[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ...
CVPR 2022 论文链接
源代码:Github
1 速读
1.1 论文试图解决什么问题?这是否是一个新的问题?
试图解决:基于PnPDE的单目物体位姿估计,需要获得图像中点的3D深度(通过深度网络之类的方法)以及2D-3D之间的关联,然后通过PnP求解得到物体位姿;而PnP本质上不可导,使得无法通过反向传播位姿的误差训练网络;
文章通过将求解位姿转换为预测位姿的概率密度解决这一问题,实现了基于位姿真值的端到端训练网络学习2D-3D关联;
在端到端训练PnP求解位姿网络不是新问题,但是以往方法对PnP的处理无法解决PnP不可导带来的收敛问题;
文章解决的新问题为:在没有形状先验的情况下,通过位姿误差直接端到端地训练得到2D-3D关联及权重系数;
1.2 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
①直接位姿预测(显式方法):一个前馈网络需要预测:深度+图像上的投影位置+物体朝向(等信息),利用标注的物体真实位姿计算损失函数,完成端到端训练
显式的方法中,物体系到相机系的转化包含在了网络结果中,这导致网络解释性差+容易过拟合;
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第1张图片](http://img.e-com-net.com/image/info8/59ee9521b9354e0aaf331dfd53820ea7.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第2张图片](http://img.e-com-net.com/image/info8/e4c47e1d66294e1489157c9ed32a8b67.jpg)
②基于PnP的位姿估计方法(隐式方法):需要给出图像坐标系下N个2D点+物体坐标系下N个3D点+各对点的关联权重(网络或者传统方法给出),通过2D-3D匹配求解最优位姿
显示的方法中,现有的神经网络策略集中在获取更准确的2D-3D的匹配关系,从而确保PnP的结果足够精确,这存在一个问题即:希望得到最优的位姿而解决方式是通过一个Surrogate loss中间损失函数完成;
同样有网络尝试从端到端优化这个问题,但是由于argmin函数不可导的性质,导致这个过程是不稳定的;
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第3张图片](http://img.e-com-net.com/image/info8/a6e749c6cecf453a957494bb05f50ee2.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第4张图片](http://img.e-com-net.com/image/info8/2386c3647893404b928e6d318bb7acda.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第5张图片](http://img.e-com-net.com/image/info8/80395a7959b14c3bade16d45212927ba.jpg)
③基于概率的深度学习:略过,作者主要提及Softmax,因为文章将其推广到连续域
1.3 文章的贡献是什么?
①提出了用于端到端位姿估计的概率PnP层:EPro-PnP,将不可微的确定PnP操作转化为可微的概率层
②提出的EPro-PnP可嵌入到基于PnP的工程中,也可以通过论文的思路灵活设计2D-3D关联网络
③将离散SoftMax拓展到连续域的思路,可以推广到其他嵌套了优化层的网络
1.4 文章解决方案的关键是什么
核心在于:将PnP位姿优化问题转变为预测位姿概率密度的问题
①将离散分类SoftMax引入连续域;
②通过最小化预测位姿和目标位姿构成的KL散度学习2D-3D之间的对应关系和权重;
1.5 实验如何设计?实验结果足够论证其效果吗?
1.6 数据集是什么?
LineMOD数据集:13条序列共1200张图片,每个object对应一个6DOF位姿
划分:每个物体200张图片用于训练;
误差指标:ADD(-S) 和 n°, n cm
nuScenes数据集:1000条序列,每条序列40张关键帧,每个关键帧有来自环视相机的6张RGB图,包含覆盖10种类别的超过140万个3D bounding box
划分:700/150/150 对应 训练/验证/测试
误差指标:mAP、Average Translation Error (ATE), Average Scale Error (ASE), Average Orientation Error (AOE), Average Velocity Error (AVE) and Average Attribute Error (AAE). Finally, there is a nuScenes detection score (NDS)
1.7 还会存在什么问题?
