sklearn学习07——可视化
sklearn学习07——可视化
- 前言
- 一、一些常用数据集
-
- 1.1、手写数据集
- 1.2、肿瘤数据集
- 1.3、波斯顿房价数据集
- 二、性能可视化
-
- 2.1、交叉验证绘制
- 2.2、重要性特征绘制
- 三、机器学习度量
-
- 3.1、混淆矩阵(Confusion Matrix)
- 3.2、ROC、AUC曲线
- 3.3、P-R曲线
- 3.4、轮廓分析
- 3.5、可靠性曲线(Calibration Curve , Reliability Curves)
- 3.6、KS检验
- 3.7、累计收益曲线
- 3.8、Lift曲线
- 四、聚类方法
-
- 4.1、手肘法(Elbow Method)
- 五、降维方法
-
- 5.1、PCA
- 5.2、2-D Projection
- 六、可视化决策树
-
- 6.1、文字形式表示
- 6.2、图片形式(plot_tree函数)
- 6.3、sns.heatmap可视化报告
- 总结
前言
本篇主要通过使用 Scikit-Plot 的模块来介绍机器学习的相关可视化,Scikit-Plot 主要包括以下几个部分:
- estimators:用于绘制各种算法
- metrics:用于绘制机器学习的onfusion matrix, ROC AUC curves, precision-recall curves等曲线
- cluster:主要用于绘制聚类
- decomposition:主要用于绘制PCA降维
一、一些常用数据集
1.1、手写数据集
代码如下:
digits = load_digits()
X_digits, Y_digits = digits.data, digits.target
print("Digits Dataset Size : ", X_digits.shape, Y_digits.shape)
X_digits_train, X_digits_test, Y_digits_train, Y_digits_test = train_test_split(X_digits, Y_digits,
train_size=0.8,
stratify=Y_digits,
random_state=1)
print("Digits Train/Test Sizes : ",X_digits_train.shape, X_digits_test.shape, Y_digits_train.shape, Y_digits_test.shape)
1.2、肿瘤数据集
代码如下:
cancer = load_breast_cancer()
X_cancer, Y_cancer = cancer.data, cancer.target
print("Feautre Names : ", cancer.feature_names)
print("Cancer Dataset Size : ", X_cancer.shape, Y_cancer.shape)
X_cancer_train, X_cancer_test, Y_cancer_train, Y_cancer_test = train_test_split(X_cancer, Y_cancer,
train_size=0.8,
stratify=Y_cancer,
random_state=1)
print("Cancer Train/Test Sizes : ",X_cancer_train.shape, X_cancer_test.shape, Y_cancer_train.shape, Y_cancer_test.shape)
1.3、波斯顿房价数据集
代码如下:
boston = load_boston()
X_boston, Y_boston = boston.data, boston.target
print("Boston Dataset Size : ", X_boston.shape, Y_boston.shape)
print("Boston Dataset Features : ", boston.feature_names)
X_boston_train, X_boston_test, Y_boston_train, Y_boston_test = train_test_split(X_boston, Y_boston,
train_size=0.8,
random_state=1)
print("Boston Train/Test Sizes : ",X_boston_train.shape, X_boston_test.shape, Y_boston_train.shape, Y_boston_test.shape)
二、性能可视化
2.1、交叉验证绘制
代码如下:
skplt.estimators.plot_learning_curve(LogisticRegression(), X_digits, Y_digits,
cv=7, shuffle=True, scoring="accuracy",
n_jobs=-1, figsize=(6,4), title_fontsize="large", text_fontsize="large",
title="Digits Classification Learning Curve")
plt.show()
skplt.estimators.plot_learning_curve(LinearRegression(), X_boston, Y_boston,
cv=7, shuffle=True, scoring="r2", n_jobs=-1,
figsize=(6,4), title_fontsize="large", text_fontsize="large",
title="Boston Regression Learning Curve ");
plt.show()

