机器人操作持续学习论文(1)原文阅读与翻译——机器人操作中无灾难性遗忘的原语生成策略学习
Primitives Generation Policy Learning without Catastrophic Forgetting for Robotic Manipulation 1机器人操作中无灾难性遗忘的原语生成策略学习
 大纲 大纲
|
关键词Index Terms
Variational Autoencoder变分自动编码器,Continual learning持续学习,Catastrophic forgetting灾难性遗忘, Robotic manipulation机器人操作
0.摘要Abstract
Abstract—Catastrophic forgetting is a tough challenge when agent attempts to address different tasks sequentially without storing previous information, which gradually hinders the de-
velopment of continual learning.
灾难性遗忘是一个严峻的挑战,当agent试图在不存储先前信息的情况下连续处理不同的任务时,它会逐渐阻碍持续学习的发展。
Except for image classification tasks in continual learning, however, there are little reviews related to robotic manipulation.
然而,除了持续学习中的图像分类任务外,很少有关于机器人操作的工作。
In this paper, we present a novel hierarchical architecture called Primitives Generation Policy
Learning to enable continual learning.
在本文中,我们提出了一种新的层次结构,称为原语生成策略学习,以实现持续学习。
More specifically, a gener-ative method by Variational Autoencoder is employed to generate
state primitives from task space, then separate policy learning component is designed to learn torque control commands for different tasks sequentially.
更具体地说,采用变分自动编码器的通用方法从任务空间生成状态原语,然后设计单独的策略学习组件,依次学习不同任务的转矩控制命令。
Furthermore, different task policies could be identified automatically by comparing reconstruction
loss in the autoencoder.
此外,通过比较自动编码器中的重建损失,可以自动识别不同的任务策略。
Experiment on robotic manipulation task shows that the proposed method exhibits substantially improved performance over some other continual learning methods.
机器人操作任务的实验表明,与其他一些连续学习方法相比,本文方法显著提高了性能。
1.简介Introduction
As a core component in artificial intelligence, learning is an essential approach to acquire new knowledge by interacting with surrounding world 2,3.
作为人工智能的核心组成部分,通过与环境互动进行学习是获取新知识的重要途径。
It requires agents are capable of memorizing different knowledge in an abstract, structured and systematic way, which benefits for performing a variety of tasks.
它要求智能体能够以抽象、结构化和系统化的方式记忆不同的知识,这有利于提升多种任务下的表现。
Traditional learning methods in machine learning usually require all task data collected in advance to learn different tasks together 4 5 , while that is particularly difficult in reality: different task information may not be presented simultaneously.
传统机器学习方法通常需要提前收集所有任务数据,以便同时学习多种任务(这种更像是多任务学习,而不是持续学习),而这难以实现:不同的任务信息可能无法同时呈现(比如不同任务数据涉及不同版权、不同隐私等,并且每个任务的数据加起来数据量过于巨大)。
Therefore, agents must learn to handle these tasks in a sequential fashion.
因此,智能体必须学会依次处理这些任务。
Faced with this learning pattern, however, agents are prone to forget how to perform previously learned tasks after learning new ones since previous information is inaccessible to current learning.
然而这种顺序学习的方式下,智能体在学习新任务后容易忘记如何执行以前学习的任务,因为当前学习无法得到以前的信息。
This phenomenon is called catastrophic forgetting 6, 7 during the process of learning sequential multi-tasks (SMT).
在学习顺序多任务(SMT)的过程中,这种现象被称为灾难性遗忘。
In terms of the neural network, it tends to deviate the weights learned in previously tasks after training on subsequent tasks, which leads to a loss of performance on the previously learned ones.
就神经网络而言,在对后续任务进行训练后,它往往会偏离在先前任务中学习到的权重,从而导致在先前学习到的任务上的性能损失。
Consequently, it is great of importance to endow agents with the ability of addressing SMT without catastrophic forgetting so as to continuously adapt to a changing environment in their life cycle.
因此,赋予智能体在不发生灾难性遗忘的情况下处理SMT的能力,以便在其生命周期中不断适应复杂多变环境,是非常重要的。
This is known as continual learning or lifelong learning 8, 9.
这被称为持续学习或终身学习。
Even though numerous recent advances have witnessed impressive gains across several domains by deep neural networks 10, 11, these approaches enjoy success with the precondition of all simultaneously available data on different tasks.
尽管深度神经网络在跨域学习上取得了大量最新进展,但这些方法能够成功的前提是同时使用了所有任务的所有可用数据。
If directly applied to SMT regime, catastrophic forgetting will inevitably occur since the weights move away from original optimal values after learning new tasks 12.
如果直接应用于SMT领域,由于学习新任务后权重偏离了原始最优值,不可避免地会发生灾难性遗忘。
Hence, it is necessary to solve catastrophic forgetting problems with continual learning which to some extent promotes the development of artificial general intelligence.
因此,有必要通过持续学习来解决灾难性遗忘问题,这在一定程度上促进了通用人工智能的发展。
Traditional solutions for catastrophic forgetting problems may suffer from some certain drawbacks.
对于灾难性遗忘问题的传统解决方案可能存在某些缺陷。
For instance, Naive fine-tune behaves oblivious in spite of a positive effect on new task learning by initializing new task with the optimal settings of old ones 13.
例如,尽管使用旧任务的参数对新任务进行初始化会对新任务学习产生积极影响,但Naive fine-tune(朴素微调)的行为仍然是健忘的。
Whereas recent advances have provided multiple ways to overcome catastrophic forgetting across avariety of domains 14, 15.
然而,最近的进展提供了多种方法来克服跨多域的灾难性遗忘。
Li et al. 14 ^{14} 14 employ fine-tune and the Distillation Networks to enable sequential learning by introducing a shared model with separate classification layers.
Li等人通过引入具有独立分类层的共享模型,利用微调和蒸馏网络实现顺序学习。
Based on this basic framework, 16 designs an extra undercomplete autoencoder to capture important features on previous tasks to overcome catastrophic forgetting.
基于这一基本框架,设计了一个额外的欠完整自动编码器,以捕获先前任务的重要特征,从而克服灾难性遗忘。
Nevertheless, these methods both need to provide the knowledge of which task is being performed during the test phase, which is to say additional task identifier has to be supplied for indicating corresponding task parameters.
然而,这些方法都需要提供测试阶段执行的任务的知识,也就是说,必须提供额外的任务标识符来将网络调整到相应的任务的参数(需要根据不同任务使用不同的分类层)。
To avoid this problem, Elastic weight consolidation (EWC) focuses on addressing SMT within one neural network by reducing the plasticity of weights that are vital to previously learned tasks 12 ^{12} 12.
为了避免这个问题,弹性权重整合(EWC)专注于通过降低对之前学习的任务至关重要的权重的可塑性,在一个神经网络内解决SMT问题。
These methods, however, usually concentrate on continuously learning knowledge related to image classification tasks, which requires to remember different images sequentially.
然而,这些方法通常聚焦于与图像分类任务相关的持续学习,这类任务需要依次记住不同的图像。
In comparison, there is little research in the field of robotics.
相比之下,在机器人领域几乎没有相关研究。
SMT-GPS 15 ^{15} 15 tries to alleviate catastrophic forgetting between a series of robotic manipulation tasks through employing EWC algorithm.
SMT-GPS尝试使用EWC算法来缓解一系列机器人操作任务学习之间的灾难性遗忘。
Ennen et al. 17 introduce Generative Motor Reflexes (GMR) to drive robust robotic policy representation, but it can only handle one task.
Ennen等人引入了生成性运动反射(GMR)来驱动鲁棒的机器人策略表达,但它只能处理一项任务。
Rather than handling one task with GMR, we aims to solve multiple robotic tasks sequentially without catastrophic forgetting.
我们的目标不是用GMR处理一个任务,而是在不发生灾难性遗忘的情况下依次解决多个机器人任务。
In this work, we propose a novel hierarchical architecture called Primitives Generation Policy Learning (PGPL), which consists of two components: primitives generation and policy learning.
