User Controllable LT 水记(用三维光流自由地编辑GAN,平移缩放偏转的一致性都很强)
User Controllable LT 水记(用三维光流自由地编辑GAN,平移缩放偏转的一致性都很强)
《User-Controllable Latent Transformer for StyleGAN Image Layout Editing》
主页:http://www.cgg.cs.tsukuba.ac.jp/~endo/projects/UserControllableLT/
论文:https://arxiv.org/abs/2208.12408
项目:https://github.com/endo-yuki-t/UserControllableLT
高度可控的、解耦的、隐编码操作
我认为这篇最大的突破是整合了 warp 和 inpainting,提出了一种更细腻并且具有先验知识的warp方法。
这种思路非常重要,因为好多方法都用了 grid_sample 做 warp ,我认为这种简陋的warp方法是有很大局限性的,最终整个模型的表现都可能受限于这一个关口(比如FOMM花里胡哨做了一堆前期工作产生好光流,结果还是要靠warp特征图),很多用了 grid_sample 做 warp 的模型都会呈现出相似的模糊感,我认为这就是由于 warp 方法不够好导致的。
先看效果展示:
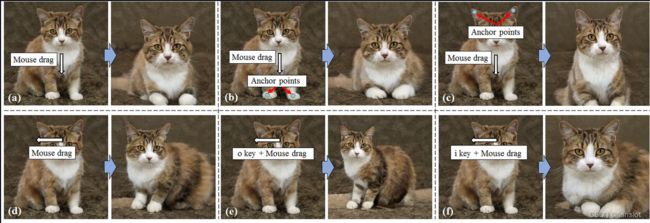 可以用鼠标操作,输入3D光流
可以用鼠标操作,输入3D光流
可以打点,固定一部分不动,另一部分平移,另一部分不管
(a) 脸部移动有很好的平移不变性,不过其他部分也会变化
(b) 固定脚部不动,移动脸部
© 固定耳朵尖不动,移动脸部(耳朵被拉长了)
(d) 可以改变脸部朝向
(e)(f) 脸部可以缩放,缩放时也有不变性
实际上还是latent的线性编辑,不过编辑方向是由一个 Transformer 预测的。
使用预训练的StyleGAN,并且不进行微调。
用预训练的GAN合成训练集,训练 Latent Transformer 。
Latent Transformer 输入 原隐编码 w before \mathbf{w}_{\text {before}} wbefore 和 3D 光流(用户输入),输出 编辑后的隐编码 w ^ after \mathbf{\hat w}_{\text {after}} w^after 。
输入隐编码是一个定长序列( W + \mathcal{W}+ W+空间),3D光流是一个不定长序列,用这两个序列做cross-attention,输出新的隐编码(定长序列, W + \mathcal{W}+ W+空间)
可惜,他用的是StyleGAN2,所以还是有纹理粘连问题。
不过令我很惊讶的是,它可以轻松生成身体结构正确的猫,我一直以为这种非对齐的数据集是很难用GAN产生合理的结构的,一般都是好多腿好多尾巴啥的。
不知道这个效果是经过了cherry pick,还是说这个预训练的StyleGAN2真的做到了能随便就产生可信的身体结构,而且还是在未对齐图像上训练的,而且能有如此之好的编辑效果。
记得去看看这个预训练模型用了什么技术实现这一点,我猜可能是用了自蒸馏的 W \mathcal{W} W 空间截断。
方法
本研究的目的是,靠 用户直接在图片上给出的 运动向量 来 编辑StyleGAN图片。
公式化表述如下:
T ( w before , U , α ) = w before + α ⋅ f ( w before , U ) \mathbf{T}\left(\mathbf{w}_{\text {before}}, \mathcal{U}, \boldsymbol{\alpha}\right)=\mathbf{w}_{\text {before}}+\boldsymbol{\alpha} \cdot f\left(\mathbf{w}_{\text {before}}, \mathcal{U}\right) T(wbefore,U,α)=wbefore+α⋅f(wbefore,U)
其中 w before \mathbf{w}_{\text {before}} wbefore 为初始的隐编码, U \mathcal{U} U 为用户输入, α \boldsymbol{\alpha} α 是一个控制编辑强度的系数, f f f 是一个任意的神经网络。
