Python入门到实战(十一)无监督学习、KMeans、KNN、实现图像分割、监督学习VS无监督学习
Python入门到实战(十一)无监督学习、KMeans、KNN、实现图像分割、监督学习VS无监督学习
- 无监督学习unsupervised learning
-
- 特点:
- 应用:
- K均值聚类
-
- 核心流程:
- 核心公式:
- KMeans VS KNN
- 实战:
-
- KMeans实现数据聚类
- KNN实现数据聚类
- 通过KMeans模型实现图像分割
- 监督学习VS无监督学习
无监督学习unsupervised learning
特点:
数据不需要标签->数据采集难度下降,极大扩充样本量
算法不受监督信息(偏见)约束->可能发现新的数据规律以及被忽略的重要信息
应用:
1.聚类分析
按照一定方法划分数据为不同的组别,使得在同一个组别中的对象有相似的一些属性
2.关联规则、3.维度缩减
K均值聚类
在样本数据控件中选K个点作为中心,计算各样本到各中心的距离,根据距离确定数据类别,是聚类算法中最基础也是最重要的算法。
同时,中心点也会根据类别内样本数据分布进行更新、
核心流程:
a.基于要求,确定聚类的个数k
b.确定k个中心
c.计算样本到各个中心点的距离
d.根据距离确定各个样本点的所属类别
e.计算同类别样本的中心点,并将其设定为新的中心
f.重复步骤c-e直到收敛(中心点不再变化)
核心公式:
KMeans VS KNN
Kmeans:
无监督学习、聚类算法、计算数据与中心点距离
监督学习、分类算法、计算数据与其他数据的距离
实战:
KMeans实现数据聚类
import pandas as pd
import numpy as np
data=pd.read_csv('kMeans_task1_data1.csv')
data_res=pd.read_csv('kMeans_task1_data2.csv')
data.head()
训练集
x1 x2 y
0 82.5302 67.9939 0.0
1 14.3821 54.6641 NaN
2 88.9239 14.9664 NaN
3 78.0811 26.0769 NaN
4 78.1597 58.6068 NaN
结果集
x1 x2 y
0 82.5302 67.9939 0
1 14.3821 54.6641 1
2 88.9239 14.9664 0
3 78.0811 26.0769 0
4 78.1597 58.6068 0
y=data_res.loc[:,'y']#取y值
x_labeled=data.iloc[0,:]#标签过的
#可视化结果
from matplotlib import pyplot as plt
fig1=plt.figure()
plt.scatter(x.loc[:,'x1'],x.loc[:,'x2'],label='unlabeled')
plt.scatter(x_labeled['x1'],x_labeled['x2'],label='labeled')
plt.title('unlabeled data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend(loc='upper left')
plt.show()
对于训练样本展示
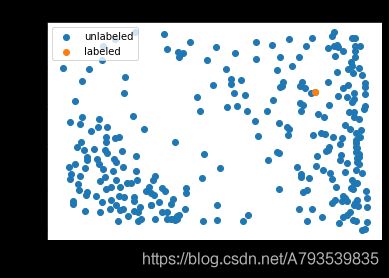
对于结果集合展示、
fig2=plt.figure()
plt.scatter(x.loc[:,'x1'][y==0],x.loc[:,'x2'][y==0],label='label0')
plt.scatter(x.loc[:,'x1'][y==1],x.loc[:,'x2'][y==1],label='label1')
plt.scatter(x_labeled['x1'],x_labeled['x2'],label='labeled')
plt.title('labeled data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend(loc='upper left')
plt.show()
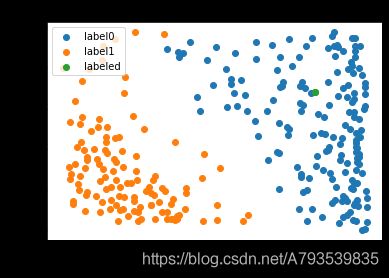
#建立模型并训练
from sklearn.cluster import KMeans
KM=KMeans(n_clusters=2,init='random',random_state=0)
#训练
KM.fit(x)
#查看聚类中心
centers=KM.cluster_centers_
fig3=plt.figure()
plt.scatter(x.loc[:,'x1'],x.loc[:,'x2'],label='unlabeled')
plt.scatter(x_labeled['x1'],x_labeled['x2'],label='labeled')
plt.scatter(centers[:,0],centers[:,1],100,marker='x',label='centers')
plt.title('unlabeled data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend(loc='upper left')
plt.show()
绿色叉叉箭头为样本中心
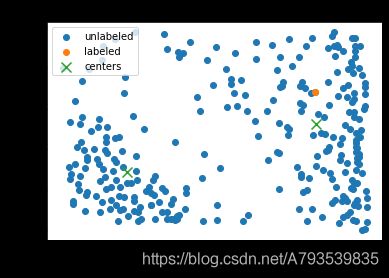
#无监督聚类结果预测
y_predict=KM.predict(x)
from sklearn.metrics import accuracy_score
accuracy=accuracy_score(y,y_predict)
print(accuracy)
0.9964912280701754
准确率达到百分之99.6以上
若是准确率十分的底,则把结果分类反转即可。无监督学习对于分类结果标签可能会有出入
预测结果可视化:
fig4=plt.figure()
