Sklearn学习
目录
数据的预处理
缺失值计算
独热编码
标准化处理
多项式转换
模型选择
模型评估与选择
机器学习主要分为三个大部分:
1.数据预处理
2.训练模型
3.对模型的评估
这三个部分都可以使用sklearn包来实现,在使用sklearn包是需要导入很多种模块,对于不是很熟悉sklearn包的人产生很大困扰,所以这篇文章将简单总结一下sklearn包的使用方法。
数据的预处理
| 缺失值计算 | 对缺失值进行填充 | from sklearn.impute import SimpleImputer |
| 标准化处理 | 对数据进行标准化处理 | from sklearn.preprocessing import StandardScaler |
| 独热编码 | 对类别进行数字编码 | from sklearn.preprocessing import OneHotEncoder |
| 多项式转换 | 对数据增加新的特征提高拟合度 | from sklearn.preprocessing import PolynomialFeatures |
缺失值计算
大部分的机器学习算法无法在缺失的特征上工作,所以我们需要对缺失的特征进行处理。对缺失值进行处理有以下三种选择
1.舍弃这些缺失值
2.放弃整个属性
3.将缺失值设置为某个值(均值,众数,中位数等)
这里主要讲解一下缺失值填充。
import numpy as np
import pandas as pd
data = {
'size': ['XL','L','M', np.nan ,'M','M'],
'color': ['red','green','blue','green','red','green'],
'gender': ['female','male', np.nan,'female','female','male'],'price': [ 199.0 , 89.0, np.nan,129.0, 79.0, 89.0],
'weight': [ 500,450,300, np.nan, 410,np.nan ],'bought': ['yes','no','yes','no','yes','no']
}
df = pd.DataFrame(data)
print("缺失值个数:",df.isnull().sum())
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan,strategy="mean")//采用平均值对空值进行填充
df[['weight']] = imputer.fit_transform(df[["weight"]])
print("填充缺失值为:",imputer.statistics_[0])这样我们最终就将weight列中的缺失值进行了填充,得到如下结果:

填充策略说明:

独热编码
大多数机器学习算法更喜欢使用数字,因此我们需要将文本转换为数字。
data = {
'size': ['XL','L','M', 'L','M'],
'color': ['red','green','blue','green','red'],
'gender': ['female','male', 'male','female','female'],
'price': [ 199.0 , 89.0,99,129.0, 79.0],
'weight': [ 500,450,300, 380, 410 ],
'bought': ['yes','no','yes','no','yes']
}
df=pd.DataFrame(data=data)
# from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
oneHotEncoder =OneHotEncoder(sparse=False)
# oneHotEncoder.fit(df[["size"]])
# print(oneHotEncoder.transform(df[["size"]]))
print(oneHotEncoder.fit_transform(df[["size"]]))
print(oneHotEncoder.categories_)这样我们就可以将size属性转换为独热编码的形式,并查看不同位置的1对应的原属性是什么。
输出结果为:

标准化处理
标准化通过计算训练集中样本的相关统计量(均值和单位方差),存储均值和标准差,对每个特征单独进行中心化和缩放。数据集的标准化是许多机器学习估计器的一个常见要求。
标准化计算公式为:
from sklearn.preprocessing import StandardScaler
a=StandardScaler()
//**为所需要标准化处理的数据
b=a.fit_transform(**)多项式转换
对于稍复杂的数据来说肯定是比一条直线要复杂的,但是在使用时仍然可以用线性模型来拟合非线性数据。一个简单的方法就是将添加每个特征的幂次方作为一个新的特征,然后在此扩征特征集上训练一个线性模型。
观察这个散点图,肯定是线性模型无法拟合的,或者说线性模型拟合的不好,但是通过多项式转换,将原始数据特征的幂次方作为新特征,就可以用线性模型很好的拟合。
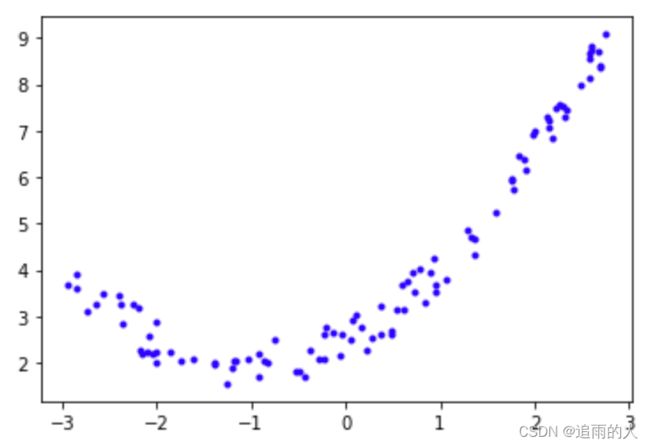
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
%matplotlib inline
m=100
x=6*np.random.rand(m,1)-3
y=0.5*x**2+x+2+np.random.rand(m,1)
plt.figure(1)
plt.plot(x,y,'.b')
poly_features = PolynomialFeatures(degree=2,include_bias=False)
x_poly=poly_features.fit_transform(x)
lin_reg=LinearRegression()
lin_reg.fit(x_poly,y)
lin_reg.intercept_,lin_reg.coef_ 最终输出结果为:![]()
意思就是
当存在多个特征时,多项式回归能够找到特征之间的关系(这是普通线性回归模型无法做到的)。PolynomialFeatures会将特征的所有组合添加到给定的多项式中。例如,如果有两个特征a和b,当degree=3的PolynomialFeatures不仅会添加特征还会添加组合
模型选择
| 模型 | 原理 | 引用 | 类别 | 说明 |
| 广义线性模型 | 基于最小二乘 | from sklearn.linear_model import LinearRegression | 回归 | |
| SGD(随机梯度下降) | from sklearn.linear_model import SGDRegressor | 分类/回归 | 大数据集 | |
| 贝叶斯回归 | from sklearn.linear_model import BayesianRidge | 回归 | ||
| Huber Regression | from sklearn.linear_model import HuberRegressor | 回归 | ||
| 正则化线性模型 | Ridge/岭回归 | from sklearn.linear_model import Ridge | 回归 | 在成本函数中加入正则化防止过拟合 |
| 正则化线性模型 | Lasso | from sklearn.linear_model import Lasso | 回归 | 在成本函数中加入正则化防止过拟合 |
| 正则化线性模型 | ElasticNet(弹性网络) | from sklearn.linear_model import ElasticNet | 回归 | 正则项是ridge和lasso的简单混合 |
| 支持向量机 | SVR,NuSVR,LinearSVR | from sklearn.svm import SVR,NuSVR,LinearSVR | 回归 | |
| SVC,NuSVC,LinearSVC | from sklearn.svm import SVC,NuSVC,LinearSVC | 分类 | ||
| OneClassSVM | from sklearn.svm import OneClassSVM | 异常检测 | ||
| 决策树 | Regression | from sklearn.tree import DecisionTreeRegressor | 回归 | |
| Classification | from sklearn.tree import DecisionTreeClassifier | 分类 | ||
| 集成学习 | Bagging | from sklearn.ensemble import BaggingClassifier/BaggingRegressor | 分类/回归 | |
| AdaBoost | from sklearn.ensemble import AdaBoostClassifier/AdaBoostRegressor | 分类/回归 | ||
| 降维 | 主成分分析 | from sklearn.decomposition import PCA | 降维 | |
| 增量PCA | from sklearn.decomposition import IncrementalPCA | 降维 | ||
| 内核PCA | from sklearn.decomposition import KernelPCA | 降维 | ||
| 奇异值分解 | from sklearn.decomposition import TruncatedSVD | 降维 | ||
| 聚类 | K-Means | from sklearn.cluster import KMeans | ||
| DBSCAN | from sklearn.cluster import DBSCAN |
模型评估与选择
| 交叉验证 | 划分数据集(训练集、测试集) | from sklearn.model_selection import train_test_split | ||
| 通过交叉验证评估score | from sklearn.model_selection import cross_val_score | |||
| 调参 | 网格搜索 | from sklearn.model_selection import GridSearchCV | ||
| 随机搜索 | from sklearn.model_selection import RandomizedSearchCV | |||
| 验证曲线 | 验证曲线 | from sklearn.model_selection import validation_curve | 横轴为某个参数的值,纵轴为模型得分 | |
| 学习曲线 | from sklearn.model_selection import learning_curve | 横轴为训练数据大小,纵轴为模型得分 |