CoT Net:Contextual Transformer Networks for Visual Recognition
文章目录
- Contextual Transformer Networks for Visual Recognition
- 一、Contextual Transformer Block
-
- 1.代码
- 2.实验
- 二、Contextual Transformer Networks
-
- 1.代码
- 2.实验
Contextual Transformer Networks for Visual Recognition
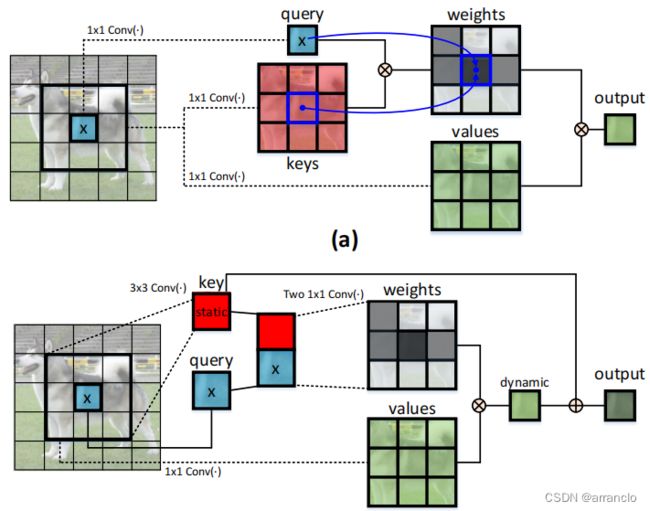
一、Contextual Transformer Block
提出一种新的计算self_atention的方法
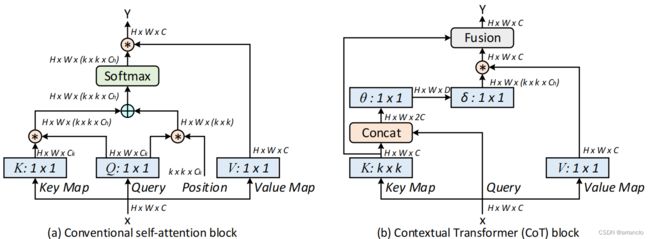
1.代码
CotLayer:代替resnet中的 3×3卷积
def forward(self, x):
# ===================================
# k1 static contextual information
# ===================================
k = self.key_embed(x) # nn.Conv2d nn.BatchNorm2d nn.ReLU
# ===================================
# k1 static contextual information
# ===================================
# ===================================
# A contextualized attention matrix
# ===================================
qk = torch.cat([x, k], dim=1) #
b, c, qk_hh, qk_ww = qk.size()
w = self.embed(qk) # nn.Conv2d nn.BatchNorm2d nn.ReLU nn.Conv2d nn.GroupNorm
w = w.view(b, 1, -1, self.kernel_size*self.kernel_size, qk_hh, qk_ww)
# ===================================
# A contextualized attention matrix
# ===================================
# ===================================
# k2 dynamic contextual representation of inputs
# ===================================
x = self.conv1x1(x) # v nn.Conv2d nn.BatchNorm2d
x = self.local_conv(x, w) # local matrix multiplication LocalConvolution
x = self.bn(x) # nn.BatchNorm2d
x = self.act(x) # nn.SiLU or x.mul(x.sigmoid())
# ===================================
# k2 dynamic contextual representation of inputs
# ===================================
# ===================================
# Fusion
# ===================================
B, C, H, W = x.shape
x = x.view(B, C, 1, H, W)
k = k.view(B, C, 1, H, W)
x = torch.cat([x, k], dim=2)
x_gap = x.sum(dim=2)
x_gap = x_gap.mean((2, 3), keepdim=True)
x_attn = self.se(x_gap) # nn.Conv2d nn.BatchNorm2d nn.ReLU nn.Conv2d
x_attn = x_attn.view(B, C, self.radix)
x_attn = F.softmax(x_attn, dim=2)
out = (x * x_attn.reshape((B, C, self.radix, 1, 1))).sum(dim=2)
# ===================================
# Fusion
# ===================================
return out.contiguous()
CoXtLayer:代替resnetxt中的3×3分组卷积
def forward(self, x):
batch_size, channels, height, width = x.size()
# ===================================
# k1 static contextual information
# ===================================
k = self.key_embed(x)
