基于图像的人群计数研究(论文阅读笔记)
基于图像的人群计数研究(论文阅读笔记)
一、人群计数研究的问题
人群计数旨在估计图像或视频中人群的数量、密度或分布,属于目标计数领域中的一类,既是智能视频监控分析领域的关键问题和研究热点,也是后续行为分析、拥塞分析、异常检测和事件检测等高级视频处理任务的基础。
二、人群计数研究的发展
1 传统的
通过传统的计算机视觉方法提取行人特征,然后通过目标检测或回归的方式获取图像或视频中人群的数量。无法从图像中提取更抽象的有助于完成人群计数任务的语义特征,使得面对背景复杂、人群密集、遮挡严重的场景时,计数精度无法满足实际需求,具有一定的局限性。
2 基于深度学习的
2.1 基于CNN的人群计数
可以分为两类:直接回归计数法和密度图估计法
| / | 直接回归计数法 | 密度图估计法 |
|---|---|---|
| 步骤 | input(图片)——>outout(人数) | input(图片)——>output(密度图)——>估计人数 |
| 适用性 | 人群稀疏场景 | 取决于密度图的质量 |
提升密度图质量的方法:引入新的损失函数来提高密度图的清晰度和准确度。无论采用哪种方法,都需要先进行特征提取。为了提升特征的鲁棒性,常使用多尺度预测、上下文感知、 空洞卷积、可形变卷积等方法改进特征提取过程,以增强特征的判别能力。
2.2 网络模型
可分为:单分支结构、多分支结构和特殊结构
a 单分支结构
早期基于 CNN 的人群计数网络均为只包含一条数据通路的单分支网络结构。
如Wang[1] 等人最先将CNN 引入人群计数领域(15年提出),提出了一种适用于密集人群场景的端到端 CNN 回归模型。该模型对AlexNet网络[2](12年提出)进行改进,将最后的全连接层替换为单神经元层,直接预测人群数量。
[1] Wang Chuan, Zhang Hua, Yang Liang, et al. Deep people counting in extremely dense crowds [C] // Proc of the 23rd ACM Int Conf on Multimedia. New York: ACM, 2015: 1299-1302
[2] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks [C] // Proc of the 25th Int Conf on Neural Information Processing systems. Cambridge, MA: MIT Press,2012: 1097-1105
Zhang 等人[3]提出了一种基于 AlexNet 的跨场景计数模型 Crowd CNN,首次尝试输出人群密度图。算法会根据目标场景特点,选择相似场景对计数模型进行微调(fine-tuning),如图 1(b)所示,以达到跨场景计数的目的。为了提升计数准确性,作者还提出了透视图(perspective map)的概念,如图 2(a)所示,颜色越红代表目标尺度越大.然后,通过密度图和透视图的融合,如图 2(b)所示,降低透视形变(perspective distortion)的不良影响,提升密度图质量。
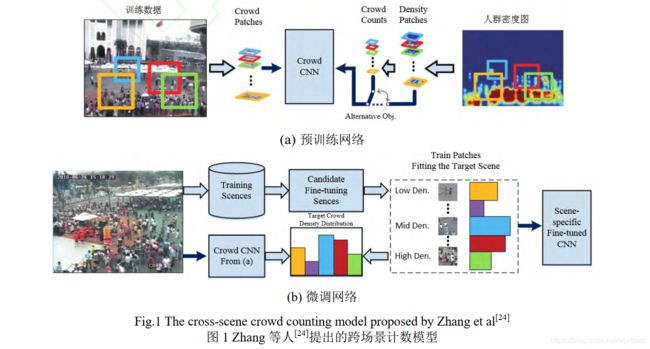
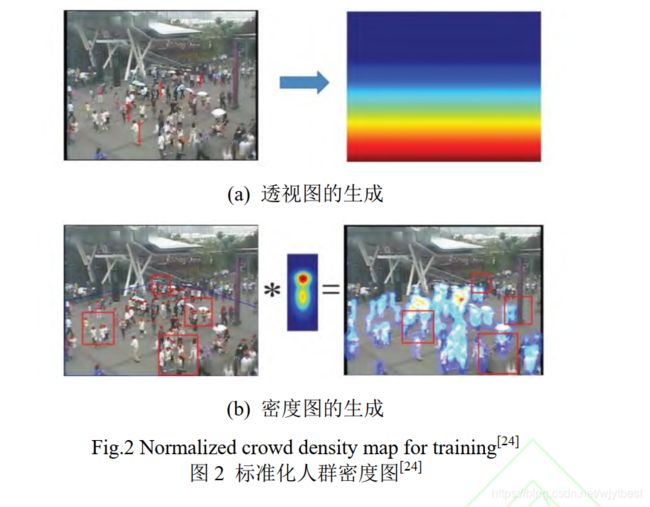
[3] Zhang Cong, Li Hongsheng, Wang Xiaogang, et al. Cross-scene crowd counting via deep convolutional neural networks [C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 833-841.
