一文带你了解Linux内核之有关Linux文件系统实现的问题
Linux的使用和用户空间程序的编程和文件系统有着密切的关系,文件系统的概念大家应该都有些熟悉,这里我不多说,因为说了也和大家以前讲解的一样,这些概念能了解就是了,大家想了解随便都能百度得到。首先我来说下Linux的虚拟文件系统。文件系统的实现因系统 的不同而不同,Linux最好的特性之一是他支持许多文件系统,文件系统的构造如下图:

上图中VFS(虚拟文件系统)依赖数据结构来保存其对一个文件系统的一般表示,其中数据结构罗列如下:
- 超级块结构:存放已经安装的文件系统的相关信息;
- 索引结点结构:存放有关文件的 信息;
- 文件结构:存放被进程打开的文件的相关信息;
- 目录项结构:存放有关路径名和路径名所指向的文件的信息。
Linux内核使用全局变量来保存先前提到的指向结构体的指针,所有的结构都用双向链表保存,内核保存指向链表头的指针,并且把它作为链表的访问点,这些结构都用list_head类型的域,用它来指向链表中的前一个元素,下表是内核保存的全局变量以及这些变量指向的链表类型(与VFS相关的全局变量)
| 全局变量 | 结构类型 |
| super_blocks | super_block |
| file_systems | file_systems_type |
| dentry_unused | dentry |
| vfsmntlist | vfsmount |
| inode_in_use | inode |
| inode_unused | inode |
super_block、file_system_type、dentry、vfsmoubt结构都保存在它们自己的链表中,索引结点能够在全局的inode_in_use上或者inode_unused上找到自己,或者它们对应的超级快的局部链表上都可以找到自己。
除了主要的VFS结构之外,还有几个其他的结构与VFS相互作用,fs_struct和files_struct,namespace,fd_set,下图讲诉了进程描述符是如何与文件相关的结构相关联的。
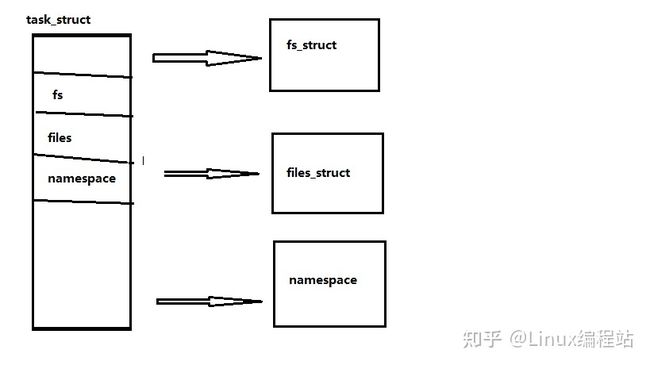
先来介绍fs_struct结构,fs_struct结构可以被多个进程描述符引用,下述代码在include/Linux/fs_struct.h中可以查到哦,代码解释不好的请大神指教
struct fs_struct{
atomic_t count; //保存引用特定fs_struct的进程描述符数目
rwlock_t lock;
int umask; //保存一个掩码,表示将要在打开文件上设置的许可权
struct dentry * root, *pwd ,*altroot; //都是指针,,,,
struct vfsmount * rootmnt, *pwdmnt, *altrootmnt; //指针,
};files_struct包含打开文件和其描述符的相关信息,它使用这些集合来对它的描述符进行分组。下面代码在include/linux/file.h上可以查看到
struct files_struct{
atomic_t count; //与fs_struct类似
spinlock_t file_lock;
int max_fds; //表示进程能够打开的文件的最大数
int max_fdset; //表示描述符的最大数
int next_fd; //保存下一个将要分配的文件描述符的值
struct file ** fd; //fd数组指向打开的文件对象的数组
fd_set *close_on_exec; //是指向文件描述符集的一个指针,这些文件描述符在exec()时候就被标志位将要关闭,如果在exec()时候被标志位“打开”的文件描述符数超过close_on_exec_init域的大小,则改变close_on_exec域的值;
fd_set *open_fds; //是一个指针,指向被标记为“打开”的文件描述符集合,
fd_set close_on_exec_init; //保存一个位域,表示打开文件对应的文件描述符
fd_set open_fds_init; //这些都是fd_set类型的域,其实都不懂,,,
struct file *fd_array[NR_OPEN_DEFAULT];//fd_array数组指针指向前32个打开的文件描述法
};通过INIT_FILES宏初始化fs_struct结构:
#define INIT_FILES \
{
.count = ATOMIC_INIT(1),
.file_lock = SPIN_LOCK_UNLOCKED,
.max_fds = NR_OPEN_DEFAULT,
.max_fdset = __FD_SETSIZE,
.next_fd = 0,
.fd = &init_files.fd_array[0];
.close_on_exec = &init_files.close_on_exec_init,
.open_fds = &init_files.open_fds_init,
.close_on_exec_init = {{0, }},
.open_fda_init = {{0, }},
.fd_array = {NULL, }
}NR_OPEN_DEFAULT的全局定义被设置为BITS_PER_LONG,BITS_PER_LONG在32位系统中是32,在64位系统中是64.
