技术博客|第16期:个性化视频搜索引擎:排序篇(下)



模型结构决定了信息提取的效率,在搜广推领域有大量的相关研究。我们借鉴业内排序模型的优秀实践并结合视频搜索的特点,设计了一套以深度编码网络为基础提取信息、适合多目标优化的多任务专家网络以及解决偏差问题的位置消偏网络三部分组成的视频搜索排序模型,整体如图1所示。
接下来分别展开介绍深度编码网络,多任务专家网络和位置消偏网络的设计。
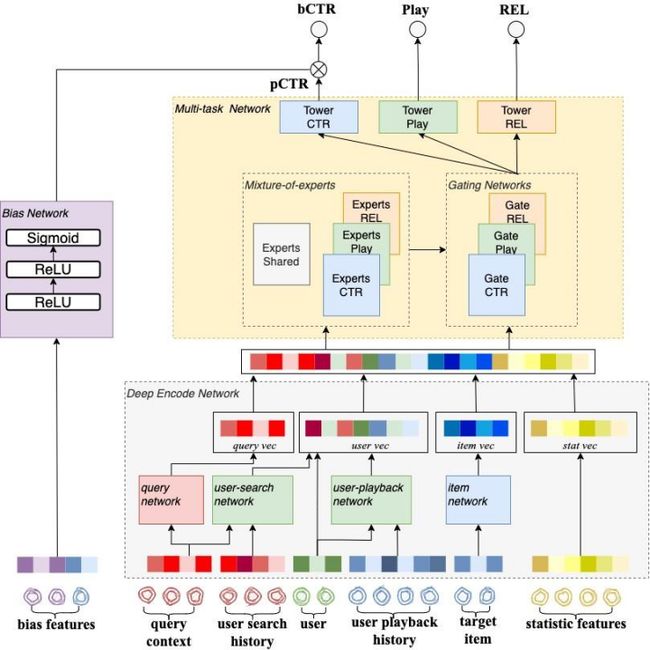
图 1: 排序模型整体结构

搜索引擎的排序信息主要包括查询词,候选视频,用户信息,搜索上下文等。我们的深度编码网络设计主要包括三部分,查询侧信息表达、候选视频侧信息表达以及用户信息表达。
查询侧信息表达 查询侧信息包括查询词本身、扩展查询词以及查询词的头部点击相关视频。查询词本身由 subterm 词袋模型生成向量,细节参考视频搜索引擎召回篇[2]。对于头部查询词,除用词袋模型生成的向量外,还有一路直接的 Embedding Lookup 向量。
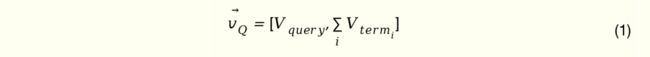
如果同一视频在多个搜索查询词下被用户点击,那么多个搜索查询词之间大概率具有相似性,对于其中一个查询词而言,其余查询词可以作为该查询词的信息表达补充,即扩展查询词。这里,我们按照共点击次数保留头部 K 个扩展查询词。每个扩展查询词和原查询词相关性是不同的,我们希望相关性差的扩展查询词的作用弱些,因此设计了和原查询词的 Attention 机制,用于区分不同扩展查询词的作用强弱。

其中 VRQ 是扩展查询词矩阵,矩阵中的每一行表示对应扩展查询词的向量。
查询词的头部点击视频也可以作为查询词的信息表达补充。我们也通过类似的 Attention 机制处理得到相关视频向量。