b 多分支结构
多分支结构的提出是为了解决人群计数场景中存在的多尺度问题。
- 如Boominathan 等人[4]基于CNN 提出了一种双分支结构计数网络 CrowdNet,通过一个浅层网络(shallow network)和一个深层网络(deep network)分别提取不同尺度的特征信息进行融合来预测人群密度图,以适应人群的非均匀缩放和视角的变化,有利于不同场景不同尺度的人群计数。
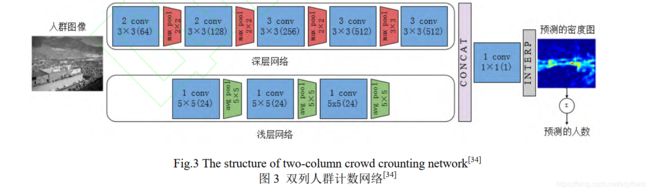
[4] Boominathan L, Kruthiventi S S S, Babu R V, et al. CrowdNet: A deep convolutional network for dense crowd counting [C] // Proc of the 24th ACM Int Conf on Multimedia. New York: ACM, 2016: 640-644
- 受多分支神经网络[5]的启发,Zhang 等人[6]提出了一种多列卷积神经网络( multi-columnCNN, MCNN)用于人群计数,其结构如图 4 所示。每一分支网络采用不同大小的卷积核来提取不同尺度目标的特征信息,减少因为视角变化形成的目标大小不一导致的计数误差。MCNN 建立了图像与人群密度图之间的非线性关系, 通过用全卷积层替换全连接层,使得模型可以处理任意大小的输入图片。为了进一步修正视角变化带来的影响, MCNN 在生成密度图时,没有采用固定的高斯核,而是利用自适应高斯核计算密度图,提升了密度图质量。
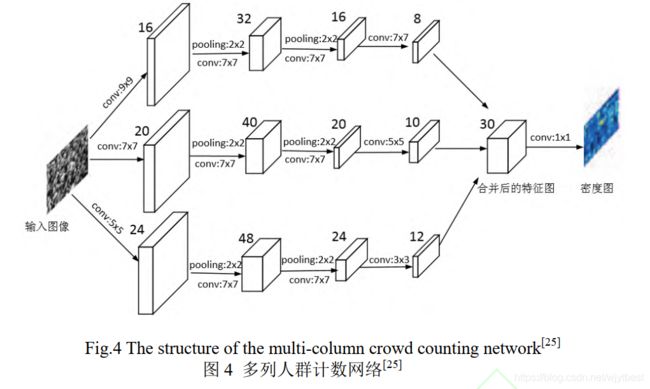
[5] Ciregan D, Meier U, Schmidhuber J. Multi-column deep neural networks for image classification [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2012: 3642-3649
[6] Zhang Yingying, Zhou Desen, Chen Siqin, et al. Single-image crowd counting via multi-column convolutional neural network [C] //Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 589-597
- 为了生成更高质量的密度图, Sindagi 等人[7]提出了上下文金字塔卷积神经网络计数模型 CP-CNN,其结构如图 5 所示。全局上下文估计器( global context estimator, GCE)和局部上下文估计器( local context estimator, LCE)分别提取图像的全局和局部上下文信息,密度估计器(density map estimator, DME)沿用了 MCNN 的多列网络结构生成高维特征图,融合卷积神经网络(fusion-CNN, F-CNN)则将前 3 个部分的输出进行融合,生成密度图,F-CNN 使用了一系列小数步长卷积层帮助重建密度图的细节。同时,针对 CNN 计数网络主要使用像素级欧氏距离损失函数来训练网络导致的生成密度图比较模糊,CP-CNN 引入对抗损失(adversarial loss),利用生成对抗网络(generative adversarial net, GAN)[8]来克服欧氏距离损失函数的不足。
