脑电EEG代码开源分享 【5.特征选择】
往期文章
希望了解更多的道友点这里
0. 分享【脑机接口 + 人工智能】的学习之路
1.1 . 脑电EEG代码开源分享 【1.前置准备-静息态篇】
1.2 . 脑电EEG代码开源分享 【1.前置准备-任务态篇】
2.1 . 脑电EEG代码开源分享 【2.预处理-静息态篇】
2.2 . 脑电EEG代码开源分享 【2.预处理-任务态篇】
3.1 . 脑电EEG代码开源分享 【3.可视化分析-静息态篇】
3.2 . 脑电EEG代码开源分享 【3.可视化分析-任务态篇】
4.1 . 脑电EEG代码开源分享 【4.特征提取-时域篇】
4.2 . 脑电EEG代码开源分享 【4.特征提取-频域篇】
4.3 . 脑电EEG代码开源分享 【4.特征提取-时频域篇】
4.4 . 脑电EEG代码开源分享 【4.特征提取-空域篇】
5 . 脑电EEG代码开源分享 【5.特征选择】
6.1 . 脑电EEG代码开源分享 【6.分类模型-机器学习篇】
6.2 . 脑电EEG代码开源分享 【6.分类模型-深度学习篇】
汇总. 专栏:脑电EEG代码开源分享【文档+代码+经验】
0 . 【深度学习】常用网络总结
脑电EEG代码开源分享 【5.特征选择】
- 往期文章
- 一、前言
- 二、特征选择 框架介绍
- 三、代码格式说明
- 三、脑电特征选择 代码
-
- 3.0 参数设置
- 3.1 特征处理标准化输入
- 3.2 特征候选集数据拼接
- 3.3 特征选择算法
-
- 3.3.1 标准差法
- 3.3.2 显著性检测法
- 3.3.3 瑞利熵法
- 3.3.4 消融特征正确率法
- 总结
- To:新想法、鬼点子的道友:
一、前言
本文档旨在归纳BCI-EEG-matlab的数据处理代码,作为EEG数据处理的总结,方便快速搭建处理框架的Baseline,实现自动化、模块插拔化、快速化。本文以任务态(锁时刺激,如快速序列视觉呈现)为例,分享脑电EEG的分析处理方法。
脑电数据分析系列。分为以下6个模块:
- 前置准备
- 数据预处理
- 数据可视化
- 特征提取(特征候选集)
- 特征选择(量化特征择优)
- 分类模型
本文内容:【5. 特征选择】
提示:以下为各功能代码详细介绍,若节约阅读时间,请下滑至文末的整合代码
由于时间原因,模块化功能性代码有待完善,先挖个坑,后续会将模块融入到整体框架中
二、特征选择 框架介绍
前文我们花了4篇文章讲完了时域、频域、时频域、空域的特征提取,
如何从庞大的特征候选集中找出优质特征,怎么评判和度量特征性能,成为本文【特征选择】的主要问题
特征选择就是从量化的角度,在庞大的候选数据集中择优选取少量优质特征,
有的小伙伴可能认为特征数量越多越好,或者说把全部特征都用上不好么?