定义用户输入 U = { v i , p i } i = 1 K \mathcal{U}=\{\mathbf{v}_i,\mathbf{p}_i\}_{i=1}^K U={vi,pi}i=1K ,包含 K K K 个 运动向量 v i ∈ R 3 \mathbf{v}_{i} \in \mathbb{R}^{3} vi∈R3 (表示xyz方向)和 像素坐标 p i ∈ Z 2 \mathbf{p}_{i} \in \mathbb{Z}^{2} pi∈Z2 (表示 v i \mathbf{v}_i vi 的起点)。
我们在 W + \mathcal{W}^+ W+ 空间中编辑隐编码。
总体流程如下:
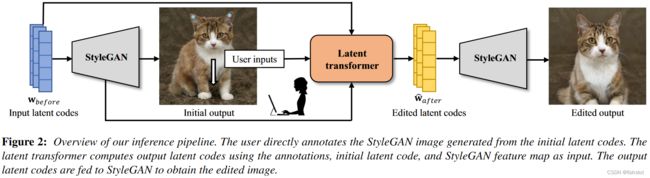
我们将用户输入 U \mathcal{U} U 、初始隐编码 w before \mathbf{w}_{\text {before}} wbefore 、StyleGAN特征图 输入 latent transformer,得到编辑后的隐编码 w ^ after \mathbf{\hat w}_{\text {after}} w^after 。最后,我们将 w ^ after \mathbf{\hat w}_{\text {after}} w^after 输入StyleGAN得到最终的图片。
训练 latent transformer 使用的是合成的数据集,我们使用 由 预训练的StyleGAN 和 光流网络 生成的 合成图像 和 伪用户输入 。
网络结构

latent tranformer 的结构
左边是 latent transformer 的整体结构
右边是 latent transformer 的 编-解码器部分 的具体结构
为了能处理数量可变的用户输入,在 latent transformer 中使用了 Transformer 编-解码 结构。
由于像素坐标 p i \mathbf{p}_{i} pi 中 不含语义信息,我们根据 像素坐标 从 StyleGAN 的特征图 中抽取特征向量。这个点子来自于最近用 StyleGAN特征图 做 语义分割 的研究 [Col20*;* ZLG21; TRS21] 。
更具体地说,我们用 w before \mathbf{w}_{\text {before}} wbefore 从 StyleGAN 中计算一个 64x64 的中间特征图,然后根据 p i \mathbf{p}_{i} pi 从特征图中提取一系列的特征向量。
我们将 特征向量 与 运动向量 v i \mathbf{v}_{i} vi 融合在一起,送入 transformer 编码器。更具体地说,我们将 特征向量 与 运动向量 v i \mathbf{v}_{i} vi 分别送入两个个线性层转为256通道,然后拼接得到一个512通道的向量,然后再过一个线性层(保持512通道),最后送入 transformer 编码器中。
在解码器这边,目标是将 w before \mathbf{w}_{\text {before}} wbefore 转换为 w ^ after \mathbf{\hat w}_{\text {after}} w^after 。
我们将 w before \mathbf{w}_{\text {before}} wbefore 过一个线性层,然后与一个可学习的位置编码相加,作为。注意 w before \mathbf{w}_{\text {before}} wbefore 处于 W + \mathcal{W}^+ W+ 空间中,位置编码的作用是帮助区分不同层的 w \mathbf{w} w 。
解码器的 cross attention 层以编码器的输出作为 key 和 value, 以处理后的 w before \mathbf{w}_{\text {before}} wbefore 作为 query,输出编辑方向。把编辑方向用 α \boldsymbol{\alpha} α 加权后与 w before \mathbf{w}_{\text {before}} wbefore 相加,就得到 w ^ after \mathbf{\hat w}_{\text {after}} w^after 。
训练
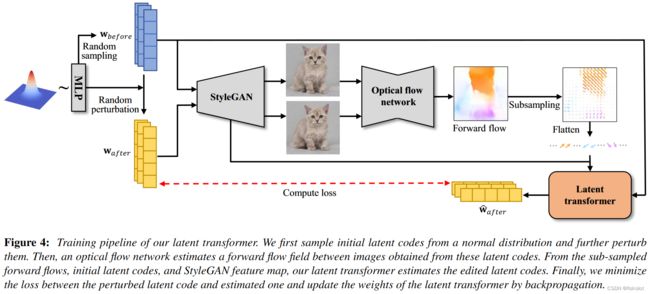
训练流程。其实光看图就差不多了。
先随机采样一个 w before \mathbf{w}_{\text {before}} wbefore ,
w before = w ‾ − ψ ( w rand − w ‾ ) \mathbf{w}_{\text {before }}=\overline{\mathbf{w}}-\psi\left(\mathbf{w}_{\text {rand }}-\overline{\mathbf{w}}\right) wbefore =w−ψ(wrand −w)
这里用了截断技巧,将随机采样的隐编码与平均隐编码之间做一个线性插值。
