PyTorch 新库 TorchMultimodal 使用说明:将多模态通用模型 FLAVA 扩展到 100 亿参数
先前的文章中,我们介绍了 TorchMultimodal,今天我们将从一个具体案例出发,演示如何在 Torch Distributed 技术加持下,在 TorchMultimodal 库中扩展多模态基础模型。
近年来,大模型已成为一个备受关注的研究领域。以自然语言处理为例,语言模型已经从几亿参数(BERT)发展到了几千亿参数(GPT-3),对下游任务的性能提升显示出重大作用。
业界对大规模语言模型如何扩展进行了广泛的研究。在视觉领域也可以观察到类似的趋势,越来越多的开发者开始转向基于 transformer 的模型(如 Vision Transformer、Masked Auto Encoders)。
显然,由于大规模模型的发展,单模态(如文本、图像、视频)相关研究不断改进,框架也迅速适应了更大的模型。
同时,随着图像-文本检索、视觉问答、视觉对话和文本到图像的生成等任务在现实世界中的应用,多模态越来越受到重视。
接下来就是训练大规模多模态模型。该领域也有了一些努力成果,如 OpenAI 的 CLIP,谷歌的 Parti 和 Meta 的 CM3。
本文将通过一个案例研究,展示如何使用 PyTorch Distributed 技术将 FLAVA 扩展到 100 亿参数。
补充阅读:HyperAI超神经:Meta 内部都在用的 FX 工具大起底:利用 Graph Transformation 优化 PyTorch 模型
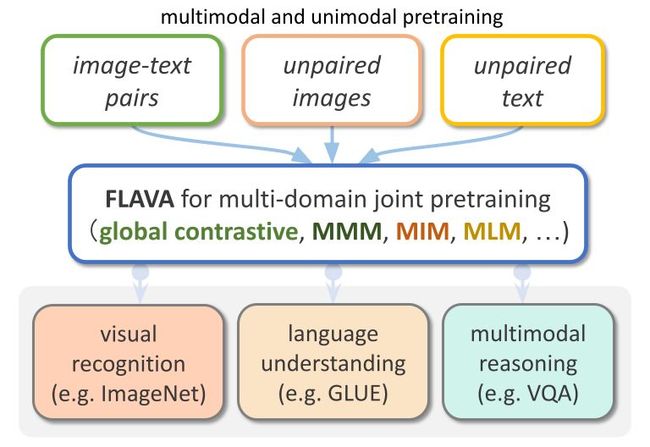
FLAVA 是一个视觉和语言基础模型在 TorchMultimodal 中可用
FLAVA 在单模态和多模态 Benchmark 中都表现出了非常突出的性能优势。本文将结合相关代码示例,演示如何扩展 FLAVA 。
代码详见:
multimodal/examples/flava/native at main · facebookresearch/multimodal · GitHub
扩展 FLAVA 概览
FLAVA 是一个基础多模态模型,由基于 transformer 的图像和文本编码器以及基于 transformer 的多模态融合模块组成。
FLAVA 在单模态和多模态数据上都进行了预训练,且这些数据的损失 (loss) 各不相同,包括掩码的语言、图像和多模态模型 loss,要求模型从其上下文中重建原始输入(自监督学习)。
此外,它还使用了图像文本匹配损失 (image text matching loss),包括对齐图像-文本对的 positive 和 negative 示例,以及 CLIP 风格的对比损失。
除了多模态任务(如图像-文本检索),FLAVA 在单模态 Benchmark(如 NLP 的 GLUE 任务和视觉的图像分类)上也表现出极佳的性能。
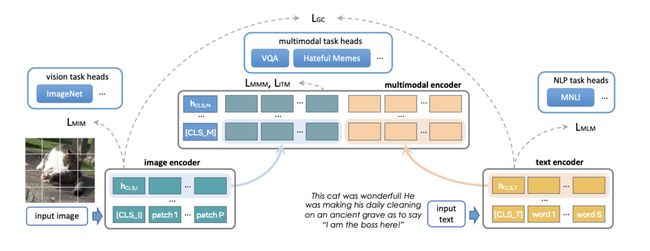
最初 FLAVA 模型约有 3.5 亿参数,并使用 ViT-B16 配置,用于图像和文本编码器。
Reference:https://arxiv.org/pdf/2010.11929.pdf
多模态融合 transformer 沿用了单模态编码器,但层数只有之前的 1/2。PyTorch 开发团队一直在探索增加编码器的尺寸,以适应更大的 ViT 变量 (variant)。