在这项工作中,我们提出了一种新的层次结构原语生成策略学习(PGPL),它由两个部分组成:原语生成和策略学习。
Primitives generation component employs a Variational Autoencoder (VAE) 18 to generate state primitives, and policy learning component aims to learn a task specific operator to perform corresponding task.
原语生成组件采用变分自动编码器(VAE)生成状态原语,策略学习组件学习特定于任务的算子以执行相应的任务。
When facing a new task, previously trained VAE is utilized to generate state primitives for subsequent policy learning.
当面临新任务时,利用先前训练过的VAE生成状态原语,用于后续的策略学习。
In this manner, we are able to generate similar state primitives to describe tasks elementary features, while giving the model more flexibility to adapt itself to different tasks with corresponding operators.
通过这种方式,我们可以生成相似的状态原语来描述任务的基本特征,同时使模型更灵活地适应具有相应算子的不同任务。
Meanwhile, task identifier could be obtained by comparing reconstruction loss in VAE among different tasks.
同时,通过比较不同任务之间的VAE重建损失,可以得到任务标识符。
To sum up, the main contributions to this paper can be listed as the followings.
综上所述,本文的主要贡献如下:
• We propose a novel hierarchical policy learning architecture Primitives Generation Policy Learning (PGPL) to achieve continual learning with an end-to-end manner in the field of robotics.
我们提出了一种新的分层策略学习体系结构原语生成策略学习(PGPL),以实现机器人领域端到端的持续学习。
• By generating state primitives with VAE, different tasks could be addressed sequentially without additional task identification.
通过使用VAE生成状态原语,可以连续处理不同的任务,而无需额外的任务标识。
• Experiment on several robotic manipulation task shows that the proposed method exhibits substantially improved performance over some other continual learning methods.
在多个机器人操作任务上的实验表明,与其他一些持续学习方法相比,该方法的性能有了显著提高。
The rest of the paper is organized as follows: Section II gives a brief review of related work. Section III presents formulation of the proposed method. Comparative experimental results are presented and discussed in section IV. Finally, concluding remarks are outlined in section V.
论文的其余部分组织如下:第二节简要回顾了相关工作。第三节介绍了所提方法的建模。第四节介绍并讨论了对比实验结果。最后,第五节概述了结论。
2.相关工作Related Work
Standard multi-task learning attempts to address multiply tasks in a single model by integrating knowledge from different domains 4 ^{4} 4.
标准多任务学习尝试通过整合不同领域的知识,在单一模型中解决多个任务。
Nevertheless, it requires the presence of all task data to train this model.
然而,训练该模型需要所有任务的数据。
In the continual learning regime, tasks are presented in a sequential fashion.
在持续学习模式中,任务是按顺序依次呈现的。(多任务学习是同时学习多个任务,而持续学习是依次学习多个任务,持续学习和人的学习方式更相近,并且更符合复杂多变环境下的实际需求)
Actually, continual learning 8 , 9 ^{8,9} 8,9has been proposed for several decades, which requires to learn SMT without catastrophic forgetting 6 , 7 ^{6,7} 6,7.
事实上,持续学习已经被提出几十年了,要求学习SMT时不要有灾难性的遗忘。
Recently, several advances in machine learning have been made to offer different solutions to overcome catastrophic forgetting.
最近,机器学习的一些进展为克服灾难性遗忘提供了不同的解决方案。
A classical method is to fine-tune a pretrained task on the target one.
经典的方法是在目标任务上微调预先训练的任务。
Generally speaking, it uses the optimal settings of old tasks to help initialize for the next ones, which
has been shown to be a successful method.
一般来说,它使用旧任务的最佳化结果来帮助初始化下一个任务,这已被证明是一种成功的方法。
However, this method gradually forget how to perform old tasks as training new tasks progresses 13 ^{13} 13.
然而,随着训练新任务的进行,这种方法逐渐忘记了如何执行旧任务(只关注了迁移能力,而没有关注稳定性)。
By introducing synaptic consolidation for artificial neural networks, Elastic weight consolidation (EWC) 12 ^{12} 12 proposes to remember old tasks through employing Fisher regularisers to keep some previous weights unchanged.
通过将突触整合引入人工神经网络,弹性权重整合(EWC)通过Fisher正则化器来保留部分以前的任务权重以记住旧任务。
Besides, Lee 19 presents an incremental moment matching (IMM) algorithm from a neural network weight level to estimate the mixture of Gaussian posterior distributions of different tasks so that
catastrophic forgetting problem could be resolved.
此外,Lee提出了一种基于神经网络权值水平的增量矩匹配(IMM)算法,以估计不同任务的高斯后验分布的混合,从而解决灾难性遗忘问题。
However, these approaches only achieve good performances on similar tasks, since the regularization constraint is obtained in a neighbourhood of one possible minimizer of previous tasks.
然而,这些方法只能在相似任务上获得良好的性能,因为正则化约束是在以前任务的一个可能极小值的邻域中获得的。
Learning without Forgetting (LwF) 14 ^{14} 14 takes advantage of the output for new task to approximate the recorded output from the original network, which benefits the preservation of responses on the old tasks.
无遗忘学习(LwF)利用新任务的输出来近似原始网络的输出,这有利于保留对旧任务的响应。
However, 20 shows that LwF could reduce the performance when faced with a sequence of tasks that are drawn from different distributions.
然而,当面临来自不同分布的任务序列时,LwF性能可能会降低。
Build upon this framework, 16 ^{16} 16introduce an additional under-complete autoencoder to construct a submanifold of important features for different tasks, which tries to restrict task distributions to enable more reasonable knowledge distillation loss 14 ^{14} 14.
在这个框架的基础上,[16]引入一个额外的欠完备自动编码器,为不同的任务构造一个重要特征的子流形,它试图限制任务分布,以实现更合理的知识提取损失[14]。
Even though this method achieve good performance in image classification tasks, it has to train extra autoencoders for each new task.
尽管这种方法在图像分类任务中取得了良好的性能,但它必须为每个新任务训练额外的自动编码器。
Generative Motor Reflexes (GMR) 17 ^{17} 17is the method with some similarities to our method.
生成性运动反射(GMR)是一种与我们的方法有一些相似之处的方法。
However, it is not designed for continual learning, but rather for learning robust robotic manipulation policy in a single task.
然而,它不是为了持续学习而设计的,而是为了在单个任务中学习鲁棒的机器人操作策略。
This Generative Motor Reflex policy is implemented under the framework of Guided Policy Search 21, which assumes access to all tasks at any time.
这种生成性运动反射策略是在引导策略搜索的框架下实现的,该框架假设可以随时访问所有任务。
Besides, instead of optimizing motor reflex, we directly consider to learn policy for torque control commands.
此外,我们没有优化运动反射,而是直接考虑学习转矩控制命令的策略。
3.提出的方法Proposed Method
A.任务数据集中的准备工作Preliminaries in Task Dataset
As the traditional continual learning problems mostly focus on how to perform image classification tasks, it is not difficult to handle tasks sequentially with an supervised learning manner.
由于传统的连续学习问题主要集中在如何执行图像分类任务上,因此用监督学习顺序处理任务并不困难。
Generally speaking, researchers basically are free and easy to access the image classification datasets, and most of them are well labelled.
一般来说,研究人员基本上可以免费、很容易地访问图像分类数据集,而且大多数数据集都有很好的标签。
For robotics tasks, however, to provide relevant datasets for continual learning is not simple and facile.
然而,对于机器人任务来说,为持续学习提供相关数据集并不简单和容易。
For example, in a robotic manipulation problem, it is hard to find a ground truth at each time step in a complicated environment to guide the action.
例如,在机器人操作问题中,在复杂环境中的每一个时间步都很难找到真值来指导操作。
Moreover, robotic trajectory samples commonly appear in a temporal relationship which is intractable to find a mapping like an image classification task between images and labels.
此外,机器人轨迹样本通常以时变形式出现,很难找到类似图像分类任务中图像到标签之间的映射。
Even if loss function could be employed to label task data, it still may deviate the true data distribution since the accumulated error will increase when solving control torques step by step.