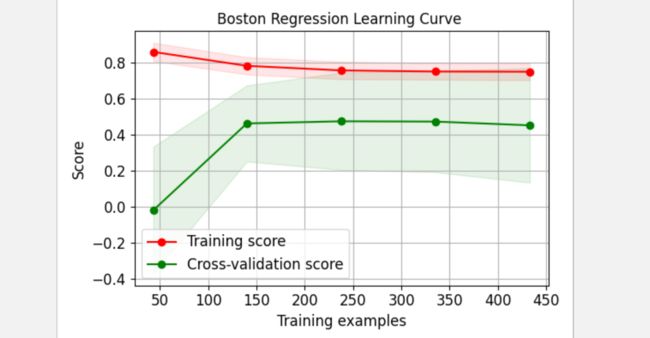
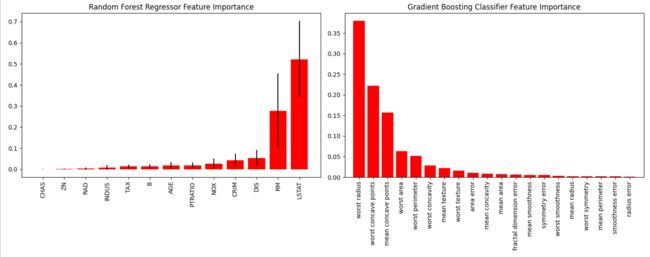
2.2、重要性特征绘制
代码如下:
rf_reg = RandomForestRegressor()
rf_reg.fit(X_boston_train, Y_boston_train)
print(rf_reg.score(X_boston_test, Y_boston_test))
gb_classif = GradientBoostingClassifier()
gb_classif.fit(X_cancer_train, Y_cancer_train)
print(gb_classif.score(X_cancer_test, Y_cancer_test))
fig = plt.figure(figsize=(15,6))
ax1 = fig.add_subplot(121)
skplt.estimators.plot_feature_importances(rf_reg, feature_names=boston.feature_names,
title="Random Forest Regressor Feature Importance",
x_tick_rotation=90, order="ascending",
ax=ax1);
ax2 = fig.add_subplot(122)
skplt.estimators.plot_feature_importances(gb_classif, feature_names=cancer.feature_names,
title="Gradient Boosting Classifier Feature Importance",
x_tick_rotation=90,
ax=ax2);
plt.tight_layout()
plt.show()
三、机器学习度量
3.1、混淆矩阵(Confusion Matrix)
代码如下:
log_reg = LogisticRegression()
log_reg.fit(X_digits_train, Y_digits_train)
log_reg.score(X_digits_test, Y_digits_test)
Y_test_pred = log_reg.predict(X_digits_test)
fig = plt.figure(figsize=(15,6))
ax1 = fig.add_subplot(121)
skplt.metrics.plot_confusion_matrix(Y_digits_test, Y_test_pred,
title="Confusion Matrix",
cmap="Oranges",
ax=ax1)
ax2 = fig.add_subplot(122)
skplt.metrics.plot_confusion_matrix(Y_digits_test, Y_test_pred,
normalize=True,
title="Confusion Matrix",
cmap="Purples",
ax=ax2);
plt.show()

3.2、ROC、AUC曲线
代码如下:
Y_test_probs = log_reg.predict_proba(X_digits_test)
skplt.metrics.plot_roc_curve(Y_digits_test, Y_test_probs,
title="Digits ROC Curve", figsize=(12,6))
plt.show()

3.3、P-R曲线
代码如下:
skplt.metrics.plot_precision_recall_curve(Y_digits_test, Y_test_probs,
title="Digits Precision-Recall Curve", figsize=(12,6))
plt.show()


3.4、轮廓分析
代码如下:
kmeans = KMeans(n_clusters=10, random_state=1)
kmeans.fit(X_digits_train, Y_digits_train)
cluster_labels = kmeans.predict(X_digits_test)
skplt.metrics.plot_silhouette(X_digits_test, cluster_labels,
figsize=(8,6))
plt.show()