2 主要内容
任务:给定一张含有 3D 物体投影的图像,确定物体坐标系到相机坐标系的刚体变换
输入:一张图片
输出:由学习到的2D-3D对应关系表出的位姿概率分布
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第6张图片](http://img.e-com-net.com/image/info8/1ce7bc8fee4745638f54113bd8ef4749.jpg)
2.1 PnP
确定:图像坐标系下N个2D点+物体坐标系下N个3D点+各对点的关联权重;求解:物体坐标系到图像坐标系的位姿变换
最小化重投影误差得到最优位姿解y:
a r g m i n y = 1 2 ∑ i = 1 N ∣ ∣ w i 2 D ∘ ( π ( R x i 3 D + t ) − x i 2 d ) ∣ ∣ 2 = 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 \underset{y}{argmin} = \frac{1}{2}\sum\limits_{i=1}^{N}||w_i^{2D}\circ(\pi(Rx_i^{3D}+t)-x_i^{2d})||^2 = \frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2 yargmin=21i=1∑N∣∣wi2D∘(π(Rxi3D+t)−xi2d)∣∣2=21i=1∑N∣∣fi(y)∣∣2定义最大似然函数 p ( X ∣ y ) p(X|y) p(X∣y),表示事件X(2D-3D匹配)发生的情况下对于位姿y的似然,似然函数最大值处对应最合理的位姿y:
p ( X ∣ y ) = e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 p(X|y) = exp -\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2 p(X∣y)=exp−21i=1∑N∣∣fi(y)∣∣2在没有任何先验知识的情况下,位姿的后验概率为似然函数的归一化:
p ( y ∣ X ) = e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 ∫ e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 d y p(y|X) = \frac{exp-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2}{\int exp -\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2\ dy} p(y∣X)=∫exp−21i=1∑N∣∣fi(y)∣∣2 dyexp−21i=1∑N∣∣fi(y)∣∣2该位姿后验概率形似SoftMax在连续域上的推广:
S o f t M a x ( α i ) = e x p α i ∑ j e x p α j SoftMax(\alpha_i) = \frac{exp\ \alpha_i}{\sum_j exp\ \alpha_j} SoftMax(αi)=∑jexp αjexp αi
2.2 KL散度
用于表出误差
KL散度表示两个几率分布P和Q差别的非对称性的度量。一般情况下,用一个近似的分布Q对一个分布P进行建模,如果我们使用 q(x) 来建立一个编码体系,用来把 x 的值传给接收者,那么由于我们使用了q(x)而不是真实分布p(x),平均编码长度比用真实分布p(x)进行编码增加的信息量(单位是 nat )为:
K L ( p ∣ ∣ q ) = − ∫ p ( x ) l o g q ( x ) p ( x ) d x = ∫ p ( x ) l o g p ( x ) d x − ∫ p ( x ) l o g q ( x ) d x KL(p||q) = -\int p(x)log\frac{q(x)}{p(x)}dx = \int p(x)log\ p(x) dx -\int p(x)log\ q(x)dx KL(p∣∣q)=−∫p(x)logp(x)q(x)dx=∫p(x)log p(x)dx−∫p(x)log q(x)dx用真实的位姿概率分布 t ( y ) t(y) t(y)和构建的位姿概率分布 p ( y ∣ X ) p(y|X) p(y∣X)之间的KL散度表示训练误差 D K L ( t ( y ) ∣ ∣ p ( y ∣ X ) ) D_{KL}(t(y)||p(y|X)) DKL(t(y)∣∣p(y∣X)):(原论文中只有最后一个式子,中间过程为我自己的推导,可能存在问题)
D K L ( t ( y ) ∣ ∣ p ( y ∣ X ) ) = ∫ t ( y ) l o g t ( y ) d y − ∫ t ( y ) l o g p ( y ∣ X ) d y D_{KL}(t(y)||p(y|X)) = \int t(y)log\ t(y)dy - \int t(y)log\ p(y|X)dy DKL(t(y)∣∣p(y∣X))=∫t(y)log t(y)dy−∫t(y)log p(y∣X)dy由于第一项是确定值,故损失函数可以不包含这一部分,则有:
L K L = − ∫ t ( y ) l o g p ( X ∣ y ) ∫ p ( X ∣ y ) d y d y L_{KL}=-\int t(y)log\frac{p(X|y)}{\int p(X|y)dy}dy LKL=−∫t(y)log∫p(X∣y)dyp(X∣y)dy = ∫ t ( y ) l o g ( ∫ ( p ( X ∣ y ) d y ) d y − ∫ t ( y ) l o g p ( X ∣ y ) d y = \int t(y)log(\int(p(X|y)dy)dy - \int t(y)log\ p(X|y)dy =∫t(y)log(∫(p(X∣y)dy)dy−∫t(y)log p(X∣y)dy最终得到由似然表示的损失函数,此时将真实的位姿概率分布设定为一个类似脉冲函数的g.t.,则有:
L K L = − l o g p ( X ∣ y g t ) + l o g ∫ p ( X ∣ y ) d y L_{KL}= -log\ p(X|y_{gt}) + log\int p(X|y)dy LKL=−log p(X∣ygt)+log∫p(X∣y)dy = 1 2 ∑ i = 1 N ∣ ∣ f i ( y g t ) ∣ ∣ 2 + l o g ∫ e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 d y = \frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y_{gt})||^2 + log\int exp-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2dy =21i=1∑N∣∣fi(ygt)∣∣2+log∫exp−21i=1∑N∣∣fi(y)∣∣2dy第一项 L t a r g e t = 1 2 ∑ i = 1 N ∣ ∣ f i ( y g t ) ∣ ∣ 2 L_{target}=\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y_{gt})||^2 Ltarget=21i=1∑N∣∣fi(ygt)∣∣2表示在目标位姿处的重投影误差,反映了在真值处的表现能力,在其他相似工作的论文中长作为损失函数
第二项 L p r e d i c t = l o g ∫ e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 d y L_{predict}=log\int exp-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2dy Lpredict=log∫exp−21i=1∑N∣∣fi(y)∣∣2dy对应 p ( y ∣ X ) p(y|X) p(y∣X)的分母,反映了在各个位姿处的表现能力,是完成端到端训练的关键;
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第7张图片](http://img.e-com-net.com/image/info8/6ffd4d71d6a14c61a83e7ff8ef63b408.jpg)
根据链式求导法则,上式loss函数的偏导数形式为:
∂ L K L ∂ ( ⋅ ) = ∂ ∂ ( ⋅ ) 1 2 ∑ i = 1 N ∣ ∣ f i ( y g t ) ∣ ∣ 2 + 1 ∫ e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 d y ∗ ∫ e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 ∗ ∂ ∂ ( ⋅ ) ( − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 ) d y \frac{\partial L_{KL}}{\partial(\cdot)} = \frac{\partial}{\partial(\cdot)} \frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y_{gt})||^2 + \frac{1}{\int exp-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2dy}*\int exp-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2\ *\frac{\partial}{\partial(\cdot)}(-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2)dy ∂(⋅)∂LKL=∂(⋅)∂21i=1∑N∣∣fi(ygt)∣∣2+∫exp−21i=1∑N∣∣fi(y)∣∣2dy1∗∫exp−21i=1∑N∣∣fi(y)∣∣2 ∗∂(⋅)∂(−21i=1∑N∣∣fi(y)∣∣2)dy = ∂ ∂ ( ⋅ ) 1 2 ∑ i = 1 N ∣ ∣ f i ( y g t ) ∣ ∣ 2 − E y ∼ p ( y ∣ X ) ∂ ∂ ( ⋅ ) ( 