真的不好…
个人总结发现特征选择的必要性至少有以下4点:
- 准确性:特征候选集中的劣质特征反而影响分类性能。大家如果将所有特征按一定规则量化后由高到低打分排序,可以看到随着低分特征的加入,准确率反而会出现拐点并下降。
- 鲁棒性:过多的特征会导致分类器过拟合,即分类器仅对指定小范围数据集有效,对外数据集分类的迁移和泛化能力降低。个人经验是,特征个数不多于样本数量的1/4,特征数量越多过拟合现象越严重。
- 即时性:特征候选集不仅占据内存和运算量,还会加大分类器拟合分类曲线时的参数复杂度,按个人经验来说100维度特征较合适,常用笔记本对于500特征的运算就很吃力了,严重影响计算速度。
- 实用性:特征也可以作为指标用于病情定级和认知调控,大多医生针对1-2个有效指标进行判读,强迫医生看满屏的1000个指标,并且告诉他其中99%都没有意义,属实是难为白衣天使了…
特征提取的代码框图、流程如下所示:
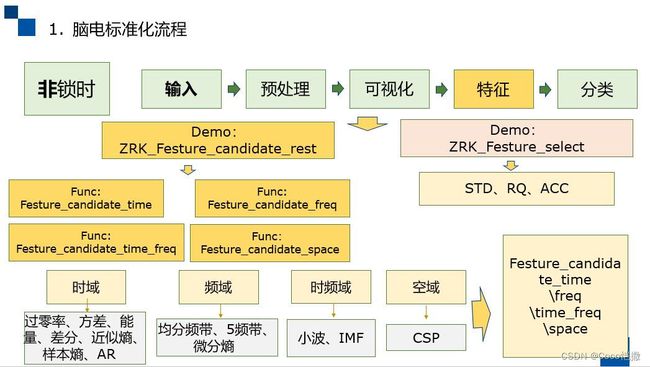
特征选择的主要功能,分为以下4部分:
- 标准差法(波动性)
- P值法(统计性)
- 瑞利熵法(可分性)
- 特征消融正确率法(实践性)
-
标准差法(波动性):标准差法的优势在于简单快速,将目标和非目标样本拼接在一起并求各特征的标准差(std)。其原理在于,过滤掉目标和非目标中特征值波动不大的特征。说人话就是,一个有效特征如果能对目标和非目标分类,必然在目标类和非目标类内的数值有变化,例如在目标样本和非目标样本中特征值均为10,则这个特征在分类时没有区分性。再人话一点的讲,如果把眼睛的数量作为特征区分人和狗,眼睛特征数对于人和狗都是2只,则眼睛个数不适于作为区分特征。(蹲一只傻乎乎说哮天犬三只眼,傻了吧~二郎神才三只眼)

标准差法的不足在于太粗糙了,并没有指向性的选择特征波动性,即波动性小的特征区分性不好,波动性大的特征也不一定好,例如纯噪声波动性很大,却没有任何分类意义。进一步讲,类内波动性大反而不是一件好事,例如步态身份识别的准确率就不如指纹,因为同一个人指纹变化较小,而步态可能因为衣着、疾病、情绪遮罩等波动大的原因而难以分辨。
分类不仅需要波动性,还要有不同类别的区分性,这在P值法中进行了综合考量。 -
P值法(统计性):P值法的优势在于其统计学理论支撑,并且充分考虑了特征的波动性和区分性。一般使用matlab中ttest2函数直接调用。其主要思想在于:若某特征在目标与非目标间是可分的,那么在两类中的分布是具有一定显著性的,即通过显著性检测可以量化特征在目标与非目标间的区分性。这个量化的P值就可代表特征的分布差异,P越小代表特征区分性较好,该特征越易于分类。例如下图(灵魂画手尽力了…),左侧就是某特征在目标和非目标间差异较大,P值相对小易于分类;而右侧难以区分区分性,P值大,难以分类。
如果说P值法有什么缺点,可能样本数量别太小勉强算得上吧。
显著性检测:

-
瑞利熵法(可分性):瑞利熵法的优势在于其指向性,就是为划定分类边界而设计。回答了什么是好的特征这一问题:类间距离大,类内距离小。fisher判别距离也有称为瑞利熵(Rayleigh entropy)。其本质思想是量化目标与非目标样本的聚类、离散程度。其主要公式为 不同类间中心距 除以 各自类内的样本距离,类间距使用欧式距离,类内局使用标准差。该结果越大代表此段数据:1. 不同类之间距离较远。2.并且各自类内样本紧凑。对应就是好划定分类边界。
fisher公式如下:
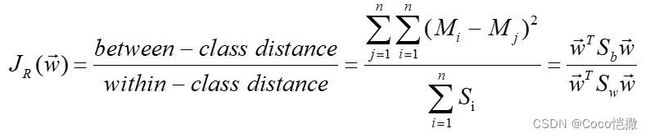
fisher示意图如下:左侧为易分类脑电样本,右侧为难分类脑电样本

-
特征消融正确率法(实践性) :特征消融正确率法的优势在于其实践性,用最朴素的手段回答朴素的问题,直接正确率来评价特征能力。什么特征分类效果好,当然是分类效果好的特征分类效果好了…其实现方法为:直接使用分类器对每个特征单独分类,选择单个分类正确率的特征组成优质特征集合。单个特征正确率的方法虽然表面观上最直接简单,但实践起来有一些隐患,例如:多种分类器的准确率结果往往不一致;分类器每次结果不稳定;单个特征普遍正确率都很低、差异不明显,等等。根源在于当特征融入了分类器变量,特征好不好就不容易说清了。
三、代码格式说明
本文非锁时任务态(下文以静息态代替)范例为:ADHD患者、正常人群在静息状态下的脑模式分类
- 代码名称:代码命名为Festure_select_xxx (Fisher\填一法-贪婪)
- 参数设置:特征候选集\正样本数\负样本数\随机循环个数。
- 输入格式:输入格式承接特征候选集Festure_candidate_xxx(特征域名称)_target/nontarget,并按照单域/全域进行特征排序和打分。
- 输出及保存格式:按照单域/全域进行特征排序和打分,其中各域的打分排序分别保存,保存格式为Festure_select_xxx(特征选择方法)_xx(特征域)_list/score
三、脑电特征选择 代码
提示:代码环境为 matlab 2018
3.0 参数设置
可视化内容可以选择,把希望可视化特征域写在Featute_select_content 中
- 一次进行10人次的批处理,subject_num = [1;10]
- 特征选择候选集包括,时域、频域、时频域、空域:Featute_select_content = [‘time’,‘freq’,‘time_freq’,‘space’];
- 运用标准差、瑞利熵、消融特征正确率,的特征选择方法:Featute_select_method = [‘std’,‘RQ’,‘one_fest_acc’];
%% 0.特征候选集-参数设置
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
data_path = 'C:\Users\EEG\Desktop\basetest_flod\save_fold\';
svae_path = 'C:\Users\EEG\Desktop\basetest_flod\save_fold\';
subject_num = [1;10];
Featute_select_content = ['time\','freq\','time_freq\','space'];
Featute_select_method = ['std','RQ\','one_fest_acc\'];
disp(['||特征域选择范围-参数设置||']);
disp(['特征域内容: ' , Featute_domain_content]);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
3.1 特征处理标准化输入
导入上一步 特征提取 阶段处理后的数据:
%% 1.特征候选集-输入赋值
