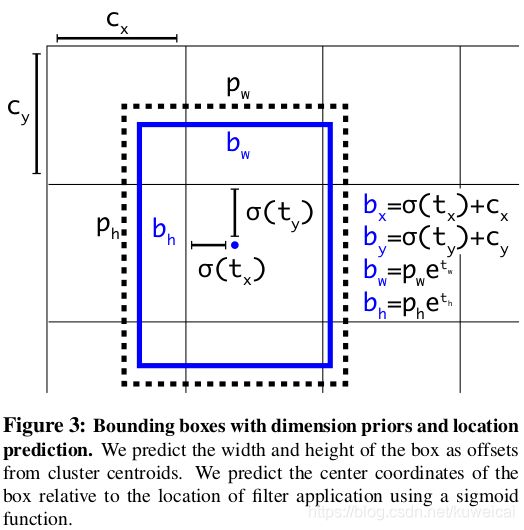
上图中:
- c x , c y c_x, c_y cx,cy 是 ceil 的中心点坐标(以图像左上角作为原点)
- $ t_x, t_y, t_w, t_h$ 是预测值
- p w , p h p_w, p_h pw,ph 是 anchor 的宽和高
- b x , b y , b w , b h b_x, b_y, b_w, b_h bx,by,bw,bh 是 bbox 的坐标和宽高
- t o t_o to 对应的是分类的置信度:$confidence = P_r(object)*IOU(b,object) = \sigma(t_o) $
- σ \sigma σ 是 sigmoid 函数, 输出值范围为 ( 0 , 1 ) (0,1) (0,1)
3 损失函数
在 YOLO v2 的论文中并没有提及损失函数的改进,但是透过 darknet 的源码,可以看到 YOLO v2 的损失函数依然是分为位置损失,置信度损失和分类损失,但是在具体的实现上略有不同,具体可以参考下面两篇博客。
-
YOLO v2 损失函数源码分析
-
目标检测算法之YOLOv2损失函数详解
4 性能
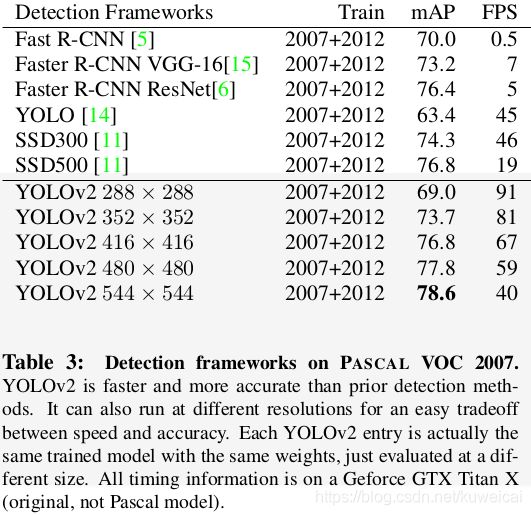
相比 v1,无论是在速度还是在精度上都有提升。另外 和 SSD(480x480 与 SSD500) 相比也是全面胜出。
参考
- YOLOv2 / YOLO9000 深入理解