Pytorch与视觉竞赛入门3-使用Pytorch搭建经典网络
Pytorch与视觉竞赛入门3-使用Pytorch搭建经典网络
VGG
原理

VGG16的结构图如下:

LRN模块
AlexNet中提出的局部响应归一化(LRN)(Krizhevsky等,2012),VGG的实验结果表明LRN对性能提升并没有什么帮助,而且还浪费了内存的计算的损耗。
特点
VGG16的突出特点是简单,体现在:
卷积层均采用相同的卷积核参数
卷积层均表示为
conv3-XXX,其中conv3说明该卷积层采用的卷积核的尺寸(kernel size)是3,即宽(width)和高(height)均为3,3*3是很小的卷积核尺寸,结合其它参数(步幅stride=1,填充方式padding=same),这样就能够使得每一个卷积层(张量)与前一层(张量)保持相同的宽和高。XXX代表卷积层的通道数。池化层均采用相同的池化核参数
池化层的参数均为2××2,步幅stride=2,max的池化方式,这样就能够使得每一个池化层(张量)的宽和高是前一层(张量)的1212。
模型是由若干卷积层和池化层堆叠(stack)的方式构成,比较容易形成较深的网络结构(在2014年,16层已经被认为很深了)。
综合上述分析,可以概括VGG的优点为: Small filters, Deeper networks.
VGG改进点总结
- 使用了更小的3*3卷积核,和更深的网络。两个3*3卷积核的堆叠相对于5*5卷积核的视野,三个3*3卷积核的堆叠相当于7*7卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3*3结构只有7*7结构参数数量的 ( 3 ∗ 3 ∗ 3 ) / ( 7 ∗ 7 ) = 55 % (3*3*3)/(7*7)=55\% (3∗3∗3)/(7∗7)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
- 在VGGNet的卷积结构中,引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
- 训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
- 采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
VGG的缺点
VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力;但同时缺点也很明显:
- 即训练时间过长,调参难度大。
- 需要的存储容量大,不利于部署。例如存储VGG16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
VGG相关的问题
-
之前的网络都用7x7,11x11等比较大的卷积核,现在全用3x3不会有什么影响吗?
几个小滤波器卷积层的组合比一个大滤波器卷积层好:
假设你一层一层地重叠了3个3x3的卷积层(层与层之间有非线性激活函数)。在这个排列下,第一个卷积层中的每个神经元都对输入数据体有一个3x3的视野。第二个卷积层上的神经元对第一个卷积层有一个3x3的视野,也就是对输入数据体有5x5的视野。同样,在第三个卷积层上的神经元对第二个卷积层有3x3的视野,也就是对输入数据体有7x7的视野。假设不采用这3个3x3的卷积层,二是使用一个单独的有7x7的感受野的卷积层,那么所有神经元的感受野也是7x7。
但是,多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。此外,假设所有的数据有C个通道,那么单独的7x7卷积层将会包含
7*7*C=49C个参数,而3个3x3的卷积层的组合仅有个3*(3*3*C)=27C个参数。直观说来,最好选择带有小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者可以表达出输入数据中更多个强力特征,使用的参数也更少。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
-
虽然网络层数加深,但VGG在训练的过程中比AlexNet收敛的要快一些,为什么?