[Featute_select_candidate_target_data,Featute_select_candidate_nontarget_data,Featute_select_candidate_content,Featute_select_candidate_target_num,Featute_select_candidate_nontarget_num,Featute_select_candidate_target_remain_trial,Featute_select_candidate_nontarget_remain_trial]= Festure_select_gather(Featute_domain_content,data_path,subject_num);
disp(['目标试次剩余: ' , num2str(Featute_select_candidate_target_remain_trial),'||平均: ', num2str(mean(Featute_select_candidate_target_remain_trial))]);
disp(['非目标试次剩余: ' , num2str(Featute_select_candidate_nontarget_remain_trial),'||平均: ', num2str(mean(Featute_select_candidate_nontarget_remain_trial))]);
disp(['目标特征域内-细节特征数量: ' , num2str(Featute_select_candidate_target_num),'||平均: ', num2str(mean(Featute_select_candidate_target_num))]);
disp(['非目标特征域内-细节特征数量: ' , num2str(Featute_select_candidate_nontarget_num),'||平均: ', num2str(mean(Featute_select_candidate_nontarget_num))]);
3.2 特征候选集数据拼接
调用、合并特征候选集的函数:
function [Featute_select_candidate_target_data,Featute_select_candidate_nontarget_data,Featute_select_candidate_content,Featute_select_candidate_target_num,Featute_select_candidate_nontarget_num,Featute_select_candidate_target_remain_trial,Featute_select_candidate_nontarget_remain_trial]= Festure_select_gather(Featute_domain_content,data_path,subject_num)
%% 对于时、频、时频、空的特征候选集汇总
% 输入
% Featute_domain_content 特征域内容
% data_path 特征候选集路径
% subject_num 被试数
% 输出
% Featute_select_candidate_target_data 目标试次特征汇总
% Featute_select_candidate_nontarget_data 非目标试次特征汇总
%
% Featute_select_candidate_content 特征域内-特征细节汇总
%
% Featute_select_candidate_target_num (目标试次)特征域内-细节特征数量
% Featute_select_candidate_nontarget_num (非目标试次)特征域内-细节特征数量
% Featute_select_candidate_target_remain_trial 目标试次剩余试次数
% Featute_select_candidate_nontarget_remain_trial 非目标试次剩余试次数
%% 1.1时域
Festure_candidate_target_time = [];
Festure_candidate_nontarget_time = [];
Featute_content_time = [];
Festure_candidate_num_target_time = [];
Festure_candidate_num_nontarget_time = [];
remain_trial_target_time = [];
remain_trial_nontarget_time = [];
if contains(Featute_domain_content,'time')
Festure_candidate_time_target_file = load([data_path ,'Festure_candidate_time_target_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
Festure_candidate_time_nontarget_file = load([data_path ,'Festure_candidate_time_nontarget_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
stuct_target_name = 'Festure_candidate_time_target';
stuct_nontarget_name = 'Festure_candidate_time_nontarget';
Festure_candidate_target_time = Festure_candidate_time_target_file.(stuct_target_name).data;
Festure_candidate_nontarget_time = Festure_candidate_time_nontarget_file.(stuct_nontarget_name).data;
% fs_down = Festure_candidate_time_target_file.(stuct_target_name).fs_down;
Featute_content_time = Festure_candidate_time_target_file.(stuct_target_name).Featute_time_content;
Festure_candidate_num_target_time = Festure_candidate_time_target_file.(stuct_target_name).Festure_time_candidate_num_target;
Festure_candidate_num_nontarget_time = Festure_candidate_time_nontarget_file.(stuct_nontarget_name).Festure_time_candidate_num_nontarget;