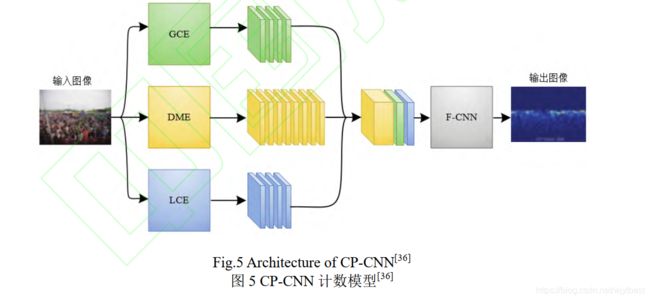
[7] Sindagi V A, Patel V M. Generating high-quality crowd density maps using contextual pyramid CNNs [C] // Proc of the IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2017: 1861-1870
[8] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarialnets [C] // Proc of the 27th Int Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2672-2680
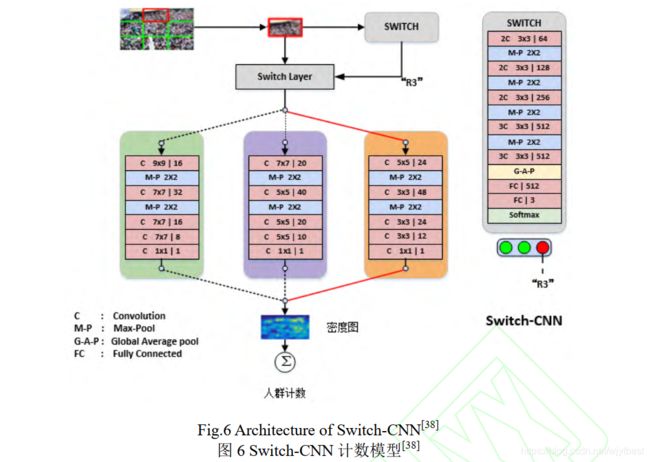
- 2017 年,Sam 等人[9]提出了一种多列选择卷积神经网络( switch convolution neural network ,Switch-CNN)用于人群计数,其结构如图 6 所示。 Swithch-CNN 虽然采用多列网络结构,但是各列网络独立处理不同的区域。在输入网络之前,图像被切分成 3×3 的区域,然后对每个区域使用特定的 SWITCH 模块进行密度等级划分,并根据密度等级选择对应的分支进行计数。通过对于密度不同的人群有针对性地选用不同尺度的回归网络进行密度估计,使得最终的计数结果更为准确。Swithch-CNN 也存在不容忽视的弊端,如果分支选择错误将会大大影响计数准确度。
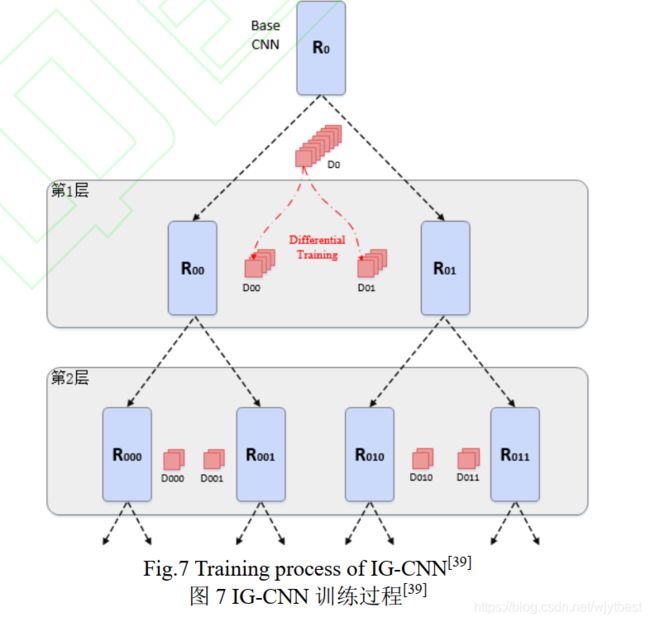
进一步,Sam 等人[10]对 Switch-CNN 进行改进,提出了逐步增长卷积神经网络(incrementally growing CNN,IG-CNN),其层次化训练过程如图 7 所示。
[9] Sam D B, Surya S, Babu R V, et al. Switching convolutional neural network for crowd counting [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition Honolulu. Piscataway, NJ: IEEE, 2017: 4031-4039