即使使用损失函数来标注任务数据,也可能会偏离真实的数据分布,因为在逐步求解控制力矩时,累积误差会增加。
To address robotic tasks in a supervised manner, we have to inevitably collect relevant labelled task samples.
为了以有监督的方式处理机器人任务,我们不可避免地收集相关的有标记任务样本。
Fortunately, in reinforcement learning, state-action pairs could be generated to construct task dataset for robotic manipulation problem.
幸运的是,在强化学习中,可以生成状态-动作对来构建机器人操作问题的任务数据集。
Here, we employ guided policy search (GPS)^ [W. H. Montgomery and S. Levine, “Guided policy search via approx-imate mirror descent,” in Advances in Neural Information Processing Systems, 2016, pp. 4008–40] to provide state-action pairs.
在这里,我们使用引导策略搜索(GPS)来提供状态-动作对。
To this end, we could run GPS to resolve corresponding action when given a state so that task dataset (i.e. state-action pairs) could be constructed.
为此,我们可以在给定状态时执行GPS来寻找相应的操作,以便构建任务数据集(即状态-操作对)。
B.任务表述 Problem Formulation
The proposed Primitives Generation Policy Learning (PGPL) architecture consists of two components, a primitives generation and policy learning.
提出的原语生成策略学习(PG-PL)体系结构由两部分组成,原语生成和策略学习。
Two components are learned together with an end-to-end manner for each task with the constructed dataset.
两个部分都是通过所构建的数据集以端到端的方式学习每个任务。
Figure 1 illustrates the architecture when PGPL is employed to address SMT in robotics.
图1说明了PGPL用于解决机器人中的SMT时的体系结构。
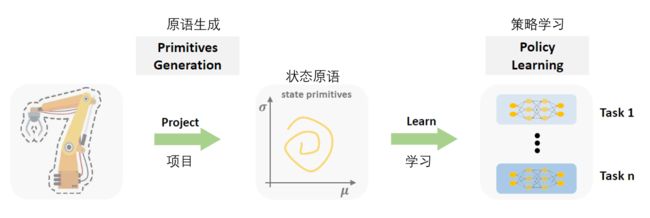 Fig. 1. The architecture of the proposed method. 图1 提出方法的架构 Fig. 1. The architecture of the proposed method. 图1 提出方法的架构
|
There are two components in PGPL. The primitives generation focuses on generating state primitives from task space.
PGPL中有两个组件。原语生成侧重于从任务空间生成状态原语。
Build upon these state primitives, we could train separate policy for each task with policy learning component.
基于这些状态原语,我们可以使用策略学习组件为每个任务训练单独的策略。
After generating state primitives for current task, primitives generation component is kept unchanged to subsequent tasks.
为当前任务生成状态原语后,原语生成组件对后续任务保持不变。
There are two main reasons behind this.
这背后有两个主要原因。
One of them is that robotic trajectories in some tasks present similarity to some degree.
其中之一是机器人在某些任务中的轨迹呈现出一定程度的相似性。
For instance, inserting peg and opening door, both of them require agent to learn a straight line to approximate target and a certain action along a direction to reach target, which makes visited trajectories show some similarity in state space.
例如,插销和开门,这两种方法都要求智能体学习一条直线来逼近目标,以及沿某个方向的执行特定动作来到达目标,这使得相应的轨迹在状态空间中表现出一定的相似性。
And the other reason is that these generated state primitives are capable of describing basic features of the task, which possess a certain degree of versatility to other similar tasks.
另一个原因是,这些生成的状态原语能够描述任务的基本特征,对其他类似任务具有一定程度的通用性。
Hence, we propose to keep the primitives generation component unchanged after learning the first task, so that it can project the original state of different task to similar state primitives which benefit for subsequent policy learning.
因此,我们建议在学习第一个任务后保持原语生成组件不变,以便将不同任务的原始状态投射到相似的状态原语,从而有利于后续的策略学习。
C. 原语生成Primitives Generation
In order to generate appropriate state primitives, the primitives generation component must satisfy two properties.
为了生成适当的状态原语,原语生成组件必须满足两个属性。
Firstly, generated state primitives are capable of describing the basic features of the task, which can reflect the original state in task space to some degree 22.
首先,生成的状态原语能够描述任务的基本特征,在一定程度上反映任务空间中的原始状态。
Secondly, primitives generation component is of value to learning other tasks.
其次,原语生成组件对学习其他任务有帮助。
To meet these two requirements, we employ the Variational Autoencoder (VAE) 18 ^{18} 18to construct our primitives generation component (shown in Figure 2).
为了满足这两个要求,我们使用变分自动编码器(VAE)来构造原语生成组件(如图2所示)。
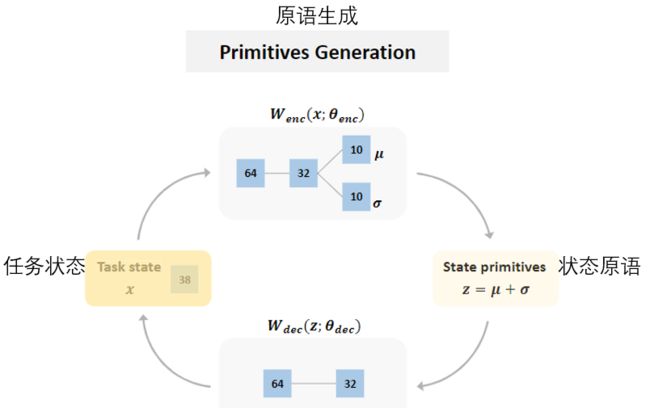 Fig. 2. The primitives generation component. A variational autoencoder is employed to generate state primitives by encoding the state x with $W_{enc}$ and reconstructing it with $W_{dec}$. The number in the box stands for the corresponding number of neurons. 图2 原语生成组件。通过使用$W_{enc}$对状态x进行编码,并使用$W_{dec}$.对其进行重构,使用变分自动编码器生成状态原语。方框中的数字代表相应的神经元数量。 Fig. 2. The primitives generation component. A variational autoencoder is employed to generate state primitives by encoding the state x with $W_{enc}$ and reconstructing it with $W_{dec}$. The number in the box stands for the corresponding number of neurons. 图2 原语生成组件。通过使用$W_{enc}$对状态x进行编码,并使用$W_{dec}$.对其进行重构,使用变分自动编码器生成状态原语。方框中的数字代表相应的神经元数量。
|
Generally, A VAE is composed of two parts: an encoder network and a decoder network.
通常,VAE由两部分组成:编码器网络和解码器网络。
Therein, the encoder network is responsible for mapping an input to a latent representation, while the decoder network tries to recover the input from the latent representation.
其中,编码器网络负责将输入映射到潜在表示,而解码器网络尝试从潜在表示恢复输入。
Specifically speaking, under the weights θ e n c \theta_{enc} θenc an encoder network W e n c W_{enc} Wenc translates an input (i.e. state x) to a mean μ and a standard deviation σ by
[ μ , σ ] = W e n c ( x ; θ e n c ) , ( 1 ) [μ, σ] = W_{enc}(x; θ_{enc}),(1) [μ,σ]=Wenc(x;θenc),(1)
具体地说,在权重 θ e n c \theta_{enc} θenc下,编码器网络 W e n c W_{enc} Wenc 使用公式(1)将输入(即状态x)转换为平均μ和标准偏差σ。
then a latent representation could be obtained by z = μ + σ.
然后可以通过z=μ+σ获得潜在表示。
That is to say, we can achieve a state primitives z following:
z = W e n c ( x ) , x ∼ p ( z ∣ x ; θ e n c ) . ( 2 ) z = W_{enc}(x), x\sim p(z|x; θ_{enc}). (2) z=Wenc(x),x∼p(z∣x;θenc).(2)
也就是说,我们可以通过公式(2)得到一个状态原语z。
Accordingly, the reconstructed input x could be solved by the
decoder network W d e c W_{dec} Wdec with the weights θ d e c θ_{dec} θdec:
x ^ = W d e c ( z ) , x ^ ∼ q ( x ^ ∣ z ; θ d e c ) . ( 3 ) \widehat{x} = W_{dec}(z), \widehat{x} ∼ q(\widehat{x}|z; θ_{dec}). (3) x =Wdec(z),x ∼q(x ∣z;θdec).(3)
因此,重构的输入x可由解码器网络 W d e c W_{dec} Wdec以权重 θ d e c θ_{dec} θdec通过公式(3)求解。
The reconstruction loss L d a t a L_{data} Ldata in VAE is the negative expected log-likelihood of the input x.
