016基于STFT和域自适应的脑电癫痫预测-2021
Seizure Prediction in EEG Signals Using STFT and Domain Adaptation
癫痫发作预测是耐药性癫痫最常用的辅助治疗策略之一。由于个体间的可变性,传统方法通常从同一患者收集训练和测试样本。然而,具有挑战性的问题领域之间的转换,各种科目仍然没有解决,导致低转化率的临床。本文提出了一种基于领域适应的模型来解决这个问题。利用短时傅里叶变换(STFT)从原始脑电信号中提取特征,并开发自动编码器将这些特征映射到高维空间。该模型通过最小化嵌入空间中的域间距离来学习域不变信息,从而通过分布对齐来提高泛化能力。
此外,为了增加其应用的可行性,这项工作模拟了临床抽样情况下的数据分布,并在这种情况下测试模型,这是第一次采用评估策略的研究。在颅内和头皮脑电数据库上的实验结果表明,与以前的方法相比,该方法能有效地减小域间隙。
3.方法
为了减少个体差异的影响,我们提出了一个通用的癫痫发作预测模型。我们方法的核心思想是在高维空间中最小化不同主题之间的领域距离。使得在域分布对齐期间可以提取域不变特征。最大平均差异(MMD)度量(张等人,2020)被选为距离度量,并且高维空间由对立自动编码器(AAE)建立(马克扎尼等人,2015)
3.1. Clinical Situation Simulation临床情境模拟
常规研究的训练集与现实生活中的采样情况不一致。在临床治疗过程中,几乎不可能长时间记录特定患者的大量脑电样本。因此,传统的特定于患者的学习策略无法执行,因为数据大小无法支持训练。为了解决这个问题,我们提出了一种新的预测器,可以使用其他患者的数据进行训练。
为了模拟临床中的采样情况,我们采用了一种特殊的训练和测试策略,如图3所示。具体来说,训练和验证集包括以前的患者数据和来自“目标”受试者的一次发作,而“目标”受试者的其余发作用作测试集。该策略参考了留一交叉验证法的思想(彭等,2018)。此外,训练和验证集被分成5个部分,80%的数据被分配给训练集,而剩余的20%被分配给验证集,以防止过度拟合。
3.2. Modal Transformation With STFT STFT模式转换
由于脑电信号的低信噪比,我们试图将输入信息从时域转换到时频域。两种预处理技术,小波和傅立叶变换(Muralidharan等人,2011;赵等人,2019),通常用于将EEG片段转换为图像形状。这里,我们采用短时傅立叶变换(STFT)从原始脑电序列产生特征图。这种转换将脑电时间序列转换成矩阵,可以满足二维MMD-AAE的输入要求。该程序还可以提取用于癫痫发作预测的重要特征。
3.3. Construction of High-Dimensional Space 高维空间的构建
这个模块试图用编码器和解码器建立一个高维空间。该模型如图4所示。通过使用编码器,我们可以将原始EEG样本的时频图像映射到嵌入子空间中。通过使用解码器,这些隐藏层被映射回一个“假”输入矩阵。隐藏空间是高维的,因此包含更多的信息。然后,利用MMD度量来对齐不同域之间的高维特征向量的分布。因此,优化的隐藏代码包含各种患者的可共享信息。
然后,我们提取这些潜在的特征,这些特征在病人中是普遍的,用于分类。在嵌入空间的构造过程中有两个步骤:重构过程和分布对齐过程。在重建过程中,自动编码器试图从高维向量中恢复时频图像。自动编码器的架构参考的架构(李等,2018)。我们设置优化目标Lrec,以引导生成的特征图\u x匹配输入图x。重建过程Lrec的损失函数定义为:

现在,我们指定域间距离度量的形式。最大平均差异(MMD)测量(贾等人,2017年)用于对齐不同域的分布。与重建过程一样,我们也给出了一个基于的正则化项来优化神经网络中的超参数(李等,2018)。假设Z = [z(1),,z(K)]T ∈ RK×l表示K个域的已学习高维特征,其中z ∈ Rl×1。对于两个任意隐藏向量z(i)和z(j ),我们假设它们分别属于两个看不见的概率分布P(i)和P(j)。通过采用核嵌入技术(Smola等人,2007年),该实例被映射到再生核希尔伯特空间(RKHS)h。RKHS中相应的平均值被给出为:
![]()
其中μ(·)是平均映射运算。h(z,·)是由h中的特征映射导出的核函数。在这项工作中,我们采用遵循模型的RBF核(李等,2018)。潜在代码z(i)和z(j)之间的域间距离可以描述为:

那么,很明显,整个潜在空间的正则化项可以被定义为:
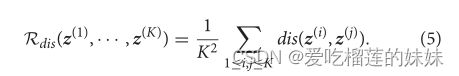
由于上述距离误差,提取的高维特征可以很好地在所有领域中推广,因为神经网络通过对齐它们的分布来学习它们的公共代码。
3.4.使用对抗学习的优化
为了进一步优化3.3节中的学习功能,我们根据AAE (Makhzani等人,2015年)引入了一个基于对抗性学习的模块。对抗学习是近年来出现的一种机器学习方法,已成功应用于癫痫脑电信号处理领域。它通常包含具有参数2G的发生器网络G和具有参数2D的鉴别器网络D。发电机网络G将产生一些输入的假版本。这些虚假数据与真实输入数据一起被发送到鉴别器网络D。那么鉴别器网络D将辨别输入样本是否是人工生成的。在训练过程中,神经网络在生成器和鉴别器之间找到一个纳什均衡,虚假数据逐渐接近真实数据。这个“零和游戏”可以描述为:

其中xr和pr是真实数据和对应的分布,xf和pf是假版本。在利用损失Jgan进行优化之后,敌对子网可以将pf与恒定的先验pr对齐。
我们希望在嵌入空间中利用上述原理。因此,我们假设不同患者之间的“真实”普遍特征来自任意的先验分布p (z)。对抗模块从先验分布p (z)中抽取样本,并将这些样本视为真实数据zr。因此,学习的潜在信息z被认为是假数据zf,其中自动编码器表示生成器g。鉴别器D也被实现在对抗模块中,其将产生的向量z与先前的样本进行区分。在本研究中,选择先验分布作为拉普拉斯分布z∞拉普拉斯(η),其中η表示超参数。
对抗模块的训练策略是一个变分推理过程。具体来说,首先,潜在编码空间已经由编码器明确建立。然后用MMD正则化项匹配不同域之间的分布,提取域不变特征向量。这些特征被引导接近先验分布p (z)。将隐藏代码与任意分布进行匹配,可以有效地缓解对某个病人的过拟合。在优化过程之后,隐藏层的聚集后验分布q (z)如下:

其中q (z | x)是自动编码器的编码函数,pd (x)是数据的边际分布。在训练阶段,概率自动编码器用对抗性损失函数Jadv来正则化,该函数被描述为:
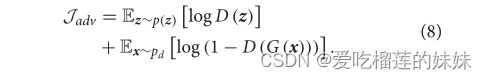
在训练之后,通过在数据分布上施加先验p (z)来定义生成模型。独热编码向量y用于监督学习(Kumar等人,2018;Saito等人,2020年)。然后,我们使用学习到的领域不变特征进行癫痫发作预测。引入SVM分类器来分析提取的特征。分类过程的损失函数由Lcla表示。整个模型的目标函数可以定义为:

其中λ0,λ1,λ2代表权衡正参数,C是分类器。我们的模型与这些模块一起被优化。一般来说,基于MMD的正则化项被设计成对准不同患者之间的分布。AAE建筑被用来构建潜在的特征空间。对抗模块被开发来将隐藏代码与先验分布相匹配。因此,该模型可以避免对某个患者的过度拟合。
4. RESUL TS AND DISCUSSION
在这一部分中,通过对比实验来验证泛化能力和评估预测精度。我们的模型在颅内和头皮EEG信号上进行了测试。在实验中利用了关于模型性能的三个常用指标:灵敏度、每小时虚警率(FPR)和受试者操作特征曲线下面积(AUC)。注意,每个脑电图片段代表一个事件,因此基于事件的指标用于评估(Temko等人,2011)。
4.1. Comparison With Conventional Methods与传统方法的比较
为了证明相对于传统方法的优势,我们选择了四项癫痫发作预测研究进行比较:FTCNN (Truong等人,2018年)、锁相值(PLV) (Cho等人,2016年)、光谱带功率(SBP) (Ozcan和Erturk,2019年)和Wav-CNN (Khan等人,2017年)。当训练和测试过程在同一主题上进行时,所有这些方法都获得了良好的模型性能。但是以前案例中的数据并不用于他们的训练阶段。在这里,我们用来自多个患者的脑电图样本训练这些模型,并用“看不见的”患者的数据测试它们。表3和表4提供了灵敏度和FPR。每个患者的AUC值如图5所示。
颅内脑电