[10] Sam D B, Sajjan N N, Babu R V, et al. Divide and grow: Capturing huge diversity in crowd images with incrementally growing CNN [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 3618-3626
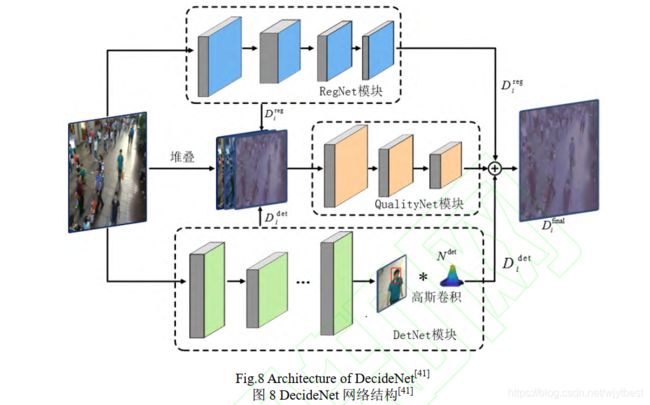
- 在已有的人群计数模型中,通常单纯地假设场景中的人群分布是稀疏或密集的。针对稀疏场景,采用检测方法进行计数; 而针对密集场景,则采用回归方法进行人群密度估计。这样的模型往往难以应对密度变化范围很广的人群场景的计数。为了解决这个问题Liu等人[11]提出了一种检测和回归相结合的人群计数模型,DecideNet,其结构如图 8 所示。RegNet 模块采用回归方法直接从图像中估计人群密度, DetNet 模块则在 Faster-RCNN的后面添加了一个高斯卷积层(Gaussian convolution),直接将检测结果转化为人群密度图,然后 QualityNet引入注意力模块,自动判别人群密集程度,并根据判别结果自适应地调整检测和回归这 2 种方法的权重,再根据这个权重将这 2 种密度图进行融合,以此获取更好的最优解。
[11] Liu Jiang, Gao Chenqiang, Meng Deyu, et al. Decidenet: Counting varying density crowds through attention guided detection and density estimation [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 5197-5206
多列计数网络发展到这里,出现的问题是:
(1)多尺度表达的性能通常依赖于网络分支的数量,即尺度的多样性受限于分支数目;
(2)已有工作大多采用欧氏距离作为损失函数,如果像素之间互相独立,生成的密度图比较模糊。
- 因此,Cao 等人[12]提出了一种尺度聚合网络(scale aggregation network, SANet),其结构如图 9 所示。该模型没有采用 MCNN 的多列网络结构,而是借鉴了 Inception[13]的架构思想,在每个卷积层同时使用不同大小的卷积核提取不同尺度的特征,最后通过反卷积生成高分辨率的密度图.整个模型由FME( feature map encoder)和 DME( density map estimator)这 2 个部分组成, FME 聚合提取出多尺度特征, DME 融合特征生成高分辨率的密度图。度量预测的密度图与 ground-truth 的相似度时,采用SSIM (图像质量评估中的结构相似性指标,2004年提出)计算局部一致性损失,然后对欧氏损失和局部一致性损失进行加权得到总损失。
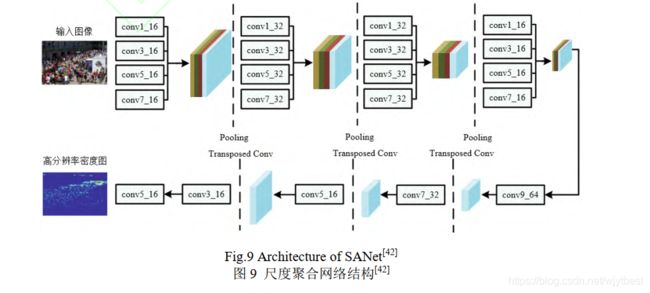