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 ) = \frac{\partial}{\partial(\cdot)} \frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y_{gt})||^2 - \underset{y\sim p(y|X)}{\mathbb{E}}\frac{\partial}{\partial(\cdot)}(\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2) =∂(⋅)∂21i=1∑N∣∣fi(ygt)∣∣2−y∼p(y∣X)E∂(⋅)∂(21i=1∑N∣∣fi(y)∣∣2)第一项 ∂ ∂ ( ⋅ ) 1 2 ∑ i = 1 N ∣ ∣ f i ( y g t ) ∣ ∣ 2 \frac{\partial}{\partial(\cdot)} \frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y_{gt})||^2 ∂(⋅)∂21i=1∑N∣∣fi(ygt)∣∣2表示在目标位姿处的重投影误差梯度;
第二项 − E y ∼ p ( y ∣ X ) ∂ ∂ ( ⋅ ) ( 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 ) - \underset{y\sim p(y|X)}{\mathbb{E}}\frac{\partial}{\partial(\cdot)}(\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2) −y∼p(y∣X)E∂(⋅)∂(21i=1∑N∣∣fi(y)∣∣2)表示重投影误差的在预测的位姿分布上的梯度期望;
以参数匹配权重 w i 2 D w_i^{2D} wi2D为例,其关于重投影误差的偏导数为:
∂ ∂ ( w i 2 D ) 1 2 ∑ j = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 = ∂ ∂ ( w i 2 D ) 1 2 ∑ j = 1 N ∣ ∣ w j 2 D ∘ ( π ( R x j 3 D + t ) − x j 2 d ) ∣ ∣ 2 \frac{\partial}{\partial(w_i^{2D})}\frac{1}{2}\sum\limits_{j=1}^{N}||f_i(y)||^2 = \frac{\partial}{\partial(w_i^{2D})}\frac{1}{2}\sum\limits_{j=1}^{N}||w_j^{2D}\circ(\pi(Rx_j^{3D}+t)-x_j^{2d})||^2 ∂(wi2D)∂21j=1∑N∣∣fi(y)∣∣2=∂(wi2D)∂21j=1∑N∣∣wj2D∘(π(Rxj3D+t)−xj2d)∣∣2 = w i 2 D ∘ ∣ ∣ π ( R x j 3 D + t ) − x j 2 d ∣ ∣ 2 = w_i^{2D} \circ ||\pi(Rx_j^{3D}+t)-x_j^{2d}||^2 =wi2D∘∣∣π(Rxj3D+t)−xj2d∣∣2 = w i 2 D ∘ r i ( y ) 2 = w_i^{2D} \circ r_i(y)^2 =wi2D∘ri(y)2有 w i 2 D w_i^{2D} wi2D关于loss函数的重投影误差的负梯度为:
− ∂ L K L ∂ ( w i 2 D ) = w i 2 D ∘ ( − r i ( y g t ) 2 + E y ∼ p ( y ∣ X ) r i ( y ) 2 ) -\frac{\partial L_{KL}}{\partial(w_i^{2D})}= w_i^{2D} \circ (-r_i(y_{gt})^2+\underset{y\sim p(y|X)}{\mathbb{E}}r_i(y)^2) −∂(wi2D)∂LKL=wi2D∘(−ri(ygt)2+y∼p(y∣X)Eri(y)2)第一项 − r i ( y g t ) 2 -r_i(y_{gt})^2 −ri(ygt)2表示在真值处重投影误差较大的点的权重需要降低,这些点往往对应图像中物体之外的点,对应下图中的uncertainty;
第二项 E y ∼ p ( y ∣ X ) r i ( y ) 2 ) \underset{y\sim p(y|X)}{\mathbb{E}}r_i(y)^2) y∼p(y∣X)Eri(y)2)表示在不同位姿处误差变化明显的点的权重需要增加,这些点往往对应图像中物体的边缘,因为这些地方对位姿变化很敏感,对应下图中的discrimination;
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第8张图片](http://img.e-com-net.com/image/info8/f8f9c2d25f8045a4bd5d72c7d7d00e53.jpg)
2.3 Monte Carlo 位姿误差
用于完成积分计算
2.3.1 蒙特卡洛方法