其中 VRD 是相关视频矩阵,矩阵中的每一行由相关视频的向量构成。
最终的查询侧向量是上述查询词向量、扩展查询词向量以及相关视频向量拼接组成。如图2左侧所示。
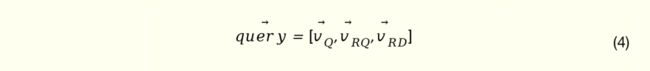
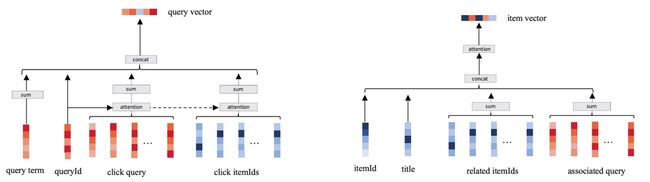
图 2: 左侧:排序模型查询侧信息表达网络结构图,左至右输入依次为查询词 term 词袋向量、查询词向量、扩展查询词向量以及相关视频向量。右侧:排序模型视频侧信息表示网络结构。左至右输入依次为视频 ID 向量、标题 term 词袋向量、相关视频向量以及相关查询词向量
候选视频侧信息表达 视频信息主要包括 meta 信息(标题、描述、分类等)和统计信息(点击量、播放量、热度等。此外,我们发现在视频侧加入一些预训练模型的输出向量有助于提升搜索效果。例如,推荐系统中的相关视频可以帮助搜索引擎更好地理解每个视频的内容类型以及用户行为在当前视频上所体现的兴趣分布。因此,我们在视频侧引入了推荐系统输出的视频向量增强视频侧信息表达。
具体如图2右侧所示,视频表示向量由视频 ID(通过 Embedding 向量化),视频标题(对 term vector 做 sum pooling),相关视频向量(推荐系统输出),点击查询构成(对历史点击做 sum pooling)。为了增加不同表示信息的交互,在上述信息之上增加了 Attention 层,计算过程参考公式组(5)。实际应用时,会提前产出每个视频表示向量以便于节省在线计算开销。

用户信息表达 除了查询词和视频,用户行为信息也是个性化排序模型非常重要的一部分。我们的模型主要使用了用户播放和搜索历史两种信息。对于播放历史,基本的输入信息是视频序列,序列当中的每一个视频都会经过前述的过程 (5) 得到一个整体视频表示向量。首先会为播放历史的每一个视频计算权重,由当前的查询词、视频表示向量和以及视频在序列中的位置向量(当前视频是倒数第几个播放记录),经过网络交互计算得到。位置向量及权重的计算参考 (6)。

公式(6)中的 linear 为全连接网络的线性变换部分,定义如下:
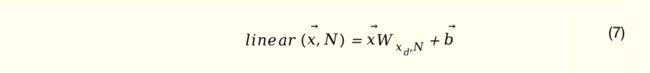
最终的播放历史向量表示为基于上述权重的播放视频加权和。搜索历史向量的表示过程类似,只是视频表示向量换成了搜索词的表示向量。
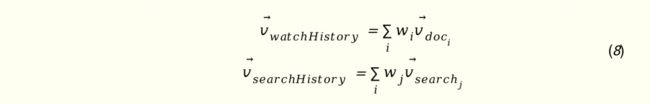
整个过程如图3所示。用户的的向量表示由上述播放历史向量、搜索历史向量以及用户ID向量三部分组成。
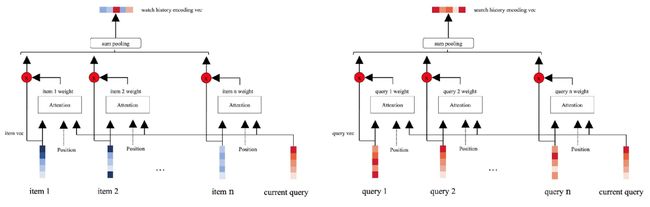
图 3: 排序模型中用户播放历史和搜索历史的编码过程。播放历史和搜索历史采用类似的编码结构。为了区分不同位置的信息输入,位置向量被引入到编码过程中。历史播放视频或者历史查询词信息与当前查询词和位置向量一起交互计算出权重系数,该系数和历史播放视频/历史查询词加权得到最终的编码向量。