[12] Cao Xinkun, Wang Zhipeng, Zhao Yanyun, et al. Scale aggregation network for accurate and efficient crowd counting [G] // LNCS 11209: Proc of the 15th European Conf on Computer Vision. Berlin: Springer, 2018: 734-750
[13] Szegedy C, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1-9
发展到这里,人们开始关注加入注意力机制来解决多尺度问题:
- Mohammad 等人[14]首次将注意力机制引入人群计数领域,提出了多分支的尺度感知注意力网络( scale-aware attention network,SAAN),其结构如图 10 所示。该网络由 4 个模块组成 ,其中多尺度特征提取器( multi-scale feature extractor, MFE)负责从输入图像中提取多尺度特征图。受到 MCNN[25]启发, MFE 被设计成包含 3 个分支的多列网络,每个分支的感受野大小不同,可以捕获不同尺度的特征;为了获得图像的全局密度信息,与MFE 中 3 个不同尺度的分支相对应,定义了 3 个全局密度等级,然后利用全局尺度注意力(global scale attentions, GSA)模块负责提取输入图像的全局上下文信息,计算 3 个全局密度等级对应的评分,并对这3 个分值进行归一化。局部尺度注意力(local scale attention, LSA)负责提取图像不同位置的细粒度局部上下文信息,并生成 3 张像素级的注意力图,用于描述局部尺度信息;最后,根据全局和局部的尺度信息对 MFE 提取的特征图进行加权,然后将加权后的特征图输入融合网络(fusion network, FN)生成最终的密度图。

[14] Hossain M, Hosseinzadeh M, Chanda O, et al. Crowd counting using scale-aware attention networks [C] // Proc of the IEEE Winter Conf on Applications of Computer Vision. Piscataway, NJ: IEEE, 2019: 1280-1288
c 特殊结构
多分支结构的缺点:
- 网络模型参数繁多、训练困难,导致计数实时性较差
- 多分支网络的结构冗余度较高。
- 多分支计数网络原本是想通过不同的分支采用大小不等的感受野来提取不同尺度的特征,增强特征的适用性和鲁棒性。但研究表明,不同分支学习到的特征相似度很高,并没有因为场景密集程度不同而出现明显差异。
所以,发展到这里人们开始思考构建一些新型的网络架构,例如空洞卷积网络(dilated convolutional networks)[15]、可形变卷积网络(deformable convolutional network)[16]、 GAN等。
[15] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions [EB/OL]. (2016-04-30)[2020-12-23]. https://arxiv.org/abs/1511.07122