扩展 FLAVA 的另一个方面,就是增加批尺寸。FLAVA 巧妙利用了 in-batch negative 的对比损失,这通常只在大批尺寸中才有。
Reference:https://openreview.net/pdfid=U2exBrf_SJh
一般来说,当操作接近最大可能的批尺寸时,也能实现最大的训练效率或吞吐量,这由可用的 GPU 内存数量决定(参见实验部分)。
下表演示了不同模型配置的输出,实验中已确定每个配置能够适应内存的最大批尺寸。
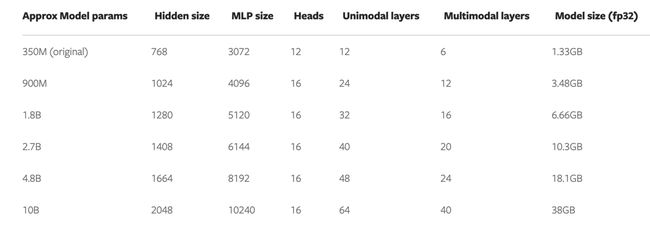
优化概览
PyTorch 提供了几种原生技术来有效地扩展模型。在下面的章节中会详细介绍三种方法,并演示如何应用这些技术,将 FLAVA 模型扩展到 100 亿参数。
分布式数据并行
分布式训练的一个常见起点是数据并行。数据并行在 GPU 之间复制模型,并进行数据集划分。不同的 GPU 会并行地处理不同的数据分区,并在模型权重更新前同步其梯度(通过 all reduce)。
下图展示了处理一个数据并行(正向迭代、反向迭代和权重更新步骤)的流程:
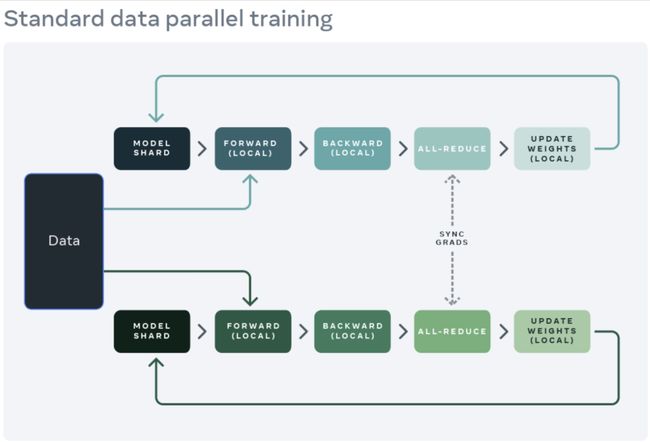
为了实现数据并行,PyTorch提供了一个原生 API,即 DistributedDataParallel(DDP),它可以作为一个模块封装器 (module wrapper) 使用,如下所示:
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])完全分片式数据并行
训练应用程序的 GPU 内存使用可以大致细分为模型输入、中间激活存储(intermediate activation,梯度计算需要用到)、模型参数、梯度和优化器状态。
扩展模型时通常会将这些元素同时增加。当单个 GPU 内存不足时,使用 DDP 扩展模型可能导致内存不足,因为它会在所有 GPU 上复制参数、梯度和优化器状态。
为了减少这种复制并节省 GPU 内存,可以将模型参数、梯度和优化器状态分片给所有 GPU,每个 GPU 只管理一个分片。这个方法参照了微软提出的 ZeRO-3。
这种方法的 PyTorch 原生实现可作为 FullyShardedDataParallel(FSDP)API,已在 PyTorch 1.12 中作为 beta 版功能发布。
在模块的正向和反向迭代过程中,FSDP 会根据计算需要对模型参数进行整合(使用 all-gather),并在计算后重新分片。它使用散射规约集合来同步梯度,以确保分片的梯度是全局平均的。FSDP 中模型的正向迭代和反向迭代流程如下:
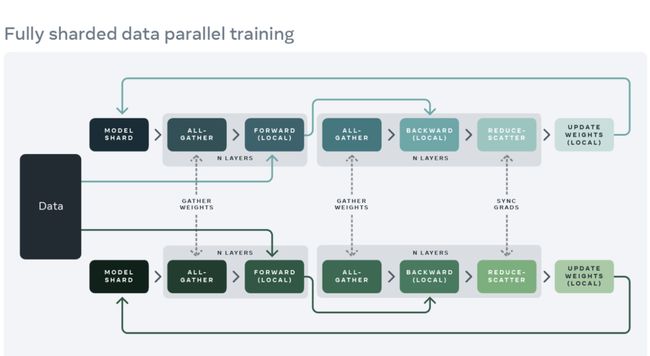
使用 FSDP 时要用 API 封装模型的子模块,从而控制某一特定子模块何时被分片或不分片。FSDP 提供了一个开箱即用的 auto-wrapping API、几个封装策略 (wrapping policy) 以及编写策略的能力。
以下示例演示了如何用 FSDP 封装 FLAVA 模型。指定自动封装策略为:transformer_auto_wrap_policy 。这将把单个 transformer 层(TransformerEncoderLayer)、图像 transformer (ImageTransformer)、文本编码器 (BERTTextEncoder) 和多模态编码器 (FLAVATransformerWithoutEmbeddings)封装为单个 FSDP 单元。