为了更好地刻画视频搜索体验,我们设计了相关性、点击率和播放时长三个优化目标,它们之间既有关联也存在差异。为了在模型结构层面表达不同优化目标之间的异同点,我们采用了业界比较流行的多任务专家网络(Customized Gate Control)进行多目标建模。网络结构主要包括专家学习 Expert 网络、权重控制 Gate 网络以及任务 Tower 网络。专家网络包括共享专家网络和任务独享专家网络,每个专家网络有多个子网络组成,专家抽取网络的输入是深度编码网络输出的向量化表达 x,输出计算公式为
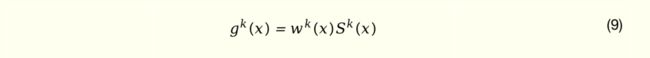
其中 Wk(.) 为第k个任务的Gate网络,输出用于加权不同的 Experts 结果,具体计算公式为
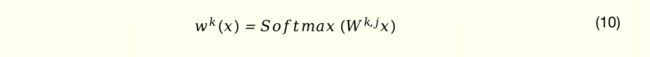
Sk(x)为第 k 个任务输入的 Experts,公式为
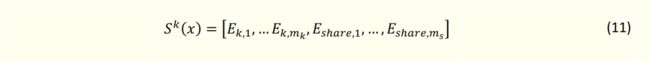
任务网络的输入为本任务相关的专家网络及共享专家网络与对应权重控制网络输出的加权和,输出计算公式如下:
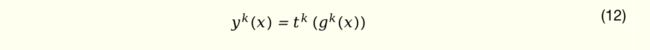
其中,tk(.) 表示第 k 个任务的 tower 网络。多任务训练的目标函数为
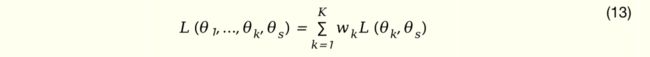
其中 θs, θk, K, wk 分别表示共享参数、任务特定参数、任务数、loss的权重,这里我们的任务为REL(相关性),CTR(点击率)和 Play(播放时长)。点击率任务的训练样本空间为全部展现样本空间;而播放时长训练的样本空间为有播放行为的样本空间,是点击样本样本空间的子集;相关性训练样本空间为带有标注的样本集合。训练时,只有在任务样本空间内的才会更新对应任务的 loss。任务的权重 wk 为预设定的经验超参。

用户点击行为通常受到视频所在位置的影响,相同的视频排的越靠前就更容易被点击。即点击概率由观察概率和视频选择概率共同决定:
![]()
为了准确估计每个视频的无偏点击率,我们在构建模型的时候增加了 Bias Network来对观察概率进行建模。除点击位置外,我们同时将设备类型 (TV/Mobile/Web),产品类型,查询词长度以及搜索页面作为输入信息,因为我们发现设备类型和查询词长度也在不同程度上影响了位置偏差。比如移动端和网页端通常输入的查询词比较完整,造成的位置偏差比电视设备要弱一些;不同的设备展示样式和视频数量也不一致,因而造成的偏差程度也有所不同。通过使用偏差网络输出的观察概率与无偏点击预估概率相乘来表示用户真实点击预估率的表示,偏差网络建模参考公式(15),模型结构参考图1。

在模型训练阶段,为了使偏差网络更好的对观察概率建模,同时减少点击预估概率信息的影响,我们对偏差网络特征做了5%-10%的dropout。线上预测时,模型裁剪掉偏差网络,使用无偏点击预估概率。

尽管信息检索的趋势是把越来越多的特征工程的工作挪到模型结构里面由模型自己来决定什么样的特征组合是最合适的。但是在我们的模型结构中还是保留了大量的人工特征,主要有两方面的原因: 首先我们认为模型结构不能够完全取代人工特征,至少不能以较低的计算成本替代,因此同时保留人工特征与模型特征可以起到相互补充的作用;其次,我们的系统经过了多个版本的迭代,天然保留了各个版本时期的特征函数,因此我们从实用主义出发,在实验验证的基础上保留了大量的人工特征。
除去前述模型部分已经介绍的输入信息外,我们的人工特征设计主要包含以下几类:
命中信息: 精准命中,部分命中,前缀命中以及命中的信息域等。
文本相似度:TF-IDF,BM25, EditDistance, Jaccard 等。
语义相似度: 我们对于长尾词增加了基于预训练模型的语义相似度特征。
点击相似度: 利用 GNN 对点击二部图建模,计算查询词和候选视频的点击相似度。
视频质量类特征:视频类型、上映时间、内容分级、热度、质量打分等。
查询词与视频的统计指标:查询次数,点击次数,点击率等。
特征离散化 特征离散化可以起到非线性表达和向量化学习的效果,同时可以解决输入特征的量纲和取值范围不一致问题。离散化的方法也多种多样,包括等宽、等频、熵最小、卡方分箱、树模型以及 autodis 等。在实际应用中,我们并未花太多精力对这个问题做深入讨论,而是采用了简单的等频分桶方法。具体而言,根据数据分布将特征值按照分位数分桶,在线上预测的时候根据当前样本的当前特征值所处的百分位决定落在哪个桶中,如公式(16)所示。
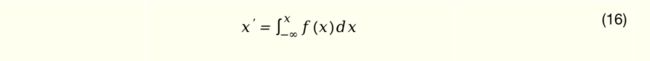
特征重要性 特征重要性分析是检查 DNN 模型是否符合预期的一个技术手段。对于搜索引擎,我们有两个场景需要做特征重要性分析,一是离线模型分析,在模型训练好以后查看重要的特征是否按照预期排在非常靠前的位置;二是线上 debug 某一个不符合预期的排序结果。
针对离线模型分析,我们对比了两种方式,第一种方式是 Mask 掉某一个特征组,对比 Mask 掉每个特征后造成的 AUC 变化大小; 第二种方式是将同一个查询词下面的搜索结果放到一个minibatch内,然后shuffle mini-batch 内部各个特征的取值并计算由 shuffle 造成的 AUC 差异,对于头部特征两种计算方式得到的特征重要度排名几乎一致。
针对线上排序问题debug,我们通常需要对比两个结果相对排序位置的原因,我们的做法是逐一交换两个视频的特征组并根据由此产生的排序分数值变化来判断是哪些特征造成的异常结果。

