(.*?) 短评
', re.S) global movie_name movie_name = re.findall(pattern, res.text)[0] # list类型 res.encoding = 'utf-8' if (res.status_code == 200): print("\n第{}页短评爬取成功!".format(page + 1)) print(url) else: print("\n第{}页爬取失败!".format(page + 1)) with open('html.html', 'w', encoding='utf-8') as f: f.write(res.text) f.close() x = etree.HTML(res.text) for i in range(1, 21): # 每页20个评论用户 name = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()'.format(i)) # 下面是个大bug,如果有的人没有评分,但是评论了,那么score解析出来是日期,而日期所在位置spen[3]为空 score = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[2]/@title'.format(i)) date = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[3]/@title'.format(i)) m = '\d{4}-\d{2}-\d{2}' try: match = re.compile(m).match(score[0]) except IndexError: break if match is not None: date = score score = ["null"] else: pass content = x.xpath('//*[@id="comments"]/div[{}]/div[2]/p/span/text()'.format(i)) id = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/@href'.format(i)) for i in tqdm(range(0, pages)): # 豆瓣只开放500条评论 get_content(33404425, 10) # 第一个参数是豆瓣电影对应的id序号,第二个参数是想爬取的评论页数 time.sleep(round(random.uniform(3, 5), 2)) infos = {'name': name_list, 'city': city_list, 'content': content_list, 'score': score_list, 'date': date_list} data = pd.DataFrame(infos, columns=['name', 'city', 'content', 'score', 'date']) data.to_excel("豆瓣影评数据.xlsx")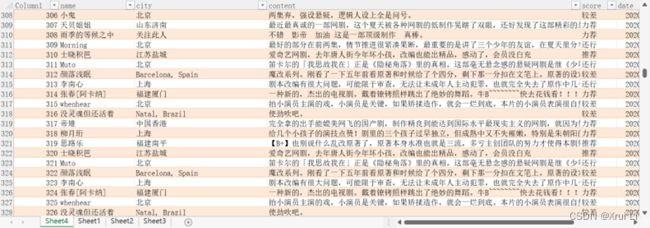
# 爱奇艺弹幕数据获取
# 获取弹幕的xml数据
import zlib
import requests
for x in range(8):
x += 1
#从1到8,第一集总共42分钟,爱奇艺每5分钟会加载新的弹幕,所以取8
#77除以5向上取整
url='https://cmts.iqiyi.com/bullet/75/00/16954467500_300_'+str(x)+'.z'
bulletold = requests.get(url).content #这步取出来的文件是乱码的
bulletnew = bytearray(bulletold)#将上一步的乱码文件用二进制再编码下
xml = zlib.decompress(bulletnew, 15+32).decode('utf-8')
#把编码好的文件备份保存,方便后边取数据
with open('C:/Users/Yearn/Desktop/iqiyi'+str(x)+'.xml','a+',encoding='utf-8') as f:
f.write(xml)
f.close()
# 对xml数据进行解析,获取用户的ID、弹幕内容、点赞数
from xml.dom.minidom import parse
import xml.dom.minidom
for x in range(8):
x+=1
DOMTree = xml.dom.minidom.parse(r"C:/Users/Yearn/Desktop/iqiyi"+str(x)+".xml")
collection = DOMTree.documentElement
# 在集合中获取所有entry数据
entrys = collection.getElementsByTagName("entry")
for entry in entrys:
content = entry.getElementsByTagName('content')[0]
rescontent.append(content.childNodes[0].data)
ID = entry.getElementsByTagName('name')[0]
resID.append(ID.childNodes[0].data)
like_count =entry.getElementsByTagName('likeCount')[0]
rescount.append(like_count.childNodes[0].data)
data1={
'ID':resID,'count1':rescount,'contents':rescontent
}
data1=DataFrame(data1)
data1.to_excel('C:/Users/Yearn/Desktop/爱奇艺弹幕数据.xlsx')

2.3 文本清洗(去停用词)
由于爬取到的影评数据存在许多无意义或重复的数据,为提高后面分析的准确性,需进行停用词处理,这里采用jieba库进行分词,并使用北京大学停用词词典对分词后的文本进行过滤。
import jieba
iqiyi_data = pd.read_excel('爱奇艺弹幕数据.xlsx')
iqiyi_content = iqiyi_data['contents'].tolist()
iqiyi_corpus = [jieba.cut(str(i), cut_all = False) for i in iqiyi_content] # 精确匹配模式
douban_data = pd.read_excel('豆瓣影评数据.xlsx')
douban_content = douban_data['contents'].tolist()
douban_corpus = [jieba.cut(str(i), cut_all = False) for i in douban_content]
# 读取停用词
with open('停用词.txt', mode='r') as f:
stopwords = [i.strip() for i in f.readlines()]
# 去停用词
douban_corpus_s = [i for i in douban_corpus if i not in stopwords]
iqiyi_corpus_s = [i for i in iqiyi_corpus if i not in stopwords]
三、描述性分析
3.1 豆瓣评分分布
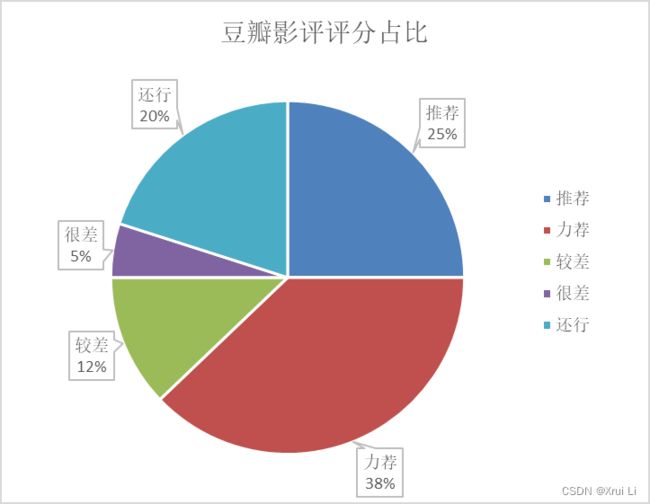
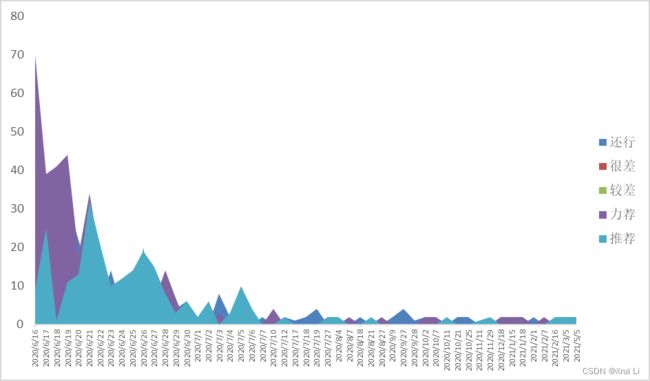
从饼状图中可发现隐秘的角落自播出以来,整体上好评(力荐+推荐)是要多余差评(较差+还行)的,而从面积图来看,可以看到自播出以来基本上每天的好评也是多于差评。因此,可以判断《隐秘的角落》整体口碑良好。
3.2 豆瓣影评词频分析


基于wordcloud库对影评关键词实现了可视化。我可以发现观众讨论最多的是张东升饰演者秦昊,其次热度第二高的角色是朱朝阳。评论出现高频词关键词有“故事”、“人物”、“剧情”、“节奏”、“原著”、“结局”、“细节”等,这也符合《隐秘的角落》一部悬疑剧情电视剧的市场定位,由于其改编自紫金陈的推理小说《坏小孩》,自然容易引起观众们把原著与改编电视剧拿来讨论与比较的情况。例如,“这部剧改编是否尊重原著”、“电视导演对剧情发展节奏的把握”等等。