remain_trial_target_time = Festure_candidate_time_target_file.(stuct_target_name).remain_trial_target;
remain_trial_nontarget_time = Festure_candidate_time_nontarget_file.(stuct_nontarget_name).remain_trial_nontarget;
end
%% 1.2频域
Festure_candidate_target_freq = [];
Festure_candidate_nontarget_freq = [];
Featute_content_freq = [];
Festure_candidate_num_target_freq = [];
Festure_candidate_num_nontarget_freq = [];
remain_trial_target_freq = [];
remain_trial_nontarget_freq = [];
if contains(Featute_domain_content,'freq')
Festure_candidate_freq_target_file = load([data_path ,'Festure_candidate_freq_target_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
Festure_candidate_freq_nontarget_file = load([data_path ,'Festure_candidate_freq_nontarget_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
stuct_target_name = 'Festure_candidate_freq_target';
stuct_nontarget_name = 'Festure_candidate_freq_nontarget';
Festure_candidate_target_freq = Festure_candidate_freq_target_file.(stuct_target_name).data;
Festure_candidate_nontarget_freq = Festure_candidate_freq_nontarget_file.(stuct_nontarget_name).data;
% fs_down = Festure_candidate_freq_target_file.(stuct_target_name).fs_down;
Featute_content_freq = Festure_candidate_freq_target_file.(stuct_target_name).Featute_freq_content;
Festure_candidate_num_target_freq = Festure_candidate_freq_target_file.(stuct_target_name).Festure_freq_candidate_num_target;
Festure_candidate_num_nontarget_freq = Festure_candidate_freq_nontarget_file.(stuct_nontarget_name).Festure_freq_candidate_num_nontarget;
remain_trial_target_freq = Festure_candidate_freq_target_file.(stuct_target_name).remain_trial_target;
remain_trial_nontarget_freq = Festure_candidate_freq_nontarget_file.(stuct_nontarget_name).remain_trial_nontarget;
end
%% 1.3时频域
Festure_candidate_target_time_freq = [];
Festure_candidate_nontarget_time_freq = [];
Featute_content_time_freq = [];
Festure_candidate_num_target_time_freq = [];
Festure_candidate_num_nontarget_time_freq = [];
remain_trial_target_time_freq = [];
remain_trial_nontarget_time_freq = [];
if contains(Featute_domain_content,'time_freq')
Festure_candidate_time_freq_target_file = load([data_path ,'Festure_candidate_time_freq_target_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
Festure_candidate_time_freq_nontarget_file = load([data_path ,'Festure_candidate_time_freq_nontarget_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
stuct_target_name = 'Festure_candidate_time_freq_target';
stuct_nontarget_name = 'Festure_candidate_time_freq_nontarget';
Festure_candidate_target_time_freq = Festure_candidate_time_freq_target_file.(stuct_target_name).data;
Festure_candidate_nontarget_time_freq = Festure_candidate_time_freq_nontarget_file.(stuct_nontarget_name).data;
% fs_down = Festure_candidate_time_freq_target_file.(stuct_target_name).fs_down;
Featute_content_time_freq = Festure_candidate_time_freq_target_file.(stuct_target_name).Featute_time_freq_content;