L d a t a = − E p ( z ∣ x ) [ l o g q ( x ∣ z ) ] . ( 4 ) L_{data} = −E_{p(z|x)}[logq(x|z)]. (4) Ldata=−Ep(z∣x)[logq(x∣z)].(4)
VAE中的重建损失 L d a t a L_{data} Ldata是输入x的负对数似然,如公式(4)。
Thus, we can utilize reconstruction loss L d a t a L_{data} Ldata to generate the state primitives z which are the latent representation of the original state in task space.
因此,我们可以利用重构损失 L d a t a L_{data} Ldata生成状态原语z,这是原始状态在任务空间中的潜在表示。
For the second property in the primitives generation component, we employ the distribution of state primitives z to address this problem.
对于原语生成组件中的第二个属性,我们使用状态原语z的分布来解决这个问题。
To be specific, VAE has an ability to control the distribution of latent representation.
具体来说,VAE具有控制潜在表征分布的能力。
If p ( z ∣ x ) p(z|x) p(z∣x)follows an independent unit Gaussian distribution, then the distribution p ( z ) p(z) p(z) will approximate an independent unit Gaussian distribution by:
p ( z ) = ∑ x p ( z ∣ x ) p ( x ) = ∑ x N ( 0 , 1 ) p ( x ) = N ( 0 , 1 ) , ( 5 ) p(z) = \sum_x p(z|x)p(x) =\sum_x N (0, 1)p(x) = N (0, 1), (5) p(z)=x∑p(z∣x)p(x)=x∑N(0,1)p(x)=N(0,1),(5)
如果 p ( z ∣ x ) p(z|x) p(z∣x)服从独立的单位高斯分布,那么如式(5),分布 p ( z ) p(z) p(z)将是一个独立的单位高斯分布。
which makes it more reasonable to generate latent variables from N ( 0 , I ) N (0, I) N(0,I).
这使得从 N ( 0 , I ) N (0, I) N(0,I)生成潜在变量更加合理。
To meet this precondition, the Kullback-Leibler
(KL) divergence L k l L_{kl} Lkl between the latent representation p ( z ∣ x ) p(z|x) p(z∣x) and N ( 0 , I ) N(0, I) N(0,I) has to be considered:
L k l = D k l ( p ( z ∣ x ) ∣ ∣ N ( 0 , I ) ) . ( 6 ) L_{kl} = D_{kl}(p(z|x)||N (0,I)). (6) Lkl=Dkl(p(z∣x)∣∣N(0,I)).(6)
为了满足这个前提条件,必须考虑潜在表示 p ( z ∣ x ) p(z|x) p(z∣x)和 N ( 0 , I ) N(0, I) N(0,I)之间的KL距离,如式(6)所示。
Therefore, different tasks can establish a relationship with N ( 0 , I ) N (0, I) N(0,I) accordingly.
因此,不同的任务可以相应地与 N ( 0 , I ) N (0, I) N(0,I) 建立关系。
To some extent, state primitives of current task build a connection with subsequent task learning.
在某种程度上,当前任务的状态原语与后续任务学习建立了联系。
D. 策略学习Policy Learning
On the one hand, primitives generation component is capable of generating state primitives to solve basic features of different tasks, which is benefit for learning a task.
一方面,原语生成组件可以生成状态原语,以作为不同任务的基本表征,这有利于任务的学习。
But on the other hand, these shared state primitives are not enough to describe each task perfectly since they are only the state submanifold of original task space.
但另一方面,这些共享状态原语不足以完美地描述每个任务,因为它们只是原始任务空间的状态子流形。
To perform every task sequentially, we have to compensate these inaccurate state primitives representation, which requires that every basic
feature of each task should be taken into consideration.
为了按顺序执行每个任务,我们必须补偿这些不准确的状态原语表示,这要求每个任务的每个基本特征都应该被考虑在内。
For this end, we need to handle each task separately to some extent.
为此,我们需要在一定程度上分别处理每项任务。
Here, build upon state primitives, we propose to train each task with separate policy neural network, then different control torques could be obtained to perform corresponding task.
此处,我们建议基于状态基元使用单独的策略神经网络来训练每个任务,然后获得不同的控制力矩来执行相应的任务。
Given the generated state primitives z z z, policy neural network f i f_i fi for task i i i and corresponding output target u i u^i ui, we can training the policy learning component through optimizing the following loss function:
L f i = min θ f i l ( f i ( z ) , u i ) ( 7 ) L_{f_i} = \min_{θ_{f_i}}l(f_i(z), u^i) (7) Lfi=θfiminl(fi(z),ui)(7)
给定生成的状态原语 z z z、任务 i i i的策略神经网络 f i f_i fi 和相应的输出目标 u i u^i ui,我们可以通过优化式(7)所示的损失函数来训练策略学习组件,
where the notation L f i L_{f_i} Lfi denotes the loss in the policy learning component f i f_i fi for task i i i with the corresponding parameters θ f i θ_{f_i} θfi to be optimized.
其中符号 L f i L_{f_i} Lfi 表示任务 i i i 的策略学习组件 f i f_i fi 的损失,相应的待学习参数表示为 θ f i θ_{f_i} θfi 。
If the number of task to learn is M , we have to train M sets of neural network parameters for policy learning component.
如果要学习的任务数为M,我们必须为策略学习组件训练M组神经网络参数。
Even though generated state primitives are shared between different tasks, we have to decide which set of parameters to load for policy learning component when executing a task.
即使生成的状态原语在不同的任务之间共享,我们也必须决定在执行任务时为策略学习组件加载哪组参数。
That is to say, the corresponding task identifier I must be given to indicate parameters.
也就是说,必须给出相应的任务标识符I来指明参数。
Fortunately, we do not need extra step to obtain task identifier.
幸运的是,我们不需要额外的步骤来获取任务标识符。
When studying primitives generation component, reconstruction loss L d a t a i L_{data_i} Ldatai of each task i i i on the training dataset X i X_i Xi could be resolved in VAE accordingly:
L d a t a i = − E p ( z ∣ x i ) [ l o g q ( x i ∣ z ) ] , x i ∈ X i , ( 8 ) L_{data_i} = −E_{p(z|x_i )}[logq(x_i|z)], x_i ∈ X_i, (8) Ldatai=−Ep(z∣xi)[logq(xi∣z)],xi∈Xi,(8)
在研究原语生成组件时,训练数据集 X i X_i Xi上每个任务i的重建损失 L d a t a i L_{data_i} Ldatai可以在VAE中使用式(8)相应地计算出来。
where reconstruction loss term L d a t a i L_{data_i} Ldatai corresponds to task i i i, whereas the VAE is established for all tasks.
其中重建损失项 L d a t a i L_{data_i} Ldatai特定于任务 i i i,而VAE则是针对所有任务建立的。
When given a task j j j for testing, we firstly employ the VAE to compute the reconstruction loss L d a t a j L_{data_j} Ldataj by sampling a trajectory, and then make a comparison with the terms L d a t a i , i = 1 , 2 , . . . , M L_{data_i} , i = 1, 2, . . . , M Ldatai,i=1,2,...,M which are already solved during the training phase.