3.3 豆瓣影评城市分布
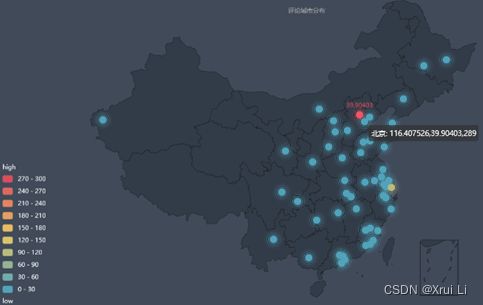
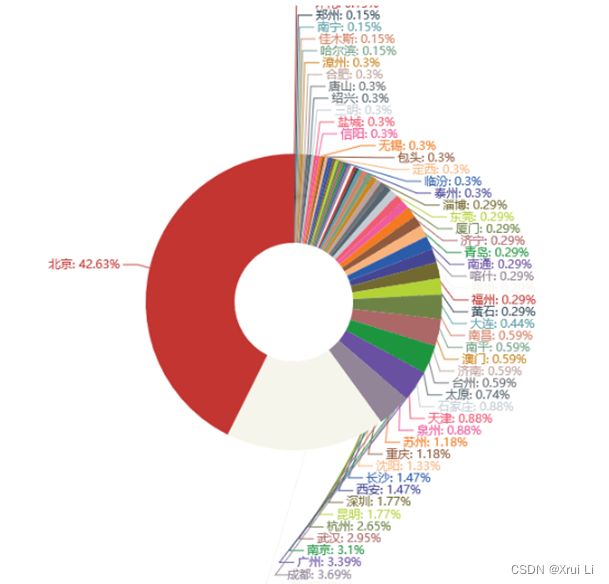
从图中可以看到评论最多的是北京与上海这两个城市,分别占了了本次数据的42%和17%,说明《隐秘的角落》在这两个城市的播放表现更好,热度更高。
3.4 豆瓣影评LDA主题分析
import pandas as pd
import numpy as np
import re
from snownlp import SnowNLP
import jieba
from gensim import corpora,models
data = pd.read_excel('ymjl_data.xlsx')
# print(type(data))
# 重复值处理
data_null = data.drop_duplicates()
print(data_null)
data_null_comments = data_null['contents']
print(len(data_null_comments))
# 过滤短句
data_len = data_null_comments[data_null_comments.str.len()>4]
print(data_len)
data_len.to_csv('contents.txt',index=False,encoding='utf-8')
# 情感分析
data = pd.read_csv('contents.txt',encoding='utf-8',header=None)
print(data)
# print(type(data))
coms = []
coms = data[0].apply(lambda x:SnowNLP(x).sentiments)
data_post = data[coms>=0.5]
data_neg = data[coms<0.5]
print(data_post)
print(data_neg)
data_post.to_csv('comments_正面情感结果.txt',encoding='utf-8',header=None)
data_neg.to_csv('comments_负面情感结果.txt',encoding='utf-8-sig',header=None)
# 去除无用符号
with open('comments_正面情感结果.txt',encoding='utf-8') as fn1:
string_data1 = fn1.read() # 使用read方法读取整段文本
pattern = re.compile(u'\t|\n|\.|-|——|:|!|、|,|,|。|;|\)|\(|\?|"') # 建立正则表达式匹配模式
string_data1 = re.sub(pattern, '', string_data1) # 将符合模式的字符串替换掉
print(string_data1)
fp = open('comments_post.txt','a',encoding='utf8')
fp.write(string_data1 + '\n')
fp.close()
with open('comments_负面情感结果.txt',encoding='utf-8') as fn2:
string_data2 = fn2.read()
pattern = re.compile(u'\t|\n|\.|-|——|:|!|、|,|,|。|;|\)|\(|\?|"') # 建立正则表达式匹配模式
string_data2 = re.sub(pattern, '', string_data2) # 将符合模式的字符串替换掉
print(string_data2)
fp = open('comments_neg.txt','a',encoding='utf8')
fp.write(string_data2 + '\n')
fp.close()
# 分词
data1 = pd.read_csv('comments_post.txt',encoding='utf-8',header=None)