∫ a b F ( x ) d x ≈ 1 N ∑ i = 1 N F ( x i ) P ( x i ) \int _a^b F(x)dx \approx \frac{1}{N}\sum \limits_{i=1}^{N}\frac{F(x_i)}{P(x_i)} ∫abF(x)dx≈N1i=1∑NP(xi)F(xi)对于正常的积分有:
∫ a b F ( x ) d x = l i m N → ∞ b − a N ∑ i = 1 N F ( x i ) = l i m N → ∞ 1 N ∑ i = 1 N F ( x i ) 1 b − a \int _a^b F(x)dx = \underset{N\rightarrow\infin}{lim}\frac{b-a}{N}\sum \limits_{i=1}^{N}{F(x_i)}=\underset{N\rightarrow\infin}{lim}\frac{1}{N}\sum \limits_{i=1}^{N}\frac{F(x_i)}{\frac{1}{b-a}} ∫abF(x)dx=N→∞limNb−ai=1∑NF(xi)=N→∞limN1i=1∑Nb−a1F(xi)即在蒙特卡洛方法中将 P ( x i ) P(x_i) P(xi)定义为均匀分布且采样次数趋向于无穷时即为积分的定义,由于N无法趋向于无穷,故为积分的近似。
对于概率分布 P ( x i ) P(x_i) P(xi),如果能够给出与 F ( x i ) F(x_i) F(xi)近似的分布函数,可以在相同采样次数N的情况下大大提高近似的精度。
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第9张图片](http://img.e-com-net.com/image/info8/d1077ca9fff5449094f5d493c98a19b7.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第10张图片](http://img.e-com-net.com/image/info8/6d9e0e54b38d4222b7286de51d18e0d0.jpg)
2.3.2 蒙特卡洛位姿误差
对于误差中的第二项用蒙特卡洛方法近似计算积分, v j v_j vj表示位姿 y j y_j yj的重要性权重
L p r e d i c t = l o g ∫ e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 d y L_{predict}=log\int exp-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2dy Lpredict=log∫exp−21i=1∑N∣∣fi(y)∣∣2dy ≈ l o g 1 K ∑ j = 1 N e x p − 1 2 ∑ i = 1 N ∣ ∣ f i ( y ) ∣ ∣ 2 q ( y i ) = l o g 1 K ∑ j = 1 N v j \approx log \frac{1}{K}\sum \limits_{j=1}^{N}\frac{exp-\frac{1}{2}\sum\limits_{i=1}^{N}||f_i(y)||^2}{q(y_i)}=log\frac{1}{K}\sum \limits_{j=1}^{N}v_j ≈logK1j=1∑Nq(yi)exp−21i=1∑N∣∣fi(y)∣∣2=logK1j=1∑Nvj
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第11张图片](http://img.e-com-net.com/image/info8/8ff02a1986f643a7bc546639784556d0.jpg)
2.4 导数正则化
推理过程中仍然需要知道通过PnP直接求解得到的位姿 y ⋆ y^\star y⋆,首先对于计算得到的 y ⋆ y^\star y⋆,通过高斯牛顿方法计算:
Δ y = − ( J T J + ε I ) − 1 J T F ( y ⋆ ) \Delta y = -(J^TJ+\varepsilon I)^{-1}J^TF(y^{\star}) Δy=−(JTJ+εI)−1JTF(y⋆) Δ y \Delta y Δy在 y ⋆ y^\star y⋆到达局部最小值时应为0,此时利用 Δ y \Delta y Δy构建正则化误差:
L r e g = l ( y ⋆ + Δ y , y g t ) L_{reg} = l(y^{\star}+\Delta y, y_{gt}) Lreg=l(y⋆+Δy,ygt)即希望 Δ y \Delta y Δy能够将PnP的解指向真实的位姿;
2.5 网络测试
2.5.1 Dense Correspondence Network
基于CDPN做出小改动,原网络旋转变换R和平移变换T由两个Head给出,作者将其替换为一个head,统一使用PnP计算;
输入:单帧图片,有对应的2d坐标 x 2 D x^{2D} x2D;
输出:①3D坐标 x 3 D x^{3D} x3D+②两通道的confidence map(对应 x 2 D x^{2D} x2D),通过Softmax和global scale得到weight map;