当给定测试任务 j j j时,我们首先使用VAE通过采样轨迹来计算重建损失 L d a t a j L_{data_j} Ldataj,然后与训练阶段已经求得的 L d a t a i , i = 1 , 2 , . . . , M L_{data_i} , i = 1, 2, . . . , M Ldatai,i=1,2,...,M进行比较。
Since reconstruction loss on the training dataset
is related to the loss on the testing dataset within the same task, we could choose the most similar loss term to determine the task identifier I by:
I = a r g m i n i ‖ L d a t a j − L d a t a i ‖ 2 , i = 1 , 2 , . . . , M ( 9 ) I = argmin_i‖L_{data_j} − L_{data_i} ‖^2, i = 1, 2, . . . , M (9) I=argmini‖Ldataj−Ldatai‖2,i=1,2,...,M(9)
由于同一任务训练数据集上的重建损失与测试数据集上的损失有关,如式(9),我们可以选择最相似的损失项来确定任务标识符I。
More specifically, every task follows a different distribution in which the data belonging to task j j j are adopted to solve the corresponding loss term L d a t a j L_{data_j} Ldataj , so other tasks i ( i ≠ j ) i(i \neq j) i(i=j) will produce greater diversity on the loss term.
更具体地说,每个任务都遵循不同的分布,其中属于任务 j j j的数据被用来计算相应的损失项 L d a t a j L_{data_j} Ldataj,因此其他任务 i ( i ≠ j ) i(i \neq j) i(i=j)将在损失项上提高更多的多样性。
Therefore, the correct task identifier I I I could be achieved by comparing these reconstruction loss terms.
因此,通过比较这些重建损失项,可以获得正确的任务标识符 I I I。
In addition, when these tasks behave more differently from each other, it will be easier to obtain different reconstruction error terms with greater diversity which helps to recognize the
correct identifier I I I.
此外,当这些任务相差较大时,将更容易获得具有更大多样性的不同重建损失项,这有助于识别正确的标识符 I I I。
E. 原语生成策略学习Primitives Generation Policy Learning
In PGPL architecture, we train two components in an end-to-end manner, which involves to learn the basic state primitives as well as individual policies.
在PGPL架构中,我们以端到端的方式训练两个组件,同时学习基本状态原语和个性化策略。
Therefore, the total loss L P G P L L_{PGPL} LPGPL could be presented as the following:
L P G P L = α L d a t a + β L k l + L f i ( 10 ) L_{PGPL} = αL_{data} + βL_{kl} + L_{f_i} (10) LPGPL=αLdata+βLkl+Lfi(10)
因此,总损失 L P G P L L_{PGPL} LPGPL可以表示为式(10)所示。
where L d a t a L_{data} Ldata denotes the reconstruction loss in VAE, L k l L_{kl} Lkl describes the KL divergence between state primitives and a unit Gaussian distribution, and L f i L_{f_i} Lfi presents the policy learning loss in primitives generation component for each task i i i.
其中 L d a t a L_{data} Ldata表示VAE中的重建损失, L k l L_{kl} Lkl表示状态原语和单位高斯分布之间的KL距离, L f i L_{f_i} Lfi 表示每个任务 i i i的原语生成组件中的策略学习损失。
Besides, α, β are the corresponding hyperparameters which weight the importance of state primitives for all tasks.
此外,α,β是对应的超参数,它对所有任务的状态基元的重要性进行加权。
When training on a new task, previously trained VAE is utilized to construct state primitives.
在对新任务进行训练时,以前训练过的VAE被用来构造状态原语。
In this manner, we can project different task data with the same mapping function to generate similar state primitives so that tasks elementary
features could be described.
通过这种方式,我们可以使用相同的映射函数投射不同的任务数据,以生成相似的状态原语,从而可以描述任务的基本表征。
For each task, we introduce separate policy learning component, which gives the architecture more flexibility to adapt itself to different tasks.
对于每项任务,我们都引入了单独的策略学习组件,这使体系结构能够更灵活地适应不同的任务。
Hence, control torques can be solved to perform each task accordingly.
因此,可以通过求解控制力矩来执行相应的每项任务。
Meanwhile, task identifiers can be obtained by comparing VAE loss among different tasks.
同时,通过比较不同任务之间的VAE损失,可以获得任务标识符。
4.实验EXPERIMEN
The proposed method is compared against the several baselines on robotic tasks.
将所提出的方法与机器人任务的多条基线进行了比较。
We consider two tasks learned sequentially to evaluate the effectiveness of overcoming catastrophic forgetting.
我们顺序学习两个任务来评估算法克服灾难性遗忘的有效性。
A.实验设置Experimental Settings
1) 环境Environment:
Two robotic manipulation tasks are constructed in the MuJoCo simulation environment 23 to evaluate the proposed method.
在MuJoCo仿真环境中构造两个机器人操作任务,以评估所提出的方法。
Figure 3 shows the relevant experimental environments for simulation.
图3展示了用于模拟的相关实验环境。
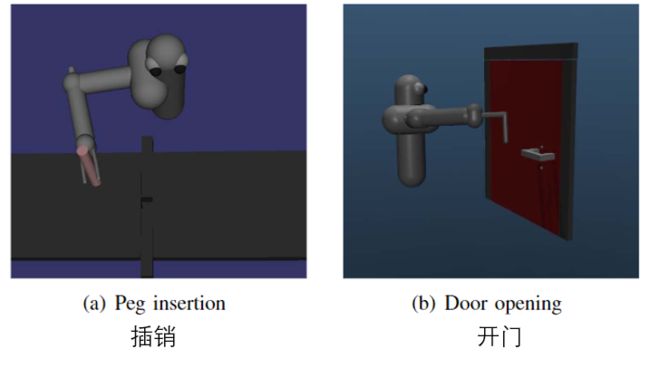 Fig. 3. Illustrative screenshots of environments. 图3 环境展示截图 Fig. 3. Illustrative screenshots of environments. 图3 环境展示截图
|
Peg insertion requires to control a 7 degree of freedom (DoF) 3D robot arm to insert a tightfitting peg into a specified hole, while door opening requires to grasp the handle and pulling the door to a target angle with a 6 DoF 3D arm.
插销需要控制一个7自由度3D机械臂,将一个紧密配合的插销插入指定的孔中,而开门需要抓住把手,并用一个6自由度3D机械臂将门拉到目标角度。
The input state consists of joint angles, end-effector angles and their velocities, and the action includes motor torque command of each joint.
输入状态包括关节角度、末端执行器角度及其速度,以及包括每个关节的电机扭矩指令在内的动作。
More precisely, there are 26 dimensional state information and 7 torque commands for peg insertion task, while door opening task requires to learn a 6 dimensional action based on a 38
dimensional state.
更准确地说,插销任务有26维状态信息和7个扭矩命令,而开门任务需要学习基于38维状态的6维动作。
2) 数据集Datasets
For peg insertion task, the Mirror Descent
GPS (MDGPS) 22 ^{22} 22, a variant of GPS, is adopted to produce corresponding task dataset from 4 different training positions (shown in Figure 4).
对于插销任务,采用GPS的一种变体镜像下降GPS(MDGPS),从4个不同的训练位置生成相应的任务数据集(如图4所示)。
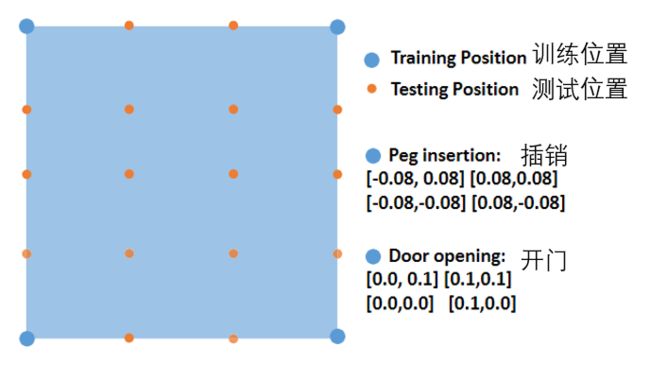
After optimizing this MDGPS agent, we could obtain 40 trajectories with 100 steps (i.e. 4000 state-action pairs) for this task to perform subsequent learning.
优化此MDGPS智能体后,我们可以为该任务获得40条100步的轨迹(即4000个状态-动作对),以执行后续学习。
Considering inherently discontinuous problems in door opening task, we use PILQR algorithm24 to generate corresponding task dataset.
考虑到开门任务中固有的不连续问题,我们使用PILQR算法生成相应的任务数据集。
Similarly, 4000 state-action pairs will be collected for this task.