CHB-MIT

广泛使用的弗莱堡医院数据库被用来评估我们的颅内脑电图模型。表3表明,我们的模型明显优于所有其他传统方法。这是合理的,因为以前的研究采用了病人特定的策略,很少考虑领域适应性。相反,我们的方法在泛化能力方面表现出明显的优势,实现了76%的灵敏度和0.19/h的平均FPR。
虽然这些结果没有达到在患者特定条件下测试的高精度,但这样的精度仍然可以满足癫痫患者的日常需求,因为它们类似于第一个人试验中的警告频率(Cook等人,2013)。
尽管如此,模拟的临床采样情况对于预测任务来说是“苛刻的”。可以观察到,所有这些模型的性能都不理想。此外,在像Pt 5、11和21这样的几个异常值上,性能下降尤其明显。这可能是由高维空间中更复杂的内部模式引起的。注意,即使在这些异常值上,我们的模型的灵敏度也略高于其他方法,这表明我们的方法实现了更好的鲁棒性。
至于头皮脑电图记录,我们使用麻省理工学院制作的公共CHB-MIT数据库来测试这些方法。如表4所示,我们的算法实现了73%的灵敏度和0.24/h的平均FPR。与传统方法相比,我们的模型的结果显示了显著的改善,这与颅内脑电图的结果一致。然而,与Freiburg测试集上的精度相比,所有模型的性能都有不同程度的下降。这可能是由于头皮EEG信号的低空间分辨率造成的,因为它们更容易被噪声污染(Ramantani等人,2016;乌斯曼等人,2019)。换句话说,颅内EEG记录具有更高的SNR,并且伪迹通常在头皮EEG中看到。
在对头皮EEG信号的测试中也存在一些异常值。在Pt 2、13和21上,所有这些模型都获得了低于标准的性能。在这些离群点的样本空间中可能存在较大的域间隙,这使得超平面难以捕捉。即使在这些异常值上,我们模型的精度也略高于随机二元分类器的下限。这给了我们将DA技术应用于癫痫发作预测的信心。
4.2. Comparison With DA Methods与DA方法的比较
我们进一步将我们的模型与现有文献中的领域适应(DA)方法进行比较。然而,关于DA方法在癫痫发作预测领域的应用报道很少。因此,我们必须采用其他领域的DA方法。通过引入最大独立领域自适应(MIDA) (Y an等,2017)、的模型不可知语义特征学习(C-DCGANs)(张等,2021)和主题不变领域自适应(SIDA) (Rayatdoost等,2021)来验证模型的优势。表5和表6提供了灵敏度和FPR。每个患者的AUC值如图6所示。