plt.scatter(x.loc[:,'x1'][y_predict==0],x.loc[:,'x2'][y_predict==0],label='label0')
plt.scatter(x.loc[:,'x1'][y_predict==1],x.loc[:,'x2'][y_predict==1],label='label1')
plt.scatter(x_labeled['x1'],x_labeled['x2'],label='labeled')
plt.title('predict labeled data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend(loc='upper left')
plt.show()
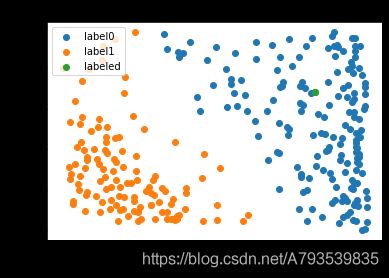
KNN实现数据聚类
from sklearn.neighbors import KNeighborsClassifier
KNN=KNeighborsClassifier(n_neighbors=3)
KNN.fit(x,y)
#knn预测
y_predict_knn=KNN.predict(x)
accuracy_knn=accuracy_score(y,y_predict_knn)
fig5=plt.figure(figsize=(8,8))
plt.scatter(x.loc[:,'x1'][y_predict_knn==0],x.loc[:,'x2'][y_predict_knn==0],label='label0')
plt.scatter(x.loc[:,'x1'][y_predict_knn==1],x.loc[:,'x2'][y_predict_knn==1],label='label1')
plt.scatter(x_labeled['x1'],x_labeled['x2'],label='labeled')
plt.title('knn predict labeled data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend(loc='upper left')
plt.show()
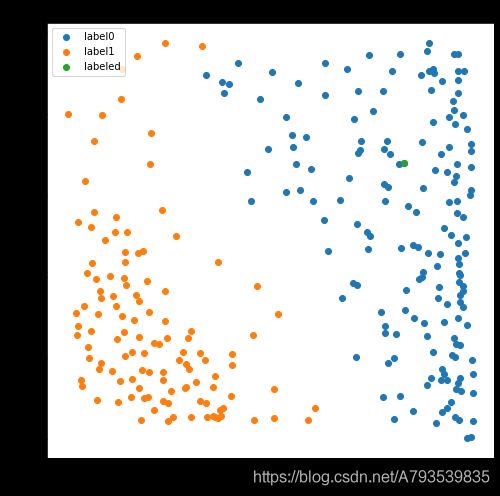
KNN 训练出来的结果与原数据百分百拟合
通过KMeans模型实现图像分割
pip install scikit-image
速度慢可参考之前的文章 在后头加上-i和国内镜像地址
import numpy as np
import matplotlib.pyplot as plt
from skimage import io as io
img=io.imread('xlz.jpg')
plt.imshow(img)

先观察清楚格式和结构
print(type(img))
print(img.shape)
(700, 700, 3)
[[[ 35 31 30]
[ 42 36 36]
[ 49 43 43]
...
print(img.shape[1],img.shape[0])
700 700
格式转换:
#format
img_data=img.reshape(-1,3)
print(img_data.shape)
(490000, 3)
相当于把数据展开,可以开始赋值训练模型了
x=img_data
#模型建立与训练
from sklearn.cluster import KMeans
model=KMeans(n_clusters=3,random_state=0)
model.fit(x)
#predict
label=model.predict(x)
print(label)
import pandas as pd
print(pd.value_counts(label))
[2 2 2 … 2 2 2]
1 235005
0 165581
2 89414
dtype: int64
#维度转化
label=label.reshape([img.shape[1],img.shape[0]])
print(label)
print(label.shape)
[[2 2 2 … 2 2 2]
[2 2 2 … 2 2 2]
[2 2 2 … 2 2 2]
…
[2 0 0 … 2 2 2]
[2 0 0 … 2 2 2]
[2 0 0 … 2 2 2]]
(700, 700)
转为了原来的格式
label=1/(label+1)#取倒数
#图像存储
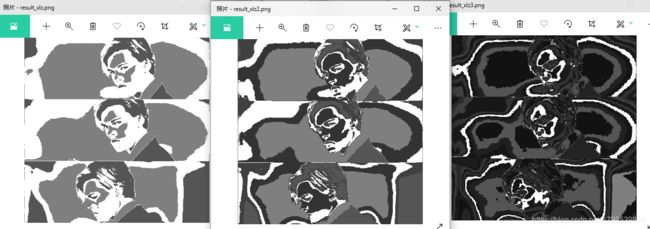
io.imsave('result_xlz.png',label)
最终结果:

model=KMeans(n_clusters=15,random_state=0)
model.fit(x)
label=model.predict(x)
#维度转化
label=label.reshape([img.shape[1],img.shape[0]])
label=1/(label+1)#取倒数/灰度处理
#图像存储
io.imsave('result_xlz3.png',label)
修改clusters的值做类别为5,15后分类后得出的结果为
监督学习VS无监督学习
监督学习其实就是有正确标签,结果作为引导、从而效率方面,拟合度都是很高的。
例如上课学习知识点,在学校的话做题目是为了考试,在工作岗位上学习是为了应用实际。
甚至老师上课将知识点内容大多时候都是给我们归纳,总结,授予。
而自己去探索,发现,总结无疑就是符合无监督学习。在这个过程中,可能会收获意想不到的,平时被忽略的地方。
随着业务复杂度上升,模型可能会比较复杂,无监督学习不一定能够有效准确的做出判断。
监督学习则需要大量,准确的数据。获取难度也是一个问题。
现实中考虑到有部分带标签数据的情况会比较多,故有如下考虑:
1.在能有充分数据时,应当优先选择监督学习
2.条件允许的情况下尽可能多收集有效数据
3.无法收集足够完整样本时,可以考虑半监督学习+监督学习
应用场景中一定无所谓对错,各有利弊,符合需求,多分析找出原因才是根本。