3.5、可靠性曲线(Calibration Curve , Reliability Curves)
代码如下:
lr_probas = LogisticRegression().fit(X_cancer_train, Y_cancer_train).predict_proba(X_cancer_test)
rf_probas = RandomForestClassifier().fit(X_cancer_train, Y_cancer_train).predict_proba(X_cancer_test)
gb_probas = GradientBoostingClassifier().fit(X_cancer_train, Y_cancer_train).predict_proba(X_cancer_test)
et_scores = ExtraTreesClassifier().fit(X_cancer_train, Y_cancer_train).predict_proba(X_cancer_test)
probas_list = [lr_probas, rf_probas, gb_probas, et_scores]
clf_names = ['Logistic Regression', 'Random Forest', 'Gradient Boosting', 'Extra Trees Classifier']
skplt.metrics.plot_calibration_curve(Y_cancer_test,
probas_list,
clf_names, n_bins=15,
figsize=(12,6)
)
plt.show()
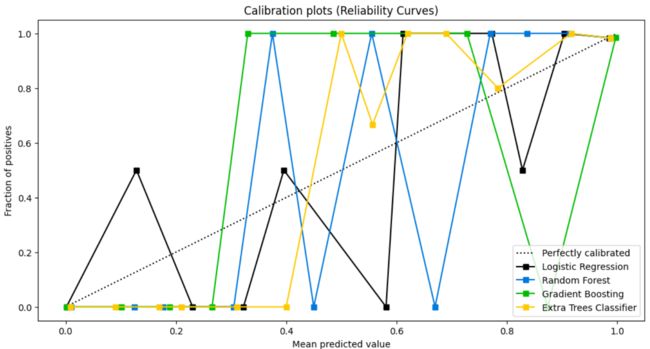
3.6、KS检验
代码如下:
rf = RandomForestClassifier()
rf.fit(X_cancer_train, Y_cancer_train)
Y_cancer_probas = rf.predict_proba(X_cancer_test)
skplt.metrics.plot_ks_statistic(Y_cancer_test, Y_cancer_probas, figsize=(10,6))
plt.show()
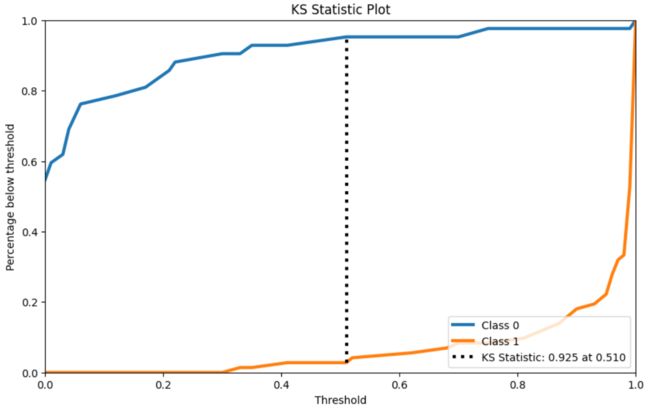
3.7、累计收益曲线
代码如下:
skplt.metrics.plot_cumulative_gain(Y_cancer_test, Y_cancer_probas, figsize=(10,6))
plt.show()

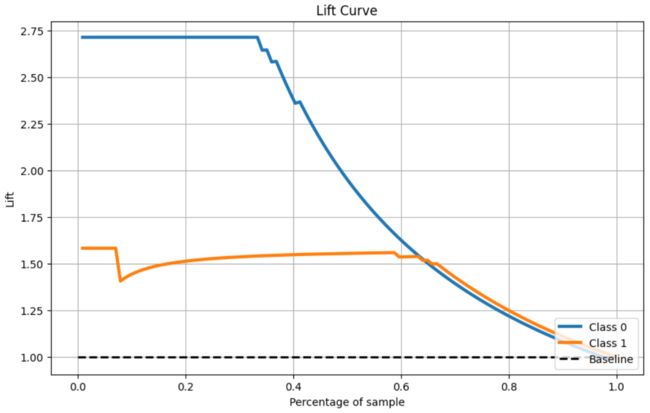
3.8、Lift曲线
代码如下:
skplt.metrics.plot_lift_curve(Y_cancer_test, Y_cancer_probas, figsize=(10,6))
plt.show()
四、聚类方法
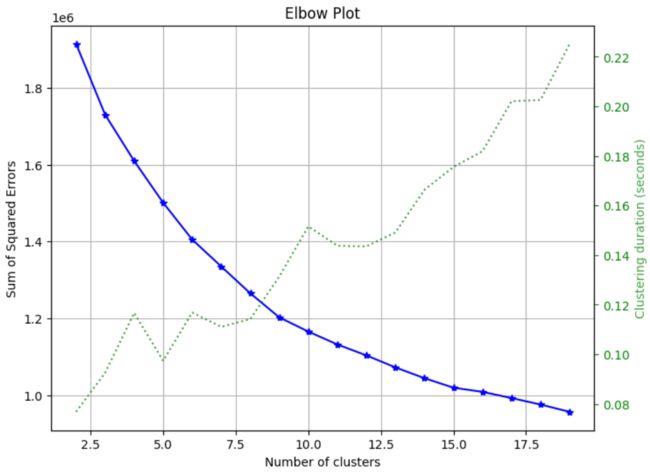
4.1、手肘法(Elbow Method)
代码如下:
skplt.cluster.plot_elbow_curve(KMeans(random_state=1),
X_digits,
cluster_ranges=range(2, 20),
figsize=(8,6))
plt.show()
五、降维方法
5.1、PCA
代码如下:
pca = PCA(random_state=1)
pca.fit(X_digits)
skplt.decomposition.plot_pca_component_variance(pca, figsize=(8,6))
plt.show()