下面来介绍一下页缓冲,我们现在看看它是如何工作和实现的。在Linux中,内存被分成区,每个拥有活跃页的链表和不活跃的链表,当页不活跃的时候,就会被写回磁盘,下图说明了上述关系:

页缓冲的核心是address_space对象,其代码在include/linux/fs.h中可以查看(这段代码不是很懂,求大神指教):
struct address_space{
struct inode *host;
struct radix_tree_root page_tree;
spinlock_t tree_lock;
unsigned long nrpages;
pgoff_t writeback;
struct address_space_operations *a_ops;
struct prio_tree_root i_map;
unsigned inr i_map_lock;
struct list_head i_mmap_nonlinear;
spinlock_t i_mmap_lock;
atomic_t truncate_count;
unsigned long flags;
struct backing_dev_info *backing_dev_info;
spinlock_t private_lock;
struct list_head private_list;
struct address_space *assoc_mapping;
};Linux内核还把块设备上的每个扇区表示buffer_head结构,buffer_head结构应用的物理区是设备b_dev的逻辑块b_blocknr,引用的物理内存是起始于块大小为b_size个字节的b_data内存数据块,这个内存块在物理页b_page中,其结构如下图:
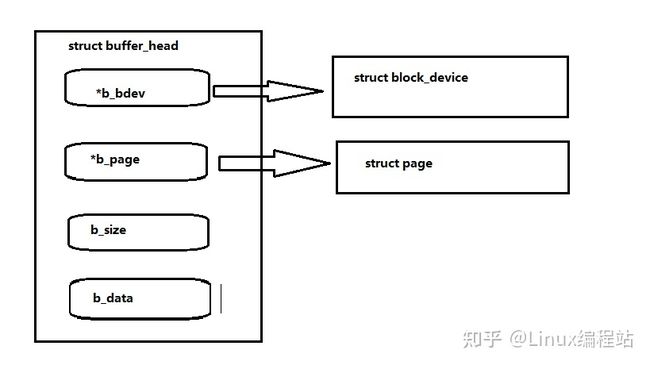
最后来说说VFS系统调用和文件系统层,并且追踪它们的执行直到内核级别,我们得先了解四个函数:open()、close()、read()、write()。
open()函数:
open 函数用于打开和创建文件。以下是 open 函数的简单描述
#include
int open(const char *pathname, int oflag, ... ); 返回值:成功则返回文件描述符,否则返回 -1
对于 open 函数来说,第三个参数(...)仅当创建新文件时才使用,用于指定文件的访问权限位(access permission bits)。pathname 是待打开/创建文件的路径名(如 C:/cpp/a.cpp);oflag 用于指定文件的打开/创建模式,这个参数可由以下常量(定义于 fcntl.h)通过逻辑或构成。
- O_RDONLY 只读模式
- O_WRONLY 只写模式
- O_RDWR 读写模式
打开/创建文件时,至少得使用上述三个常量中的一个。以下常量是选用的:
- O_APPEND 每次写操作都写入文件的末尾
- O_CREAT 如果指定文件不存在,则创建这个文件
- O_EXCL 如果要创建的文件已存在,则返回 -1,并且修改 errno 的值
- O_TRUNC 如果文件存在,并且以只写/读写方式打开,则清空文件全部内容
- O_NOCTTY 如果路径名指向终端设备,不要把这个设备用作控制终端。
- O_NONBLOCK 如果路径名指向 FIFO/块文件/字符文件,则把文件的打开和后继 I/O设置为非阻塞模式(nonblocking mode)
以下三个常量同样是选用的,它们用于同步输入输出
- O_DSYNC 等待物理 I/O 结束后再 write。在不影响读取新写入的数据的前提下,不等待文件属性更新。
- O_RSYNC read 等待所有写入同一区域的写操作完成后再进行
- O_SYNC 等待物理 I/O 结束后再 write,包括更新文件属性的 I/O
open 返回的文件描述符一定是最小的未被使用的描述符。
如果 NAME_MAX(文件名最大长度,不包括'\0')是 14,而我们想在当前目录下创建文件名长度超过 14 字节的文件,早期的 System V 系统(如 SVR2)会截断超出部分,只保留前 14 个字节;而由 BSD 衍生的(BSD-derived)系统会返回错误信息,并且把 errno 置为 ENAMETOOLONG。
POSIX.1 引入常量 _POSIX_NO_TRUNC 用于决定是否截断长文件名/长路径名。如果_POSIX_NO_TRUNC 设定为禁止截断,并且路径名长度超过 PATH_MAX(包括 '\0'),或者组成路径名的任意文件名长度超过 NAME_MAX,则返回错误信息,并且把 errno 置为 ENAMETOOLONG。
close()函数
进程使用完文件后,发出close()系统调用:
sysopsis
#include
int close(int fd); 参数:fd文件描述符
函数返回值:0成功,-1出错
参数fd是要关闭的文件描述符。需要说明的是:当一个进程终止时,内核对该进程所有尚未关闭的文件描述符调用close关闭,所以即使用户程序不调用close,在终止时内核也会自动关闭它打开的所有文件。但是对于一
个长年累月运行的程序(比如网络服务器),打开的文件描述符一定要记得关闭,否则随着打开的文件越来越多,会占用大量文件描述符和系统资源。
read()函数
当用户级别程序调用read()函数时,Linux把它转换成系统调用sys_read():
功能描述: 从文件读取数据。
所需头文件: #include