主要因为:
- 使用小卷积核和更深的网络进行的正则化;
- 在特定的层使用了预训练得到的数据进行参数的初始化。对于较浅的网络,如网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
代码实现
模型需求分析
对模型进行抽象和分析,以便写出更优美的代码~
由VGG多个变种的结构图可知,主要包括5个卷积块和一个分类块,可以考虑用一个函数对5个卷积块进行包装,传入的参数为channel大小和层数,利用nn.Sequential函数把块中的各个层串联起来。
代码
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class VGG(nn.Module):
"""
VGG builder
"""
def __init__(self, arch: object, num_classes=1000) -> object:
super(VGG, self).__init__()
self.in_channels = 3
self.conv3_64 = self.__make_layer(64, arch[0])
self.conv3_128 = self.__make_layer(128, arch[1])
self.conv3_256 = self.__make_layer(256, arch[2])
self.conv3_512a = self.__make_layer(512, arch[3])
self.conv3_512b = self.__make_layer(512, arch[4])
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def __make_layer(self, channels, num):
layers = []
for i in range(num):
layers.append(nn.Conv2d(self.in_channels, channels, 3, stride=1, padding=1, bias=False)) # same padding
layers.append(nn.BatchNorm2d(channels))
layers.append(nn.ReLU())
self.in_channels = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv3_64(x)
out = F.max_pool2d(out, 2)
out = self.conv3_128(out)
out = F.max_pool2d(out, 2)
out = self.conv3_256(out)
out = F.max_pool2d(out, 2)
out = self.conv3_512a(out)
out = F.max_pool2d(out, 2)
out = self.conv3_512b(out)
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return F.softmax(out)
构建模型
网络的深入通过一个数组控制,数组的元素没每个卷积层组内卷积层的数量。
def VGG_11():
return VGG([1, 1, 2, 2, 2], num_classes=1000)
def VGG_13():
return VGG([2, 2, 2, 2, 2], num_classes=1000)
def VGG_16():
return VGG([2, 2, 3, 3, 3], num_classes=1000)
def VGG_19():
return VGG([2, 2, 4, 4, 4], num_classes=1000)
打印模型
def test():
# net = VGG_11()
# net = VGG_13()
# net = VGG_16()
net = VGG_19()
net.cuda()
summary(net, (3, 224, 224))
test()
#打印结果
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,728
BatchNorm2d-2 [-1, 64, 224, 224] 128
ReLU-3 [-1, 64, 224, 224] 0
Conv2d-4 [-1, 64, 224, 224] 36,864
BatchNorm2d-5 [-1, 64, 224, 224] 128
ReLU-6 [-1, 64, 224, 224] 0
Conv2d-7 [-1, 128, 112, 112] 73,728
BatchNorm2d-8 [-1, 128, 112, 112] 256
ReLU-9 [-1, 128, 112, 112] 0
Conv2d-10 [-1, 128, 112, 112] 147,456
BatchNorm2d-11 [-1, 128, 112, 112] 256
ReLU-12 [-1, 128, 112, 112] 0
Conv2d-13 [-1, 256, 56, 56] 294,912
BatchNorm2d-14 [-1, 256, 56, 56] 512
ReLU-15 [-1, 256, 56, 56] 0
Conv2d-16 [-1, 256, 56, 56] 589,824
BatchNorm2d-17 [-1, 256, 56, 56] 512
ReLU-18 [-1, 256, 56, 56] 0
Conv2d-19 [-1, 256, 56, 56] 589,824
BatchNorm2d-20 [-1, 256, 56, 56] 512
ReLU-21 [-1, 256, 56, 56] 0
Conv2d-22 [-1, 256, 56, 56] 589,824
BatchNorm2d-23 [-1, 256, 56, 56] 512
ReLU-24 [-1, 256, 56, 56] 0
Conv2d-25 [-1, 512, 28, 28] 1,179,648
BatchNorm2d-26 [-1, 512, 28, 28] 1,024
ReLU-27 [-1, 512, 28, 28] 0
Conv2d-28 [-1, 512, 28, 28] 2,359,296
BatchNorm2d-29 [-1, 512, 28, 28] 1,024
ReLU-30 [-1, 512, 28, 28] 0
Conv2d-31 [-1, 512, 28, 28] 2,359,296
BatchNorm2d-32 [-1, 512, 28, 28] 1,024
ReLU-33 [-1, 512, 28, 28] 0
Conv2d-34 [-1, 512, 28, 28] 2,359,296
BatchNorm2d-35 [-1, 512, 28, 28] 1,024
ReLU-36 [-1, 512, 28, 28] 0
Conv2d-37 [-1, 512, 14, 14] 2,359,296
BatchNorm2d-38 [-1, 512, 14, 14] 1,024
ReLU-39 [-1, 512, 14, 14] 0
Conv2d-40 [-1, 512, 14, 14] 2,359,296
BatchNorm2d-41 [-1, 512, 14, 14] 1,024
ReLU-42 [-1, 512, 14, 14] 0
Conv2d-43 [-1, 512, 14, 14] 2,359,296
BatchNorm2d-44 [-1, 512, 14, 14] 1,024
ReLU-45 [-1, 512, 14, 14] 0
Conv2d-46 [-1, 512, 14, 14] 2,359,296
BatchNorm2d-47 [-1, 512, 14, 14] 1,024
ReLU-48 [-1, 512, 14, 14] 0
Linear-49 [-1, 4096] 102,764,544
ReLU-50 [-1, 4096] 0
Dropout-51 [-1, 4096] 0
Linear-52 [-1, 4096] 16,781,312
ReLU-53 [-1, 4096] 0
Dropout-54 [-1, 4096] 0
Linear-55 [-1, 1000] 4,097,000
================================================================
Total params: 143,672,744
Trainable params: 143,672,744
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 340.13
Params size (MB): 548.07
Estimated Total Size (MB): 888.77
----------------------------------------------------------------
ResNet
原理
原理部分主要摘自:ResNet详解与分析
残差结构有什么作用可以查看之前的博客:Transformer相关——残差模块
残差模块结构图示
F ( x ) + x F(x)+x F(x)+x构成的block称之为Residual Block,即残差块,如下图所示,多个相似的Residual Block串联构成ResNet。
一个残差块有2条路径 F ( x ) F(x) F(x)和 x x x, F ( x ) F(x) F(x)路径拟合残差,不妨称之为残差路径, x x x路径为identity mapping恒等映射,称之为”shortcut”。图中的 ⊕ ⊕ ⊕为element-wise addition,要求参与运算的 F ( x ) F(x) F(x)和 x x x的尺寸要相同。所以,随之而来的问题是:
- 残差路径如何设计?