Festure_candidate_num_target_time_freq = Festure_candidate_time_freq_target_file.(stuct_target_name).Festure_time_freq_candidate_num_target;
Festure_candidate_num_nontarget_time_freq = Festure_candidate_time_freq_nontarget_file.(stuct_nontarget_name).Festure_time_freq_candidate_num_nontarget;
remain_trial_target_time_freq = Festure_candidate_time_freq_target_file.(stuct_target_name).remain_trial_target;
remain_trial_nontarget_time_freq = Festure_candidate_time_freq_nontarget_file.(stuct_nontarget_name).remain_trial_nontarget;
end
%% 1.4空域
Festure_candidate_target_space = [];
Festure_candidate_nontarget_space = [];
Featute_content_space = [];
Festure_candidate_num_target_space = [];
Festure_candidate_num_nontarget_space = [];
remain_trial_target_space = [];
remain_trial_nontarget_space = [];
if contains(Featute_domain_content,'space')
Festure_candidate_space_target_file = load([data_path ,'Festure_candidate_space_target_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
Festure_candidate_space_nontarget_file = load([data_path ,'Festure_candidate_space_nontarget_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))]);
stuct_target_name = 'Festure_candidate_space_target';
stuct_nontarget_name = 'Festure_candidate_space_nontarget';
Festure_candidate_target_space = Festure_candidate_space_target_file.(stuct_target_name).data;
Festure_candidate_nontarget_space = Festure_candidate_space_nontarget_file.(stuct_nontarget_name).data;
% fs_down = Festure_candidate_space_target_file.(stuct_target_name).fs_down;
Featute_content_space = Festure_candidate_space_target_file.(stuct_target_name).Featute_space_content;
Festure_candidate_num_target_space = Festure_candidate_space_target_file.(stuct_target_name).Festure_space_candidate_num_target;
Festure_candidate_num_nontarget_space = Festure_candidate_space_nontarget_file.(stuct_nontarget_name).Festure_space_candidate_num_nontarget;
remain_trial_target_space = Festure_candidate_space_target_file.(stuct_target_name).remain_trial_target;
remain_trial_nontarget_space = Festure_candidate_space_nontarget_file.(stuct_nontarget_name).remain_trial_nontarget;
end
%% 2.特征候选集汇总
Featute_select_candidate_target_data = [Festure_candidate_target_time Festure_candidate_target_freq Festure_candidate_target_time_freq Festure_candidate_target_space];
Featute_select_candidate_nontarget_data = [Festure_candidate_nontarget_time Festure_candidate_nontarget_freq Festure_candidate_nontarget_time_freq Festure_candidate_nontarget_space];
Featute_select_candidate_content = [Featute_content_time Featute_content_freq Featute_content_time_freq Featute_content_space];
Featute_select_candidate_target_num = [Festure_candidate_num_target_time Festure_candidate_num_target_freq Festure_candidate_num_target_time_freq Festure_candidate_num_target_space];
Featute_select_candidate_nontarget_num = [Festure_candidate_num_nontarget_time Festure_candidate_num_nontarget_freq Festure_candidate_num_nontarget_time_freq Festure_candidate_num_nontarget_space];