data2 = pd.read_csv('comments_neg.txt',encoding='utf-8',header=None)
# 向jieba词库中添加新词
name_list = ['朱朝阳','国产剧']
for k in name_list:
jieba.add_word(k)
mycut = lambda x: ' '.join(jieba.cut(x)) # 自定义简单分词函数
data1 = data1[0].apply(mycut)
data2 = data2[0].apply(mycut)
data1.to_csv('comments_post_cut.txt',index=False,header=False,encoding='utf-8')
data2.to_csv('comments_neg_cut.txt',index=False,header=False,encoding='utf-8')
print(data2)
# LDA主题分析(基于概率)
post = pd.read_csv('comments_post_cut.txt',encoding='utf-8',header=None,error_bad_lines=False)
neg = pd.read_csv('comments_neg_cut.txt',encoding='utf-8',header=None,error_bad_lines=False)
stop = pd.read_csv('stoplist.txt',encoding='utf-8',header=None,sep='tipdm',engine='python')
stop = [' ',''] + list(stop[0]) # 添加空格
post[1] = post[0].apply(lambda s: s.split(' '))
post[2] = post[1].apply(lambda x: [i for i in x if i not in stop])
neg[1] = neg[0].apply(lambda s: s.split(' '))
neg[2] = neg[1].apply(lambda x: [i for i in x if i not in stop])
# 正面主题分析
post_dict = corpora.Dictionary(post[2]) # 建立词典
post_corpus = [post_dict.doc2bow(i) for i in post[2]]
# 每个主题输出5个
post_lda = models.LdaModel(post_corpus, num_topics=5, id2word=post_dict) # LDA模型训练
for i in range(3):
print(post_lda.print_topic(i)) # 循环输出每个主题
# 负面主题分析
neg_dict = corpora.Dictionary(neg[2]) # 建立词典
neg_corpus = [neg_dict.doc2bow(i) for i in neg[2]]
# 每个主题输出5个
neg_lda = models.LdaModel(neg_corpus, num_topics=5, id2word=neg_dict) # LDA模型训练
for i in range(3):
print(neg_lda.print_topic(i)) # 循环输出每个主题
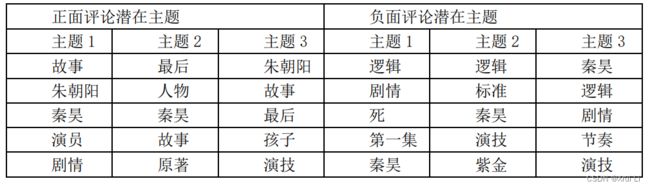
根据差评中的潜在主题中的高频词,即逻辑、剧情、第一集、秦昊、演技、剧情、节奏、紫金等关键词,反映了对这部剧有所失望的很可能是阅读过原著小说《坏小孩》的观众,认为电视剧的剧情把握和对原著的改编并没有达到这些用户的期望,而且从主题1中可以发现,尤其是第一集的故事铺垫和背景交代可能远远没有达到他们的预期,认为其损失了过多的原著该有的信息。此外对演员演技,存在两方褒贬不一的评价,可能是演员没有将这些用户在小说中幻想的角色更生动有力地表现还原出来,导致他们感到有所失落
3.5 豆瓣影评情感分析
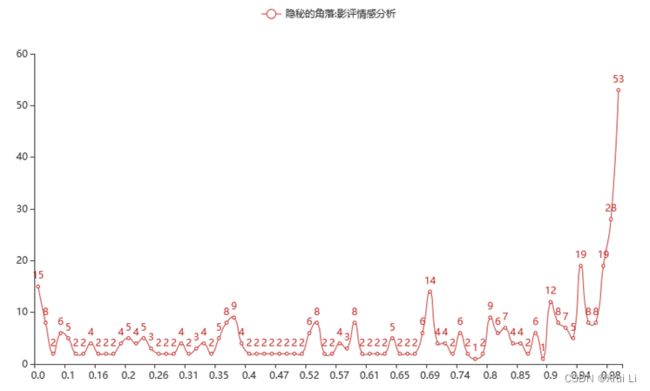