[16] Dai Jifeng, Qi Haozhi, Xiong Yuwen, et al. Deformable convolutional networks [C] // Proc of the IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2017: 764-773
- 2018 年, Li 等人[17]提出了一种适用于密集人群计数的空洞卷积神经网络模型 CSRNet,其网络结构如图 11 所示。
空洞卷积可以在保持分辨率的同时扩大感受野的优势,保留更多的图像细节信息。
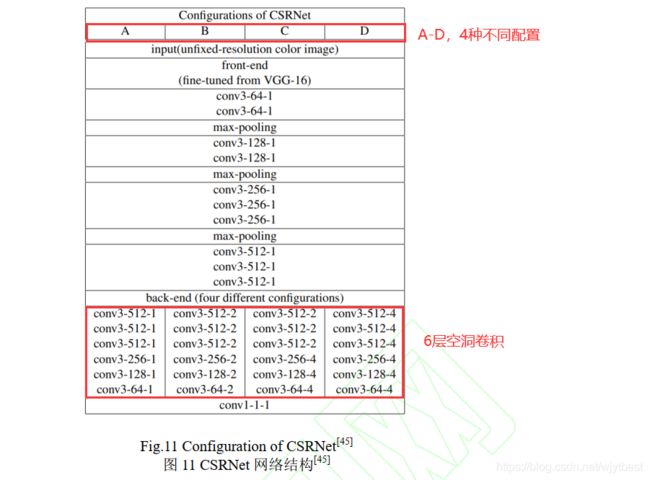
[17] Li Yuhong, Zhang Xiaofan, Chen Deming. CSRNET: Dilated convolutional neural networks for understanding the highly congested scenes [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 1091-1100
- 一种基于 GAN 的跨尺度人群计数网络[18](adversarial cross-scale consistency pursuit network, ACSCP),其结构如图 12 所示,对抗损失的引入使得生成的密度图更加尖锐, U-net 结构的生成器保证了密度图的高分辨率,同时跨尺度一致性正则子约束了图像间的跨尺度误差。因此,该模型最终能生成质量好、分辨率高的人群分布密度图。
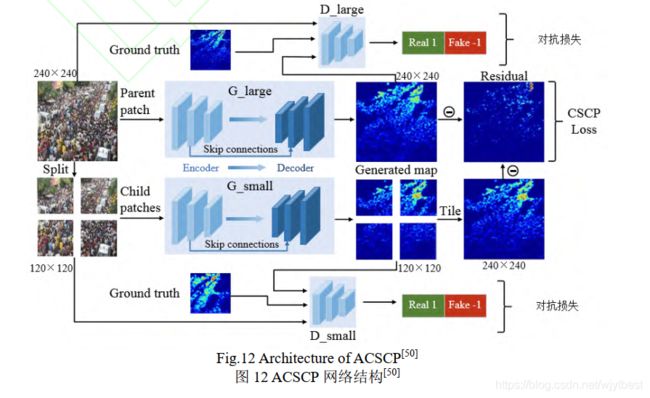
[18] Shen Zan, Xu Yi, Ni Bingbing, et al. Crowd counting via adversarial cross-scale consistency pursuit [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 5245-5254
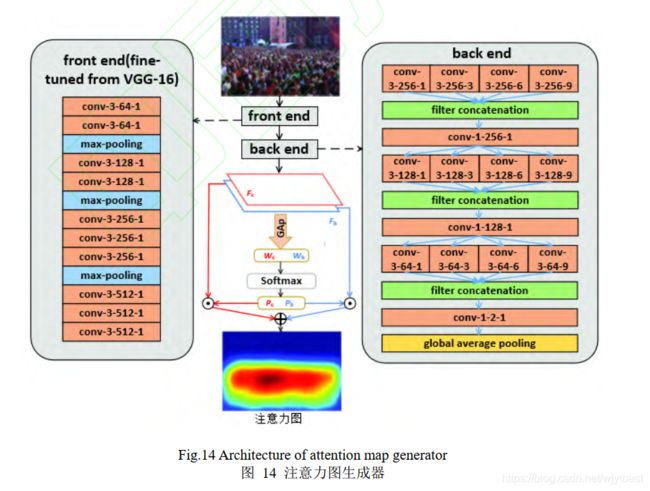
- 为了解决背景噪声、遮挡和不一致的人群分布问题,Liu 等人[19]提出了一种融合了注意力机制的可形变卷积网络 ADCrowdNet用于人群计数。如图 13 所示,该网络模型主要由 2 个部分串联而成,其中注意力图生成器(attention map generator, AMG)用于检测人群候选区域,并估计这些区域的拥挤程度,密度图估计器( density map estimator, DME) 是一个多尺度可形变卷积网络,用于生成高质量的密度图。由于加入了注意力,可形变卷积添加了方向参数,卷积核在注意力指导下在特征图上延伸,可以对不同形状的人群分布进行建模,很好地适应真实场景中摄像机视角失真和人群分布多样性导致的畸变,保证了拥挤场景中人群密度图的准确性。