- shortcut路径如何设计?
- Residual Block之间怎么连接?(也就是残差网络的结构)
残差路径如何设计?
在原论文中,残差路径可以大致分成2种,一种有bottleneck结构,即下图右中的1×1卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”,另一种没有bottleneck结构,如下图左所示,称之为“basic block”。
shortcut路径如何设计?
shortcut路径大致也可以分成2种,取决于残差路径是否改变了feature map数量和尺寸,一种是将输入x原封不动地输出,另一种则需要经过1×1卷积来升维 or/and 降采样,主要作用是将输出与F(x)路径的输出保持shape一致,对网络性能的提升并不明显,两种结构如下图所示:


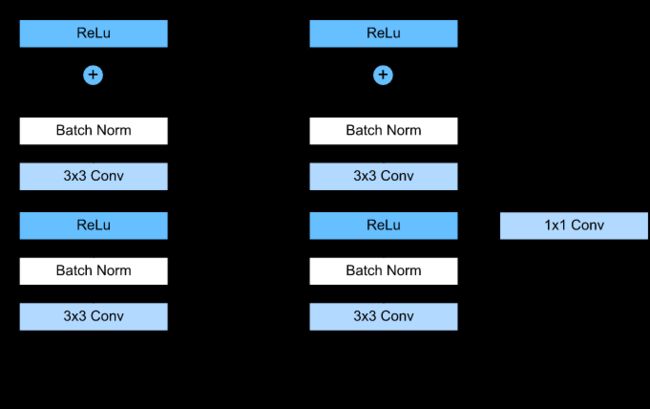
残差网络的结构
ResNet的设计有如下特点:
- 与plain net相比,ResNet多了很多“旁路”,即shortcut路径,其首尾圈出的layers构成一个Residual Block;
- ResNet中,所有的Residual Block都没有pooling层,降采样是通过conv的stride实现的;
- 分别在conv3_1、conv4_1和conv5_1 Residual Block,降采样1倍,同时feature map数量增加1倍,如图中虚线划定的block;
- 通过Average Pooling得到最终的特征,而不是通过全连接层;
- 每个卷积层之后都紧接着BatchNorm layer,为了简化,图中并没有标出;
ResNet结构非常容易修改和扩展,通过调整block内的channel数量以及堆叠的block数量,就可以很容易地调整网络的宽度和深度,来得到不同表达能力的网络,而不用过多地担心网络的“退化”问题,只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。
不断地增加ResNet的深度,甚至增加到1000层以上,残差也没有发生“退化”,可见Residual Block的有效性。ResNet的动机在于认为拟合残差比直接拟合潜在映射更容易优化,下面通过绘制error surface直观感受一下shortcut路径的作用,图片截自Loss Visualization。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5j09AD08-1637497879881)(https://s2.ax1x.com/2020/02/24/38Kd2t.png)]
- ResNet-20(no short)浅层plain net的error surface还没有很复杂,优化也会很困难,但是增加到56层后复杂程度极度上升。对于plain net,随着深度增加,error surface 迅速“恶化”;
- 引入shortcut后,error suface变得平滑很多,梯度的可预测性变得更好,显然更容易优化;


改进
论文Identity Mappings in Deep Residual Networks进一步研究ResNet,通过ResNet反向传播的理论分析以及设计了以下几种不同的Residual Block结构。注意,这里的视角与之前不同,这里将shortcut路径视为主干路径,将残差路径视为旁路。

经过实验验证,(e)full pre-activation表现最好,具有更强的泛化能力,能更好地避免“退化”,堆叠大于1000层后,性能仍在变好。具体的变化在于:
- **通过保持shortcut路径的“纯净”,可以让信息在前向传播和反向传播中平滑传递,这点十分重要。**为此,如无必要,不引入1×1卷积等操作,同时将上图灰色路径上的ReLU移到了F(x)路径上。
- 在残差路径上,将BN和ReLU统一放在weight前作为pre-activation,获得了“Ease of optimization”以及“Reducing overfitting”的效果。
代码实现
模型需求分析
对模型进行抽象和分析,以便写出更优美的代码~
需要实现:
- 两个不同残差模块的类
BasicBlock和Bottleneck;其中的3x3的卷积层和1x1的卷积层可以被进一步包装起来,注意在conv3_1、conv4_1和conv5_1 Residual Block,需要降采样1倍,但在conv2_1不需要,因此残差模块需要一个控制是否降采样的参数。 - ResNet模型:需要传入block类型及block的层数;
- 构建模型的函数:封装构建不同的ResNet。
代码
pytorch官方实现的源码
conv3x3和conv1x1
dilation表示空洞卷积间隔,空洞卷积是什么可以查看的博客:Pytorch与视觉竞赛入门2_冬于的博客-CSDN博客
from typing import Type, Any, Callable, Union, List, Optional
import torch
import torch.nn as nn
from torch import Tensor
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
"""3x3 convolution with padding"""
return nn.Conv2d(
in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=dilation,
groups=groups,
bias=False,
dilation=dilation,
)
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
BasicBlock
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1: #空洞卷积
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1 如果stride=1就不使用下采样
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
Bottleneck
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion: int = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.0)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