同样,将为此任务收集4000个状态操作对。
In addition, to evaluate the effectiveness of the proposed PGPL method, different initial positions are utilitzed to testify whether the agent can finish the task sequentially.
此外,为了评估所提出的PGPL方法的有效性,使用了不同的初始位置来验证智能体是否可以顺序完成任务。
To be specific, for peg insertion task, we choose 81 points uniformly in the square constructed by 4 training positions, while 121 testing point are obtained in the same way for door opening task.
具体来说,对于插销任务,我们在由4个训练位置构成的正方形中均匀地选择81个点,而对于开门任务,我们以相同的方式获得121个测试点。
3) 架构Architecture
Instead of taking image as a visual observation, we employ raw data directly collected from sensors
in the simulation environment to train the PGPL architecture.
我们没有将图像作为视觉观察,而是在模拟环境中使用直接从传感器收集的原始数据来训练PGPL体系结构。
The proposed architecture consists of two components: primitives generation and policy learning.
该体系结构由两部分组成:原语生成和策略学习。
For primitives generation component, we design a multi-layer perceptrons (MLP) with the structure of [38 − 64 − 32 − 10] to generate the mean and standard deviation of state primitives in VAE with encoder network W e n c W_{enc} Wenc and corresponding decoder network W d e c W_{dec} Wdec.
对于原语生成组件,我们设计了一个结构为[38− 64− 32− 10]的多层感知器(MLP),使用编码器网络 W e n c W_{enc} Wenc和相应的解码器网络 W d e c W_{dec} Wdec,来生成VAE中状态原语的平均值和标准偏差。
As for policy learning component, we employ separate MLP with [10 − 32 − 7] for each task.
对于策略学习模块,我们针对每个任务采用了单独的[10− 32− 7]的 MLP。
The activation function ReLU is applied to the whole architecture except for the last fully connected linear layer.
除最后一个全连接线性层外,整个架构都采用ReLU作为激活函数。
Note that even though the dimension of state in two tasks are different, we could conduct a zero padding to render the same input dimension for the neural network.
即使两个任务中的状态维度不同,我们也可以通过零填充,为神经网络呈现相同的输入维度。
In our experiment, peg insertion task will increase its state dimension from 26 to 38 by zero padding.
在我们的实验中,插销任务通过零填充将其状态维数从26增加到38。
Moreover, since door opening task only involves 6 dimensional action, we will extract corresponding torque commands from the last
layer to perform the task.
此外,由于开门任务只涉及6维动作,我们将从最后一层提取相应的扭矩命令来执行该任务。
Here, the neural network is trained using an ADAM optimizer with the momentum term 0.9 and initial learning rate 0.001.
这里,神经网络使用ADAM优化器进行训练,动量项为0.9,初始学习率为0.001。
Besides, we set hyperparameter α for reconstruction loss in VAE to 0.7, a KL divergence coefficient β = 0.001, and batch size 25.
此外,我们将VAE中重建损失的超参数α设置为0.7,KL发散系数β=0.001,批量大小为25。
Epochs are trained to 100, 150 for peg insertion and door opening task, respectively.
训练轮数插销和开门任务分别被设置为100、150。
4)比较方法 Compared Methods:
The proposed PGPL architecture is compared with other 3 methods.
将提出的PGPL体系结构与其他3种方法进行了比较。
Finetuning optimizes each new task using the previous task model as initialization.
**FineTunning(微调)**使用以前的任务模型作为初始化来优化每个新任务。
Elastic weight consolidation (EWC) introduces the Fisher information obtained from the previous task to regularize the new task learning, and incremental moment matching (IMM) reestimates the posterior distributions of different tasks to solve catastrophic forgetting problem.
**弹性权重整合(EWC)**引入从先前任务中获得的Fisher信息来规范新的任务学习,**增量矩匹配(IMM)**重新匹配不同任务的后验分布来解决灾难性遗忘问题。
o make a fair comparison, the same neural network settings are adopted except for network structure designed as [38 − 64 − 100 − 64 − 32 − 7] which tries to imitate the structure in PGPL.
为了进行公平比较,采用与PGPL中相似的[38 − 64 − 100 − 64 − 32 − 7] 的网络结构。
B. 状态原语生成State Primitives Generation
The primitives generation component in the context of continual learning is typically important since it is responsible for generating state primitives so that the basic features of the task could be solved for subsequent learning.
在持续学习环境中,原语生成组件通常很重要,因为它负责生成状态原语,为后续学习任务的提供基本表征。
At the same time, it has some ability to generalize to other similar tasks.
同时,它也有一定的能力在相似任务间进行泛化。
Figure 5 shows the learned information about state primitives for different tasks during the training.
图5显示了训练期间不同任务学习到的状态原语的信息。
 Fig. 5. Results of mean and standard deviation of state primitives (sp for short) in VAE for two tasks. We can divide state primitives coarsely into two groups.Group 1 contains sp2, sp3, sp6, sp7, sp8 and sp9, while the rest of state primitives (i.e. sp1, sp4, sp5 and sp10) constitute the group 2. Note that standard deviation term located in longitudinal coordinates actually describes the log function of the square of standard deviation logσ2 图5。两项任务VAE中状态基元(简称sp)的平均值和标准差结果。我们可以粗略地将状态原语分为两组。第1组包含sp2、sp3、sp6、sp7、sp8和sp9,而其余的状态原语(即sp1、sp4、sp5和sp10)构成第2组。注意,位于纵坐标中的标准偏差项实际上描述了标准偏差对数σ2平方的对数函数。 Fig. 5. Results of mean and standard deviation of state primitives (sp for short) in VAE for two tasks. We can divide state primitives coarsely into two groups.Group 1 contains sp2, sp3, sp6, sp7, sp8 and sp9, while the rest of state primitives (i.e. sp1, sp4, sp5 and sp10) constitute the group 2. Note that standard deviation term located in longitudinal coordinates actually describes the log function of the square of standard deviation logσ2 图5。两项任务VAE中状态基元(简称sp)的平均值和标准差结果。我们可以粗略地将状态原语分为两组。第1组包含sp2、sp3、sp6、sp7、sp8和sp9,而其余的状态原语(即sp1、sp4、sp5和sp10)构成第2组。注意,位于纵坐标中的标准偏差项实际上描述了标准偏差对数σ2平方的对数函数。
|
虽然原语生成组件是在第一个任务中训练的,但它仍然在不同任务之间呈现一些基本表征。
State primitives are mainly divided into two groups and state primitives in each group show some similarity.
状态基元主要分为两组,每组的状态基元都有一定的相似性。
For instance, state primitives in group 1 always increase firstly and then behave an oscillatory descent to achieve a stable value at the end of training.
例如,第一组中的状态基元总是先增加,然后表现出振荡下降,训练结束时达到稳定值。
This observation indicates that primitives generation component is able to capture the basic features among different tasks in spite of only trained on the first one.
这一观察结果表明,原语生成组件能够捕获不同任务之间的基本特征,尽管只在第一个任务上进行了训练。
One possible explanation is that robotic tasks for peg insertion and door opening, to some extent, present some similar patterns during the learning phase.
一种可能的解释是,机器人插销和开门的任务在学习阶段呈现出一定程度上的相似模式。
As Equation 6 presents, since each task builds a KL constrain with an independent unit Gaussian distribution N (0, 1), they establish some inherent relationships correspondingly with each other.
如式6所示,由于每个任务都用独立单位高斯分布建立了KL距离,因此它们彼此建立了一些相应的内在关系。
This can been verified from Figure 5 as well.
这也可以从图5中得到验证。
C. 任务识别Task Identifying
Since each task has the corresponding policy learning component, we have to solve a task identifier to indicate which policy to execute.
由于每个任务都有相应的策略学习组件,我们必须求解任务标识符,以指明要执行的策略。
In fact, there is a discrepancy between different tasks even for the same primitives generation component.
事实上,即使有相同的原语生成组件,不同的任务之间也存在差异。
To explain this problem, we pick a state primitive and plot its learning process for two tasks in Figure 6.
