[PVT] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolution
paper: https://arxiv.org/abs/2102.12122
code: https://github.com/whai362/PVT/
文章目录
- 1. Motivation
- 2. Contribution
- 3. Method
-
- 3.1 Overall Architecture
- 3.2 Feature Pyramid for Transformer
- 3.3 Spatial-Reduction Attention
- 3.3 Detailed settings of PVT series
- 4. Experiments
-
- 4.1 Image Classification
- 4.2 Object Detection
- 4.3 Semantic Detection
- 4.4 Instance Segmentation
- 4.5 Pure Transformer Dense Prediction
-
- 4.5.1 PVT+ DETR
- 4.5.2 PVT+Trans2Seg
- 4.6 Ablation Experiments
- 4.6.1 Pre-trained Weights
- 4.6.2 Deeper vs. Wider
- 4.6.3 Computation Cost
- 5. Codes
-
- 5.1 PatchEmbed
- 5.2 Attention (SRA)
- 5.3 model
1. Motivation
- 作者想实现一个纯净的,无卷积操作的transformer backbone,用于稠密任务。
As far as we know, exploring a clean and convolution-free Transformer backbone to address dense prediction tasks in computer vision is rarely studied.
- VIT的局限性,输入的特征图的分辨率较低,并且stride只能是16或者32,计算和内存开销都很大。
As far as we know, exploring a clean and convolution-free Transformer backbone to address dense prediction tasks in computer vision is rarely studied.
- (1) its output feature map has only a single scale with low resolution
- (2) its computations and memory cost are relatively high even for common input image size
图1为CNN网络,VIT网络以及作者提出的PVT,3种backbone的对比。
2. Contribution
- 本文提出了PVY金字塔视觉transformer,作为多种像素级别的任务的backbone,并且是不需要卷积的。
We propose Pyramid Vision Transformer (PVT), which is the first backbone designed for various pixel-level dense prediction tasks without convolutions. Combining PVT and DETR, we can build an end-to-end object detection system without convolutions and hand-crafted components such as dense anchors and non-maximum(NMS).
- PVT中实现了渐进收缩金字塔progressive shrinking pyramid以及 空间维度降维attention(SRA),提出的新结构可以用来减少资源的消耗,使得PVT对学习多尺度以及高分辨率的featmap更加的灵活,从而来实现dense predictions(典型工作就是检测和分割)。
We overcome many difficulties when porting Transformer to dense pixel-level predictions, by designing progressive shrinking pyramid and spatial-reduction attention (SRA), which are able to reduce the resource consumption of using Transformer, making PVT flexible to learn multi-scale and high-resolution feature maps.
- PVT可以应用于图像分类,目标检测,语义分割,实例分割等等。
We verify PVT by applying it to many different tasks, e.g., image classification, object detection, and semantic segmentation.
3. Method
3.1 Overall Architecture
3.2 Feature Pyramid for Transformer
首先对于 H × W × 3 H \times W \times 3 H×W×3,首先根据patch size=4,分为16个patch,为了不改变图像带下,就将图像变为 H i − 1 P i × H i − 1 P i × ( P i 2 C i − 1 ) = H i − 1 4 × H i − 1 4 × ( 4 × 4 × 3 ) \frac{H_{i-1}}{P_i}\times \frac{H_{i-1}}{P_i} \times (P_i^2C_{i-1})=\frac{H_{i-1}}{4}\times \frac{H_{i-1}}{4} \times (4\times 4 \times 3) PiHi−1×PiHi−1×(Pi2Ci−1)=4Hi−1×4Hi−1×(4×4×3),然后通过linear以及norm完成Patch Embedding操作,得到当前stage的 C i C_i Ci,最后得到的featmap 和PE结合,送入SRA中。
但通过代码阅读后发现,linear实质上是直接通过卷积操作:input channel = 3,output channel = Ci,kernel大小为patch size的卷积核来实现的,相当于将原图 H × W H \times W H×W通过卷积缩放为 H i − 1 P i × H i − 1 P i \frac{H_{i-1}}{P_i}\times \frac{H_{i-1}}{P_i} PiHi−1×PiHi−1,然后通过卷积核的数量将通道变成 C i C_i Ci。从而可以得到 H i − 1 P i × H i − 1 P i × C i \frac{H_{i-1}}{P_i}\times \frac{H_{i-1}}{P_i} \times C_i PiHi−1×PiHi−1×Ci,对于stage1来说是 C i = 64 C_i=64 Ci=64,从而在进入SRA中加入PE(绝对位置编码实现)。
3.3 Spatial-Reduction Attention
SRA相比较于普通的Scale-Product Attention,将K,V的空间维度进行了缩小,变成了 H i W i / R i 2 × C i H_iW_i / R^2_i \times C_i HiWi/Ri2×Ci的大小,R为缩放因子(在5.2 SRA实现中用sr_ratio表示)这样子输出还是和Q的维度一致。
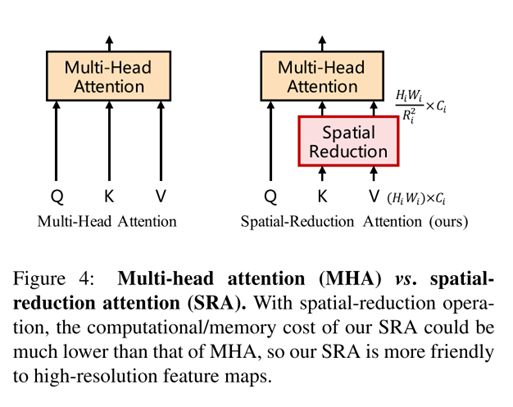
SRA的公式1,2与原multi-head attention基本类似,只是加入了 S R ( x ) SR(x) SR(x)的reshape操作,如公式3所示。
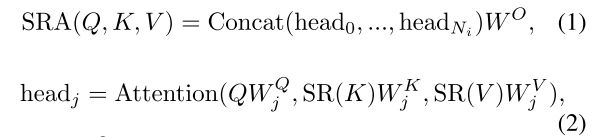
3.3 Detailed settings of PVT series
需要注意的是 C = [ C 1 , C 2 , C 3 , C 4 ] = [ 64 , 128 , 320 , 512 ] C = [C_1, C_2, C_3, C_4] = [64, 128, 320, 512] C=[C1,C2,C3,C4]=[64,128,320,512]以及 P = [ P 1 , P 2 , P 3 , P 4 ] = [ 4 , 2 , 2 , 2 ] P=[P_1, P_2, P_3, P_4] = [4, 2, 2, 2] P=[P1,P2,P3,P4]=[4,2,2,2],每一个stage的featmap和原图之间的缩放倍数 [ 4 , 8 , 16 , 32 ] [4,8,16,32] [4,8,16,32],以及每一个stage中的encode含有多少个nhead,每一个stage中含有多少个encoder,从而分为了Tiny,Small,Medium,Large。
4. Experiments
4.1 Image Classification
4.2 Object Detection
4.3 Semantic Detection
![[PVT] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolution_第1张图片](http://img.e-com-net.com/image/info8/cea1dfedd3f84e56ae280956598a19c1.jpg)
4.4 Instance Segmentation
4.5 Pure Transformer Dense Prediction
4.5.1 PVT+ DETR
4.5.2 PVT+Trans2Seg

4.6 Ablation Experiments
4.6.1 Pre-trained Weights
4.6.2 Deeper vs. Wider
4.6.3 Computation Cost
5. Codes
5.1 PatchEmbed
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, =4, in_chans=3, embed_dim=64):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
5.2 Attention (SRA)
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# sra
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
5.3 model
@register_model
def pvt_tiny(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model