搜索排序涉及产品、算法、工程和数据等多方面技术话题,是一个比较大的系统性问题。
仅在模型设计方面就包括经典的 LTR 算法,近世代的 DNN 模型结构,多目标优化,位置消偏等内容;在搜索体验上同时需要考虑到个性化与相关性的平衡;在工程上要考虑数据的一致性以及特征工程的合理设计等等。排序话题内容广泛,非本文浅言所能详述,故而本文作者仅从自身实践出发,以 Hulu 和 Disney+ 搜索引擎的设计为例,简述我们是如何设计排序系统的。除了文中所讨论内容,我们认为还有一些问题也需要我们在设计排序系统时认真考虑:
对业务目标有深入的理解。我们是对什么内容排序,应该关注什么样的业务目标? 只有对所做的业务有深入的理解才能够设计恰到好处的排序目标。
设计模型之前先解决好工程和数据的问题。不同模型对工程架构有不同的要求,要确保工程架构和数据体系能够支撑模型设计。
优化指标之前先做好相关性的保底工作。搜索引擎有明显的客观用户体验,在相关性没有建设好的前提下贸然优化指标很有可能出现头部搜索结果不相关的现象。

[1] 邹敏, 个性化视频搜索引擎排序篇(上)https://mp.weixin.qq.com/s/8KkXANIorplUEv-qFf4ZdA
[2] 邹敏, 个性化视频搜索引擎召回篇https://mp.weixin.qq.com/s/lmzsB8DZ8MKdlXqI-QfcCw
[3] Jiang, Shan, et al. "Learning query and document relevance from a web-scale click graph." Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 2016.
[4] Lamkhede, Sudarshan, and Sudeep Das. "Challenges in search on streaming services: netflix case study." Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2019.
[5] Huang, Jui-Ting, et al. "Embedding-based retrieval in facebook search." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[6] Li, Sen, et al. "Embedding-based product retrieval in taobao search." Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021.
[7] Junyan Chen,Jason Li,etc Make Every feature Binary: A 135B parameter sparse neural network for massively improved search relevance https://www.microsoft.com/en-us/research/blog/make-every-feature-binary-a -135b-parameter-sparse-neural-network-for-massively-improved-search-relevance/, August 2021
[8] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[9] Kerber, Randy. "Chimerge: Discretization of numeric attributes." Proceedings of the tenth national conference on Artificial intelligence. 1992.
[10] McMahan, H. Brendan, et al. "Ad click prediction: a view from the trenches." Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013.
[11] Guo, Huifeng, et al. "PAL: a position-bias aware learning framework for CTR prediction in live recommender systems." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.

Youcheng Jiang, 内容推荐部门搜索组资深研发工程师。
Min Zou, 内容推荐部门搜索组资深研发经理。
内容推荐部门(Content Discovery Org.)是迪士尼流媒体核心研发部门,主攻Hulu、Disney+、Star+等迪士尼流媒体产品线的三大业务方向:搜索、个性化推荐、内容推广。在每个业务方向上都和人工智能技术深度融合,涉及AI平台的搭建、前沿算法的研究、以及工程系统的集成,致力于为迪士尼流媒体用户提供最佳的视频观看体验。
自成立伊始,该部门始终将内容的精准传递作为首要业务目标,深入结合工程、算法和数据,利用人才优势与人工智能基础解决业务问题。
推荐阅读:
个性化视频搜索引擎:排序篇(上)