函数原型:ssize_t read(int fd, void *buf, size_t count);
参数:
- fd: 将要读取数据的文件描述词。
- buf:指缓冲区,即读取的数据会被放到这个缓冲区中去。
- count: 表示调用一次read操作,应该读多少数量的字符。
返回值:返回所读取的字节数;0(读到EOF);-1(出错)。
以下几种情况会导致读取到的字节数小于 count :
- 读取普通文件时,读到文件末尾还不够 count 字节。例:如果文件只有 30 字节,而我们想读取 100,字节,那么实际读到的只有 30 字节, 函数返回 30 。此时再使用 read 函数作用于这个文件会导致 read 返回 0
- 从终端设备(terminal device)读取时,一般情况下每次只能读取一行。
- 从网络读取时,网络缓存可能导致读取的字节数小于 count字节。
- 读取 pipe 或者 FIFO 时,pipe 或 FIFO 里的字节数可能小于 count 。
- 从面向记录(record-oriented)的设备读取时,某些面向记录的设备(如磁带)每次最多只能返回一个记录。
- 在读取了部分数据时被信号中断,读操作始于 cfo 。在成功返回之前,cfo 增加,增量为实际读取到的字节数。
例程如下(程序是网上找的例子,贴下来以以供大家理解一下)::
#include
#include
#include
#include
#include
#include
int main(void)
{
void* buf ;
int handle;
int bytes ;
buf=malloc(10);
/*
LooksforafileinthecurrentdirectorynamedTEST.$$$andattempts
toread10bytesfromit.Tousethisexampleyoushouldcreatethe
fileTEST.$$$
*/
handle=open("TEST.$$$",O_RDONLY|O_BINARY,S_IWRITE|S_IREAD);
if(handle==-1)
{
printf("ErrorOpeningFile\n");
exit(1);
}
bytes=read(handle,buf,10);
if(bytes==-1)
{
printf("ReadFailed.\n");
exit(1);
}
else
{
printf("Read:%dbytesread.\n",bytes);
}
return0 ;
} write()函数
功能描述: 向文件写入数据。
所需头文件: #include
函数原型:ssize_t write(int fd, void *buf, size_t count);
返回值:写入文件的字节数(成功);-1(出错)
功能:write 函数向 filedes 中写入 count 字节数据,数据来源为 buf 。返回值一般总是等于 count,否则就是出错了。常见的出错原因是磁盘空间满了或者超过了文件大小限制。对于普通文件,写操作始于 cfo 。如果打开文件时使用了 O_APPEND,则每次写操作都将数据写入文件末尾。成功写入后,cfo 增加,增量为实际写入的字节数。
例程如下(程序是网上找的例子,贴下来以以供大家理解一下):
#include
#include
#include
#include
#include
#include
int main(void)
{
int *handle; char string[40];
int length, res;/* Create a file named "TEST.$$$" in the current directory and write a string to it. If "TEST.$$$" already exists, it will be overwritten. */
if ((handle = open("TEST.$$$", O_WRONLY | O_CREAT | O_TRUNC, S_IREAD | S_IWRITE)) == -1)
{
printf("Error opening file.\n");
exit(1);
}
strcpy(string, "Hello, world!\n");
length = strlen(string);
if ((res = write(handle, string, length)) != length)
{
printf("Error writing to the file.\n");
exit(1);
}
printf("Wrote %d bytes to the file.\n", res);
close(handle); return 0; } 小结
今天看的代码不多,差不多都是网上找的代码,有些解释也是查阅资料写上去的,有些还是不懂,希望各路大神指教,这里我总结了有关Linux文件系统实现的问题,但是具体的细节方面并没有提及到,大家看了之后应该只能有一个大致的最Linux文件系统的了解,有读者问我看的是哪些书,这里我说明一下,看了Linux内核编程,还有深入理解Linux内核以及网上各种资料或者其他大牛写的好的博客。这里我是总结了一下,并且把自己不懂的还有觉得重要的说了一下,希望各位大神给些建议,thanks~
- - 内核技术中文网 - 构建全国最权威的内核技术交流分享论坛
原文地址:一文带你了解Linux内核之有关Linux文件系统实现的问题 - 文件系统 - 内核技术中文网 - 构建全国最权威的内核技术交流分享论坛(版权归原作者所有,侵删)