为了解释这个问题,我们选择了一个状态原语,并在图6中绘制了两个任务中该状态原语的学习过程。
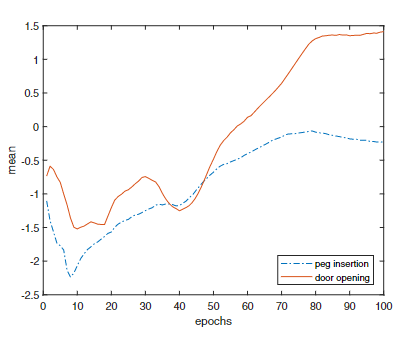 Fig. 6. Result of the mean of state primitive 5 in learning VAE. 图6 VAE学习过程中状态原语5均值展示。 Fig. 6. Result of the mean of state primitive 5 in learning VAE. 图6 VAE学习过程中状态原语5均值展示。
|
Though the state primitive 5 (sp5 for short) belongs to group 2 among these 10 primitives both in two tasks, it presents differently during the
learning process.
虽然状态原语5(简称sp5)属于两个任务的10个原语中属于第二组的,但在学习过程中却表现出不同。
After 50 epochs, sp5 will increase sharply in door opening task and achieve the final mean at 1.41, while in peg insertion task sp5 varies slowly to get a mean of -0.23 at the end.
50轮训练后,sp5在开门任务中会急剧增加,最终平均值为1.41,而在插销任务中,sp5变化缓慢,最终平均值为-0.23。
Therefore, VAE presents some difference in state primitives among different tasks.
因此,VAE在不同任务之间呈现出一些状态原语的差异。
Actually, the loss of VAE could be employed to indicate the corresponding task identifier.
实际上,VAE的损失可以用来作为相应的任务标识符。
Given a task, we sample some trajectories ahead to calculate the average loss under different task policies, and compare the loss term to choose the task identifier.
给定一个任务,我们先对一些轨迹进行采样,计算不同任务策略下的平均损失,并比较损失项来选择任务标识符。
Table I illustrates the relevant result.
表一列出了相关结果。
 TABLE 1 Results of recognizing the task identifier 表1 任务识别符辨识结果 TABLE 1 Results of recognizing the task identifier 表1 任务识别符辨识结果
|
If we sample 5 trajectories to solve VAE loss terms, we can obtain the average reconstruction loss of 2.34 to match corresponding task parameters when testing door opening task.
如果我们采样5条轨迹来求解VAE损失项,我们可以得到平均重建损失2.34,以匹配测试开门任务时相应的任务参数。
It is worth noting that only Data loss (i.e. reconstruction loss) is employed to choose the task identifier since KL loss term in VAE is constrained with an independent unit Gaussian distribution N (0, 1), which makes it present a certain similarity among different tasks.
值得注意的是,由于VAE中的KL损失项受独立单位高斯分布的约束,使得它在不同任务间有哦一定程度的相似性,因此仅使用了数据损失(即重建损失)来选择任务标识符。
D. 克服灾难性遗忘Overcoming Catastrophic Forgetting
In this section, the proposed PGPL method is applied to learn tasks sequentially.
在本节中,所提出的PGPL方法用于顺序学习任务。
Here, we make a comparison with Finetuning, EWC and IMM to verify the effectiveness of PGPL.
在这里,我们与FineTunning、EWC和IMM进行了比较,以验证PGPL的有效性。
Under the same experiment settings, peg insertion and door opening task are learned sequentially among different methods.
在相同的实验设置下,不同的方法依次学习插销和开门任务。
As can be seen from Table II, the proposed method can perform the task well regardless of peg insertion or door opening.
从表II中可以看出,无论是插销还是开门,所提出的方法都能很好地完成任务。
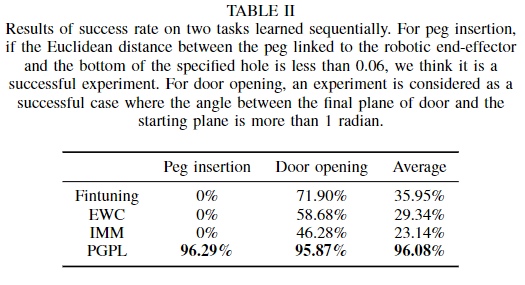 TABLE 2 Results of success rate on two tasks learned sequentially. For peg insertion, if the Euclidean distance between the peg linked to the robotic end-effector and the bottom of the specified hole is less than 0.06, we think it is a successful experiment. For door opening, an experiment is considered as a successful case where the angle between the final plane of door and the startin plane is more than 1 radian. 表1 顺序学习两项任务的成功率。对于插销,如果与机器人末端执行器相连的桩与指定孔底部之间的欧氏距离小于0.06,我们认为这是一个成功的实验。对于开门,如果门的最终平面与起始平面之间的角度大于1弧度,则认为实验是成功的。 TABLE 2 Results of success rate on two tasks learned sequentially. For peg insertion, if the Euclidean distance between the peg linked to the robotic end-effector and the bottom of the specified hole is less than 0.06, we think it is a successful experiment. For door opening, an experiment is considered as a successful case where the angle between the final plane of door and the startin plane is more than 1 radian. 表1 顺序学习两项任务的成功率。对于插销,如果与机器人末端执行器相连的桩与指定孔底部之间的欧氏距离小于0.06,我们认为这是一个成功的实验。对于开门,如果门的最终平面与起始平面之间的角度大于1弧度,则认为实验是成功的。
|
After sequentially learning, we can achieve 96.29% and 95.87% for these two tasks respectively.
经过顺序学习,这两项任务的完成率分别为96.29%和95.87%。
In fact, this result is guaranteed by recognizing task identifier correctly.
事实上,正确识别任务标识符可以保证这一结果。
The last section already verifies the effectiveness of VAE to select task identifier.
最后一节验证了VAE选择任务标识符的有效性。
For other methods, they all forget how to perform the previous task after learning on new tasks, since it is much difficult for them to solve outputs within one set of parameters.
对于其他方法,他们在学习新任务后都会忘记如何执行前一个任务,因为他们很难在同一组参数内求解输出。
To be specific, in robotic manipulation problem, to solve the torque commands for the final output is a regression problem, which is different from the classification problem in image classification.
具体来说,在机器人操作问题中,解决最终输出的扭矩指令是一个回归问题,这与图像分类中的分类问题不同。
More importantly, in order to complete a task, robotic manipulation usually involves to execute a
specific trajectory.
更重要的是,为了完成一项任务,机器人操作通常需要执行特定的轨迹。
Whereas these robotic trajectory appears in a temporal form which means every executed action will have an influence on subsequent decision since new state of trajectory is up to the last state, last action and dynamics in the environment.
然而,这些机器人轨迹是以时间序列形式出现的,这意味着每一个执行的动作都会对后续决策产生影响,因为新的轨迹状态取决于环境中的最后一个状态、最后一个动作和动力学。
Apparently, it will cause accumulated error if we can not learn a relatively precise policy.
显然,如果我们学不到一个相对精确的策略,这会导致累计误差。
But for image classification task, each classification operation is independent from each other.
但对于图像分类任务,每个分类操作都是相互独立的。
To this extent, there actually is some difference between image classification and robotic problem in the field of continual learning.
在这个程度上,图像分类和机器人问题在持续学习领域实际上有一些区别。
Even though EWC has been applied to reinforcement learning problem (e.g. Atari task) with Deep Q Networks (DQN)25, it actually employs task specific information to handle
different tasks.
尽管EWC已被应用于具有深度Q网络(DQN)的强化学习问题(例如Atari任务),但它实际上使用特定于任务的信息来处理不同的任务。
As paper 12 ^{12} 12 stated, “task-specific bias and
gains at each layer” are used, which indicates that it is difficult to handle complex task within only one set of policy.
正如文献[12]所述,“每一层都使用特定于任务的偏置项和增益”,这表明仅在一组策略中处理复杂任务是困难的。
An interesting result is that EWC or IMM loss their advantage than traditional finetuning technique.