从情感折线图可看出整体情感得分要大于0.5,尤其是最多人数的得分0.99有53人。因此,可以判断《隐秘的角落》的播出受到了大多数观众的追捧,口碑整体趋向于好的方向,不存在很明显的评价两极分化。
3.6 人物提及词频分析
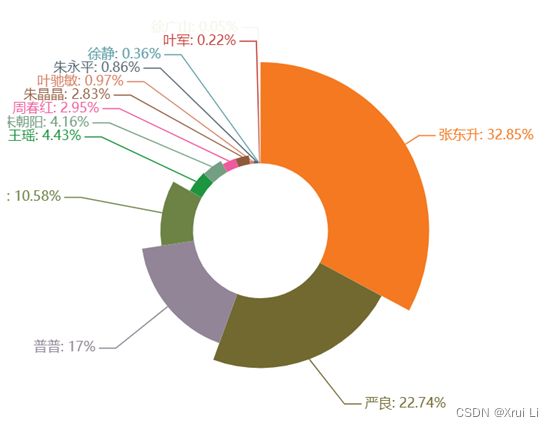
根据可视化结果可以看到,评论中“张东升”这一角色的提及频率最高,其次是“严良”和“普普”,推测张东升在该剧中的人物塑造是最为成功,给观众留下了较为深刻的印象。该剧中张东升不同于一般脸谱化的反派角色,其人物形象更加丰满,同时由于其台词出圈,也引发了观众对人物的热议。但观察可视化结果,同样发现作为主角的“朱朝阳”提及频率却并不高。节目播出后,剧中朱朝阳的人气并不低,并且由于后期剧情的反转,该角色理应受到观众热议。在观察原网友评论数据后发现,弹幕数据相较豆瓣评论更显口语化,大部分弹幕中观众一般称呼他为“学霸”、“儿子”等。
3.7 人物关系网络分析

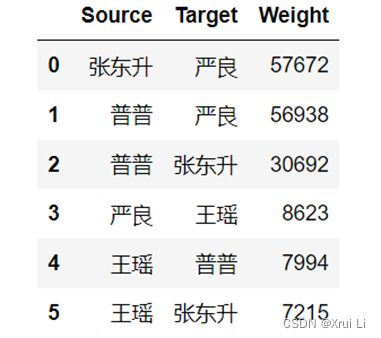
根据可视化结果可以看到,“严良” “普普”“张东升”这三个人的发生交集最高,即在用户在弹幕中提及最多,说明这三个人是剧中的主要人物,每次出场时都能引发用户进行弹幕评论。并且从这个关系网络,可以看出,剧中的人物关系错综复杂。
四、统计建模
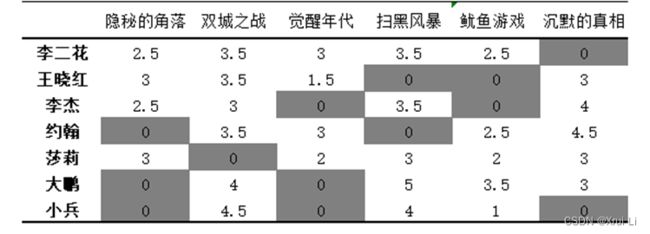
data = {'李二花': {'隐秘的角落': 2.5, '双城之战': 3.5,
'觉醒年代': 3.0, '扫黑风暴': 3.5, '鱿鱼游戏': 2.5},
'王晓红': {'隐秘的角落': 3.0, '双城之战': 3.5,
'觉醒年代': 1.5, '沉默的真相': 3.0},
'李杰': {'隐秘的角落': 2.5, '双城之战': 3.0,
'扫黑风暴': 3.5, '沉默的真相': 4.0},
'约翰': {'双城之战': 3.5, '觉醒年代': 3.0,
'沉默的真相': 4.5, '鱿鱼游戏': 2.5},
'莎莉': {'觉醒年代': 2.0, '隐秘的角落': 3.0, '扫黑风暴': 3.0,
'沉默的真相': 3.0, '鱿鱼游戏': 2.0},
'大鹏': {'双城之战': 4.0, '沉默的真相': 3.0, '扫黑风暴': 5.0,
'鱿鱼游戏': 3.5},
'小兵': {'双城之战': 4.5, '鱿鱼游戏': 1.0, '扫黑风暴': 4.0}}
# 构建用户评分矩阵
data = pd.DataFrame(data)
data = data.fillna(0) # 0分表示用户尚未观看该影剧
mdata = data.T
# 计算电影之间的相似性矩阵, 并将相关性取值标准化到[0,1]之间。
mcors = mdata.corr()
mcors = mcors.applymap(lambda x:0.5 + 0.5*x)
# calculate the score of every item of every user
def cal_score(matrix, mcors, item, user):
"""
matrix:用户的评分矩阵
mcors:电影的相似性矩阵
item:电影名称
user:用户名称
return:用户对指定电影的一个打分
"""
totscore = 0
totsims = 0
score = 0
if pd.isnull(matrix[item][user]) or matrix[item][user] == 0:
for mitem in matrix.columns:
if matrix[mitem][user] == 0:
continue
else:
totscore += matrix[mitem][user] * mcors[item][mitem]
totsims += mcors[item][mitem]
# 加权平均得分, 电影评分为权值
score = totscore / totsims
else:
score = matrix[item][user]
return score
# 计算所有电影的得分矩阵
def cal_matscore(matrix, mcors):
"""
matrix:用户评分矩阵
mcors:电影相关性矩阵
return:用户对各电影的评分
"""
