细粒度 文档图像版面分析
基于实例分割网络的细粒度文档图像版面分析
英文引用:Zhao P, Wang W, Cai Z, et al. Accurate Fine-Grained Layout Analysis for the Historical Tibetan Document Based on the Instance Segmentation[J]. IEEE Access, 2021, 9: 154435-154447.
中文引用:赵鹏海. 乌金体藏文文档版面分析与识别系统[D].西北民族大学,2022.DOI:10.27408/d.cnki.gxmzc.2022.000367.
摘要
版面分析是文档信息理解的重要步骤,是对文档图像内的文字、图片等区域进行自动分析和理解的过程。通过版面分析,可以完成对图片中待识别区域的定位与分割,丛而为后续的识别打下基础。大多数版面分析方法其分割粒度较大,所得到的区域仍需进一步切分才可为识别所用,而现有的细粒度的版面分析方法在文本行复杂交错的藏文古籍文档图像表现较差。为了得到准确的版面分析结果,我们提出了一种细粒度的版面分析方法。首先,使用传统的行切分算法并辅以人工矫正,快速生成了所需的标注文件。其次,使用标注数据训练SOLOv2,使得网络完成拟合。最后,使用该网络进行推理,得到输入图像中的文本行与左右标题区域。实验结果表明,我们使用的方法可以较为准确地完成对藏文古籍文档图像的版面分析,AP50值最高可达93.6%。总的来说,本文证明了SOLO系列网络在藏文古籍文档图像版面分析任务中的有效性,我们也认为该网络对其它类型的文档的版面分析也会是准确高效的。
引言
版面分析(DLA)是DAR中的一个重要组成部分,其目的是定位待识别文字区域,为后续的识别的前提。待识别区域可以是文本块图像,文本行图像,也可以是一幅插图,即图像理解的主要研究对象。大多数现有的版面分析相关研究方法是基于语义分割网络的,这些网络不能区分实例个体且往往分割粒度较大,所获得的文本块区域仍然需要进一步切分才能用于识别,这将导致系统模块耦合度较高,阻碍了系统准确率的进一步提升。

近些年也有一些学者以行粒度进行端到端的版面分析,从而省去了行切分这一步骤。这些方法大多基于实例分割网络,比如著名的Mask R-CNN。该网络可以直接将页面中不同的文本行进行分割、提取,从而得到不同的文本行实例,其在大多数数据集上有着出色的性能表现。
然而大多数实例分割网络难以处理文本行交错复杂的藏文古籍文档图像。图2中展示了一例典型的藏文古籍文档图像,从图中可以看出,该例藏文古籍文档图像中文本行间距较小、文字上下紧密排列、交叠现象甚至行间粘连。同时,句子之间的距离长短不一,在文本行中产生了大量的空白。此外,图像中还存在光照不均、污渍、破损等问题,这进一步增加版面分析的难度。除了上述这些问题,我们还缺少适当粒度的藏文古籍文档图像版面分析数据集,而构建一套高质量的版面分析数据集也充满挑战。

动机
我们参考了Prusty A等人利用Mask R-CNN网络对印文历史文档图像进行版面分析的方法[19],并尝试将该方法使用在藏文古籍文档图像上。如图3(a)左侧一列所示,我们使用Labelme[23]工具以粗粒度标注了10张图片,并将这些数据送入Mask R-CNN网络不断训练以试图测试出该网络在我们数据集上的极限效果(尽管可能发生过拟合)。实验结果如图3(b)左侧一列所示,实验结果如同Prusty A的实验结果一样出现了文本行两端丢失的情况。我们认为这可能是由于Mask R-CNN的Mask分支的输出尺寸(ground truth region masks)过小,而这导致了图像中大量信息的丢失。因此,我们将该输出的尺寸通过额外的两个转置卷积层放大了两倍,改进的实验结果如图3(c)左侧一列所示。可以看到,两端漏字的现象得到了很好的改善。