一个有趣的结果是EWC或IMM失去了与传统微调技术相比的优势。
One possible explanation is EWC proposes to solve continual learning problem with a Bayesian manner which requires to compute the posterior probability of previous tasks in a Laplace approximate way.
一种可能的解释是,EWC提出用贝叶斯方法解决持续学习问题,该方法要求以拉普拉斯近似方法计算先前任务的后验概率。
Hence, the final solution only works in the neighbourhood of previously learned tasks.
因此,最终的解决方案只适用于先前学习过的任务。
If directly applying this method to complex situation where tasks behave differently from each other, EWC can not find an effective solution to remember previous tasks without catastrophic forgetting.
如果将这种方法直接应用于任务行为不同的复杂情况,EWC无法找到一种有效的方法来记忆以前的任务,而不会造成灾难性的遗忘。
As for IMM, it considers to recompute the neural network parameters by introducing the mixture of Gaussian posterior with averaging operation (with or without Fisher information weighted), which actually is too simple to represent sophisticated behaviours with only one set of policies in the robotic tasks.
对于IMM,它考虑通过引入高斯后验和平均操作(有或没有Fisher信息加权)的混合来重新计算神经网络参数,这实际上太简单,无法用一组策略来表示机器人任务中的复杂行为。
Figure 7 illustrates the variation of task success rate in the learning process of how to open the door.
图7展示了开门任务学习过程中任务成功率的变化。
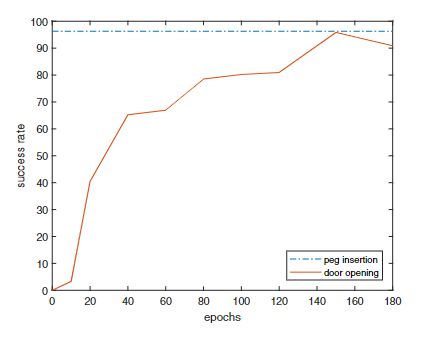 Fig. 7. Result of success rate during the process of learning door opening. 图1. 开门任务学习过程中成功率展示。 Fig. 7. Result of success rate during the process of learning door opening. 图1. 开门任务学习过程中成功率展示。
|
After learning on peg insertion task, the VAE component remains unchanged, and the corresponding policy learning component is kept for this task, which makes the success rate always keep at 96.29%.
在学习插销任务后,VAE组件保持不变,并为该任务保留相应的策略学习组件,使成功率始终保持在96.29%。
With the shared VAE component and training on new policy learning component, we can achieve the optimal result (i.e.95.87%) for door opening task after learning 150 epochs.
通过共享VAE组件和在新的策略学习组件上训练,我们可以在学习150轮迭代后,获得开门任务的最佳结果(即95.87%)。
5. 结论CONCLUSION
This work proposes Primitives Generation Policy Learning, a novel hierarchical architecture to address continual learning problem without catastrophic forgetting.
本研究提出了原语生成策略学习,这是一种新的层次结构,可以解决连续学习问题,而不会造成灾难性遗忘。
Different from traditional continual learning algorithms in image classification,we focus on solving problems sequentially in the field of robotic manipulation.
与传统的图像分类连续学习算法不同,我们专注于机器人操作领域的顺序求解问题。
Specifically speaking, by generating state primitives, we are able to provide some basic state features for policy learning, and indicate which task is being performed by comparing reconstruction loss.
具体来说,通过生成状态原语,我们能够为策略学习提供一些基本的状态特征,并通过比较重建损失来指明正在执行的任务。
And then agent could learn a separate policy with more flexibility to adapt itself to different tasks in the policy learning component.
然后,智能体在策略学习组件中可以学习一个单独策略,以更灵活地适应不同任务。
Relevant experiment on robotic task emonstrates that the proposed method presents substantially improved performance over some other continual learning methods.
对机器人任务的相关实验表明,与其他一些持续学习方法相比,所提出方法在性能上有了显著提高。
Xiong F , Liu Z , Huang K , et al. Primitives Generation Policy Learning without Catastrophic Forgetting for Robotic Manipulation[C]// 2019 International Conference on Data Mining Workshops (ICDMW). 2019. ↩︎
S. Legg and M. Hutter, “Universal intelligence: A definition of machine intelligence,” Minds and Machines, vol. 17, no. 4, pp. 391–444,2007 ↩︎
R. S. Michalski, J. G. Carbonell, and T. M. Mitchell, Machine learning: An artificial intelligence approach. Springer Science & Business Media,2013. ↩︎
R. Caruana, “Multitask learning,” Machine learning, vol. 28, no. 1, pp.41–75, 199 ↩︎
S. Thrun and L. Pratt, Learning to learn. Springer Science & Business Media, 201 ↩︎
M. McCloskey and N. J. Cohen, “Catastrophic interference in connec-tionist networks: The sequential learning problem,” in Psychology of learning and motivation. Elsevier, 1989, vol. 24, pp. 1 ↩︎
R. M. French, “Catastrophic forgetting in connectionist networks,”Trends in cognitive sciences, vol. 3, no. 4, pp. 128–135, ↩︎
S. Thrun, “Lifelong learning algorithms,” Learning to learn, vol. 8, pp.181–209, 1998 ↩︎
W. Hao, J. Fan, Z. Zhang, and G. Zhu, “End-to-end lifelong learning: a framework to achieve plasticities of both the feature and classifier constructions,” Cognitive Computation, pp. 1–13, 20 ↩︎
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521,no. 7553, p. 436, 2 ↩︎
Y. Xie, J. Xiao, K. Huang, J. Thiyagalingam, and Y. Zhao, “Correlation
filter selection for visual tracking using reinforcement learning,” IEEE Transactions on Circuits and Systems for Video Techn ↩︎J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins,A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinskaet al., “Overcoming catastrophic forgetting in neural networks,” Pro-ceedings of the National Academy of Sciences, p. 201611835, 2 ↩︎
R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern
recognition, 2014, pp. 580– ↩︎Z. Li and D. Hoiem, “Learning without forgetting,” IEEE transactions
on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935–2947, 201 ↩︎F. Xiong, B. Sun, X. Yang, H. Qiao, K. Huang, A. Hussain, and Z. Liu, “Guided policy search for sequential multitask learning,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2018 ↩︎
A. Rannen, R. Aljundi, M. B. Blaschko, and T. Tuytelaars, “Encoder
based lifelong learning,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1320–13 ↩︎P. Ennen, P. Bresenitz, R. Vossen, and F. Hees, “Learning robust manipulation skills with guided policy search via generative motor reflexes,” in Robotics and Automation (ICRA), 2019 IEEE International Conference on. IEEE, May. 20 ↩︎
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proceedings of the International Conference on Learning Representations (ICLR), 2014 ↩︎
S.-W. Lee, J.-H. Kim, J. Jun, J.-W. Ha, and B.-T. Zhang, “Overcoming
catastrophic forgetting by incremental moment matching,” in Advances in Neural Information Processing Systems, 2017, pp. 4652–466 ↩︎R. Aljundi, P. Chakravarty, and T. Tuytelaars, “Expert gate: Lifelong
learning with a network of experts,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 3366–3375 ↩︎S. Levine and V. Koltun, “Guided policy search,” in Proceedings of the 30th International Conference on Machine Learning (ICML-13), Jun. 2013, pp. 1–9 ↩︎
X. Yang, K. Huang, R. Zhang, and A. Hussain, “Learning latent features with infinite nonnegative binary matrix trifactorization,” IEEE Transactions on Emerging Topics in Computational Intelligence, no. 99, pp. 1–14, 2018 ↩︎
E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model-based control,” in Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ
International Conference on. IEEE, 2012, pp. 5026–5033. ↩︎[24] Y. Chebotar, K. Hausman, M. Zhang, G. Sukhatme, S. Schaal,and S. Levine, “Combining model-based and model-free updates for
trajectory-centric reinforcement learning,” in Proceedings of the 34th International Conference on Machine Learning (ICML-17), vol. 70, Aug. 2017, pp. 703–711. ↩︎V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G.Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,”
Nature, vol. 518, no. 7540, p. 529, 2015. ↩︎