注意力图生成器 AMG 的网络结构如图 14 所示,采用了 VGG-16 网络前 10 个卷积层作为前端(front end),用来提取图像的底层特征,后端(back end)架构类似 Inception 结构,采用多个空洞率不同的空洞卷积层扩大感受野,应对不同尺度的人群分布.后端输出 2 通道的特征图,分别代表前景(人群)和背景.然后,通过对特征图取全局平均池化获得相应的权重,再对其结果用softmax进行分类获取概率.最后,对特征图和概率进行点乘获得注意力图。
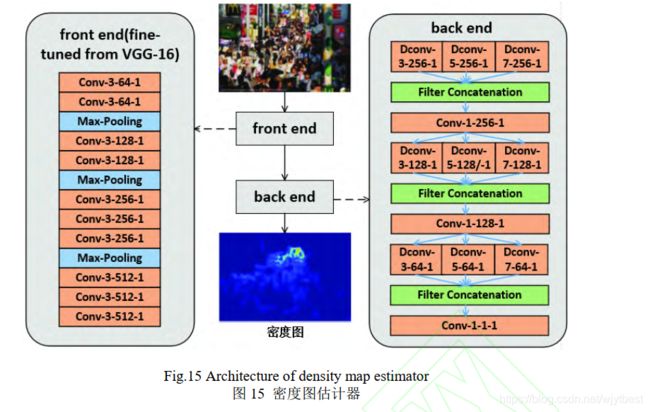
密度图估计器 DME 的网络结构如图 15 所示, 前端依然使用 VGG-16,后端架构依然类似 inception 结构,但是采用了更适合拥挤嘈杂场景的多尺度可形变卷积,以适应人群分布的几何形变。
[19] Liu Ning, Long Yongchao, Zou Changqing, et al. ADCrowdNet: An attention-injective deformable convolutional network for crowd understanding [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2019: 3225-3234
3. 损失函数
3.1 欧式距离

优点:简单、训练速度快,计数效果较好,早期得到了较为广泛的应用。
缺点:鲁棒性较差,很容易因为个别像素点的极端情况而影响整体的计数效果。此外,欧氏距离损失是取所有像素点的平均,并不关注图片的结构化信息。对于同一张图片,容易出现人群密集区域预测值偏小,而人群稀疏区域预测值偏大的问题,但是最终的平均结果却没有体现这些问题,从而导致生成的密度图模糊、细节不清晰。
3.2 结构相似性损失(SSIM)
这个指标是在图像质量评价相关论文中由Wang 等人提出的图像质量评价标准,SSIM 从图像的亮度、对比度和结构这 3 个方面度量图像相似性,并通过均值、方差、协方差 3 个局部统计量计算2张图像之间的相似度。SSIM的取值范围在-1~1之间,SSIM 值越大,说明相似度越高。

3.3 生成对抗损失
GAN为解决图像转换问题提供了一个可行的思路,即可以通过生成网络和判别网络的不断博弈,进而使生成网络学习人群密度分布,生成密度图的质量逐渐趋好;判别网络也通过不断训练,提高本身的判别能力。
4. 密度图生成
高质量密度图是人群计数算法成功的基础和关键, ground-truth 的生成方法将是人群计数领域未来的一个研究重点。为了训练计数网络,需要对人群图片中的目标进行标注,常见的做法是为图片中的每个人头标注中心坐标,然后再利用高斯核将坐标图转化为 ground-truth人群密度图,ground-truth 密度图生成的关键在于如何选择高斯核,设置不同的高斯核对网络性能的影响很大,以下介绍几种常用的高斯核设置方法。
4.1 几何自适应法
由于存在透视效应,在人群图片中远近景目标的尺寸差异较大,不同位置人头对应着不同大小的像素区域.因此要想生成更精确的人群密度图,就需要考