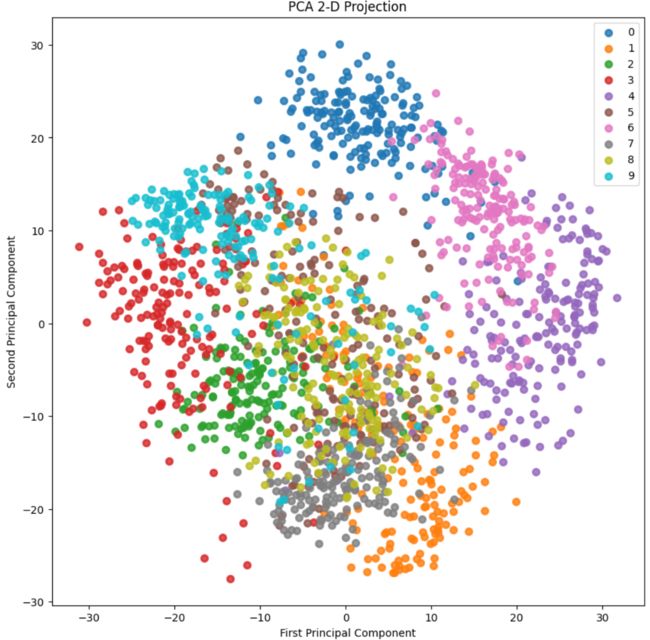
5.2、2-D Projection
代码如下:
skplt.decomposition.plot_pca_2d_projection(pca, X_digits, Y_digits,
figsize=(10,10),
cmap="tab10")
plt.show()
六、可视化决策树
代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import tree
import graphviz
# 加载数据集
dataset = load_iris()
# 转换成.DataFrame形式
df = pd.DataFrame(dataset.data, columns = dataset.feature_names)
# 添加品种列
df['Species'] = dataset.target
# 用数值替代品种名作为标签
target = np.unique(dataset.target)
target_names = np.unique(dataset.target_names)
targets = dict(zip(target, target_names))
df['Species'] = df['Species'].replace(targets)
# 提取数据和标签
X = df.drop(columns="Species")
y = df["Species"]
feature_names = X.columns
labels = y.unique()
X_train, X_test, y_train, y_test = train_test_split(X,y,
test_size = 0.4,
random_state = 42)
model = DecisionTreeClassifier(max_depth =3, random_state = 42)
model.fit(X_train, y_train)
6.1、文字形式表示
代码如下:
# 以文字形式输出树
text_representation = tree.export_text(model)
print(text_representation)
|— feature_2 <= 2.45
| |— class: setosa
|— feature_2 > 2.45
| |— feature_3 <= 1.75
| | |— feature_2 <= 5.35
| | | |— class: versicolor
| | |— feature_2 > 5.35
| | | |— class: virginica
| |— feature_3 > 1.75
| | |— feature_2 <= 4.85
| | | |— class: virginica
| | |— feature_2 > 4.85
| | | |— class: virginica
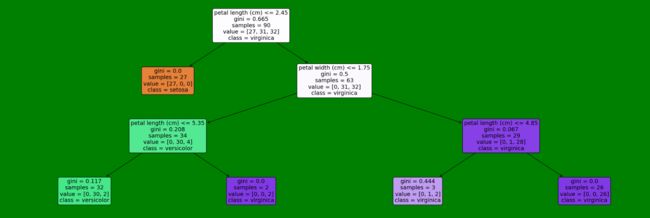
6.2、图片形式(plot_tree函数)
代码如下:
# 用图片画出
plt.figure(figsize=(30,10), facecolor ='g') #
a = tree.plot_tree(model,
feature_names = feature_names,
class_names = labels,
rounded = True,
filled = True,
fontsize=14)
plt.show()
6.3、sns.heatmap可视化报告
代码如下:
from sklearn.metrics import classification_report
import numpy as np
import seaborn as sns
import pandas as pd
y_pred = model.predict(X_test)
target_names = np.unique(dataset.target_names)
clf_report = classification_report(y_test,
y_pred,
labels=labels,
target_names=target_names,
output_dict=True)
plt.figure(figsize=(8,6))
sns.heatmap(pd.DataFrame(clf_report).iloc[:-1, :].T, annot=True)
plt.show()

总结
本篇文章主要对机器学习多个方面进行可视化操作的教学,主要包括以下几个方面:模型特征重要性可视化、不同模型性能度量方式的可视化、一些算法的效果随参数变化的曲线等,最后对决策树模型以两种方式(文字形式、图片形式)展示出来,能够直观看出决策树的每条分支的最优划分属性、基尼指数(基尼值)等信息。这些可视化操作很方便的帮助我们找到自己训练出的模型的缺点。