此处②的改动中,Softmax将一个绝对的对应权重转换为一个相对的关系,同时global scale表示了对于预测分布的全局集中度,保证KL散度误差可以更好地收敛,在实验结果中有声明没有softmax不会收敛;
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第12张图片](http://img.e-com-net.com/image/info8/b1241e282ff74867829dc70cb6829b5a.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第13张图片](http://img.e-com-net.com/image/info8/5a4ee5ed4f5c4abbbead18b670591b06.jpg)
实验结果比较:
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第14张图片](http://img.e-com-net.com/image/info8/0749aafda094483eafe6d42bf8c01ecb.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第15张图片](http://img.e-com-net.com/image/info8/3cf94890e5974958b516f990b0fdaf0b.jpg)
2.5.2 Deformable Correspondence Network
基于FCOS3D做出更改,FCOS3D是一个one-stage detector直接生成一系列信息,作者保留head的结果用于生成object queries(embedding point+reference point)而不是直接预测位姿;
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第16张图片](http://img.e-com-net.com/image/info8/c1dd537a0b0f43f8a0e085690f3c0210.jpg)
一个多头的attention layer从稠密的特征中采样得到point特征,然后聚合成object特征;
point特征经过一个subnet预测出3D点和对应的权重,其中3D点坐标是在归一化的object坐标系下的,没有尺度;
object特征用于预测object级别的参数(3D定位socre、权重、尺寸、速度等);
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第17张图片](http://img.e-com-net.com/image/info8/bed6bed11eef48d38da2e305db30d8b0.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第18张图片](http://img.e-com-net.com/image/info8/a45d2975f0614a65af901a6b4c85c64c.jpg)
3 实验结果
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第19张图片](http://img.e-com-net.com/image/info8/2013bac100cf4d838d9977343c27eff1.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第20张图片](http://img.e-com-net.com/image/info8/efe181b4adc3402884ebbed92a493c1f.jpg)
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第21张图片](http://img.e-com-net.com/image/info8/148f9904d8c241598934cc0ab27a3b54.jpg)
3 疑问
①为什么位姿最优解在反向传播中不可导?
答:由于argmin函数是不可导的,如下图所示:
argmin的作用:对于一组2D-3D匹配X,存在一组与pose相关的损失函数,argmin会到达损失函数极小值对应的位姿;
损失函数的特点:由2D-3D匹配X确定,存在多个局部最小值,分别对应多个pose
不可导的体现:在训练过程中,会导致2D-3D匹配变化 Δ X \Delta X ΔX,这导致损失函数的形状发生变化,当一个局部最小值取代成为全局最小值的时候,argmin对于 Δ X \Delta X ΔX表现出不连续
![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ..._第22张图片](http://img.e-com-net.com/image/info8/85936473698143cfb9bffb404e03e62e.jpg)
②位姿积分是怎么做的?
答:使用蒙特卡洛方法近似;
③怎么用重要性权重更新位姿分布?
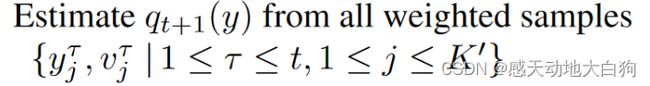
④boungding box、深度、尺寸等信息出现的原理是什么?(不是本篇文章的内容)