虑透视畸变的影响,大人头应采用大尺寸高斯核,小人头则正好相反。
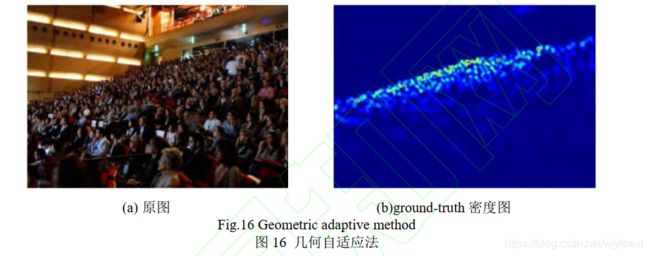
MCNN认为在拥挤的场景中,头部大小通常与相邻 2 个人中心点的距离有关。因此根据每个人与其k个邻居的平均距离来自适应地确定每个人的头部尺寸,也就是高斯卷积核的方差,然后将所有人头卷积后的结果进行累加,生成人群密度图。这种方法虽然考虑了多尺度差异,但是对于近处目标来说,人头间距远大于人头的实际尺寸,导致高斯核尺寸过大,近处人群的密度图会因为值过小而消失。如图 16 所示,密度图中只能看到远处有人群,而近处的人群极不明显。
4.2 固定高斯核法
该方法忽略了人头尺寸差异,以及自身与邻居的相似性,无论图片中哪个位置的人头均采用方差大小固定的高斯核对每个人头进行高斯模糊,采用固定高斯核的算法有 CP-CNN[36],其生成的 ground-truth 密度图如图 17 所示.固定高斯核法解决了几何自适应法中的近处人头消失的问题,但是由于高斯核大小固定,对于远处人头来说,高斯核尺寸可能过大,使得远处人头出现重叠,降低了密度图质量。

4.3 内容感知标注法
为解决上述 2 种方法存在的问题, Oghaz 等人[66]提出了一种通过内容感知标注技术生成密度图的方法。首先,用暴力最近邻(brute-force nearest neighbor)算 法 定 位 最 近 的 头 部 , 再 用 无 监 督 分 割 算 法Chan-Vese 分割出头部区域,然后依据邻居头部的大小计算高斯核尺寸,其生成的密度图如图 18 所示。该方法也是根据邻居情况灵活确定高斯核大小,但是与几何自适应法相比,它采用 brute-force 最近邻算法替代 k-d 树 空 间 划 分 法 (k-d tree space partitioning approach)来寻找最近邻,这样能确保寻找结果与实际相符。

5. 评价指标
在人群计数领域,常用的评价指标有:
- 均方误差(mean squared error)
- 平均绝对误差(mean absolute error)
- 均方根误差(root mean squared error)

MAE 可以反映模型的准确性,而 MSE 和 RMSE可以反映模型的鲁棒性。
6. 总结
1、对于目标计数方向,采集图像非常困难,且无法实现准确标注,此时可以考虑通过人工合成的方法生成图片,例如 GCC[20]通过生成对抗网络人工合成了大量图片,为构建数据集提供了新思路。
2、不同场景下(光照、天气、遮挡)的人群计数问题研究
3、人群计数的迁移学习
[20] Wang Qi, Gao Junyu, Lin Wei, et al. Learning from synthetic data for crowd counting in the wild [C] // Proc of the IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2019: 8198-8207
参考文献:余鹰,朱慧琳,钱进,潘诚,苗夺谦.基于深度学习的人群计数研究综述.计算机研究与发展.