ResNet模型
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
num_classes: int = 1000,
zero_init_residual: bool = False,
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(
self,
block: Type[Union[BasicBlock, Bottleneck]],
planes: int,
blocks: int,
stride: int = 1,
dilate: bool = False,
) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(
block(
self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
)
)
self.inplanes = planes * block.expansion
for _ in range(1, blocks): #只有layer2...layerN内部的第一个残差模块要用下采样
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
return nn.Sequential(*layers)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
构建模型
def _resnet(
arch: str,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
pretrained: bool,
progress: bool,
**kwargs: Any,
) -> ResNet:
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
model.load_state_dict(state_dict)
return model
def resnet18(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet18", BasicBlock, [2, 2, 2, 2], pretrained, progress, **kwargs)
def resnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-34 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet34", BasicBlock, [3, 4, 6, 3], pretrained, progress, **kwargs)
def resnet50(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet50", Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
def resnet101(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet101", Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
def resnet152(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-152 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet152", Bottleneck, [3, 8, 36, 3], pretrained, progress, **kwargs)
打印模型
from torchsummary import summary
net = resnet34()
summary(net, (3, 224, 224))
#打印结果
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 64, 56, 56] 36,864
BatchNorm2d-20 [-1, 64, 56, 56] 128
ReLU-21 [-1, 64, 56, 56] 0
Conv2d-22 [-1, 64, 56, 56] 36,864
BatchNorm2d-23 [-1, 64, 56, 56] 128
ReLU-24 [-1, 64, 56, 56] 0
BasicBlock-25 [-1, 64, 56, 56] 0
Conv2d-26 [-1, 128, 28, 28] 73,728
BatchNorm2d-27 [-1, 128, 28, 28] 256
ReLU-28 [-1, 128, 28, 28] 0
Conv2d-29 [-1, 128, 28, 28] 147,456
BatchNorm2d-30 [-1, 128, 28, 28] 256
Conv2d-31 [-1, 128, 28, 28] 8,192
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 128, 28, 28] 147,456
BatchNorm2d-36 [-1, 128, 28, 28] 256
ReLU-37 [-1, 128, 28, 28] 0
Conv2d-38 [-1, 128, 28, 28] 147,456
BatchNorm2d-39 [-1, 128, 28, 28] 256
ReLU-40 [-1, 128, 28, 28] 0
BasicBlock-41 [-1, 128, 28, 28] 0
Conv2d-42 [-1, 128, 28, 28] 147,456
BatchNorm2d-43 [-1, 128, 28, 28] 256
ReLU-44 [-1, 128, 28, 28] 0
Conv2d-45 [-1, 128, 28, 28] 147,456
BatchNorm2d-46 [-1, 128, 28, 28] 256
ReLU-47 [-1, 128, 28, 28] 0
BasicBlock-48 [-1, 128, 28, 28] 0
Conv2d-49 [-1, 128, 28, 28] 147,456
BatchNorm2d-50 [-1, 128, 28, 28] 256
ReLU-51 [-1, 128, 28, 28] 0
Conv2d-52 [-1, 128, 28, 28] 147,456