score_matrix = np.zeros(matrix.shape)
score_matrix = pd.DataFrame(score_matrix, columns=matrix.columns, index=matrix.index)
for mitem in score_matrix.columns:
for muser in score_matrix.index:
score_matrix[mitem][muser] = cal_score(matrix, mcors, mitem, muser)
return score_matrix
# 根据各用户所有电影的得分矩阵进行推荐得分前n的电影
def recommend(matrix, score_matrix, user, n):
"""
matrix:用户评分矩阵
score_matrix:各用户各电影的得分矩阵
user:用户名称
n:推荐的电影数量
"""
user_ratings = matrix.loc[user, :]
not_rated_item = user_ratings[user_ratings == 0]
recom_items = {}
# recom_items={'a':1,'b':7,'c':3}
for item in not_rated_item.index:
recom_items[item] = score_matrix[item][user]
recom_items = pd.Series(recom_items)
recom_items = recom_items.sort_values(ascending=False)
return recom_items[:n]
# 推荐主程序
score_matrix = cal_matscore(mdata, mcors)
for i in range(10):
user = input(str(i)+' 请输入用户名称:')
print(recommend(mdata,score_matrix,user,3))
模型演示结果如下,输入想要得到预测评分的用户名,最终成功预测三个电视剧的得分,分别是“隐秘的角落:3.2分”、“沉默的真相:2.9分”、“觉醒年代:2.5分”。如果要选择一部电视剧推荐给小兵的话,建议选择预测评分较高的《隐秘的角落》,可能用户喜欢观看的概率会更高。

五、总结与建议
本报告使用Python和Excel基于电视剧《隐秘的角落》的豆瓣影评及爱奇艺弹幕进行初步统计分析。分别对豆瓣影评进行了评分分布、关键词频率、影评城市分布、LDA主题分析,然后对爱奇艺弹幕评论进行了人物网络分析,共得出以下几个较重要的结论:电视剧《隐秘的角落》整体口碑较高,广受观众喜爱;该剧的热度随着时间的推移逐渐减小;观众讨论最多的是张东升饰演者秦昊,其次是剧中角色朱朝阳;评论用户多位于北京与上海两个城市,该剧在北京的收视效果最好;该剧的剧情和演员演绎方面广受观众好评;演员秦昊饰演的张东升在弹幕讨论中热度最高;人物网络错综复杂。
最后,本文通过收集观众对一系列相似类型剧集的评分数据,构建了电影评分预测模型,分析未观看观众对《隐秘的角落》的可能打分,从而决定是否为其推荐该剧。
基于以上分析结果,本报告给影片制作方做出如下建议:
- 影片改编拍摄时,应尊重原著,非必要不要对原著进行大的纂改,做到改编不胡编;
- 影片的首播十分重要,在影片开播前要做足宣传,在各大平台网站上投放预告片、播放花絮、爆料趣事,大幅度做宣传,除北京、上海等大城市外,其余地区热度较低,更加需要加大宣传;
- 观众往往根据其观看一部剧的初印象,来评判该剧是否值得继续观看,因此影片的开播集十分重要,影片制作方要着重注意开场的剧情、台词、运镜等,以吸引观众、留住粉丝,同时也要避免头重脚轻,应兼顾后续剧情;
- 为了维持影片的热度以及挖掘其中更多的内容价值,影片制作方可以选择与更多的自媒体方合作,对内容进行有趣好玩的二次创作,例如:人物经典场面、电视剧剧情解说、鬼畜等等;
- 《隐秘的角落》一剧中各角色的饰演者,尤其是几位主演的演技生动,热度高涨,未来影片制作方可以考虑继续合作。
同时,对于观众,给出如下建议:
- 该剧的整体评价较好,剧情和演员演技广受好评,具有观看价值;
- 该剧定位于悬疑犯罪剧,剧中人物关系较为复杂,剧情跌宕起伏,考验逻辑思维能力,可以推荐喜爱该类影视的观众观看。