Featute_select_candidate_target_remain_trial = mean([remain_trial_target_time;remain_trial_target_freq;remain_trial_target_time_freq;remain_trial_target_space]);
Featute_select_candidate_nontarget_remain_trial = mean([remain_trial_nontarget_time;remain_trial_nontarget_freq;remain_trial_nontarget_time_freq;remain_trial_nontarget_space]);
end
3.3 特征选择算法
3.3.1 标准差法
待完善成标准接口函数
主要调用函数:std_score = std([target_festure ; nontarget_festure]),量化特征波动、离散程度
主要调用函数:sort(std_score,' descend'),对标准差法的量化特征的得分排序,以降序顺序,选取波动大(STD高)的前XX个特征
3.3.2 显著性检测法
待完善成标准接口函数
主要调用函数:[~,p_score,~]=ttest2(target_festure,nontarget_festure);,对目标\非目标的某个特征进行显著性检测
主要调用函数:sort(p_score),对P值检测法的量化特征的得分排序,以降序顺序,选最显著的(显著值低)前XX个特征
3.3.3 瑞利熵法
待完善成标准接口函数
function [RQ_list,RQ_score,RQ_result] = RQ_choice_zrk(class_num,sample_num,fest_num,zongshuju)
%% 参数介绍
% RQ_list为 最后的特征号排序(降序)
% RQ_score为 最终特征降序对应额瑞利熵值
% RQ_result特征顺序的瑞利熵值
% class_num 分类的类别数
% sample_sum 类别的样本数
% fest_num 每类的特征数量
% zongshuju行数为一类的一个样本的全部特征
%% impport data
RQ_data = zongshuju;
data_t = RQ_data';
nor_data = zeros(fest_num,class_num*sample_num);
%% normalization(0-1)
for nor_num = 1:class_num
nor_data(:,sample_num*(nor_num-1)+1:sample_num*(nor_num)) = mapminmax(data_t(:,sample_num*(nor_num-1)+1:sample_num*(nor_num)), 0, 1);
end
%% var&mean
% var_data_nor = nor_data';
% mean_data_nor = nor_data';
var_data_nor = zongshuju;
mean_data_nor = zongshuju;
std_data = zeros(class_num,fest_num);
mean_data = zeros(class_num,fest_num);
for var_mean_num = 1:class_num
std_data(var_mean_num,:) = std(var_data_nor(sample_num*(var_mean_num-1)+1:sample_num*var_mean_num,:));
mean_data(var_mean_num,:) = mean(mean_data_nor(sample_num*(var_mean_num-1)+1:sample_num*var_mean_num,:));
end
sum_std_data = sum(std_data);
sum_mean_data = zeros(1,fest_num);
for mean_i = 1:fest_num
for mean_j = 1:class_num
for mean_k = 1:class_num
sum_mean_data(1,mean_i) = sum_mean_data(1,mean_i) + (mean_data(mean_j,mean_i)-mean_data(mean_k,mean_i))^2;
end
end
end
RQ_result = sum_mean_data./sum_std_data;
[RQ_list,RQ_score]=sort(RQ_result,2,'descend');
% figure();
% plot(RQ_result);
% title('特征号与RQ值');
% xlabel('N号特征');
% ylabel('RQ');
end
3.3.4 消融特征正确率法
待完善成标准接口函数
主要调用函数,遍历所有特征,每次放入一个特征进行分类:
knn_class = ClassificationKNN.fit([train_target_festure ; train_nontarget_festure],label_train,'NumNeighbors',3);
[predict_label_knn,Scores_knn] = predict(knn_class, [test_target_festure ; test_nontarget_festure]);
accuracy_knn = length(find(predict_label_knn == test_label))/length(test_label)*100;
主要调用函数:sort(accuracy_knn,' descend'),对 消融特征正确率法的量化特征的得分排序,以降序顺序,选取单个正确率(ACC值高)前XX个特征
总结
对于脑电这类实验科学,面对陌生且新颖的试验任务数据,
最快最有效的方法就是:广撒网,多敛鱼,择优而从之,
把特征候选集搞得多多的,特征选择优中选优,
这种唯结果论的方法粗暴,但大多情况下有效。
特征工程中有句名言:
特征决定上限,而分类器只是逼近这个上限,
非要从一堆噪声特征中分出个你我他,实在是强人所难了。
如果分类性能不佳,与其修仙调参,不如从特征上下功夫,
特征分析永远是数据处理中最耗时、最折磨、最需要创新、最有收益的步骤。
囿于能力,挂一漏万,如有笔误请大家指正~
感谢您耐心的观看,本系列更新了约30000字,约3000行开源代码,体量相当于一篇硕士工作。
往期内容放在了文章开头,麻烦帮忙点点赞,分享给有需要的朋友~
坚定初心,本博客永远:
免费拿走,全部开源,全部无偿分享~
To:新想法、鬼点子的道友:
自己:脑机接口+人工智领域,主攻大脑模式解码、身份认证、仿脑模型…
在读博士第3年,在最后1年,希望将代码、文档、经验、掉坑的经历分享给大家~
做的不好请大佬们多批评、多指导~ 虚心向大伙请教!
想一起做些事情 or 奇奇怪怪点子 or 单纯批评我的,请至[email protected]