BatchNorm2d-53 [-1, 128, 28, 28] 256
ReLU-54 [-1, 128, 28, 28] 0
BasicBlock-55 [-1, 128, 28, 28] 0
Conv2d-56 [-1, 256, 14, 14] 294,912
BatchNorm2d-57 [-1, 256, 14, 14] 512
ReLU-58 [-1, 256, 14, 14] 0
Conv2d-59 [-1, 256, 14, 14] 589,824
BatchNorm2d-60 [-1, 256, 14, 14] 512
Conv2d-61 [-1, 256, 14, 14] 32,768
BatchNorm2d-62 [-1, 256, 14, 14] 512
ReLU-63 [-1, 256, 14, 14] 0
BasicBlock-64 [-1, 256, 14, 14] 0
Conv2d-65 [-1, 256, 14, 14] 589,824
BatchNorm2d-66 [-1, 256, 14, 14] 512
ReLU-67 [-1, 256, 14, 14] 0
Conv2d-68 [-1, 256, 14, 14] 589,824
BatchNorm2d-69 [-1, 256, 14, 14] 512
ReLU-70 [-1, 256, 14, 14] 0
BasicBlock-71 [-1, 256, 14, 14] 0
Conv2d-72 [-1, 256, 14, 14] 589,824
BatchNorm2d-73 [-1, 256, 14, 14] 512
ReLU-74 [-1, 256, 14, 14] 0
Conv2d-75 [-1, 256, 14, 14] 589,824
BatchNorm2d-76 [-1, 256, 14, 14] 512
ReLU-77 [-1, 256, 14, 14] 0
BasicBlock-78 [-1, 256, 14, 14] 0
Conv2d-79 [-1, 256, 14, 14] 589,824
BatchNorm2d-80 [-1, 256, 14, 14] 512
ReLU-81 [-1, 256, 14, 14] 0
Conv2d-82 [-1, 256, 14, 14] 589,824
BatchNorm2d-83 [-1, 256, 14, 14] 512
ReLU-84 [-1, 256, 14, 14] 0
BasicBlock-85 [-1, 256, 14, 14] 0
Conv2d-86 [-1, 256, 14, 14] 589,824
BatchNorm2d-87 [-1, 256, 14, 14] 512
ReLU-88 [-1, 256, 14, 14] 0
Conv2d-89 [-1, 256, 14, 14] 589,824
BatchNorm2d-90 [-1, 256, 14, 14] 512
ReLU-91 [-1, 256, 14, 14] 0
BasicBlock-92 [-1, 256, 14, 14] 0
Conv2d-93 [-1, 256, 14, 14] 589,824
BatchNorm2d-94 [-1, 256, 14, 14] 512
ReLU-95 [-1, 256, 14, 14] 0
Conv2d-96 [-1, 256, 14, 14] 589,824
BatchNorm2d-97 [-1, 256, 14, 14] 512
ReLU-98 [-1, 256, 14, 14] 0
BasicBlock-99 [-1, 256, 14, 14] 0
Conv2d-100 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-101 [-1, 512, 7, 7] 1,024
ReLU-102 [-1, 512, 7, 7] 0
Conv2d-103 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-104 [-1, 512, 7, 7] 1,024
Conv2d-105 [-1, 512, 7, 7] 131,072
BatchNorm2d-106 [-1, 512, 7, 7] 1,024
ReLU-107 [-1, 512, 7, 7] 0
BasicBlock-108 [-1, 512, 7, 7] 0
Conv2d-109 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-110 [-1, 512, 7, 7] 1,024
ReLU-111 [-1, 512, 7, 7] 0
Conv2d-112 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-113 [-1, 512, 7, 7] 1,024
ReLU-114 [-1, 512, 7, 7] 0
BasicBlock-115 [-1, 512, 7, 7] 0
Conv2d-116 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-117 [-1, 512, 7, 7] 1,024
ReLU-118 [-1, 512, 7, 7] 0
Conv2d-119 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-120 [-1, 512, 7, 7] 1,024
ReLU-121 [-1, 512, 7, 7] 0
BasicBlock-122 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-123 [-1, 512, 1, 1] 0
Linear-124 [-1, 1000] 513,000
================================================================
Total params: 21,797,672
Trainable params: 21,797,672
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 96.29
Params size (MB): 83.15
Estimated Total Size (MB): 180.01
----------------------------------------------------------------
参考资料
VGG-论文解读
VGG16学习笔记
ResNet详解与分析
pytorch官方实现的源码