这采用了一种递归封装的方法来进行有效的内存管理。例如,在单个 transformer 层的正向或反向迭代完成后,删除参数、释放内存从而减少了峰值内存使用。
FSDP 还提供了一些可配置的选项来调整应用程序的性能,如本例中 limit_all_gathers 的使用。它可以防止过早地收集所有模型参数,减轻应用程序的内存压力。
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)activation checkpointing
如上,中间激活存储 (intermediate activation)、模型参数、梯度和优化器状态会影响 GPU 内存的使用。FSDP 可以减少后三者带来的内存消耗,但不能减少激活所消耗的内存。激活所使用的内存随着批尺寸或隐藏层数量的增加而增加。
activation checkpointing 通过在反向迭代过程中重新计算激活,而非将其保存在特定 checkpointed 模块的内存中,来减少内存的使用。
例如,通过对 27 亿参数模型应用 activation checkpointing,正向迭代后的活动内存峰值减少了 4 倍。
PyTorch 提供了一个基于 wrapper 的 activation checkpointing API。且 checkpoint_wrapper允许用户通过 check 封装单个模块,apply_activation_checkpointing 允许用户指定策略在整个模块中用 checkpointing 封装模块。
这两个 API 可以应用于大多数模型,因为它们不需要对模型定义代码进行任何修改。
然而,如果需要对 checkpointed segment 进行更细化的控制,如对模块内的特定功能进行 checkpointing,可以利用 torch.utils.checkpoint API,这需要修改模型代码。
activation checkpointing wrapper 对单个 FLAVA transformer 层(用 TransformerEncoderLayer 表示)的应用如下所示:
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
如上所示,用 activation checkpointing 封装 FLAVA transformer 层,用 FSDP 封装整体模型,可以将 FLAVA 扩展到 100 亿参数。
实验
对于上文提到的不同优化方法,我们将进一步实验其对系统性能的影响。
背景介绍:
-
使用含 8 个 A100 40 GB GPU 的单节点
-
运行 1000 次迭代预训练
-
使用 bfloat16 数据类型的 PyTorch 混合精度训练 (automatic mixed precision)
-
启用 TensorFloat32 格式,提高 A100 上的 matmul 性能
-
将吞吐量定义为每秒处理的平均项目数(测量吞吐量时忽略前 100 次迭代)
-
训练收敛及其对下游任务指标的影响,会作为未来研究的新方向
图 1 显示了每个模型配置和优化的吞吐量,local batch size 为 8,在 1 个节点上可能的最大 batch size。优化的模型变体 (model variant) 没有数据点,说明该模型无法在单个节点上训练。