# ===================================
# k1 static contextual information
# ===================================
# ===================================
# A contextualized attention matrix
# ===================================
qk = torch.cat([x.unsqueeze(2), k.unsqueeze(2)], dim=2)
qk = qk.view(batch_size, -1, height, width)
w = self.embed(qk)
w = w.view(batch_size * self.dw_group, 1, -1, self.kernel_size*self.kernel_size, height, width) # 分组
# ===================================
# A contextualized attention matrix
# ===================================
# ===================================
# k2 dynamic contextual representation of inputs
# ===================================
x = self.conv1x1(x)
x = x.view(batch_size * self.dw_group, -1, height, width) # 分组
x = self.local_conv(x, w)
x = x.view(batch_size, -1, height, width) # 分组
x = self.bn(x)
x = self.act(x)
# ===================================
# k2 dynamic contextual representation of inputs
# ===================================
# ===================================
# Fusion
# ===================================
B, C, H, W = x.shape
x = x.view(B, C, 1, H, W)
k = k.view(B, C, 1, H, W)
x = torch.cat([x, k], dim=2)
x_gap = x.sum(dim=2)
x_gap = x_gap.mean((2, 3), keepdim=True)
x_attn = self.se(x_gap)
x_attn = x_attn.view(B, C, self.radix)
x_attn = F.softmax(x_attn, dim=2)
out = (x * x_attn.reshape((B, C, self.radix, 1, 1))).sum(dim=2)
# ===================================
# Fusion
# ===================================
2.实验
CoT block各部分的重要性

using only static context
using only dynamic context
linearly fusing static and dynamic contexts
CoT block
二、Contextual Transformer Networks
ResNet: 用CoTBlock代替resnet中的 3×3卷积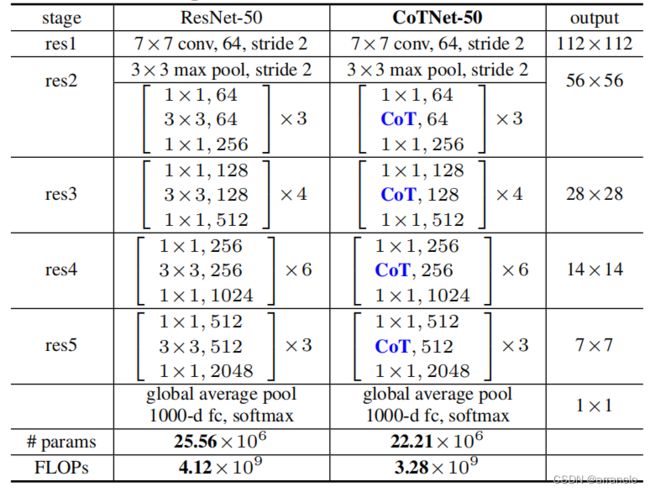
ResNetXt: 用CoTBlock代替resnetxt中的3×3分组卷积,为了使两者的参数和运算量保持一致,将 CoTNeXt-50的输入特征图大小从32×4d减小到了2×48d
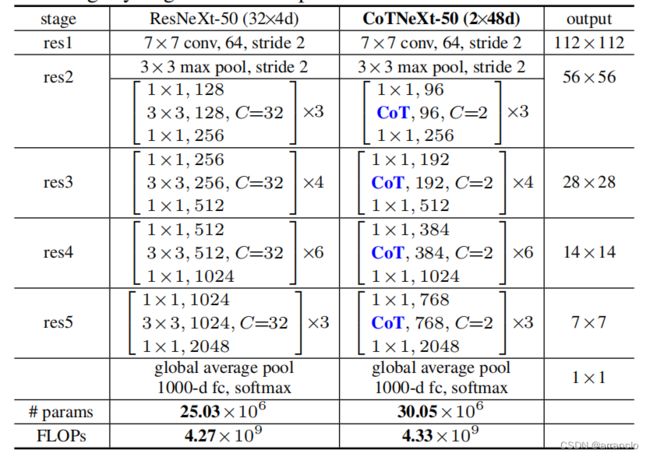
1.代码
Bottleneck:
def forward(self, x):
residual = x
x = self.conv1(x) # nn.Conv2d
x = self.bn1(x) # nn.BatchNorm2d
if self.drop_block is not None:
x = self.drop_block(x)
x = self.act1(x) # nn.ReLU
if self.avd is not None:
x = self.avd(x) # nn.AvgPool2d
x = self.conv2(x) # CotLayer
#x = self.bn2(x)
#if self.drop_block is not None:
# x = self.drop_block(x)
#x = self.act2(x)
#if self.aa is not None:
# x = self.aa(x)
x = self.conv3(x) # nn.Conv2d
x = self.bn3(x) # nn.BatchNorm2d
if self.drop_block is not None:
x = self.drop_block(x)
if self.se is not None:
x = self.se(x) # create_attn
if self.drop_path is not None:
x = self.drop_path(x)
if self.downsample is not None:
residual = self.downsample(residual)
x += residual
x = self.act3(x) # nn.ReLU
return x
2.实验
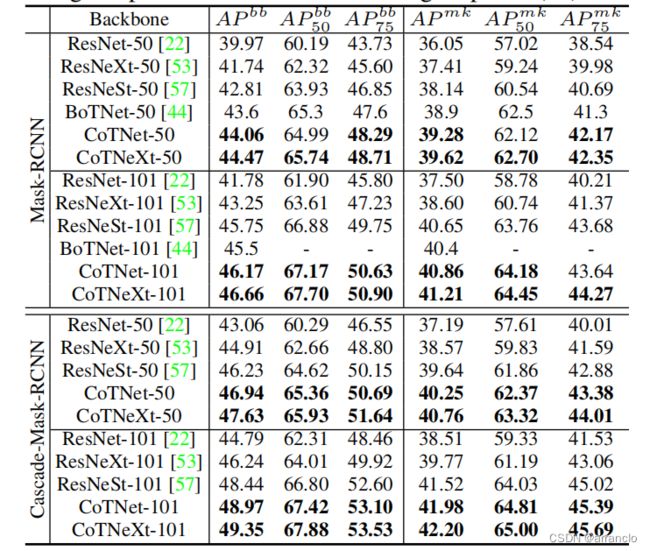
CotTNet及CotTNetXt与其他模型在实例分割上的准确度比较