对 w before \mathbf{w}_{\text {before}} wbefore 做一个随机扰动 得到 w after \mathbf{w}_{\text {after}} wafter ,
w after = w before − ϕ ( w rand ′ − w before ) \mathbf{w}_{\text {after }}=\mathbf{w}_{\text {before }}-\phi\left(\mathbf{w}_{\text {rand }}^{\prime}-\mathbf{w}_{\text {before }}\right) wafter =wbefore −ϕ(wrand ′−wbefore )
就是随机采样一个新的隐编码 w rand ′ \mathbf{w}_{\text {rand}}^{\prime} wrand′ 然后与 w before \mathbf{w}_{\text {before}} wbefore 做线性插值。
由于StyleGAN的深层控制姿势和形状,浅层控制风格和颜色,所以我们只操作最深的6层的隐编码。
对于 w before \mathbf{w}_{\text {before}} wbefore 和 w after \mathbf{w}_{\text {after}} wafter 输出的图片,我们用一个预训练的 光流网络 计算 前向光流场。
为了能处理三维运动,我们使用 [YR20] ,这个方法能估计出提供 位置变化 的 光流 和 提供 比例变化 的 光膨胀。
于是我们对于每个 光流 ( x j , y j ) \left(x_{j}, y_{j}\right) (xj,yj) 和 光膨胀 z j z_{j} zj 计算出 三维运动向量 ( x j σ f , y j σ f , z j σ e ) T \left(\frac{x_{j}}{\sigma_{f}}, \frac{y{j}}{\sigma_{f}}, \frac{z_{j}}{\sigma_{e}}\right)^{T} (σfxj,σfyj,σezj)T ,其中 σ f \sigma_{f} σf 和 σ e \sigma_{e} σe 是分别是用于归一化光流和光膨胀的常数,因为这两者在范围上往往有很大的不同。为了计算这两个参数,我们随机采样几百对 w before \mathbf{w}_{\text {before}} wbefore 和 w after \mathbf{w}_{\text {after}} wafter ,对每一对都估计光流,我们定义 σ f \sigma_{f} σf 和 σ e \sigma_{e} σe 分别是光流和光膨胀的最大值的平均值。
然后我们下采样光流场,使用 16x16 的光流场作为 latent tranformer 的输入。
在训练过程中,始终保持 α \boldsymbol{\alpha} α 为 1 。
我们计算 w after \mathbf{w}_{\text {after}} wafter 和 w ^ after \mathbf{\hat w}_{\text {after}} w^after 之间的 L2 损失。
用户交互
额,这个就不用看了吧
实现细节
我们使用 RTX A4000 显卡(这里用了复数,可能不止一块)。
我们使用 预训练的 StyleGAN2 ,来自 https://github.com/justinpinkney/awesome-pretrained-stylegan2 。
对于 transformer 的编码器,我们使用了与 ViT 相同的架构。对于 transformer 的解码器,我们在 《Attention is all you need》 的原架构的基础上,采用了 PreNorm [WLX*19](在sublayers之前应用归一化),在前向层中将 ReLU 替换为 GeLU 。
对所有 transformer 的编码器和解码器,将多头注意力 从 8头 改成 6头。为了训练 latent transformer ,我们使用 Ranger 优化器,学习率为0.001。采样 w before \mathbf{w}_{\text {before}} wbefore 和 w after \mathbf{w}_{\text {after}} wafter 时, ψ = 0.3 \psi=0.3 ψ=0.3 , ϕ = 0.1 \phi=0.1 ϕ=0.1 。
latent transformer 训练了 6万次迭代,batch_size 为 1 。在 256x256 上需要4小时训练,推理时间为 0.02 秒。在 1024x1024 上需要 7小时训练,推理时间为 0.07 秒。