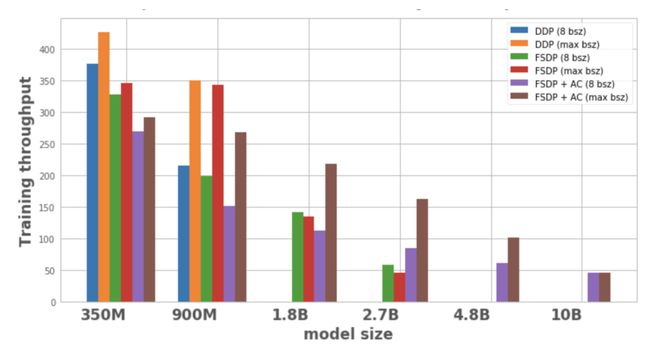
图1:不同配置下的训练吞吐量
图 2 展示了所有 GPU 在每个优化中可能的最大批尺寸。
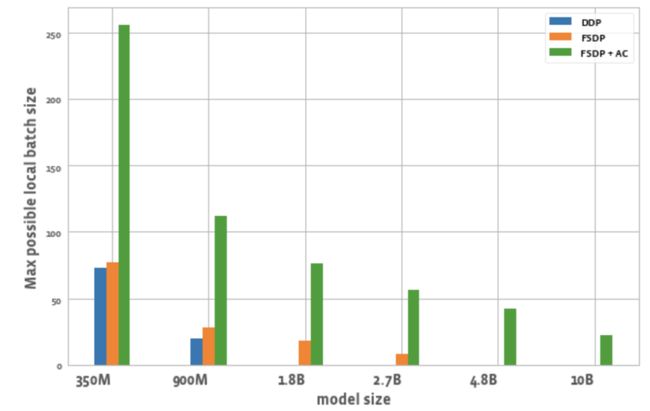
图2:不同配置下可能的最大本地批尺寸
从中可以观察到:
1. 扩展模型尺寸:
DDP 只能在一个节点上适应 350M 和 900M 的模型。使用 FSDP 可以节省内存,所以能够训练比 DDP 大 3 倍的模型(即 1.8B 和 2.7B 的变体)。将激活检查点(AC)与 FSDP 结合起来,可以训练更大的模型,约为 DDP 的 10 倍(如 4.8B 和 10B 变体)。
2. 吞吐量:
- 对于较小的模型,当批尺寸为 8 时,DDP 的吞吐量略高于或等于 FSDP,可以解释为 FSDP 需要额外的通信。FSDP 和 AC 结合在一起的吞吐量最低。这是因为 AC 在反向迭代的过程中,重新运行 checkpointed 正向迭代通道,为了节省内存牺牲了额外的计算。然而,对于 2.7B 模型,与单独的 FSDP 相比,FSDP + AC 实际上具有更高的吞吐量。这是因为带有 FSDP 的 2.7B 模型即使在批处尺寸为 8 的情况下也接近内存的极限,会触发 CUDA malloc retry,从而导致训练速度减慢。AC 有助于减少内存压力导致 no retry。
- 对于 DDP 和 FSDP + AC,模型的吞吐量会随着批尺寸的增加而增加。FSDP 对较小的变体也是如此。然而,对于 1.8B 和 2.7B 参数模型,当增加批尺寸时,吞吐量下降。一个潜在的原因是,在内存极限时,PyTorch 的 CUDA 内存管理可能不得不重试 cudaMalloc 调用或运行成本高昂的碎片整理 (defragmentation),以找到空闲的内存块来处理工作负载的内存需求,这可能导致训练速度减慢。
- 对于只能用 FSDP 训练的大模型 (1.8B,2.7B,4.8B) 而言,最高吞吐量的设置是用 FSDP+AC 扩展到最大批尺寸。对于 10B,可以观察到小批尺寸和最大批尺寸的吞吐量几乎相等。这是因为 AC 会导致计算量增加,而最大批尺寸可能会由于在 CUDA 内存限制下运行,导致成本高昂的碎片整理操作。然而,对于这些大模型,批尺寸的增加足以抵销这种开销。
3. 批尺寸:
与 DDP 相比,单独使用 FSDP 可以实现略高的批尺寸。对于 350M 参数模型,使用 FSDP+AC 可以实现比 DDP 高 3 倍的批尺寸,对于 900M 参数模型,可以实现 5.5 倍的批尺寸。即使是 10B,最大的批尺寸也约是 20,这相当不错。FSDP+AC 基本上可以用较少的 GPU 实现较大的全局批尺寸,对对比学习任务 (contrastive learning task) 特别有效。
结论
随着多模态基础模型的发展,扩展模型参数和高效训练正在成为一个重点领域。PyTorch 生态系统旨在通过提供不同的工具,加速训练和扩展多模态模型。
未来,PyTorch 将增加对其他类型模型的支持,比如多模态生成模型,以及提升相关技术的自动化。欢迎大家持续关注 PyTorch 开发者社区公众号,你也可以扫码备注「PyTorch」,加入 PyTorch 社群。

PyTorch 官方博客、教程
最新进展、最佳实践
扫码备注加入讨论组