对于颅内脑电图样本,我们仍然利用弗赖堡医院的数据库作为测试集。显然,与其他DA方法相比,我们的模型实现了最好的性能,灵敏度为76%,平均FPR为0.19/h。
那么SIDA方法比其他方法稍有优势。将该模型与SIDA进行比较,我们看到获得了大约7%的收益。将我们的方法与CDCGANs进行比较,我们注意到获得了另外3%的好处。至于MASF,观察到20%的收益,与MIDA相比总共有25%的差额。
在头皮脑电数据方面,实验采用了开放的CHB-MIT数据集。这些DA算法的精度等级与颅内EEG数据的性能一致。与其他方法相比,我们的模型具有明显的优势,其灵敏度为73%,平均FPR为0.24/h。我们的模型在颅内和头皮脑电上的高模型性能证明了在癫痫发作预测上的应用潜力。
显然,除了所提出的方法之外,SIDA实现了最佳性能。这种优势的原因可能归功于CNN和生成性对抗网络(GAN)的结合。SIDA是来自情感识别领域的深度神经网络。原始脑电图数据被转换成脑电图频谱。通过最小化情感识别的损失和主题混淆,SIDA提取不同域之间的不变特征。我们推测,在这项任务中,四达的GAN结构可能具有优势,这需要进一步证明。
与其他模块相比,C-DC gan做出了相对较大的贡献。C-DC gan也采用基于对抗学习的结构。它还使用数据增强技术,人工生成脑电图记录。通过增加数据多样性,CDCGANs希望提高域转换的鲁棒性。然而,人造数据可能涉及更多污染EEG样本的伪像(Fahimi等人,2020)。此外,C-DCGANs是基于深度学习的框架的变体。因此,它具有与DNN相关的不确定性,特别是缺乏正式的融合保证。
毫不奇怪,MASF和MIDA的结果并不令人满意。MASF的核心思想是利用语义特征和基于梯度的元学习建立一个模型不可知的学习范式。然而,高维空间中的判别超平面可能太复杂而无法用语义特征来描述。MIDA通过学习具有背景信息的子空间来减少域分布之间的差异。很明显,特定于背景的特征不是有效的特征。
基于上述观察,我们推测基于对抗学习的技术对于减轻个体可变性相对优越,因为所有基于对抗学习的模型对于癫痫发作预测实现了相当好的模型性能和泛化能力。在颅内和头皮EEG数据集上的实验表明,对立结构在开发通用癫痫预测模型方面具有潜力。
4.3. Impact on Different Components对不同组件的影响(消融实验)
在本节中,我们进行实验来了解所提出模型的不同模块对最终预测结果的影响。为了定量计算每个组成部分的贡献,我们调整相应的权衡正参数,并观察其变化趋势。
实验结果列于表7、8中。这里,我们讨论该模型中的三个组件:具有损失Lrec的重建模块、具有损失Jadv的对抗模块以及域间距离正则化项Rdis。
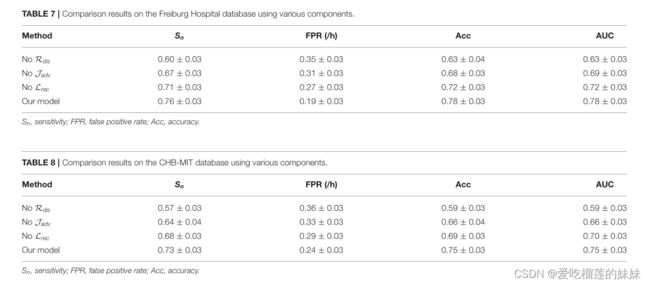
如表7和表8所示,我们观察到,删除域间距离正则化项、敌对子网或分类组件会导致颅内和头皮EEG数据库的性能下降。这样的结果表明,这些模块可以有效地提高模型性能:(1) AAE适用于癫痫脑电信号处理,AAE提出的嵌入空间是有意义的。(2) MMD是一种适当的距离度量,用于最小化癫痫发作预测任务中的域间隙。(3)重建过程可以迫使模型从潜在的高维空间中学习重要特征。
通过调整这些权衡项目,可以获得一组适合癫痫发作预测的超参数。对于颅内脑电数据,最合适的权衡参数设置为λ0 = 1.05,λ1 = 1.2e2,λ2 = 0.7。对于头皮脑电数据,最合适的参数设置为λ0 = 1,λ1 = 1.1e2,λ2 = 0.6。
我们还讨论了MMD度量相对于其他距离度量的优越性。标准化的欧几里德距离和KL-散度用于比较。实验结果如图7所示。结果表明,应用MMD测度后,颅内脑电和头皮脑电的准确率分别提高了3%和4%,证明了MMD测度在癫痫预测任务中的优势。

5. CONCLUSION
这项工作提出了一个通用的癫痫预测器,以减轻个体变异的影响。通过结合STFT和MMD-AAE,我们的模型低降了癫痫区域方差的影响,提高了泛化能力。此外,在训练和测试期间使用了模拟临床抽样场景,这是首次尝试采用该评估策略。与以往研究中针对患者的策略相比,这种检测方法相对具有挑战性。该方法具有较高的域移位鲁棒性和精度,证明了该方法在实际应用中的可行性。
通过分析DA方法的比较结果,对对抗学习在癫痫发作预测中的有效性进行了猜想。这种现象的潜在原因尚不清楚,因为在现有的文献中没有明确的解释癫痫的动态。寻找更强大的DA算法和潜在原因将被视为我们未来研究的一部分。