然而,由于藏文古籍文档图像大多存在文本行粘连、排列紧密等问题,以粗粒度标注的数据对应的文本行分割结果较差。因此,我们认为细粒度可能会改善字符边缘的分割准确度,并以细粒度标注了5张图片,标注区域的边缘紧贴字符的边缘,如图3右侧一列。并使网络在这些数据上不断训练。图3右侧一列b c展示了网络在训练集上的实验结果,令人惊讶的是以细粒度数据训练的网络的最终结果反而更为糟糕,很大一部分的文本行都没有被网络准确地分割出来。
我们推测,若能继续放大Mask分支的输出尺寸,分割准确度会继续提升。但由于显卡内存的限制,无法再次放大Mask的尺寸来试图提升结果了。因此我们希望使用一种Mask Head尺寸不受限的实例分割网络对文本行交错复杂的藏文古籍文档图像进行准确的细粒度版面分析。王鑫龙等人通过对MS COCO数据集的调查,发现绝大部分实例的根本区别在于它们有着不同的中心坐标与大小,并根据这个思想提出了两种优秀的(promising)实例分割网络SOLO[24]与其改进版SOLOv2[7]。与Mask R-CNN不同,这些网络没有限制Mask的尺寸,因此在物体边缘上的分割细节更为出色。
网络模型及代码
SOLOv2代码如下:
Github:WXinlong/SOLO
数据集构建代码如下:
Github:ssocean/Fine-Grained-Label-Builder
准确、动态、高效的数据集构建方法
由于人工标注面临种种困难,我们提出了一种半自动标注方案:
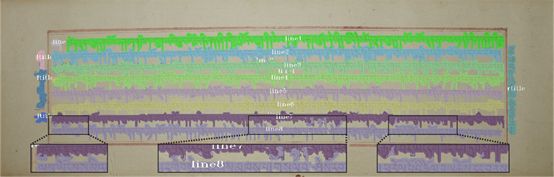
(1)取得文本行灰度图。首先使用行切分算法得到单独的文本行,这里我们使用的是王轶群等人提出的文本行切分算法[16],并得到红蓝相间的文本行渲染图。然后借助于Adobe Photoshop等软件,人工地将左右标题区域切分出来,并擦除其中的假阴性(False Negative)像素点,得到标题图。最后将文本行渲染图与标题图合并,指定第i行像素值全部为20*i, i∈[1,8],左右标题像素值分别设置为180与200,得到有着不同像素值文本行与标题的灰度结果图(见图7)。
(2)确定待识别区域轮廓。在灰度结果图上依据不同的像素值提取得到不同的待处理区域,并对这些区域依次进行形态学腐蚀与膨胀操作。第一步,将灰度图像统一缩放至1504×1504大小并进行一次形态学开操作以消除噪点等细小物体。第二步,迭代膨胀p次并随后腐蚀q次(要求p>=q),得到一个或多个边界扩张(p-q)个像素个数的连通域。这样可以尽可能地减少连通域的个数,但同时避免扩张过大引起粘连并对结果产生影响。图8展示了不同边界类型的GT。膨胀与腐蚀操作所使用的结构元素(Structuring Element)均为3×3的矩形元素。我们使用了Suzuki等人的算法[30]对所有连通域依次进行计算,得到这些区域的最外层轮廓,并通过引用[31]的方法,对轮廓上的像素点进行了精简以试图减少标注文件的大小与缩短数据加载时间。如下为寻找轮廓的算法1伪代码。
(3)依据连通域轮廓生成标注文件。将连通域类别与轮廓点(continuous points)坐标及其它图片信息写入labelme格式的JSON文件,并借助labelme2coco工具将其转换为COCO格式的JSON文件。从上到下文本行的标注类别依次为line1,line2,…,line8,左右标题的标注类别分别是ltitle与rtitle。若一条文本行中包含多个连通域(由于句子间距较大),那么这些连通域的group_id属性则会从1开始设置为不同的值。
尽管通过加入模拟污渍、模拟光照不均、扭曲倾斜等效果可能会进一步增强方法的鲁棒性,但我们没有对数据进行任何形式的增广。
实验结果及评价
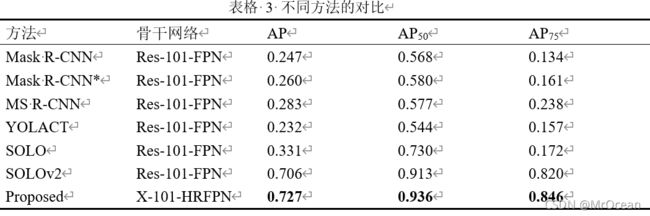
我们使用了不同的实例分割网络在数据集上进行了实验,包括Mask R-CNN,改进的Mask R-CNN*(增加两层反卷积层以扩大Mask尺寸)、Mask Scoring R-CNN[36]、YOLACT[37]、SOLO[24]、SOLOv2[7]以及我们所提出的网络。所有神经网络的训练与推理细节都尽可能地保持一致,batch size设置为1,输入图像的尺寸设置为2496×800、边界类型为10-4。表格3展示了不同方法的量化结果,Res-101-FPN代表由101层的ResNet与FPN构成的骨干网络,X-101-HRFPN代表骨干网络为ResNeXt与HRFPN。从表3可以看出Mask R-CNN、YOLACT等Mask Head受限的方法的指标明显低于Mask Head不受限的SOLOv2网络。这些网络的版面分析结果类似于图3所展示的样例结果,结果中有大量错误切分的情况。而SOLOv2网络分割结果较为准确、相应的评价指标也更高。我们提出的以ResNeXt与HRFPN为骨干网络的改进版SOLOv2,在所有的评价指标中均有提升,达到了最高指标。